- The paper introduces AdaHOP, which adapts Hadamard rotations based on detected outlier patterns in tensors to achieve effective low-precision training.
- It employs a novel outlier extraction method and hardware-optimized kernels, achieving up to 3.6× memory compression and 1.8× speedup.
- Empirical results on Llama3.2-1B and Instella-3B demonstrate training quality nearly matching BF16 precision while significantly reducing compute overhead.
AdaHOP: Outlier-Pattern-Aware Low-Precision Training for LLMs
Introduction and Motivation
Low-precision training (LPT) techniques have become critical for scaling LLMs, enabling significant savings in memory and computational throughput by quantizing both weights and activations. However, extreme values—outliers—frequently appear within LLM tensors and substantially amplify quantization error, especially in aggressive mixed-precision settings (e.g., MXFP4). Prior art typically mitigates outliers by globally applying Hadamard (or other rotation) transforms, without accounting for structural variability in outlier distributions across different tensors and computation paths. This paper introduces AdaHOP, a framework for adaptive, outlier-pattern-aware rotation in LPT. AdaHOP is centered on new empirical and theoretical insights into the spatial structure and temporal stability of outliers in LLMs, leveraging these findings for both algorithmic and hardware-efficient low-precision training.
Outlier Pattern Characterization and Analysis
The authors conduct the first systematic, layer-wise, path-specific analysis of outlier patterns in weights, activations, and gradients of LLMs (Llama3, Instella) during training. Tensors are found to reliably manifest one of three patterns:
- Row-wise outliers: Disproportionately large values concentrated in specific rows (typical for gradients).
- Column-wise outliers: Large values isolated in specific columns (dominant in activations).
- None: Uniform magnitude, lacking pronounced outlier regions (common in weights).
3D tensor visualizations highlight these structures: weights display uniformity, activations exhibit column-wise outliers, and gradients reveal row-wise concentration.

Figure 1: 3D visualization of real LLM tensors; right-sided Hadamard transform attenuates column-wise outliers, while left-sided leaves outlier structure largely unchanged.
An exhaustive pattern-pair analysis across LLM compute paths (Forward, ∇W, ∇X) reveals that not only are these patterns non-random, but their pairwise combinations systematically determine the effectiveness of Hadamard transforms. Notably, the optimal direction for the transform hinges on the orthogonality between smoothing and outlier structures. For instance, Inner Hadamard Transform (IHT) is highly effective only for column-row (CR) pattern pairs; elsewhere, it can be neutral or detrimental.
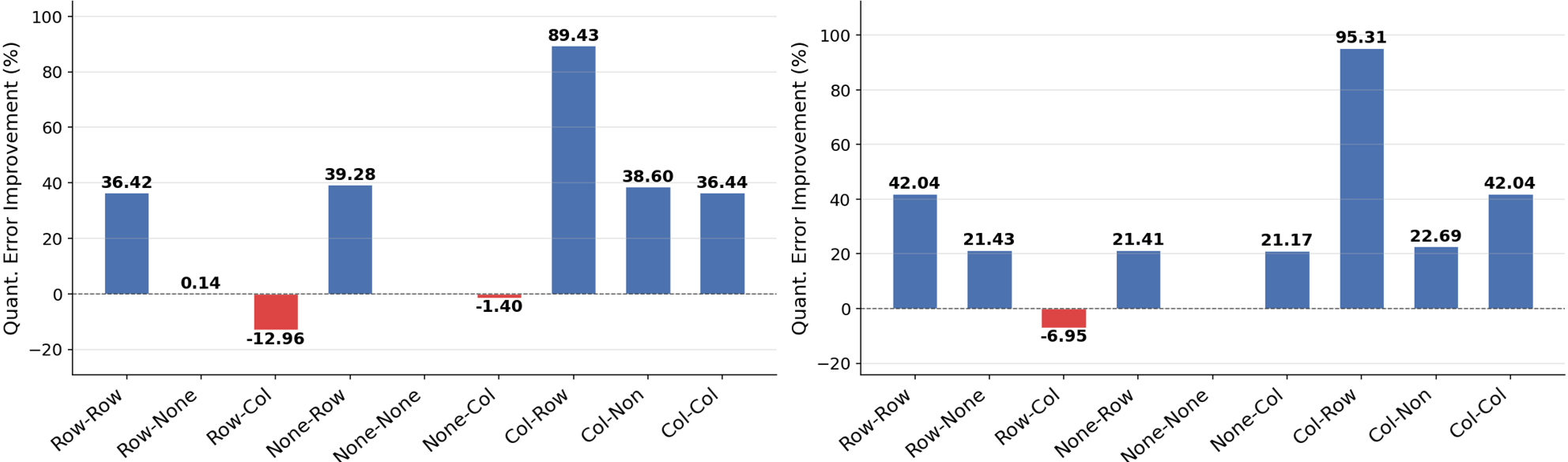
Figure 2: Quantization error improvement for different outlier pattern pairs, demonstrating IHT's selective effectiveness (CR pairs), while hindering others (RC, RR, etc).
Surveying LLM layers, the patterns remain highly stable during training, enabling robust pattern discovery via brief calibration and eliminating the need for dynamic, runtime detection.
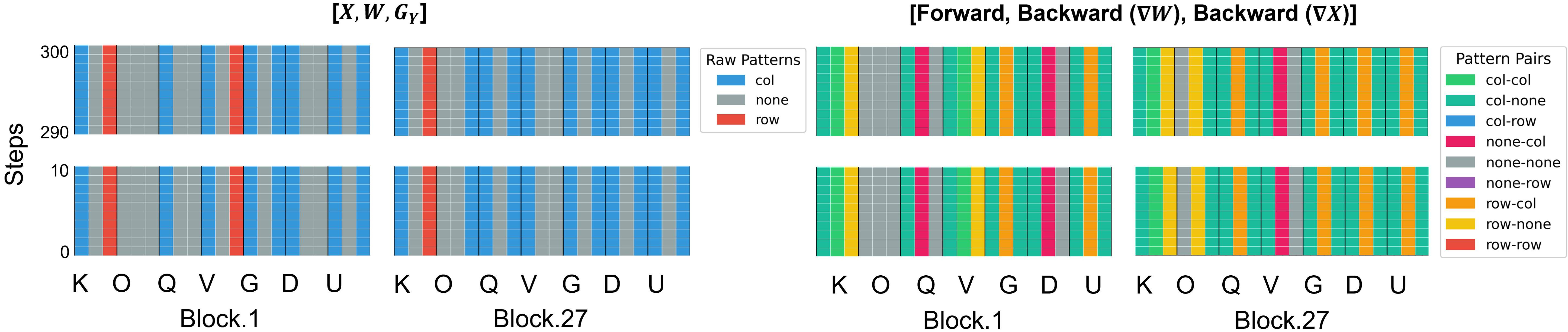
Figure 3: Visualization of detected outlier patterns per layer across 300 training steps; pattern assignments are stable—supporting static calibration.
An extended view (see Figure 4) captures depth-dependent transitions in gradient patterns but confirms temporal persistence, allowing one-time calibration to inform all subsequent training.
Adaptive Strategy: The AdaHOP Framework
AdaHOP operationalizes these empirical findings via a four-component methodology:
- Calibration-based Pattern Detection: A short BF16 “warmup” phase establishes each tensor’s outlier pattern by computing dimension-normalized coefficient of variation (CV), using majority voting for final assignment. This incurs negligible overhead.
- Pattern-Aware Strategy Assignment: AdaHOP assigns to each matrix multiplication the optimal low-precision computation, selecting from three options:
- IHT (when the smoothing direction mitigates outliers: CN/NN pairs)
- IHT with Outlier Extraction (OE) (when dominant outliers resist smoothing: RN, RC, NC, CC)
- High-precision BF16 (for attention-critical or otherwise sensitive pairs in AdaHOP-Lv2)
- Outlier Extraction (OE): Extreme rows/columns are identified and routed to a high-precision computation path, while the remainder is handled by low-precision IHT.
- Hardware-Aware Kernel Implementation: All stages are fused and tile-optimized for AMD CDNA4 GPUs, minimizing data movement and maximizing throughput. OE operates at hardware-motivated granularities (e.g., k=64 for the number of extracted elements).
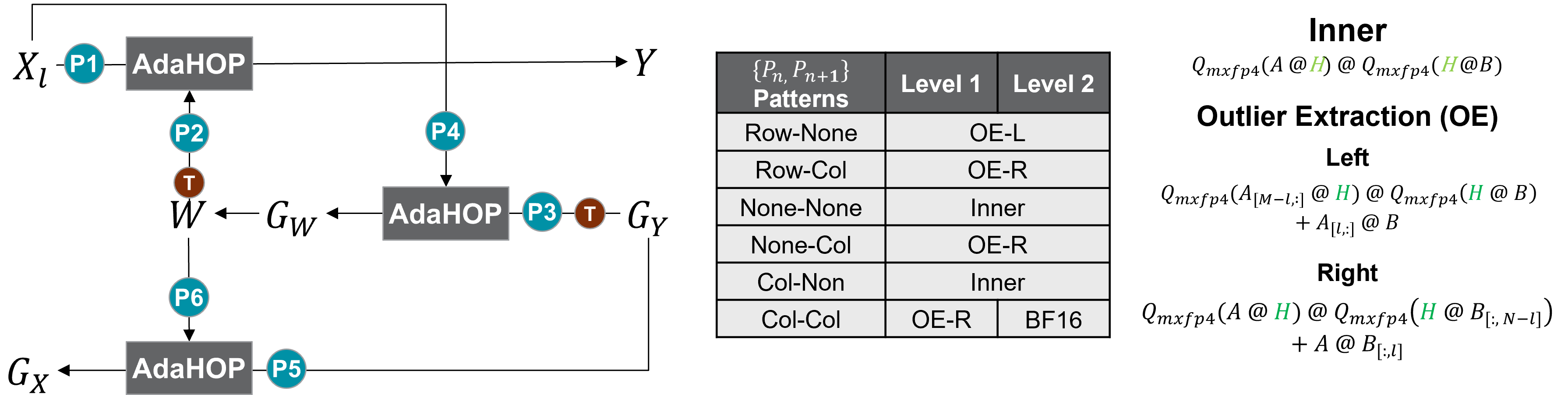
Figure 5: AdaHOP pipeline, dynamically selecting among IHT, OE+IHT, and BF16 based on the current operand pair's detected outlier pattern.
Theoretical Foundation
The theoretical analysis establishes that:
- Transform Efficacy: Hadamard transforms substantially reduce quantization error only when their mixing acts orthogonally to the dominant outlier direction.
- Outlier Extraction Superiority: For extreme outlier cases, routing these components through a separate high-precision path and applying IHT to the residual is provably more effective than any global transform in terms of error scaling.
- Temporal Stability: Once assigned, layer-wise patterns remain constant. Therefore, static assignment generates equivalent benefits to dynamic adaptation but with much lower overhead.
Empirical Results
Numerical results demonstrate that AdaHOP closes the quality gap between full-precision BF16 and aggressive low-precision (MXFP4) training. On both Llama3.2-1B and Instella-3B, AdaHOP’s loss curves are consistently within 0.01 of BF16, outperforming all prior MXFP4 methods both in terms of loss and downstream accuracy.
Figure 6: Training loss curves show AdaHOP's minimal loss gap to BF16 for Llama3.2-1B and Instella-3B.
AdaHOP achieves up to 3.6× memory compression and 1.8× kernel-level speedup over BF16, with negligible quality regression on diverse downstream tasks (LAMBADA, HellaSwag, ARC-Easy, PIQA).
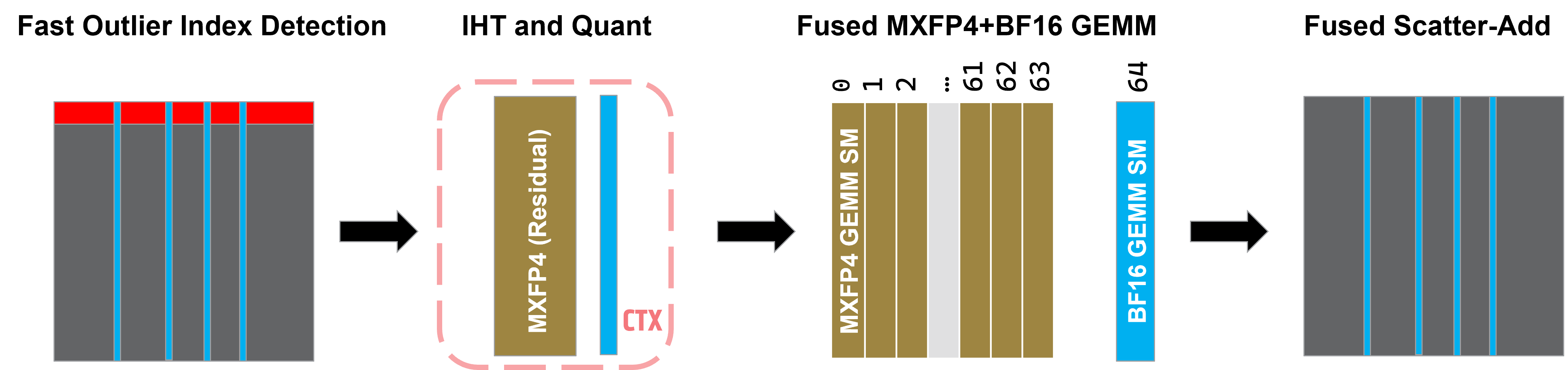
Figure 7: Hardware-aware AdaHOP implementation: FOID, IHT+Quant, fused MXFP4+BF16 GEMM, and fused scatter-add achieve efficient concurrent high/low-precision computation.
The hardware-optimized Triton kernels ensure that OE and fused mixed-precision GEMS are executed with minimal extra latency over baseline low-precision computation, and overall training throughput is competitive with or superior to baseline approaches.
Broader Implications and Future Directions
AdaHOP advances LPT theory and practice by showing that outlier pattern diversity—not previously accounted for in LPT—is an underexploited axis for accuracy-preserving efficiency gains. Practically, AdaHOP enables stable, nearly lossless training of LLMs using aggressive quantization formats, unlocking significant memory and compute savings. Theoretically, the pattern-centric view is likely to generalize to other architectures and emerging hardware formats.
Future work suggested by the authors includes extending AdaHOP to integrate learned, layer-specific rotation matrices, as well as validating and refining the approach on family-diverse LLMs (e.g., Mixtral, Gemma architectures) and additional quantization formats. Adaptive or learnable selection of OE granularity (e.g., dynamic adjustment of k per layer) could further improve the efficiency-accuracy trade-off.
Conclusion
AdaHOP establishes that outlier patterns in LLM training are structured, persistent, and amenable to static calibration, contradicting prevalent uniform-transform practices in prior low-precision frameworks. By aligning the Hadamard transform direction and outlier extraction strategy with operand-specific pattern pairs, AdaHOP delivers BF16-equivalent training quality at substantially reduced precision, memory, and compute overheads. Its design and successful hardware realization mark a substantive advance in the deployment of efficient, scalable LPT for future generations of large neural models.