- The paper demonstrates that carefully engineered prompt ensembles enable open-source LLMs to nearly match frontier models in verifying complex mathematical proofs.
- It employs balanced accuracy and self-consistency metrics across multiple Olympiad-graded datasets to quantify verifier performance.
- Ensemble methods effectively reduce false negatives and variance, underscoring the critical role of inference-time prompt design in reliable proof verification.
Evaluating the Necessity of Frontier Models for Mathematical Proof Verification
Problem Scope and Motivation
The research investigates whether the verification of complex natural language mathematical proofs requires frontier LLMs, given their demonstrated superiority in generating solutions for Olympiad-level problems. Although frontier models (e.g., GPT-5.2, Gemini 3.1 Pro) significantly outperform smaller open-source models in problem solving, verification is often presumed easier than generation, and critical for gaining trust in LLM outputs and improving reasoning pipelines. The study systematically evaluates two frontier and four smaller open-source models (\oss{} and \qwen{} series) across three proof-graded datasets (IMO-GradingBench, ProofArena, ProofBench) using metrics of balanced accuracy and self-consistency. The central question is whether smaller models can reliably verify proofs to the same standard as frontier models, and if deficits can be addressed by inference-time prompt engineering rather than additional post-training or access to proprietary frontier models.
Balanced accuracy and self-consistency are adopted as principal metrics. The datasets encapsulate human-graded natural language proofs of Olympiad-level difficulty, aligning ground truth with binary correctness judgments. Frontier models achieve leading balanced accuracy (Gemini 3.1 Pro: 87.7%), but smaller open-source models are within ∼10% (e.g., Qwen[35B]: 76.6%). However, smaller models lag in self-consistency by up to ∼25%, implying greater variability across repeated runs and higher false negative rates. Prompt choice exerts strong influence: stricter, stepwise prompts (e.g., GIMO) induce rejection bias, while open-ended prompts (IMOBench) incline towards acceptance of flawed proofs. Error bars across three-run averages highlight prompt sensitivity dominating variance.
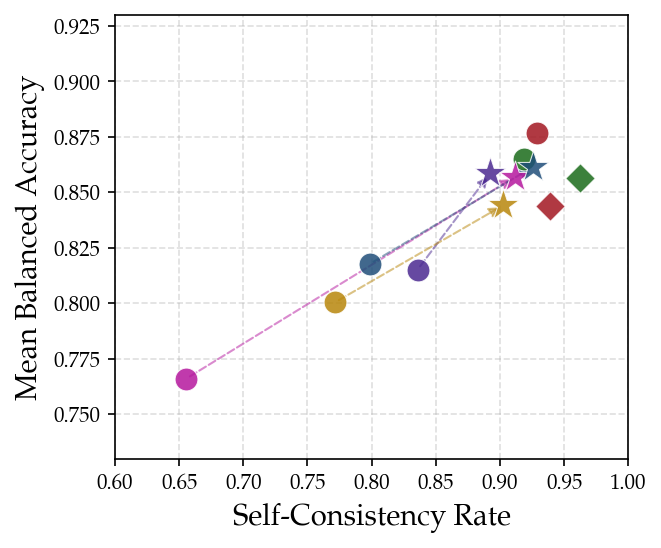
Figure 1: Mean balanced accuracy and self-consistency rates for frontier and open-source LLM judges, illustrating prompt ensemble effects and scale-induced consistency gaps.
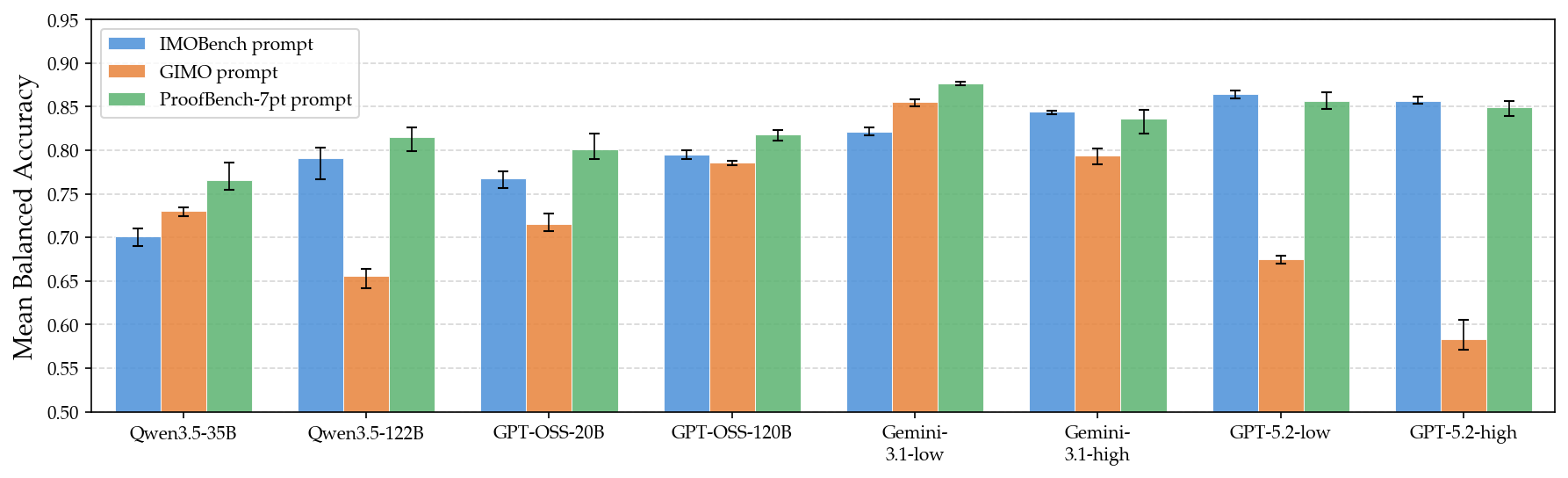
Figure 2: Mean balanced accuracy across models and prompts, showing the relatively small scale-induced gap and prompt-dependent performance.
False positive and false negative rates further articulate the verification dynamics: smaller models are considerably more prone to false negatives, with mean FNR difference of 13.3% versus only 1.1% for FPR. This translates operationally to accepting flawed proofs despite apparent mathematical capacity.
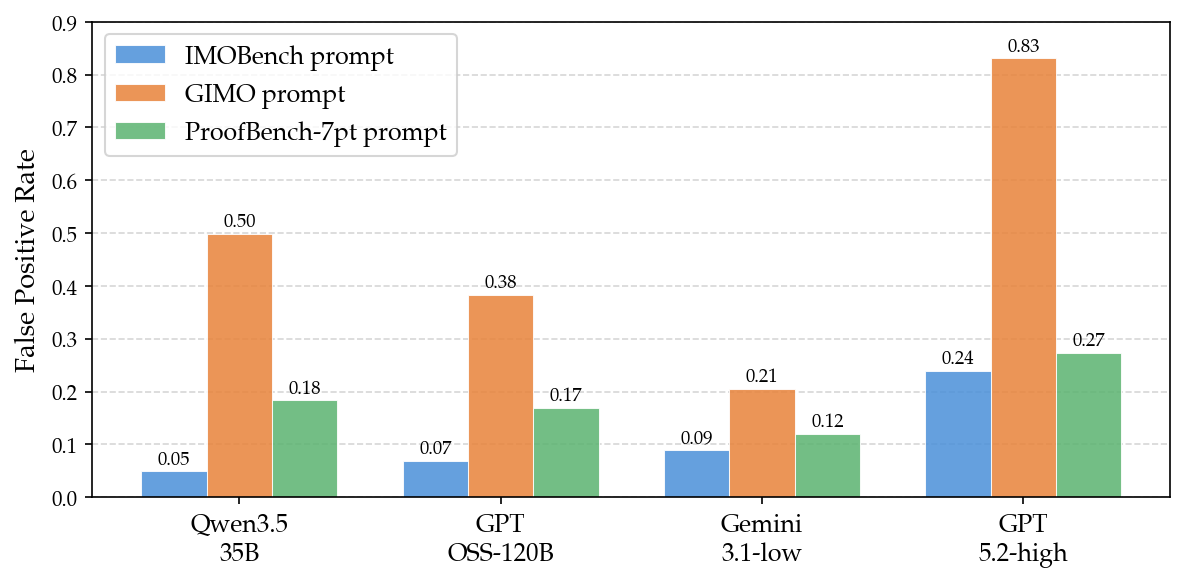
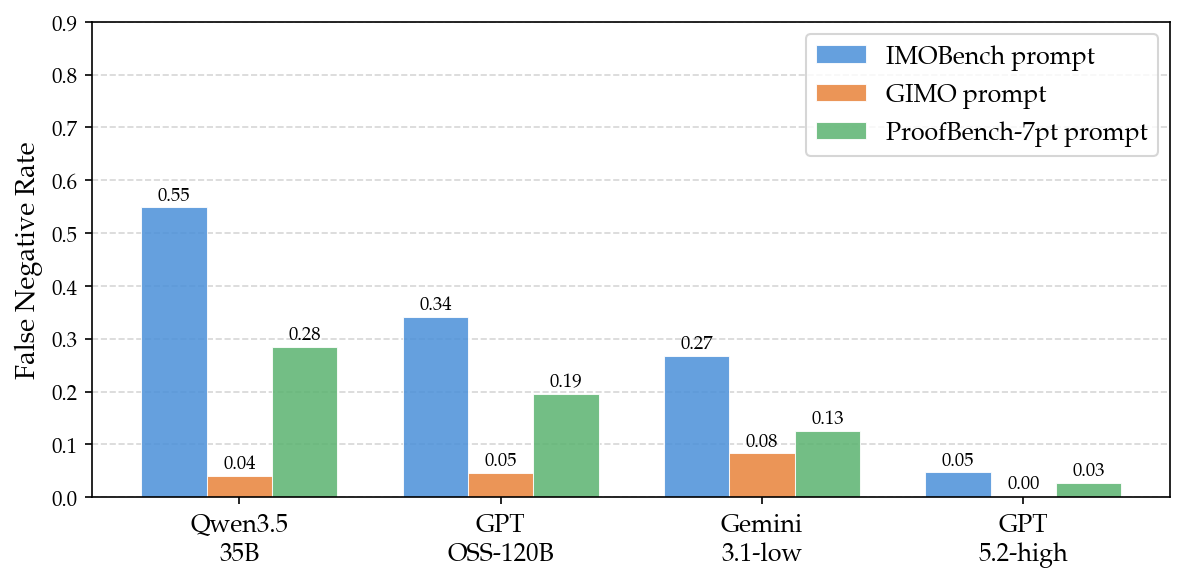
Figure 3: Per-model, per-prompt breakdown of false positive and false negative rates, highlighting open-source verifier tendency towards false negatives.
Qualitative Failure Analysis and Prompt Engineering
To probe the nature of verification failures, the researchers annotated incorrect proofs using LLM-driven error identification, exposing characteristic small model failure modes: verbatim reproduction without deeper logical scrutiny, or unwarranted invention of missing arguments. These are not fundamentally a deficiency in mathematical capacity but stem from insufficient elicitation via general-purpose prompts. Automated prompt search, guided by error annotation, identifies a set of 12 specialized prompts that collectively enable \oss[120B] to catch all but three errors in a balanced evaluation subset. The same prompt set, when applied to other small models (\oss[20B], \qwen[35B]), results in high error agreement rates, supporting the hypothesis that prompt diversity elicits latent verifier capability.
Ensemble Prompting and Aggregation
Building upon the error detection rubric, a prompt ensemble is synthesized — eight distinct verification strategies are run in parallel, and threshold voting is employed for aggregation (≥8/12 "Correct" verdicts required). This ensemble is empirically tuned for high balanced accuracy and reproducibility, with five general grading instances and seven highly specialized prompts targeting stepwise rigor, entailment, theorem application, and domain-specific reasoning (e.g., geometry, number theory). Evaluation across datasets demonstrates marked improvements: balanced accuracy gains up to 9.1%, self-consistency gains up to 15.9%. Ensemble methods consistently outperform repetition or merged-prompt baselines, confirming that prompt diversity, not mere run count, is responsible for robustness.
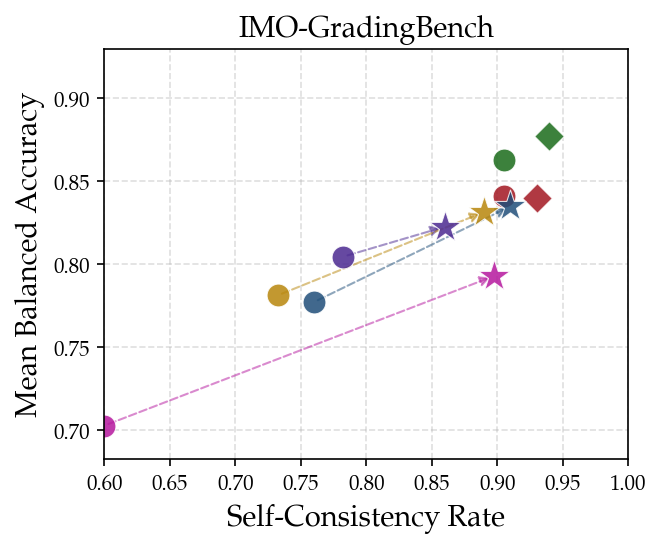
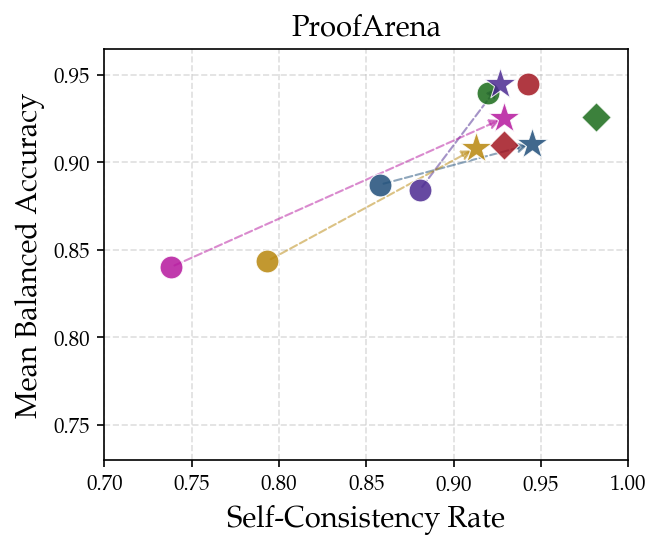
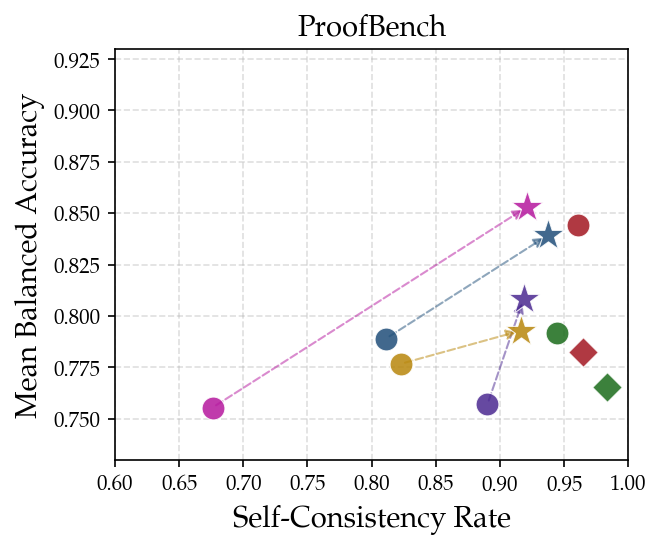
Figure 4: Prompt ensemble performance on three datasets, demonstrating accuracy and self-consistency improvements across multiple models.
Ablation studies show that increasing sample count moderately erodes self-consistency for individual models, but the ensemble's gains hold even with many samples. When grading thresholds are relaxed (accepting 6-point proofs), ensemble methods remain effective though absolute metrics shift. Prompt ensemble results transfer across models and datasets, underscoring the generality of the approach.
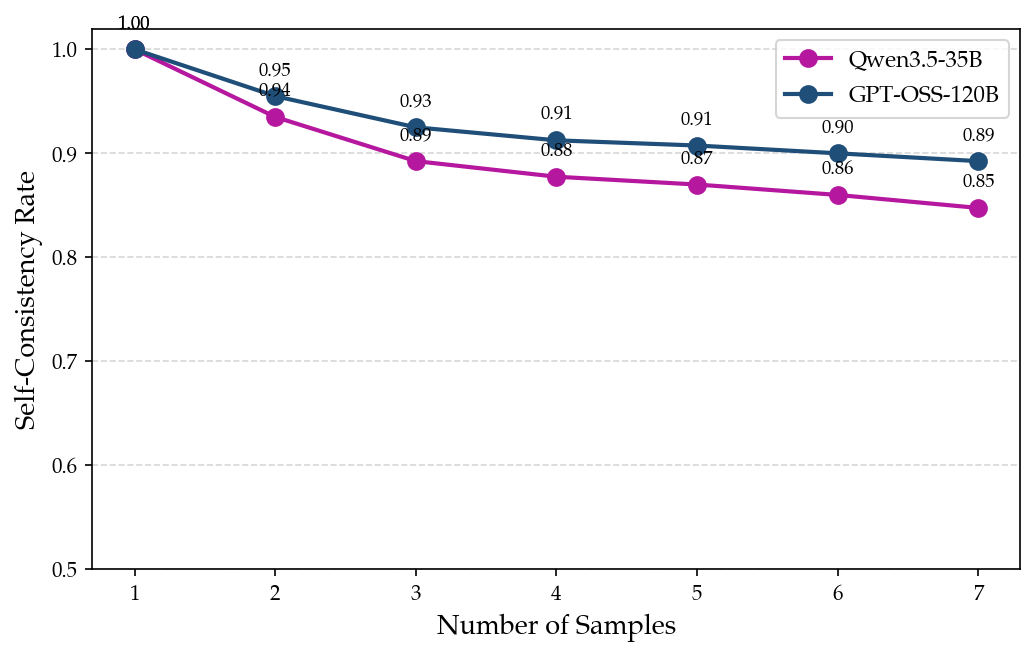
Figure 5: Self-consistency rate decreases as the number of independent judgment samples increases, but ensemble effect persists.
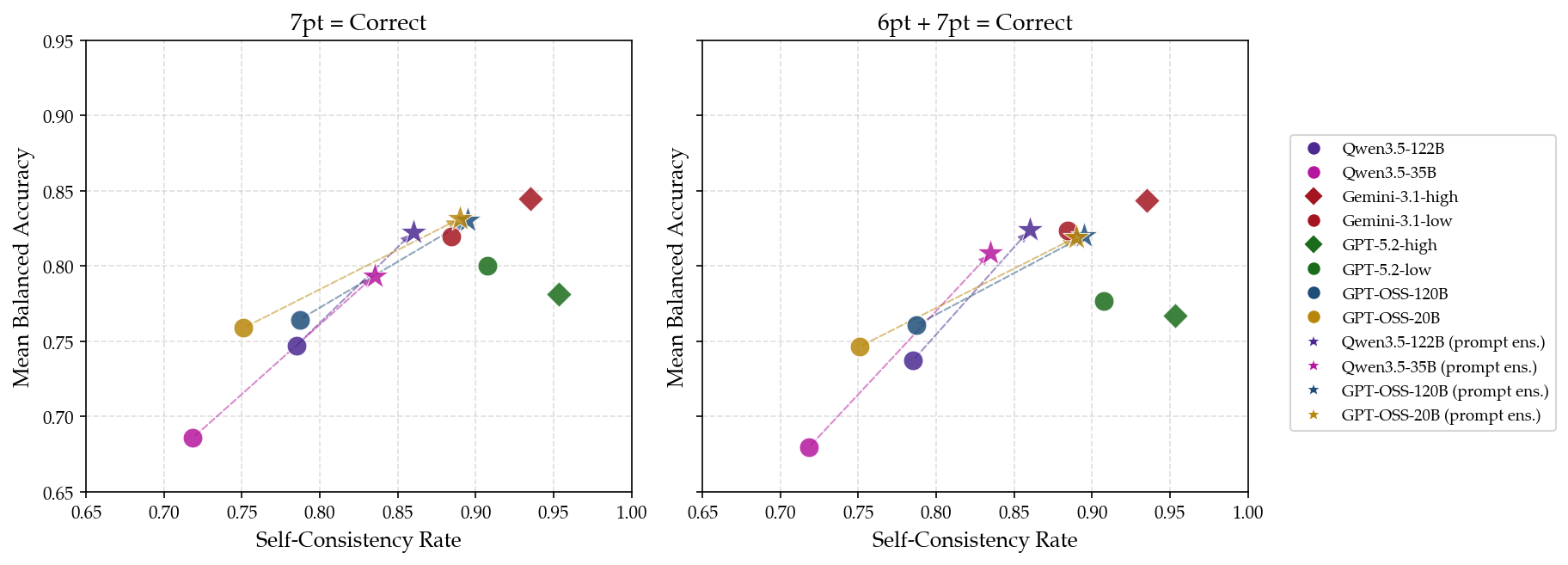
Figure 6: Impact of grading thresholds (7-point vs 6-point) on balanced accuracy and self-consistency.
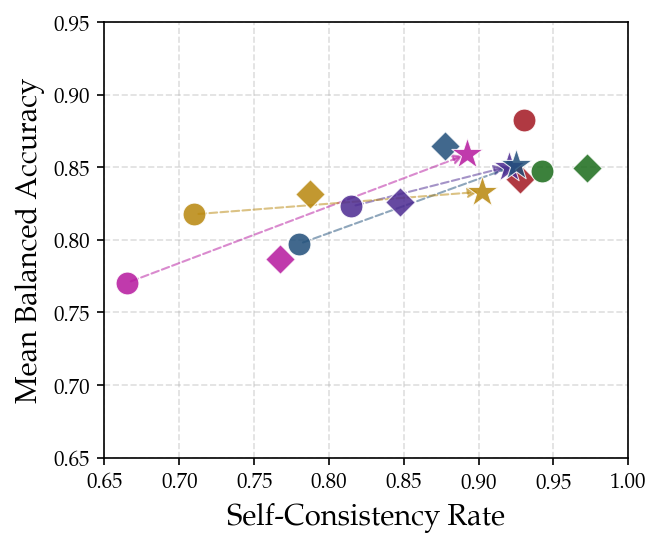
Figure 7: Ensemble benefits for models under high reasoning effort, with prompt ensemble outperforming test-time scaling alone.
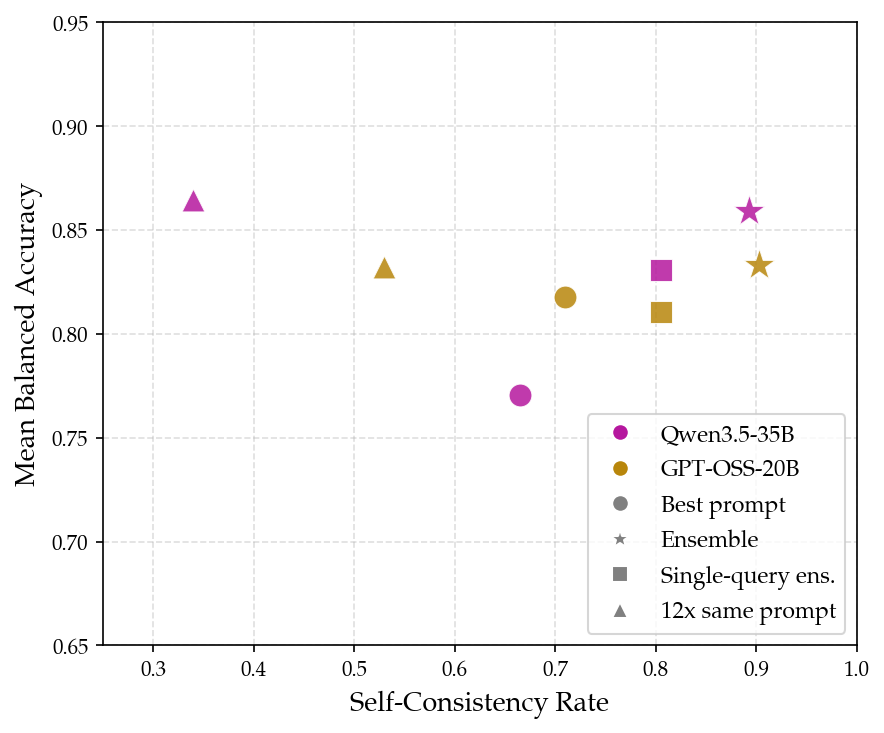
Figure 8: Comparison of ensemble diversity strategies showing full ensemble superiority in accuracy and consistency.
Error Statistics and Ensemble Robustness
Prompt-level analysis reveals a wide spectrum of FPR–FNR trade-offs. Strict prompts sharply reduce FNR but elevate FPR, lenient prompts do the converse, and baseline general prompts have the highest FNR. The ensemble achieves competitive (often lowest) FPR and FNR, rivalling frontier models. The ensemble confers stability by combining less correlated judgments, reducing variance due to prompt repetition.
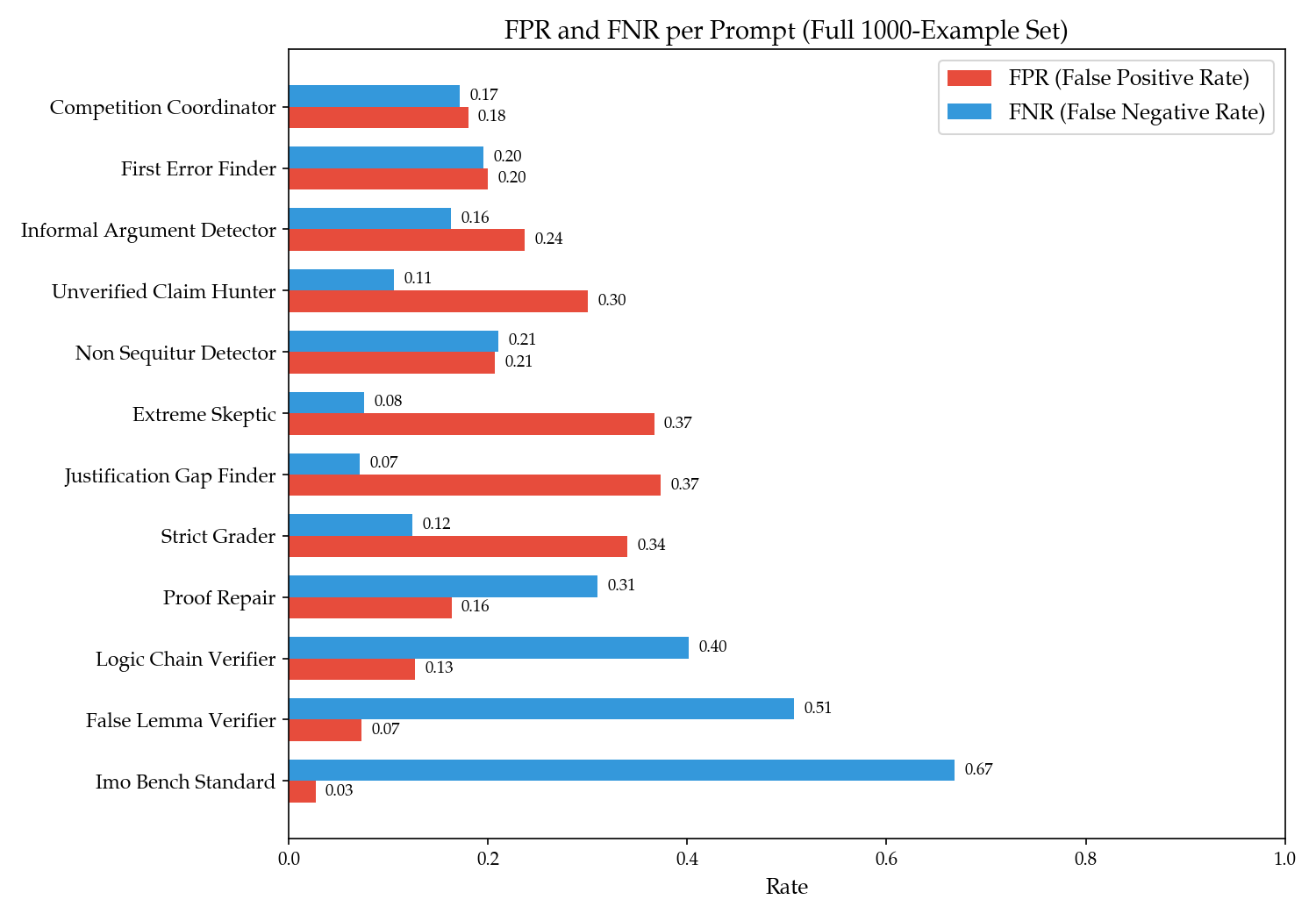
Figure 9: False positive and false negative rates for each error detection prompt, highlighting ensemble trade-offs.
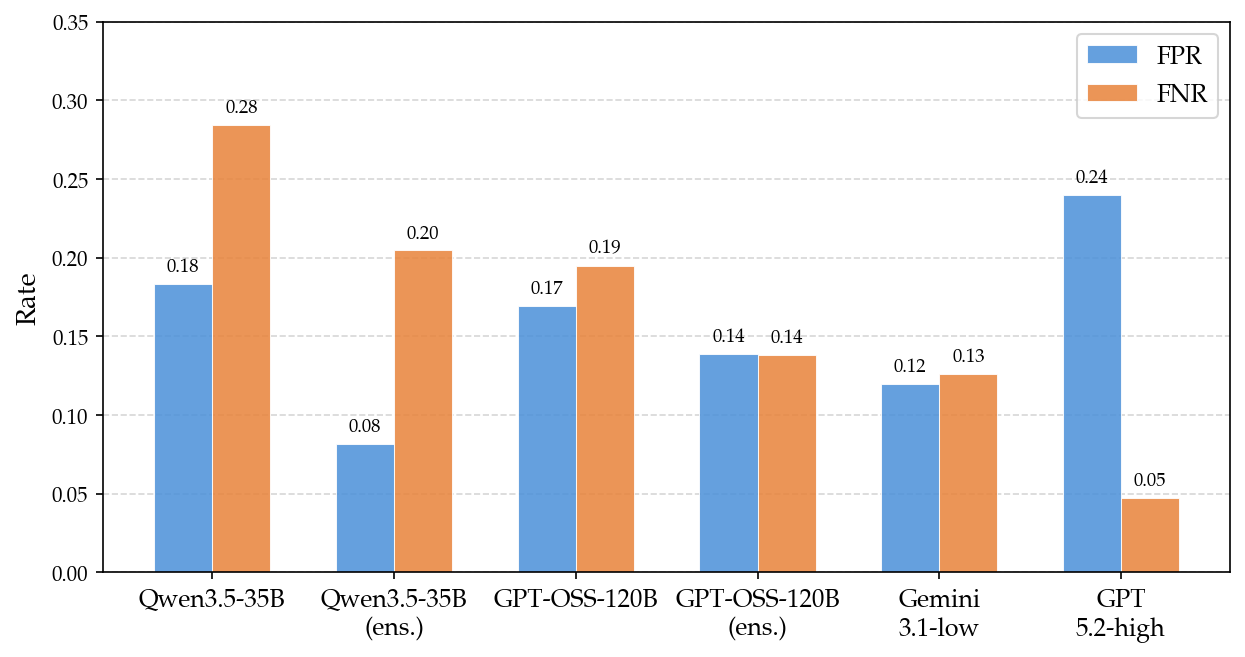
Figure 10: FPR and FNR comparison of ensembled open-source and frontier models; ensemble closes error gap with frontier.
Implications, Limitations, and Future Directions
The findings establish that open-source LLMs, when equipped with carefully engineered prompt ensembles, reach frontier-level verifier performance for natural language mathematical proofs, erasing most scale-induced gaps in balanced accuracy and self-consistency. The key limitation of smaller models is not inherent mathematical reasoning, but reproducible elicitation of that reasoning via appropriate prompts. This shifts the locus of advancement from model scale and post-training to inference-time technique design and prompt engineering.
Practically, this democratizes access to reliable mathematical verification, circumventing proprietary model constraints and compute barriers. Theoretically, it suggests prompt-ensembling techniques can capture transferable verification strategies, potentially generalizable to other domains such as legal or financial reasoning. The approach also informs reward model and post-training design by exposing the critical inference-time failure modes and their remediation.
Limitations include residual errors among frontier models and the dependency on prompt design. Future work is indicated in comprehensive error analysis of frontier verifiers, further transfer studies to adjacent domains, and integration of prompt ensemble methodologies within feedback-driven LLM training pipelines for improved robustness.
Conclusion
The study demonstrates that reliable mathematical proof verification does not require frontier LLMs; smaller open-source models, equipped with prompt ensembles targeting diverse verification strategies, achieve equivalent accuracy and reproducibility. This reduces reliance on large-scale proprietary models for verification tasks, affirms the centrality of inference-time prompt engineering, and extends the applicability of LLMs in mathematical and other reasoning-intensive domains. These insights prompt further research in cross-domain testing and reward model refinement, and suggest practical strategies for scalable and accessible automated verification in scientific contexts.

