Steerable Visual Representations
Abstract: Pretrained Vision Transformers (ViTs) such as DINOv2 and MAE provide generic image features that can be applied to a variety of downstream tasks such as retrieval, classification, and segmentation. However, such representations tend to focus on the most salient visual cues in the image, with no way to direct them toward less prominent concepts of interest. In contrast, Multimodal LLMs can be guided with textual prompts, but the resulting representations tend to be language-centric and lose their effectiveness for generic visual tasks. To address this, we introduce Steerable Visual Representations, a new class of visual representations, whose global and local features can be steered with natural language. While most vision-LLMs (e.g., CLIP) fuse text with visual features after encoding (late fusion), we inject text directly into the layers of the visual encoder (early fusion) via lightweight cross-attention. We introduce benchmarks for measuring representational steerability, and demonstrate that our steerable visual features can focus on any desired objects in an image while preserving the underlying representation quality. Our method also matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination, exhibiting zero-shot generalization to out-of-distribution tasks.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
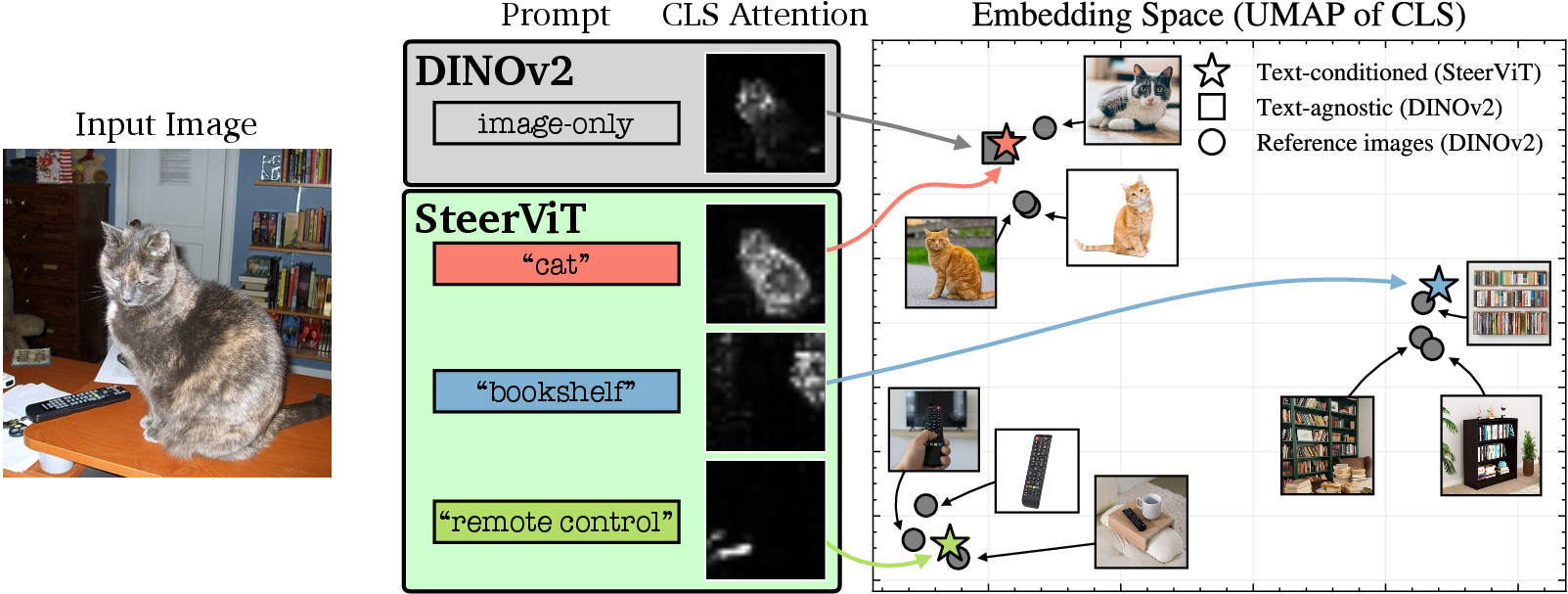
This paper is about teaching computer vision models to “pay attention” to whatever you ask for in an image, using plain language. The authors build a system called SteerViT that lets you steer what a vision model looks for—like telling it “focus on the remote control” instead of the most obvious thing (say, a cat). The big idea: you can guide the model with a short text prompt without breaking its general skill at understanding images.
What questions did the paper ask?
- Can we make a vision model focus on small or less obvious things in an image when we tell it what to look for in words?
- Can we do this without hurting the model’s overall quality for tasks like classification and segmentation?
- Is it better to mix text and image information early inside the vision model (while it’s still “looking”) rather than only at the end?
How did they do it?
Think of a Vision Transformer (ViT) like a careful photographer that scans an image in patches and builds a summary. Normally, it tends to focus on the most eye-catching object (like a bright cat in a room). The authors add a simple “steering” attachment that lets the photographer listen to short instructions—your text prompt—while it looks.
Here’s the approach in everyday terms:
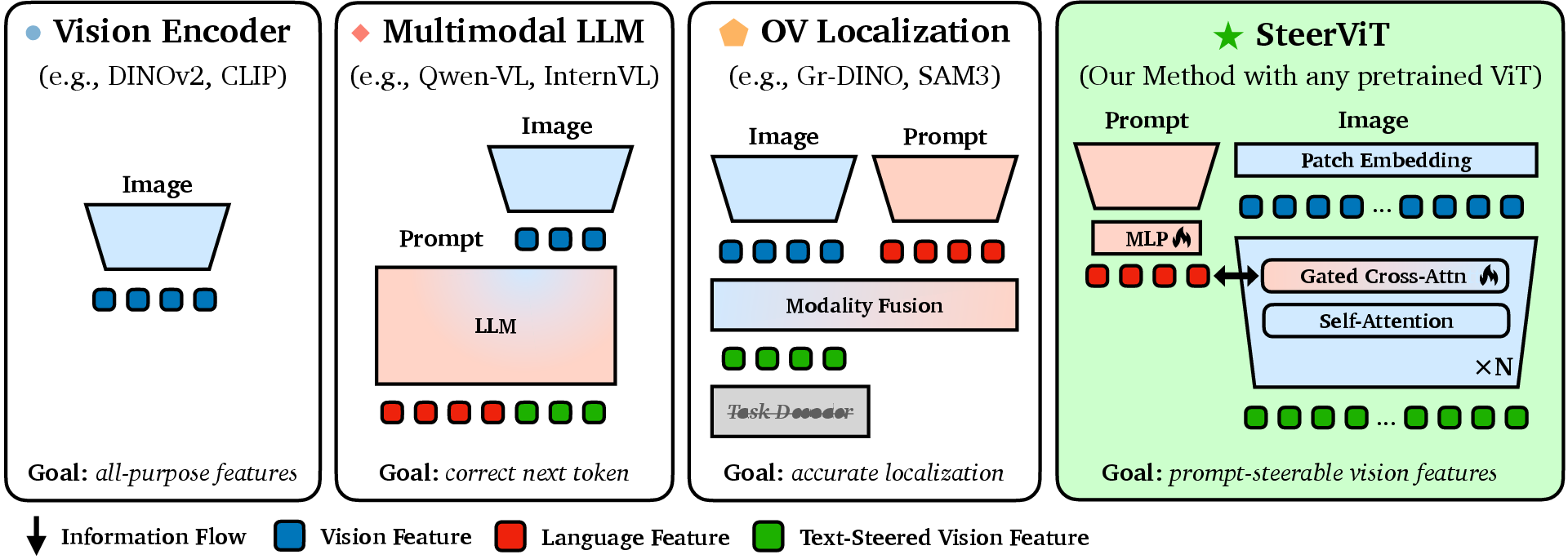
- The base model: They start with strong, pretrained vision models (like DINOv2). These are kept frozen—like using a great camera without changing its internal parts.
- Early fusion: Instead of telling the model what you want after it’s already done looking, they whisper instructions into its “ears” as it looks. In practical terms, they insert small cross‑attention layers inside the vision model so image features can directly “listen” to the text prompt during processing. This is called early fusion.
- Cross‑attention with a safety dial: The new layers have a gate (a tiny control knob) that decides how much the text should influence what the model attends to. It starts at zero (so it behaves exactly like the original model) and can gently turn up during training. Later, you can even adjust this dial yourself at test time.
- Training task (simple but smart): They train using “referential segmentation.” You show an image and a short phrase like “the bookshelf,” and the model learns to highlight the right patches. This encourages the vision model to route and use language in a helpful way without changing the original model’s knowledge.
- Data: They train on datasets where text describes regions of images (like RefCOCO) and related resources (e.g., Visual Genome, LVIS, Mapillary), so the system learns many ways people refer to things.
Analogy: Imagine giving a museum guide a flashlight (the attention) and instructions like “Find objects with eyes” or “Focus on the remote.” Early fusion means the guide hears your instructions while walking through the rooms, not just at the exit.
What did they find?
They built new tests and also used existing ones. Here are the key takeaways and why they matter:
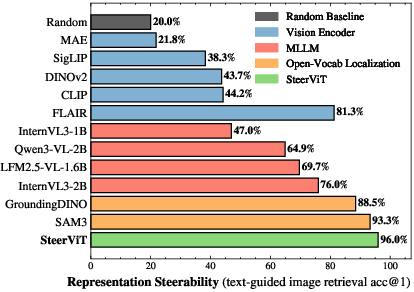
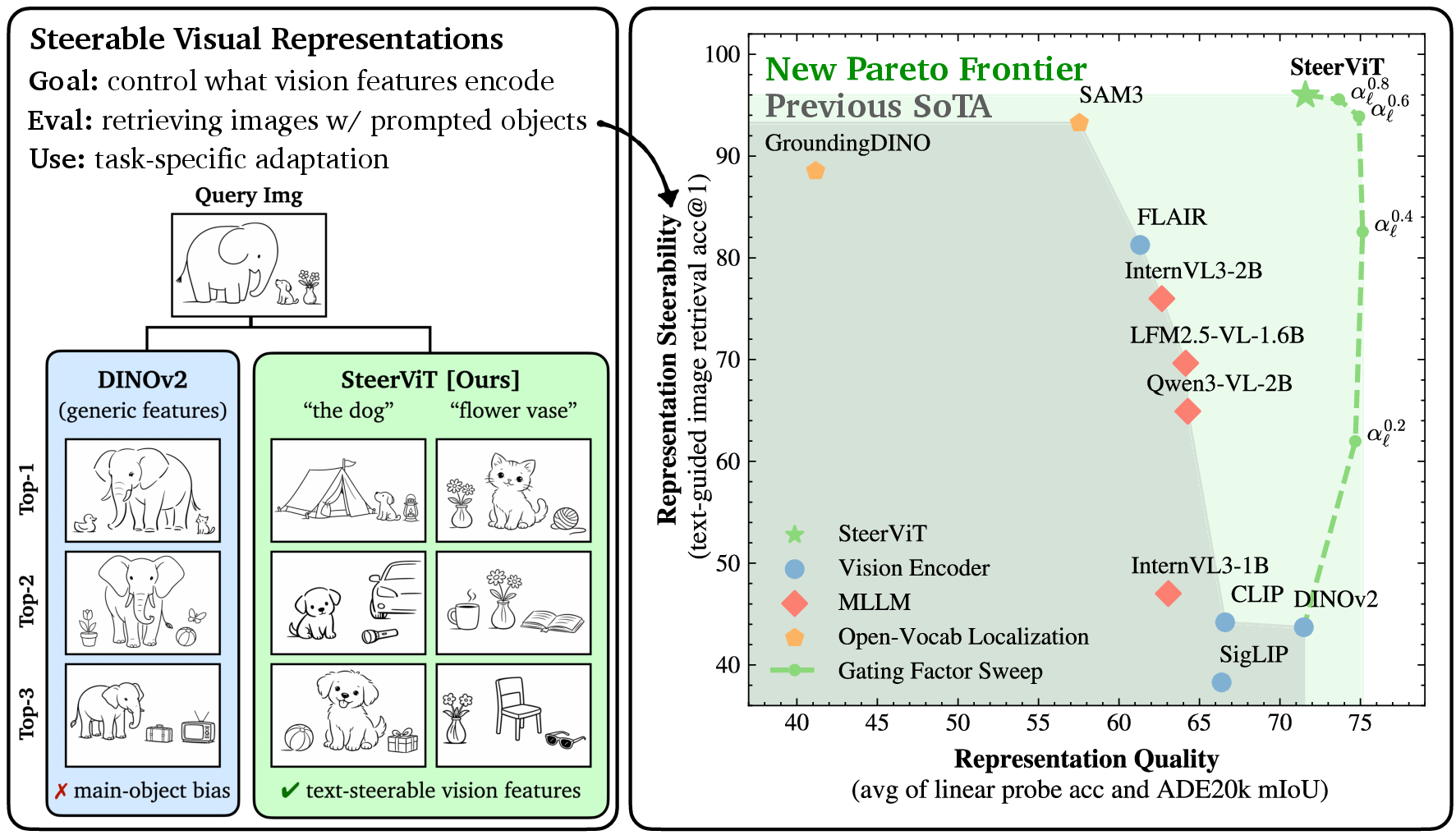
- Steers what’s important on command: On their CORE benchmark (a text‑guided image retrieval test), normal vision models mostly retrieve images with the same scene (e.g., “kitchen”) and ignore the small object you asked for (e.g., “fruit bowl”). SteerViT, guided by your prompt, retrieves images that match the requested object even if it’s tiny or not very noticeable. It performed much better than standard models and also better than “late fusion” approaches that mix text in only at the end.
- Attention goes where you ask: In a “mosaic” test (four pictures stitched together), SteerViT’s attention maps shift toward whatever you name (“person,” “potted plant”), while a regular model keeps focusing on the most prominent objects. This shows the model truly re-routes its focus based on your words.
- Keeps overall quality high: A common problem is that when you make a model very steerable, you often damage its general ability on standard tasks. SteerViT avoids this trade-off: it stays strong on classification and segmentation while also being steerable. In fact, by turning the “gate” dial, you can smoothly balance how much to listen to the text versus the original vision features.
- More detailed prompts unlock finer understanding: On personalized object tests (telling similar-looking objects apart, like “your white ECCV mug” vs. other mugs), more specific text prompts made a big difference. With detailed descriptions, SteerViT recognized specific instances much better—approaching or beating methods that needed special fine-tuning. This shows the model’s “granularity” depends on how detailed your instruction is.
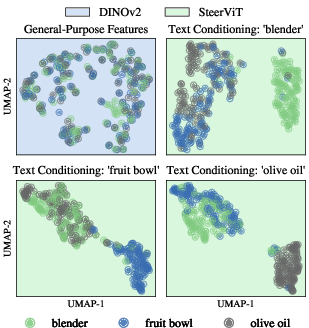
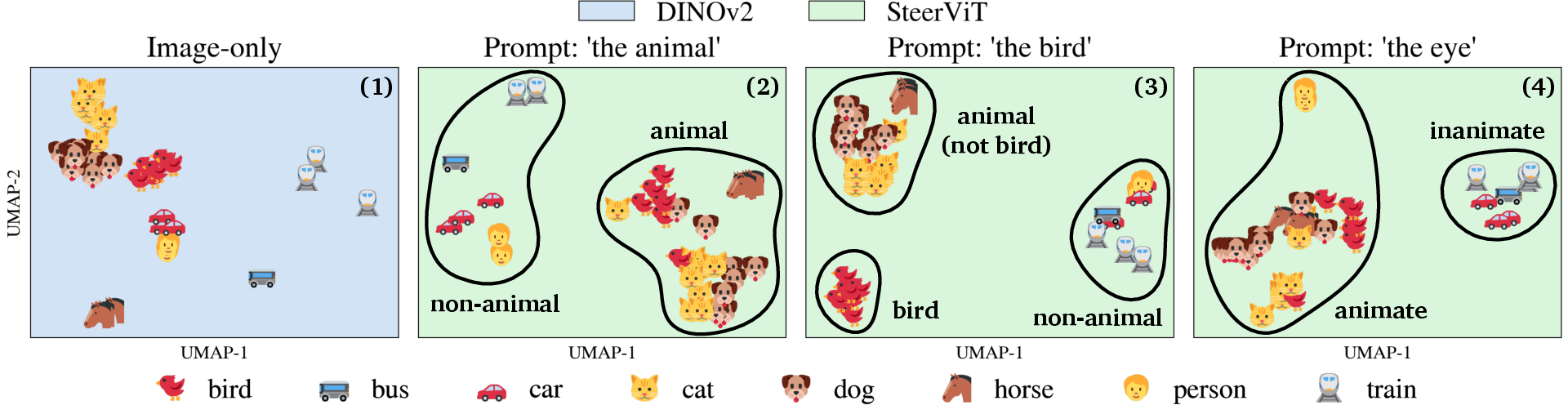
- Can group by concepts or traits, not just labels: When prompted with “animal,” images grouped by animal vs. non‑animal. With “bird,” birds separated more clearly. With “eye,” all things that have eyes (people, animals) clustered together, even across different categories. This means you can reorganize the model’s “map of images” by any idea you describe—not just fixed categories.
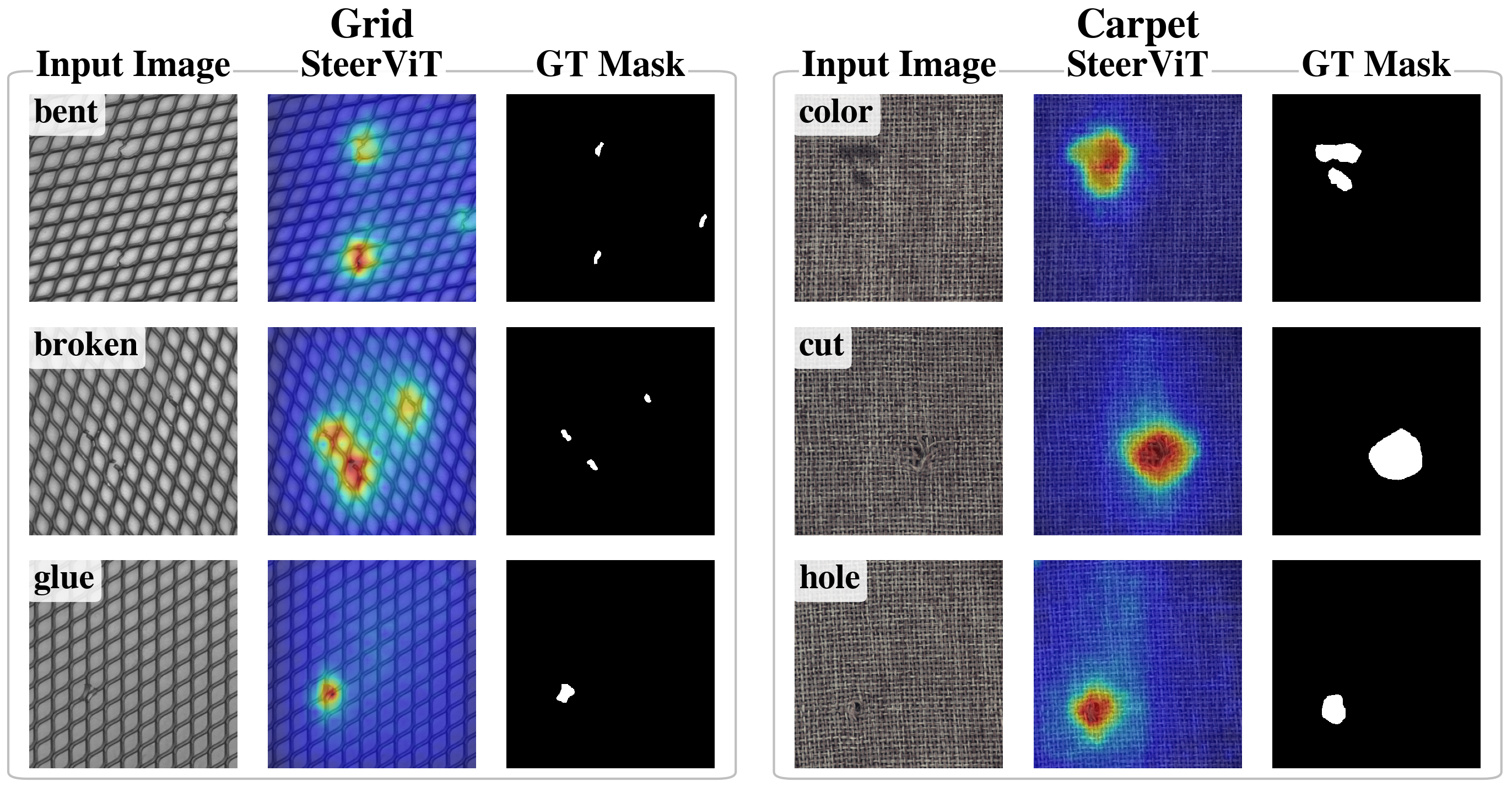
- Works zero-shot in new domains: In industrial anomaly detection (finding defects on objects like carpet or metal), SteerViT could highlight anomalies using a simple prompt like “the anomaly in the carpet,” despite never being trained specifically for this. It performed competitively with specialized zero-shot methods.
- Efficient and flexible: SteerViT adds only about 21 million new parameters on top of the frozen vision model—far smaller than giant multimodal models with billions of parameters. It also works across different backbones (DINOv2, SigLIP, MAE), with early fusion consistently beating late fusion.
Why does this matter?
This work shows a practical, flexible way to control what a vision model pays attention to—using everyday language—without retraining the whole model or sacrificing accuracy. That opens up many uses:
- Smarter search: “Find the photos where a small red backpack appears in a park,” even if it’s tiny in the background.
- Helpful robots and AR: “Focus on the green screwdriver,” so a robot or headset can attend to that object immediately.
- Personalized recognition: “My blue water bottle with stickers,” letting you find your specific item among many look-alikes.
- Industrial inspection: “Highlight the defect in the metal sheet,” working out of the box in new settings.
- Education and accessibility: Systems that can adapt their focus based on simple prompts, helping users specify what they want to see.
Bigger picture: It suggests a shift in how we combine vision and language. Instead of making LLMs carry the visual load, we let strong vision models be guided by language early in processing. This “steerable vision” idea could become a standard, lightweight way to adapt powerful vision systems to many tasks—just by changing the prompt.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address to strengthen and extend SteerViT.
- Real-world steerability beyond synthetic edits: Validate CORE-like conditional retrieval on large-scale, fully natural datasets with annotated non-salient objects and diverse scenes; quantify gains without inpainting artifacts.
- Breadth of downstream evaluations: Assess representation quality retention on a broader suite of tasks (e.g., object detection, instance/panoptic segmentation, pose estimation, depth) to confirm generality.
- Standard referring segmentation metrics: Report performance on RefCOCO/+/g with standard IoU/[email protected] to situate the approach among SOTA referential grounding methods (the model is trained on these datasets but not evaluated with their canonical metrics).
- Robustness to prompt phrasing: Systematically measure sensitivity to paraphrases, synonyms, negation, typos, varying prompt lengths, and adversarial/ambiguous instructions; develop prompt-robust steering.
- Multilingual and cross-lingual steering: Replace RoBERTa-Large with multilingual or instruction-tuned encoders and test zero-shot cross-lingual steerability without retraining.
- Multi-concept and relational prompts: Evaluate steering with conjunctions/disjunctions and spatial/relational reasoning (e.g., “the person to the left of the dog”, counting, attributes across objects).
- Negative prompts and exclusion: Test whether text can suppress concepts (e.g., “focus on the kitchen except the cat”) and design mechanisms for reliable exclusion.
- Confidence and abstention: Calibrate when to ignore or down-weight text that is irrelevant to the image; detect out-of-scope prompts to prevent harmful over-steering.
- Failure modes with incorrect prompts: Beyond CORE, quantify the impact of wrong or misleading prompts on generic tasks (classification/segmentation) and propose safeguards against performance collapse.
- Automatic conditioning strength: Learn prompt-conditioned, per-layer/per-head gates (instead of a global post-hoc scaling) to automatically trade off steerability and feature quality.
- Finer-grained gating: Explore token-wise, head-wise, and spatially adaptive gates for more precise control over where and how language influences features.
- Placement and quantity of CA layers: Optimize which blocks to augment, how many CA layers to insert, and whether different backbones prefer earlier or later fusion.
- Alternative fusion mechanisms: Compare gated CA with other early-fusion designs (e.g., FiLM, residual adapters, low-rank modulation) under equal parameter budgets.
- Text encoder choice: Study the effect of CLIP-text, DeBERTa, instruction-tuned LLMs, and frozen vs. lightly-tuned text encoders on steerability and visual quality.
- Generalization to larger/smaller backbones: Evaluate ViT-L/H, Swin, ConvNeXt, and mobile backbones; analyze scaling laws for steerability vs. quality vs. compute.
- Compute and memory overhead: Provide wall-clock latency, throughput, and memory benchmarks across resolutions/hardware; quantify the marginal cost of CA layers at inference.
- High-resolution and small-object regimes: Test at higher resolutions (≥1024 px) and on datasets emphasizing tiny objects to assess spatial precision of steering.
- Pixel-level supervision: Investigate whether pixel-aligned decoders or higher-resolution patching improve local steerability without harming global feature quality.
- Data scaling and diversity: Analyze how training on larger, more diverse referential/grounding corpora affects steerability, attribute/relational understanding, and robustness.
- OOV and long-tail concepts: Evaluate zero-shot steering to unseen categories, rare attributes, or fine-grained subtypes; characterize failure and recovery strategies.
- Compositional attribute steering: Move beyond qualitative UMAPs; quantify disentanglement and controllability for orthogonal attributes (e.g., color, material, part presence).
- Temporal/video extension: Extend to video ViTs; test prompt-conditioned tracking, temporal grounding, and persistence of steering over time.
- 3D and embodied settings: Explore steering for 3D point clouds, multi-view images, or robot perception where language guides attention in space and time.
- Interaction with downstream learners: Study how steered features integrate with training-free detectors/segmenters or lightweight fine-tuning in task pipelines.
- Interpretability and causality: Go beyond attention maps; conduct causal interventions (e.g., token ablations, concept activation vectors) to verify that language drives feature changes.
- Safety and bias: Audit whether text conditioning amplifies dataset or language biases (gender, race, culture) or suppresses safety-critical cues when mis-prompted; propose mitigation.
- Stability and reproducibility: Report variance across seeds/training runs and sensitivity to hyperparameters; establish best practices for robust training.
- Dependence on MLLM-generated descriptions (PODS): Quantify how noisy or hallucinated descriptions affect instance discrimination; investigate automated, reliable captioning or self-descriptions.
- Anomaly detection scope: Evaluate on more AD datasets (VisA, BTAD, MVTec-3D), with per-category analysis, threshold calibration, and comparison to strong non-zero-shot baselines.
- Bi-directional fusion: Explore limited vision-to-language updates (without drifting to language space) to improve alignment while retaining vision-centric embeddings.
- Continual prompting and session dynamics: Test sequential prompts on the same image to ensure stateless behavior and absence of hysteresis in features.
- Licensing and data issues: Clarify reliance on FLUX.2 edits for CORE and dataset licenses; assess potential style artifacts and their influence on results.
- Open-source artifacts: Provide full training code, pretrained weights, and data processing scripts to enable verification and broader adoption.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with minimal adaptation by leveraging the paper’s SteerViT approach (lightweight, early text–vision fusion with frozen ViTs and a frozen text encoder, trained via referential segmentation), which preserves base visual representation quality while enabling text-steered attention and global semantics.
- Conditional image retrieval in digital asset management and e-commerce (sectors: software, media, retail)
- What: Text-steered retrieval that finds images containing non-salient or small objects (“fruit bowl in a kitchen”, “blue backpack in a park”), outperforming late-fusion baselines and vanilla ViTs.
- Tools/products/workflows:
- “Steerable visual search” module for DAM systems and stock photo libraries.
- Vector DB pipelines that index generic ViT features and apply SteerViT at query time to steer global representations before similarity search.
- Assumptions/dependencies:
- Strong base ViT (e.g., DINOv2) and SteerViT cross-attention add-on (~21M params).
- Effective prompt engineering; retrieval degrades with incorrect or overly vague prompts.
- Personalized object discrimination in consumer photo libraries (sectors: software, consumer apps)
- What: Zero-shot instance-aware recognition (“my white ECCV mug”) and re-ranking by adding detailed descriptions; performance scales with prompt specificity and can surpass per-class fine-tuned ViT baselines.
- Tools/products/workflows:
- Photo managers that let users store instance descriptions; retrieval and album auto-curation via text prompts.
- UI exposes a “specificity knob” (maps to gate scaling factor) to tune coarse-to-fine granularity.
- Assumptions/dependencies:
- Detailed user-provided descriptions improve performance; coarse prompts may underperform vanilla ViT.
- Privacy and on-device inference considerations for consumer deployments.
- Zero-shot industrial anomaly segmentation (sectors: manufacturing, energy, infrastructure)
- What: Prompt-driven anomaly heatmaps (“the anomaly in the carpet”, “corrosion on the flange”) achieving competitive PRO scores vs dedicated zero-shot methods on MVTec.
- Tools/products/workflows:
- Inspection dashboards that let operators type anomaly prompts and visualize heatmaps; no task-specific training required.
- Rapid triage tools for QA lines or field inspections.
- Assumptions/dependencies:
- Requires known object class in prompt; domain shift may still exist for highly specialized imagery.
- Calibration/thresholding needed for production alerting.
- Analyst tools for targeted attention and explainability (sectors: security, compliance, media QA)
- What: Text-steered attention maps to focus on specific objects/attributes in cluttered scenes; improves interpretability and analyst efficiency.
- Tools/products/workflows:
- “Attention lens” plugin for CV dashboards that overlays prompt-conditioned heatmaps on frames.
- Gate scaling factor as a UI slider to balance general visual quality and steerability per task.
- Assumptions/dependencies:
- Misleading prompts can steer attention away from relevant cues; requires human-in-the-loop validation.
- Open-vocabulary search in surveillance and forensics (sectors: public safety, enterprise security)
- What: Post-event retrieval of non-salient entities or attributes (“person with red backpack”, “vehicle with broken taillight”) across large video/image stores.
- Tools/products/workflows:
- On-demand steering at query time over precomputed backbone features; re-encoding with SteerViT only for candidate frames to control latency.
- Assumptions/dependencies:
- Legal/policy compliance for surveillance use; careful governance to avoid misuse and bias.
- Performance depends on image quality and accurate prompts.
- Content moderation and curation (sectors: social platforms, media operations)
- What: Targeting small or less salient visual cues (e.g., brand logos, regulated items) for moderation, de-duplication, or tagging.
- Tools/products/workflows:
- Text-steered filters in moderation queues; editorial workflows that refine prompts to reduce false positives.
- Assumptions/dependencies:
- Category ambiguity handled via prompt specificity; requires human oversight.
- Semi-automatic annotation and dataset exploration for researchers (sectors: academia, ML teams)
- What: Prompt-conditioned patch-level masks accelerate labeling; clustering views steered by categories, super-categories, or attributes (e.g., “animal”, “has eyes”).
- Tools/products/workflows:
- Labeling tools that propose masks from text; interactive embedding visualizers that reorganize clusters based on prompt.
- Assumptions/dependencies:
- Weak supervision—quality varies by prompt and object scale; human edits required for ground truth.
- Robotics prototypes for open-vocabulary pick-and-place and scene understanding (sectors: robotics, warehousing R&D)
- What: Perception steered by text goals (“pick the blue screwdriver”, “grasp the handle”) to focus attention on relevant parts or instances without re-training.
- Tools/products/workflows:
- Integrate SteerViT into perception stack; planners produce textual objectives; downstream grasp planners consume steered attention maps/regions.
- Assumptions/dependencies:
- Real-time constraints and motion blur; requires optimization or batching for low-latency inference.
- Assistive object finding on mobile devices (sectors: accessibility, consumer apps)
- What: Prompt-based “find my X” visual highlighting in camera view (e.g., “find the TV remote”).
- Tools/products/workflows:
- On-device or hybrid inference; pointer/AR overlay to guide users to target object.
- Assumptions/dependencies:
- Compute/energy budgets on mobile; on-device privacy; variability in household clutter.
Long-Term Applications
These use cases are promising but require further research, scaling, domain adaptation, or systems integration beyond the current scope.
- Medical imaging: text-steered focus and segmentation (sectors: healthcare)
- What: Radiologists steer attention to subtle findings (“subtle ground-glass opacity”) or anatomical structures via prompts; potential to aid triage.
- Dependencies/assumptions:
- Requires domain-specific training/validation and regulatory approval; current training data are natural images, not medical.
- Robustness and explainability standards for clinical use.
- Autonomous driving and advanced ADAS (sectors: automotive)
- What: Real-time steering toward rare/hard-to-see hazards (“debris on road shoulder”, “broken traffic sign”) to complement standard detectors.
- Dependencies/assumptions:
- Strict latency and reliability; adversarial robustness; extensive validation in edge cases and adverse weather.
- AR/VR and wearable assistants (sectors: AR/XR, consumer hardware)
- What: Persistent, user-driven highlighting of objects/affordances (“exits”, “tool handles”, “allergen labels”) in immersive scenes.
- Dependencies/assumptions:
- Efficient high-res, low-latency inference; stable temporal tracking and multi-object prompts; ergonomic UI for prompt input.
- Geospatial and disaster response analytics (sectors: geospatial, public safety)
- What: Satellite/aerial image triage via prompts (“burnt areas”, “new construction”, “flooded fields”) to surface non-salient or novel patterns.
- Dependencies/assumptions:
- Domain adaptation to overhead imagery; handling multi-scale objects; model calibration for large-area scanning.
- Agriculture and infrastructure inspection (sectors: agriculture, utilities, energy)
- What: Zero-/few-shot detection of specific disease signs or asset faults via text prompts (“rust on tower cross-arm”, “leaf spot patterns”).
- Dependencies/assumptions:
- Domain-specific vocabulary and imagery; controlled data collection for evaluation; integration with existing inspection workflows.
- Document understanding and compliance (sectors: finance, govtech, enterprise)
- What: Text-steered attention to signatures, stamps, or specific clauses in scanned documents and forms.
- Dependencies/assumptions:
- Extension from natural images to document layouts; possibly integrating OCR and transformer document encoders; privacy and compliance.
- Video analytics with temporal consistency (sectors: media analytics, surveillance, sports tech)
- What: Prompt-steered tracking (“track the referee’s hand”, “monitor machinery indicator lights”) across frames with consistent identity and attention.
- Dependencies/assumptions:
- Temporal models for stable steering; handling occlusions and motion; scalable indexing of long videos.
- Edge deployment and compression (sectors: IoT, robotics, mobile)
- What: Distilled/quantized steerable modules for constrained devices that allow on-device prompting.
- Dependencies/assumptions:
- Research on compressing cross-attention layers without losing steerability; hardware acceleration for early-fusion blocks.
- Safety, governance, and audit for steerable vision (sectors: policy, standards)
- What: Frameworks and tools for logging prompts, measuring prompt sensitivity, and detecting harmful/malicious steering in surveillance or moderation.
- Dependencies/assumptions:
- Benchmarks for prompt-induced failure modes; standardized reporting of prompt influence (e.g., gate scaling, ablations); alignment with privacy laws.
- 3D perception and multimodal extensions (sectors: robotics, mapping)
- What: Text-steered perception across RGB-D, LiDAR, or 3D point clouds (“highlight load-bearing beams”, “detect loose cables”).
- Dependencies/assumptions:
- Early-fusion designs for 3D encoders; joint training with suitable referential grounding datasets; efficient cross-modal attention.
- Active learning and data operations (sectors: MLOps, data labeling services)
- What: Use text prompts to discover underrepresented attributes or edge cases and prioritize labeling; dynamic clustering driven by evolving taxonomies.
- Dependencies/assumptions:
- Human-in-the-loop pipelines; multi-annotator consensus for prompt-defined concepts; dataset governance.
- Robustness to adversarial or incorrect prompts (sectors: all)
- What: Guardrails that detect/mitigate harmful steering or prompt mistakes; uncertainty estimates for prompt-conditioned outputs.
- Dependencies/assumptions:
- Research on prompt plausibility checks, fallback behaviors, and confidence-aware steering; test suites like CORE with negative prompts.
- Generalized “Steerable Perception SDK” (sectors: software platforms)
- What: Standardized, pluggable early-fusion modules and APIs that expose text steering and gate control across ViT backbones for enterprise CV.
- Dependencies/assumptions:
- Broad backbone support, performance profiling, and orchestration with vector DBs and downstream tasks; developer tooling and documentation.
Notes on feasibility across all applications:
- Compute/latency: SteerViT adds ~21M parameters and modest overhead; real-time use may require optimization, batching, or model distillation.
- Prompt quality: Outcomes are sensitive to prompt correctness and specificity; UI affordances and prompt libraries help mitigate.
- Domain shift: Trained on general vision grounding data; specialized domains benefit from adaptation and rigorous evaluation.
- Controllability: The gating factor provides a practical knob to trade steerability vs. pure visual fidelity at inference; may need per-task tuning.
Glossary
- AdamW: A variant of the Adam optimizer that decouples weight decay from gradient updates to improve generalization. "using AdamW with a cosine schedule that warms up to over 5k steps"
- attention heatmaps: Visualizations of attention weights that highlight where a model focuses in an image. "the attention heatmaps and the ground-truth segmentation masks"
- CLS token: A special aggregate token in transformer models used to summarize an entire input sequence (here, an image). "The [CLS]-token of SteerViT was not directly optimized for targeted attention and remains frozen in its original state."
- cosine schedule: A learning rate schedule that follows a cosine curve for smooth decay during training. "using AdamW with a cosine schedule that warms up to over 5k steps"
- cosine similarity: A similarity measure between vectors based on the cosine of the angle between them, commonly used for retrieval. "PODS computes cosine similarities on frozen global features"
- cross-attention: An attention mechanism where queries from one modality attend to keys/values from another modality. "we invert the gated cross-attention (CA) formulation from Flamingo"
- early fusion: Integrating language into visual processing within the visual encoder layers rather than after feature extraction. "we inject text directly into the layers of the visual encoder (early fusion) via lightweight cross-attention."
- element-wise addition: Combining vectors by adding corresponding elements; used here as a simple late fusion strategy. "we fuse visual and text embeddings via post-hoc element-wise addition (late fusion)."
- embedding space: The vector space in which features are represented and organized, enabling similarity and clustering operations. "and how it organizes the embedding space"
- frozen (parameters): Model weights that are kept fixed (not updated) during training. "within frozen ViT blocks"
- gating factor: A scalar control that modulates the strength of injected signals (e.g., cross-attention) into a model. "By modulating a gating factor (\cref{eq:gated_ca}), SteerViT achieves a new Pareto frontier."
- gated cross-attention: Cross-attention whose contribution is controlled by a learnable gate to preserve base representations. "we invert the gated cross-attention (CA) formulation from Flamingo"
- inpainting: Editing images by contextually filling or inserting objects into regions. "and inpaint five objects contextually fitting each scene into each image"
- last-token summary pooling: A pooling strategy that uses the final token’s hidden state as a summarized representation. "we extract prompt-specified vision features by following the last-token summary pooling of E5-V"
- late fusion: Combining visual and textual signals after their encoders have produced separate representations. "most vision-LLMs (e.g., CLIP) fuse text with visual features after encoding (late fusion)"
- linear classifier head: A simple linear layer on top of features to map them to class or mask predictions. "A linear classifier head maps each patch representation to a mask probability"
- linear probing: Evaluating representation quality by training a simple linear classifier on frozen features. "measured by the accuracy of linear probing for the CLS feature"
- Multimodal LLMs (MLLMs): LLMs augmented to process multiple modalities, such as text and images. "Multimodal LLMs can be guided with textual prompts"
- NDCG: Normalized Discounted Cumulative Gain, a ranking metric that emphasizes placing relevant items higher. "we report PR-AUC for classification and NDCG for retrieval."
- one-vs-all retrieval: A retrieval setup where a single positive target is searched among many negatives in a gallery. "We frame the problem as one-vs-all retrieval"
- open-vocabulary (OV) localization: Detecting or segmenting objects described by arbitrary text labels not seen during training. "Open-vocabulary (OV) localization: SAM3"
- out-of-distribution (OOD): Data that departs from the distribution seen during training. "exhibiting zero-shot generalization to out-of-distribution tasks."
- Pareto frontier: The set of models for which no objective (e.g., quality vs. steerability) can be improved without worsening another. "SteerViT achieves a new Pareto frontier."
- Pareto improvement: An improvement where at least one objective gets better without degrading another. "We show that SteerViT achieves a Pareto improvement over prior approaches"
- patch tokens: The tokenized image patches fed into a Vision Transformer. "a ViT produces a sequence of patch tokens"
- PR-AUC: Area under the precision–recall curve, summarizing performance across precision–recall thresholds. "measuring the area under the precision-recall-curve (PR-AUC)"
- referential segmentation: Segmenting image regions referred to by a natural language expression. "We select referential segmentation for this purpose"
- residual stream: The pathway in transformer blocks where residual connections carry and combine representations across layers. "To fuse textual conditioning into the ViT's residual stream"
- RoBERTa-Large: A large pretrained transformer-based text encoder used to produce language embeddings. "We adopt a frozen, pretrained text encoder (RoBERTa-Large"
- semantic segmentation: Dense prediction task assigning a semantic label to each pixel (or patch). "semantic segmentation for patch features"
- soft cross-entropy loss: A variant of cross-entropy that accommodates soft (fractional) targets instead of hard labels. "We adopt the soft cross-entropy loss to train our model"
- steerability: The ability of a representation to adapt its focus based on conditioning (e.g., text prompts). "We posit three desiderata that steerable representations should satisfy: ... Steerability:"
- tanh gate: A gating mechanism that uses the tanh function to modulate the contribution of injected features. "through a tanh gate with a layer-specific learnable scalar"
- token-level embeddings: Vector representations for each token (e.g., words) produced by a text encoder. "to produce token-level embeddings "
- UMAP: Uniform Manifold Approximation and Projection, a nonlinear dimensionality reduction method for visualization. "via UMAP~\cite{UMAP}"
- Vision Transformer (ViT): A transformer architecture that processes images as sequences of patch tokens. "Pretrained Vision Transformers (ViTs) such as DINOv2 and MAE"
- zero-shot generalization: Performing a task without task-specific training by leveraging general-purpose learned representations. "exhibiting zero-shot generalization to out-of-distribution tasks."
- patchified: The process of dividing an image into patches aligned to the ViT’s grid. "that is patchified to match the ViT's grid"
Collections
Sign up for free to add this paper to one or more collections.