- The paper introduces DEMASK, a novel method that uses a dependency predictor to identify weakly dependent tokens for parallel decoding in dLLMs.
- It employs a greedy subset selection algorithm and theoretical TV bounds to limit output divergence while significantly accelerating generation.
- Empirical evaluations on Dream-7B demonstrate a 1.7–2.2× speedup with improved accuracy, validating both the efficiency and the sub-additivity assumption.
Dependency-Guided Parallel Decoding in Discrete Diffusion LLMs
Discrete diffusion LLMs (dLLMs) utilize iterative denoising of masked sequences and allow bidirectional attention, diverging from sequential autoregressive decoding. The principal advantage is parallel decoding: multiple tokens can be unmasked in each step, dramatically increasing throughput. However, parallel sampling introduces a distributional mismatch; instead of drawing from the model's true joint conditional, it approximates with a fully factorized product of per-token marginals, degrading output quality in the presence of strong inter-token dependencies. Empirically, sampling marginals in tasks like arithmetic ("1+□=□") yields inconsistent sequences due to the lack of mutual conditioning.
The objective of this work is to accelerate dLLM generation by paralleling token sampling, while strictly bounding the deviation from true joint inference. The core insight is that when masked positions are approximately conditionally independent, the joint-marginal gap is negligible, and they can be unmasked simultaneously. Therefore, a method is needed to identify subsets of masked positions exhibiting weak dependencies to optimize the accuracy–efficiency trade-off.
DEMASK: Methodology and Theoretical Guarantees
DEMASK introduces a lightweight dependency predictor, trained to estimate pairwise conditional influences between masked positions from hidden states in a single forward pass. These pairwise scores are used by a greedy subset selection algorithm: starting from a left-to-right bias, candidates with high top-1 confidence are filtered, and among these, those minimizing aggregate dependency are greedily added to a parallel sampling batch until a cumulative threshold τ is exceeded.
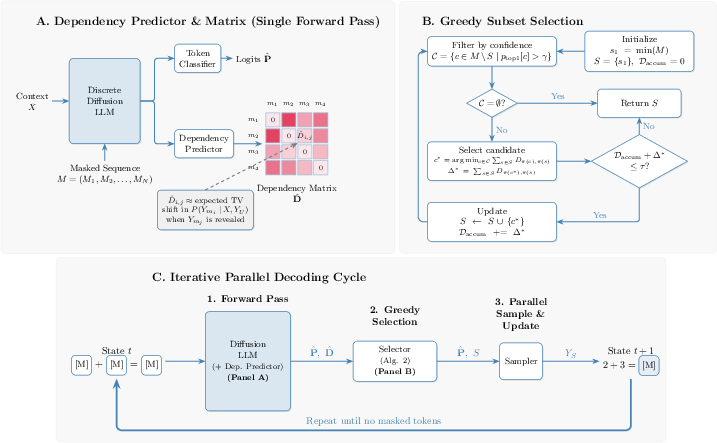
Figure 1: Overview of DEMASK. (A) Dependency predictor estimates pairwise dependencies from hidden states. (B) Greedy subset selection ensures parallel unmasking within TV distance bounds. (C) Iterative decoding cycle accelerates inference.
DEMASK's theoretical foundation consists of a sub-additivity assumption: the cumulative dependency on a token's history is upper-bounded by the sum of its pairwise dependencies. This yields a rigorous upper bound on the total variation (TV) distance between the true joint and the factorized approximation for the selected batch, directly limiting the probability of output divergence under maximal coupling. Scalably, the dependency predictor uses a Q/K-style attention mechanism with sigmoid normalization, projecting hidden states to predict non-symmetric pairwise TV distances.
The dependency predictor is trained in a two-phase pipeline: (i) explicit TV cache generation via forward passes with sampled masks, (ii) MSE minimization vs. cached ground truth, ensuring unbiased estimation of conditional dependency means.
Empirical Evaluation: Efficiency, Accuracy, and Sub-Additivity Validation
DEMASK is evaluated on Dream-7B, a 7B-parameter dLLM. Compared against entropy-based (Dream baseline), top-1 confidence, token-order, and KLASS, DEMASK dominates the Pareto frontier of accuracy vs. mean diffusion steps across diverse tasks including MMLU-Pro (reasoning), GSM8K (math), HumanEval and MBPP (coding).
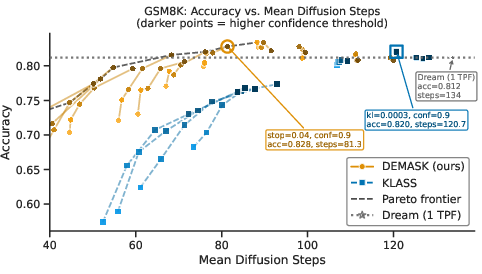
Figure 2: DEMASK consistently outperforms KLASS in the accuracy vs. mean diffusion steps trade-off, demonstrating superior efficiency across GSM8K configurations.
DEMASK achieves a 1.7–2.2× speedup with matching or improved accuracy over baselines. Specifically, accuracy on MMLU-Pro increases by 3.6 percentage points over entropy-based sequential decoding, with an average speedup of 1.9× across main benchmarks. Critically, parallelism-induced accuracy drops observed in all baselines are substantially mitigated; dependency-aware selection maintains output quality with increased batch size.
The validity of the sub-additivity assumption—the theoretical crux for bounding TV distance—is empirically confirmed: the CDF of dependency slack on Tulu 3 SFT Mixture demonstrates rare violations (<6%) and positive slack increasing with subset size.
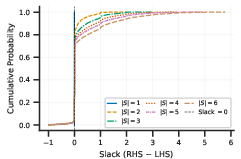
Figure 3: Empirical CDF of the slack between cumulative pairwise and joint influence, supporting the sub-additivity assumption across subset sizes.
Practical and Theoretical Implications
DEMASK's architecture is backbone-agnostic and requires only masked hidden states, enabling extension to other dLLMs (e.g., LLaDA, LLaDA 2.0). The dependency predictor is efficient (∼26M parameters), and its decoupled training facilitates rapid adaptation for new architectures. The method's theoretical TV bound, operationalized via maximal coupling, provides a probabilistic guarantee on the fidelity of parallel decoding outputs, representing a robust control mechanism for diffusion model inference.
Practically, DEMASK delivers improvements in both speed and output consistency for high-throughput applications, particularly in scenarios requiring multi-token reasoning or code generation where conditional dependencies are non-trivial. The dependency-guided approach can be hybridized with remasking strategies and more sophisticated selectors (e.g., adaptive thresholds, deeper networks) to further optimize the accuracy–efficiency Pareto front.
Limitations and Future Directions
DEMASK's guarantees hinge on the empirical validity of the sub-additivity assumption and the predictor's accuracy. While violations are rare and have not translated into significant downstream performance drops, formal characterization of the relationship between approximation error and output quality remains open.
Extension to new diffusion backbone architectures will require TV cache regeneration and predictor training on those models. Additionally, more expressive dependency predictors (e.g., multi-head, deeper layers) may improve dependency estimation fidelity, at a potential computational cost.
Further theoretical refinement could relax the dependence on sub-additivity and yield tighter bounds. Exploring adaptive τ/γ adjustment based on generation progress or domain-specific characteristics may provide dynamic accuracy–efficiency balancing.
Conclusion
DEMASK offers a mathematically principled, empirically validated mechanism for dependency-guided parallel decoding in dLLMs, achieving substantial inference speedups without sacrificing accuracy. The approach unifies efficient batching with distributional guarantees, and its flexibility paves the way for practical deployment in diverse generative NLP tasks and scalable architectures.