- The paper demonstrates that scaling in-context examples yields log-linear improvements in low-resource MT, with proprietary models showing up to 2x gains.
- It reveals that BM25-based demonstration selection achieves similar performance with fewer examples, drastically reducing inference costs.
- The study finds that demonstration ordering has minimal impact while highlighting the critical role of domain-aligned data.
Many-Shot In-Context Learning for Low-Resource Machine Translation: Large-Scale Empirical Analysis and Practical Implications
Introduction
This paper presents a systematic evaluation of many-shot in-context learning (ICL) paradigms for machine translation (MT) into ten extremely low-resource languages (LRLs), leveraging four state-of-the-art LLMs. It empirically addresses the efficacy of increasing demonstration set sizes (up to 1,000 examples), various example selection strategies, domain effects, and the role of instance ordering in prompt construction. The study focuses exclusively on recent benchmark additions to FLORES+, incorporating typologically, morphologically, and orthographically diverse LRLs, with extensive evaluation in both directions (English→LRL and LRL→English).
Scaling Properties of Many-Shot ICL in LRL MT
The main finding is strong log-linear improvement in translation quality as the number of in-context examples increases, particularly when translating from English into LRLs. Proprietary models (Gemini 2.5 Flash, GPT-4.1) exhibit robust scaling, with relative gains up to 2x (chrF++ delta exceeding +35 for specific languages) between zero-shot and 1,000-shot settings, confirming that increased context utilization is an effective adaptation mechanism when standard parameter updates (fine-tuning) are not viable due to data scarcity.
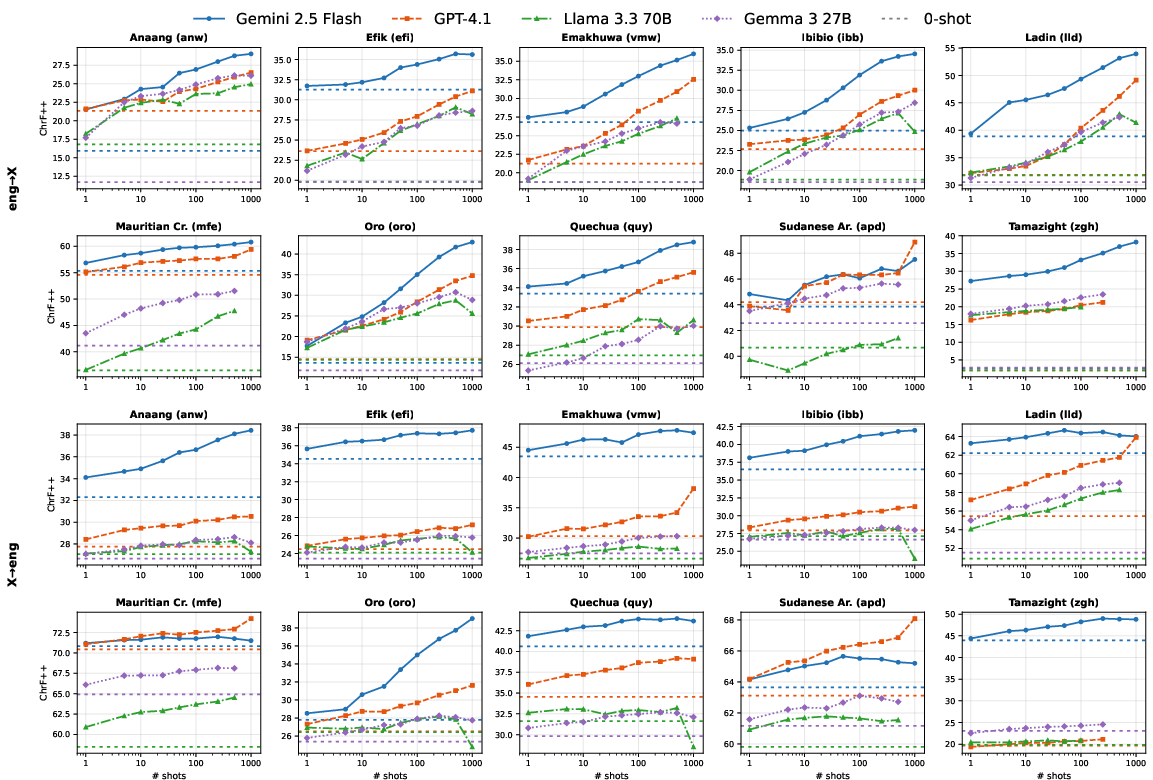
Figure 1: Per-language scaling curves (chrF++, random selection) for both translation directions, showing consistent gains with increased shots, especially for English→LRL.
Notably, the scaling trend is less consistent for LRL→English compared to English→LRL. Some language pairs (e.g., Sudanese Arabic and Mauritian Creole) show subdued improvements, potentially due to interference from related high-resource varieties and lack of sufficient orthographic representation in pretraining. Furthermore, open-weight models (Gemma 3 27B, Llama 3.3 70B) frequently fail at the largest context sizes due to attention window limits and reduced long-context modeling competence; for these models, 250–500 shots saturate performance, with marginal or even negative returns at 1,000 examples.
Demonstration Selection: Retrieval-Based Methods and Cost-Efficiency
A central empirical contribution is the quantitative analysis of demonstration selection strategies. BM25-based retrieval on the English side consistently outperforms random selection, especially for smaller shot values. The sample efficiency is substantially increased: 50 BM25-retrieved in-domain examples achieve approximately the same average performance as 250 randomly selected ones, and 250 BM25-retrieved examples are competitive with 1,000-shot random selection, reducing inference cost by a factor of 4x.
This sample efficiency advantage holds across nearly all language pairs; only at the largest context sizes does the gap narrow to negligible levels, as context saturation begins to dominate. These results indicate a strong empirical prior—demonstration informativeness and source-target similarity correlate directly with translation quality, confirming and extending findings from high-resource scenarios to the LRL extremal regime.
Domain Sensitivity: In-Domain vs. Out-of-Domain Scale Effects
The study robustly demonstrates that the domain of in-context examples critically impacts many-shot ICL scaling. In all cases where in-domain (Wikipedia) data is compared to BM25-retrieved Bible examples (out-of-domain), performance with Bible data plateaus or degrades with increasing shot counts, whereas Wikipedia examples maintain a positive scaling trend.
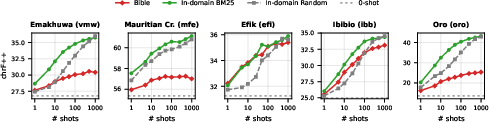
Figure 2: Bible vs. in-domain examples (chrF++, English→LRL, Gemini 2.5 Flash)—in-domain scales linearly, Bible data saturates or declines beyond 25 shots.
Despite overall lower utility, for a subset of languages (notably Efik and Ibibio) Bible data provides competitive improvements at low shot counts, reflecting some domain overlap and typological alignment. This suggests that when in-domain parallel data is truly absent, high-coverage out-of-domain resources can provide modest, short-term gains.
Demonstration Ordering and Retrieval Variants
The authors systematically investigate the effect of prompt ordering (by sentence length, similarity, and combined length) and retrieval strategies (BM25, dense retrieval) on translation performance. The results indicate that demonstration order—whether short-to-long, long-to-short, or random—is inconsequential for many-shot settings, with no statistically meaningful differences among permutations.
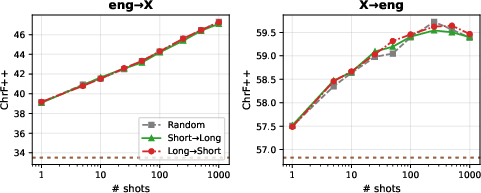
Figure 3: Effect of example ordering on translation quality (chrF++, Gemini 2.5 Flash, averaged across five LRLs), confirming negligible impact.
Ordering by semantic proximity, as opposed to simple BM25 ranking, also fails to yield consistent improvements. These findings imply that, in contrast to the strong order effects noted in few-shot settings, high-shot ICL for translation is relatively robust to ordering perturbations—further supporting the predominance of demonstration selection and scale.
Comparative Model Behavior
Across all evaluated directions and scaling conditions, proprietary LLMs consistently surpass open-weight alternatives for LRL MT, with the performance gap exacerbated at larger context sizes. Inconsistencies and context fragmentation in Gemma and Llama models highlight ongoing deficiencies in the long-context utilization and cross-lingual generalization of open-weight architectures, even when provided with many high-quality demonstrations.
Practical and Theoretical Implications
The strong data efficiency of retrieval-augmented many-shot ICL, combined with log-linear quality scaling, underscores a concrete pathway for boosting LLM coverage of extremely LRLs absent advanced fine-tuning pipelines or language-specific adaptations. It also implicates cost constraints as the primary bottleneck for practitioners, given that large-scale LLM inference remains economically inaccessible to most LRL communities (experiments exceeded \$30,000 in API credits).
On the theoretical front, the negligible effects of order and the magnitude of domain drift contra-indicate some leading hypotheses regarding example sequencing for ICL and highlight the criticality of domain-aligned parallel corpora for all scaling regimes. The fact that open-weight LLMs remain inferior in this regime suggests continued overfitting of pretraining objectives to high-resource languages and the necessity of architecture and curriculum changes for more inclusive multilingual models.
Future outlook
Given these results, future work should prioritize:
- Transfer and augmentation mechanisms (e.g., back-translation, explicit grammar cues, code-augmented grammar rules [(2604.02596), 2025.acl-long.202]) to mitigate the total lack of in-domain parallel data.
- Scaling dataset curation and public release for extreme LRLs to facilitate reproducibility and equitable research.
- Architectural adjustments for open-source LLMs to support context windows commensurate with many-shot ICL requirements and high-quality parameter-efficient adaptation for rare scripts.
- Incorporation of embedding-based MT evaluation metrics and human assessment, as automatic metrics remain unreliable for some typologically distant languages.
Conclusion
This paper provides a rigorous empirical foundation for many-shot ICL in LRL MT, with large-scale evidence for the critical role of carefully selected demonstrations, demonstration scale, and source-domain alignment. It establishes new best practices for scaling translation quality under severe data and resource constraints, and elucidates the main limitations and cost bottlenecks obstructing further progress. The findings strongly motivate further research on efficient retrieval methods, data augmentation techniques, and more inclusive LLM pretraining regimes for the expansion of high-fidelity MT to the full spectrum of linguistic diversity.
References
- "An Empirical Study of Many-Shot In-Context Learning for Machine Translation of Low-Resource Languages" (2604.02596)
- "Read it in Two Steps: Translating Extremely Low-Resource Languages with Code-Augmented Grammar Books" [2025.acl-long.202]
- "A Benchmark for Learning to Translate a New Language from One Grammar Book" [tanzer2024a]
- "Few-shot Learning with Multilingual Generative LLMs" [2022.emnlp-main.616]
- "A Survey on In-context Learning" [2024.emnlp-main.64]

