- The paper introduces the V2X-QA benchmark designed for explicit viewpoint decoupling to evaluate multimodal models across vehicle, infrastructure, and cooperative views.
- It employs a twelve-task taxonomy with expert-verified MCQA format and LoRA-based adapters to ensure robust and bias-reduced evaluation.
- Experimental results show that the V2X-MoE model improves accuracy significantly (up to 95.3% on vehicle-side tasks) and enhances calibration in cross-view scenarios.
V2X-QA: A Benchmark for Multimodal Reasoning Across Vehicle-Side, Infrastructure-Side, and Cooperative Views in Autonomous Driving
Motivation and Background
Autonomous driving research increasingly relies on multimodal LLMs (MLLMs) for semantic understanding, decision support, and interpretable system diagnostics. Existing benchmarks predominantly focus on ego-centric, vehicle-only visual question answering (VQA), which does not address safety-critical requirements or the realities of occlusions, partial observability, or macroscopic traffic dynamics. In parallel, the V2X community has developed perception datasets for cooperative driving (V2V and V2I), but these lack standardized annotation protocols for language-based evaluation.
To bridge this gap, the V2X-QA benchmark is introduced to enable systematic, multi-perspective evaluation of MLLMs across vehicle-side, infrastructure-side, and cooperative evidence regimes. By decoupling these viewpoints and organizing tasks into a rigorous taxonomy, V2X-QA enables controlled diagnosis of reasoning capabilities under heterogeneous observability, exposing not only model weaknesses but also the impact of evidence accessibility on safety-critical decision making.
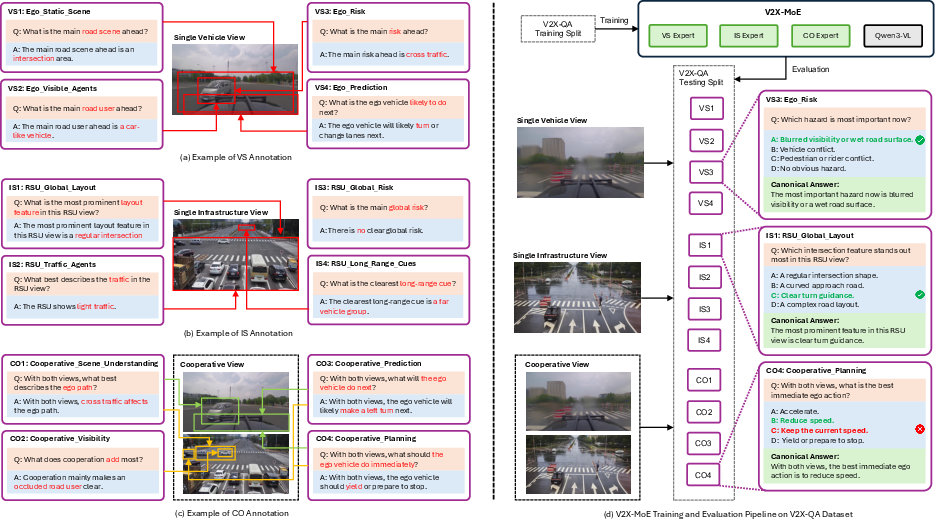
Figure 1: Overview of V2X-QA. Left: representative examples of the twelve viewpoint-aligned tasks organized by vehicle-side, infrastructure-side, and cooperative settings. Right: Illustration of the MCQA-based training and evaluation pipeline for the V2X-MoE model.
Dataset Construction and Task Taxonomy
V2X-QA is built atop real-world synchronized vehicle-infrastructure imagery, using the V2X-Seq-SPD domain to ensure datasets reflect realistic cooperative driving contexts. The dataset comprises 33,216 instances spanning three evidence regimes:
- Vehicle-Side (VS): 12,000 samples over four tasks focused on localized scene understanding, visible agents, risk, and short-horizon prediction.
- Infrastructure-Side (IS): 10,608 samples for global layout, macroscopic traffic, long-range, and infrastructure-centric risk analysis.
- Cooperative (CO): 10,608 samples requiring simultaneous vehicle-infrastructure evidence fusion for cross-view reasoning, occlusion resolution, joint prediction, and planning.
The twelve-task taxonomy is strictly viewpoint-aligned. Tasks are allocated to one of three groups (VS, IS, CO) and further subdivided into perception, prediction, and reasoning/planning categories. Each sample is associated with a single, expert-verified multiple-choice question, with three question variants per task to enforce annotation diversity and avoid bias.
This design critically distinguishes V2X-QA from prior works: it is not merely a union of single-perspective datasets, but a fully view-decoupled benchmark supporting controlled evidence-accessibility experiments. This enables accurate attribution of reasoning failure to input limitations versus model deficits, and allows evaluation under practical V2X assumptions such as intermittent connectivity.
MCQA Protocol and Expert Verification
All annotations follow a fixed multiple-choice question answering (MCQA) format. For each sample, a pool of three task-specific questions is constructed, answered using Gemini-2.5-Pro, and then systematically verified and corrected by human experts to ensure visual grounding and answer consistency. Balanced data splits are derived via pairwise mapping across the three viewpoints, controlling for information leakage and maintaining scenario-level consistency.
Dataset diagnostics reveal a task-dependent, non-uniform answer distribution reflecting real-world traffic priors and event frequency, with systematic analysis provided for correct option position, entropy, and majority-class ratios to support fair benchmarking and mitigate positional bias.
V2X-MoE: Viewpoint-Specific LoRA Mixture-of-Experts
V2X-QA includes a strong reproducible baseline, V2X-MoE, implemented as a Qwen3-VL-8B-based MLLM with explicit viewpoint routing and LoRA-based adapters:
- Architecture: A shared frozen multimodal backbone is combined with three LoRA experts (VS, IS, CO). The inference-time router deterministically activates the appropriate adapter based on the evidence regime. LoRA updates (rank 16) are injected into all self-attention projections, with only expert parameters finetuned.
- Training Protocol: The model is trained using MCQA-aligned autoregressive supervision with randomized answer ordering for bias reduction, task-balanced sampling, and stage-wise cooperative/infrastructure refinement. All evaluation employs a standardized prompt template instructing short, option-only responses.
- Reliability Analysis: Confidence calibration is evaluated using ECE and Brier scores, with explicit comparison between evidence regimes.
(Figure 1) (Figure 2)
Figure 2: View-specific LoRA injection in V2X-MoE, highlighting router-based expert selection and adaptation at the transformer attention-projection level.
Experimental Analysis and Results
V2X-QA supports controlled benchmarking of both proprietary (e.g., GPT-5.2, Gemini-3 Flash, Qwen-3.5-Plus) and open-source (Intern-S1, Qwen-2.5-VL, etc.) MLLMs without viewpoint-aligned adaptation. The main findings are:
- Vehicle-Side (VS): Top proprietary/open models achieve 58–61% accuracy; V2X-MoE scores 95.3%.
- Infrastructure-Side (IS): Frontier models reach 55–60%; V2X-MoE achieves 94.0%.
- Cooperative (CO): Most closed/open models underperform (23–44%). V2X-MoE demonstrates a dramatic improvement (86.2%), with stability across cross-view reasoning, visibility, and planning tasks.
Further breakdowns highlight that general-purpose MLLMs are brittle under cross-view settings—CO tasks induce instability and task-level collapse, particularly in planning and occlusion-handling (CO2/CO4). V2X-MoE's explicit viewpoint routing and LoRA specialization provide both strong aggregate accuracy and balanced task performance, confirming the necessity of architectural and training adaptations for V2X benchmarks.
Reliability analysis exposes that cooperative regimes yield a significant drop in calibration quality (ECE: 0.038 for VS/IS vs. 0.086 for CO), indicating that cross-view reasoning not only challenges accuracy but also confidence estimation.
Implications and Future Directions
V2X-QA fundamentally reframes MLLM evaluation for autonomous driving by treating viewpoint accessibility as an explicit experimental variable, not an implicit assumption. Key implications:
- Practical: For real-world autonomous driving, models cannot rely solely on ego-centric information. Infrastructure-side reasoning and cooperative evidence fusion are indispensable for robust macroscopic understanding, risk anticipation, and intersection-wide context.
- Benchmarking: Standardized, view-decoupled MCQA evaluation exposes previously hidden weaknesses in current MLLMs and will accelerate development of reliable, deployment-ready models by differentiating between lacking evidence and faulty reasoning.
- Methodology: Viewpoint-aligned adaptation (e.g., MoE with hard routing/LoRA experts) is critical for genuine cross-view generalization, outperforming naive capacity scaling or simple multi-image input concatenation.
- Theoretical: Explicit benchmarking under varying observability supports more interpretable diagnosis of reasoning bottlenecks and may guide the development of modular architectures for long-horizon, uncertainty-aware planning.
Anticipated research directions include the extension of V2X-QA to temporal and communication-aware settings, richer V2X modalities (V2V+V2I+cloud), and joint evaluation of calibration, robustness, and uncertainty under more realistic operational scenarios.
Conclusion
V2X-QA provides a comprehensive, publicly available benchmark and standard for evaluating MLLMs in autonomous driving under explicit vehicle, infrastructure, and cooperative evidence regimes. It demonstrates that cooperative and infrastructure-based reasoning are not trivial extensions of ego-centric QA, but distinct domains requiring architectural interventions such as explicit routing and view-specialized adaptation. Experimental results underline persistent deficits in state-of-the-art MLLMs and showcase the effectiveness of viewpoint-aware baselines for multi-perspective autonomous driving reasoning. V2X-QA establishes a new foundation for advancing reliable, cooperative, and interpretable embodied intelligence in connected traffic environments (2604.02710).