- The paper introduces LT-ADMM-DP, a method that combines localized updates with privatized gradient mechanisms for efficient nonconvex optimization.
- It leverages gradient clipping and Gaussian noise within an ADMM framework to maintain rigorous differential privacy while reducing communication rounds.
- Theoretical and empirical analyses validate faster convergence and explicit privacy-accuracy trade-offs in decentralized learning.
Communication-Efficient Distributed Learning with Differential Privacy: An Expert Overview
Motivation and Context
Distributed learning in decentralized settings poses inherent challenges, notably the tension between minimizing communication overhead and providing rigorous differential privacy (DP) guarantees for agents' private data. Existing approaches often involve a trade-off between communication efficiency and the statistical indistinguishability central to DP. The paper "Communication-Efficient Distributed Learning with Differential Privacy" (2604.02558) addresses this gap by proposing a unified framework for nonconvex distributed optimization that ensures both properties.
The framework considers a network G=(V,E) of N agents, each holding local data with losses fi(x) and objectives
xi∀imin N1i=1∑Nfi(xi)s.t. x1=x2=...=xN,
where the equality constraint enforces consensus on the model parameters. The assumptions include L-smooth local costs, bounded gradient variation (accounting for data heterogeneity), and network connectivity. Differential privacy is pursued at the level of adjacent mini-batches in local stochastic gradient computations.
Algorithmic Contributions: LT-ADMM-DP
The proposed Local Training ADMM with Differential Privacy (LT-ADMM-DP) integrates recent advances in communication-efficient distributed optimization with state-of-the-art privacy-preserving mechanisms. The method is characterized by a threefold innovation:
- Local Training to Reduce Communication: Agents execute τ steps of local stochastic updates before exchanging information, throttling the number of expensive communication rounds.
- Gradient Clipping and Gaussian Noise: To enforce DP, local gradients are clipped (to a threshold ζ) and perturbed with zero-mean Gaussian noise (N(0,σe2I)). This mechanism bounds the ℓ2-sensitivity and harmonizes with Rényi DP analysis.
- Coupling via ADMM Bridge Variables: Consensus is achieved through an augmented Lagrangian dual variable update, facilitating efficient decentralized coordination and leveraging the algebraic connectivity of the underlying communication graph.
Theoretical Analysis
Convergence Guarantees
The algorithm is shown to converge to a stationary point of the nonconvex problem within a bounded neighborhood. The primary result establishes that the expected optimality error, as a function of the number of global iterations K and algorithmic parameters N0, satisfies
N1
highlighting the trade-off: increasing step size or local iteration count (N2) accelerates convergence but increases asymptotic error, with N3 (noise variance) directly controlling the privacy-accuracy frontier.
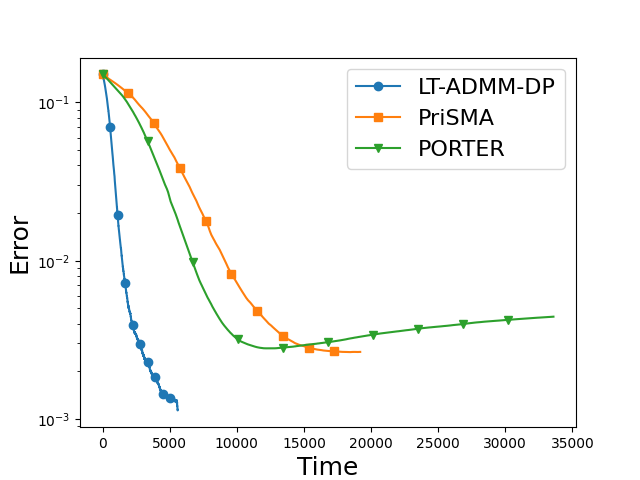
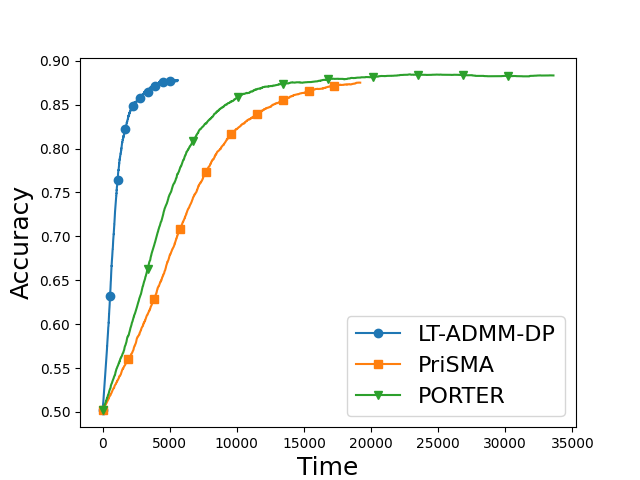
Figure 1: Errors N4 for LT-ADMM-DP and baselines, illustrating improved convergence rates and smaller stationary error for a matched privacy budget.
Differential Privacy Guarantees
The DP analysis employs the Rényi DP (RDP) framework to achieve tight accounting under composition. The per-agent DP guarantee is quantitatively characterized as
N5
where N6 is the number of rounds, N7 is local steps per round, and N8 and N9 denote mini-batch and dataset sizes, respectively. This analytical form elucidates the trade-off between privacy (smaller fi(x)0), noise magnitude fi(x)1, and sample complexity.
Empirical Validation
The algorithm's superior empirical performance is demonstrated on a nonconvex regularized logistic regression task, compared against PORTER [li2025convergence] and PriSMA [huang2025differential], both under a fixed privacy budget fi(x)2. Evaluation on a ring network of fi(x)3 shows that LT-ADMM-DP achieves faster convergence in terms of wall-clock complexity and superior final accuracy than both baselines, while satisfying strict DP constraints. The simulation accounts for both local computation and communication cost.
Implications and Future Directions
This work rigorously demonstrates that communication efficiency and nontrivial DP guarantees can be achieved simultaneously for nonconvex decentralized learning by combining local update batching and privatized gradients within an augmented Lagrangian optimization framework. The main theoretical implications include:
- Scalability with Network Topology: Convergence bounds scale with the network's algebraic connectivity; sparser graphs necessitate finer-tuned step sizes.
- Explicit Privacy-Accuracy-Cost Trade-off: The analytical results tightly connect the privacy budget, model utility, and system-level resource constraints, informing principled hyperparameter selection.
- Applicability Beyond Strong Convexity: Guarantees hold under fi(x)4-smoothness and bounded heterogeneity, removing the need for global convexity.
Looking forward, potential research avenues include:
- Adaptive or dynamic gradient clipping (as in [fukami2025adaptive, wei2025dc]) to minimize information loss while maximizing privacy.
- Extensions to heterogeneous data distributions and time-varying topology.
- Asynchronous or partially participated update architectures for additional robustness.
Conclusion
The proposed LT-ADMM-DP framework establishes a new benchmark for distributed learning algorithms that are simultaneously communication-efficient and rigorously differentially private for nonconvex objectives (2604.02558). The method achieves strong numerical and theoretical performance, and provides explicit design trade-offs between efficiency, accuracy, and privacy budgets. The approach is well-positioned for practical deployment in federated settings where both communication overhead and data confidentiality are paramount.