- The paper introduces intrinsic-relational routing that systematically distinguishes node attributes from traversable edges to promote reusable, ontology-centric schemas.
- It deploys an LLM-guided, iterative refinement process, achieving 93.3% category coverage and effective modular rule-based schema design on a Wikidata core set.
- Empirical results demonstrate a 2.4-point macro accuracy gain in entity disambiguation and robust audit performance compared to traditional taxonomies.
OntoKG: Ontology-Oriented Knowledge Graph Construction with Intrinsic-Relational Routing
Introduction and Motivation
OntoKG addresses a persistent challenge in the construction of large-scale knowledge graphs: the lack of explicit, reusable, and ontology-driven schemas. Traditional approaches, such as those embodied by DBpedia and YAGO, primarily focus on type alignment and often entangle schema formation with ad hoc construction pipelines. LLM-driven pipelines, while automating extraction at scale, exacerbate schema inconsistency—resulting in non-reusable and opaque type/relation taxonomies.
The central thesis of OntoKG is to place schema engineering at the heart of graph construction, treating the declarative schema itself as a reusable, portable, and semantically valuable artifact. The core methodological innovation is "intrinsic-relational routing": the systematic, rule-based assignment of properties as either intrinsic (node attributes, facilitating tabular lookups) or relational (traversable edges, forming the graph topology), tightly coupled to an explicit schema modularization.
Methodology: Intrinsic-Relational Routing and Schema Engineering
At the methodological level, OntoKG operationalizes schema formation as follows:
- Declarative Classification Schema: The schema is a set of configuration files per category, specifying gate values for entity-to-category assignment, and per-category modules comprising property-grouping rules.
- Intrinsic-Relational Distinction: For each module, properties are routed as either intrinsic attributes or as relational links, enforcing the "edge boundary" via design-time schema decision.
- Iterative, Oracle-Guided Refinement: Schema development proceeds through an iterative loop, partitioning failure cases (unclassified entities, entities lacking module assignment), and resolving them via three oracular interventions: category assignment, module assignment, and module refinement.
- Agentic LLM Workflow: An LLM is deployed not as a triple extractor but as a schema design agent, equipped with grounding tools for property/entity validation and sample retrieval, thus minimizing hallucination and maximizing determinism.
Notable aspects include the dual-layer schema design, inspired by foundational ontology (rigid sortals vs. roles/mixins), and an explicit mapping to property graph data models, supporting direct export to systems like Neo4j.
Case Study: Wikidata Instantiation and Schema Coverage
OntoKG is instantiated on the January 2026 Wikidata dump (~100M items). Data cleaning, driven by structural QID signatures, bulk import detection, and a curation scoring mechanism, filters the domain to a 34.6M-entity “core set” prioritizing editorial and non-bulk content.
The refined schema achieves 93.3% category coverage and 98.0% module assignment rate among classified entities. The resulting schema comprises 8 primary categories (people, organizations, places, creative_works_media, knowledge, science, events_actions, products_artifacts) and 94 modules (56 intrinsic, 38 relational), with modularization explicitly surfacing cross-category relational domains (e.g., military, religion, finance). Processing throughput is maximized via a Rust implementation capable of >100k entity classifications per second.
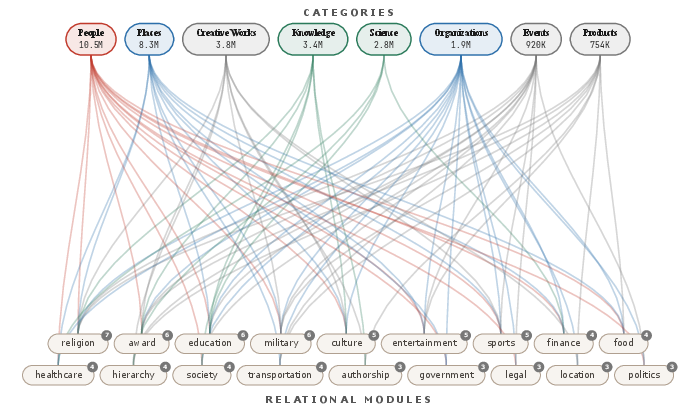
Figure 2: OntoKG's bipartite schema architecture, showcasing how 8 high-level categories connect to cross-cutting relational modules spanning the graph.
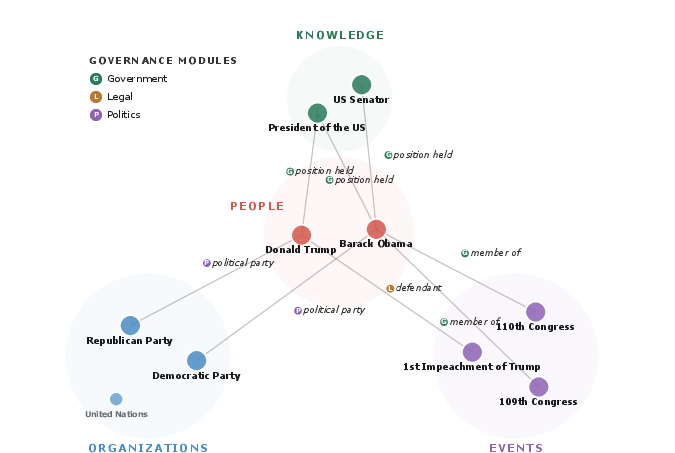
Figure 1: Example of an extracted governance subgraph, where relational modules such as government, legal, and politics bridge semantically distinct categories.
Applications and Empirical Evaluation
1. Ontology Structure and Subgraph Extraction
The intrinsic-relational dichotomy leads to a two-tier ontology, supporting structural analysis. Cross-category relational modules enable extraction of topic- or domain-focused subgraphs, with explicit bridging across otherwise siloed categories. Domain-specific clusters, as observed in the bipartite view, facilitate high-level thematic querying and analytic slicing.
2. Benchmark Annotation Auditing
By leveraging the independently engineered, gate-driven classifier (drawing only from ontological types, not dataset-specific NER training), OntoKG enables principled external auditing of annotation corpora. On datasets such as AIDA-YAGO and CleanCoNLL, OntoKG's classification resolves annotation disagreements and reveals systematic errors or task definition boundaries. Notably, it demonstrates a high degree of alignment (93–97.9%) with curated NER labels, and more critically, resolves ambiguous or disputed cases with transparency into the ontological rationale.
3. Entity Disambiguation
Module-structured type profiles improve entity disambiguation. Comparing against YAGO 4.5 types on the BLINK benchmark, the module-based strategy provides denser and more specific type labels, yielding a macro accuracy gain of +2.4 points in controlled candidate settings, particularly benefiting high-ambiguity (large candidate set) queries. This is attributed to the recovery of fine-grained occupation signals and cross-module distinctions absent from conventional taxonomies.
4. Schema Customization
The declarative, modular YAML schema is designed for extensibility. Users can selectively include/exclude categories or modules, decompose broad modules into fine-grained facets (e.g., splitting education into humanities, engineering, biomedical), or add domain-specific gate values, enabling rapid domain-tailored graph construction without pipeline changes.
OntoKG’s schema can be directly used as a prompt template for LLM-based entity and relation extraction from unstructured text, circumventing schema induction from LLMs and anchoring extraction in a formally defined, curated ontology. This setup supports both structured output alignment and direct graph population, facilitating hybrid human-KG/LLM-in-the-loop workflows.
Strong Empirical Results and Claims
- Coverage: 93.3% of core entities categorized, 98.0% assigned to at least one module.
- Graph Output: 34M nodes, 61.2M edges, 94 well-documented relationship and property types.
- Disambiguation: +2.4 macro accuracy improvement vs. YAGO 4.5 on BLINK controlled-candidate evaluation.
- Benchmark Auditing: Clear statistical advantage in annotation error triage (7.8:1 correctness ratio in disputed CoNLL assignments).
Implications and Future Prospects
Practically, OntoKG unlocks portable, ontology-centric downstream usage for structured querying, semantic search, and LLM retrieval augmentation, decoupling KG use from pipeline idiosyncrasies. Theoretically, it operationalizes a scalable ontology engineering method, balancing foundational rigor (via modularization and the intrinsic-relational lens) with practical tractability at web scale.
The approach anticipates emerging needs for schema-guided retrieval and integration—especially as hybrid KGs merge LLM-extracted structures with cleaned, ontology-driven graphs. A major open avenue is dynamic schema extension as new relation/modalities enter via LLM-augmented extraction, requiring principled, semi-automatic module induction or re-alignment.
Conclusion
OntoKG demonstrates that knowledge graph construction can be re-centered around schema engineering, with intrinsic-relational routing enabling high coverage, explicit modularization, and direct reuse for a variety of advanced ontology-reliant applications. Its declarative framework, empirical results, and demonstrated portability to LLM-driven workflows set a new template for knowledge graph projects seeking to maximize downstream interoperability and semantic clarity.
Figure 3: The relational structure of OntoKG's schema supports domain-focused extraction of subgraphs, as shown here for governance domains crossing multiple primary categories.