- The paper introduces PhDLspec, a transformer-based method that integrates ab initio gradient spectra to enable physically-interpretable inference of over 30 stellar parameters from blended low-res data.
- It achieves sub-percent spectral emulation and robust abundance recovery (<0.1 dex for key elements) validated through cross-survey calibration and systematic error correction.
- The model combines forward modeling with evolutionary optimization, offering a scalable solution for precise stellar label determination in large spectroscopic surveys.
PhDLspec: Physically-Grounded Deep Learning for High-Dimensional Stellar Spectroscopy
Motivation and Physical Challenges in Low-Resolution Spectral Analysis
Low-resolution stellar spectra from large surveys such as LAMOST present a persistent challenge for precise chemical abundance analysis: extensive line blending leads to a high-dimensional parameter inference problem, often requiring simultaneous modeling of >20 correlated stellar labels. Traditional approaches restrict fitting to a minimal set of atmospheric parameters and global metallicity to circumvent template library and interpolation constraints, at the expense of chemical resolution. Purely data-driven mappings between low- and high-resolution spectra scale to large samples, but lack physical interpretability and propagate systematic errors.
PhDLspec implements a forward-modeling paradigm based on deep learning, integrating strict physical priors in its model architecture and training objective to deliver scalable, physically-interpretable label inference from blended, low-resolution stellar spectra in high-dimensional label space.
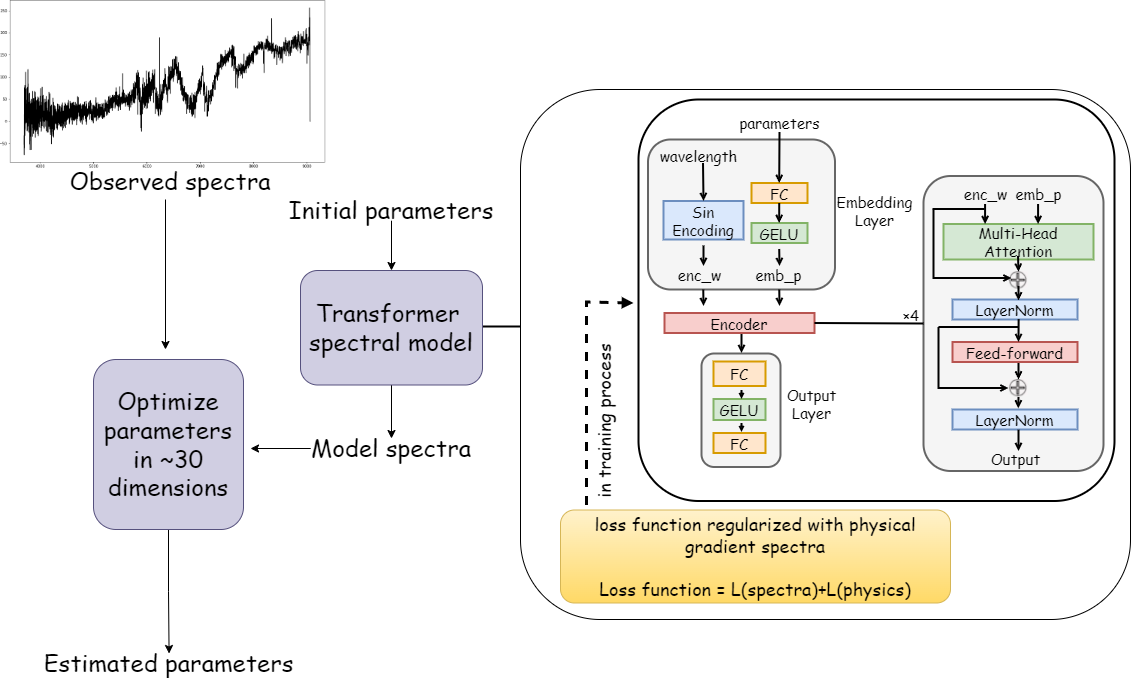
Figure 1: Schematic diagram of PhDLspec. The transformer-based spectral model leverages wavelength and stellar parameter embeddings, multi-head attention, and is trained with regularization from physical gradient spectra computed via ab initio modeling.
Self-Attention for Spectral Emulation
PhDLspec adopts a transformer encoder architecture, exploiting multi-head self-attention to model the complex dependencies between blended absorption features and stellar labels across the full spectral range. The input embedding combines sinusoidal wavelength encoding with a fully connected parameter embedding, enabling portable representation of spectral sequences observed on varied grids.
This architecture enables PhDLspec to efficiently interpolate synthetic spectra across ≳30 stellar parameters—well beyond the practical range of polynomial models or standard neural networks—while capturing long-range feature correlations critical for blended lines.
Incorporation of Ab Initio Spectral Gradients
To guarantee physical interpretability, PhDLspec regularizes its training with ab initio gradient spectra: for each label, gradient spectra ∇θf(λ;θ) are computed with the Kurucz ATLAS12 models. The loss function enforces matching both flux and its first-order derivatives with respect to all stellar labels, balancing contributions across elements by amplitude-normalized weights. Use of L1 loss ensures robustness against outliers and direct physical comparability between flux and gradient residuals.
This hybrid deep learning-forward modeling approach unifies the expressiveness of attention-based architectures and the physical sensibility of model-driven spectral synthesis, enforcing model adherence to differential spectral responses for all parameters.
High-Dimensional Optimization and Inference
Parameter inference is posed as a high-dimensional, non-convex optimization problem: PhDLspec fits observed spectra via minimization of a reduced χ2, using the Covariance Matrix Adaptation Evolution Strategy (CMA-ES). Due to the multi-modal, black-box landscape, stochastic evolutionary search with adaptive covariance learning achieves the computational efficiency required for 30+ parameter fits per spectrum. For computational tractability, a staged optimization scheme is employed: Group I parameters (atmospheric and strong-feature abundances) are optimized first, followed by Group II (weak-feature abundances).
Formal uncertainties are estimated analytically from the Jacobian and the error-covariance propagation, enabling error scaling by fit quality (χ2).
PhDLspec demonstrates sub-percent spectral emulation accuracy and precise label recovery across the high-dimensional parameter grid:
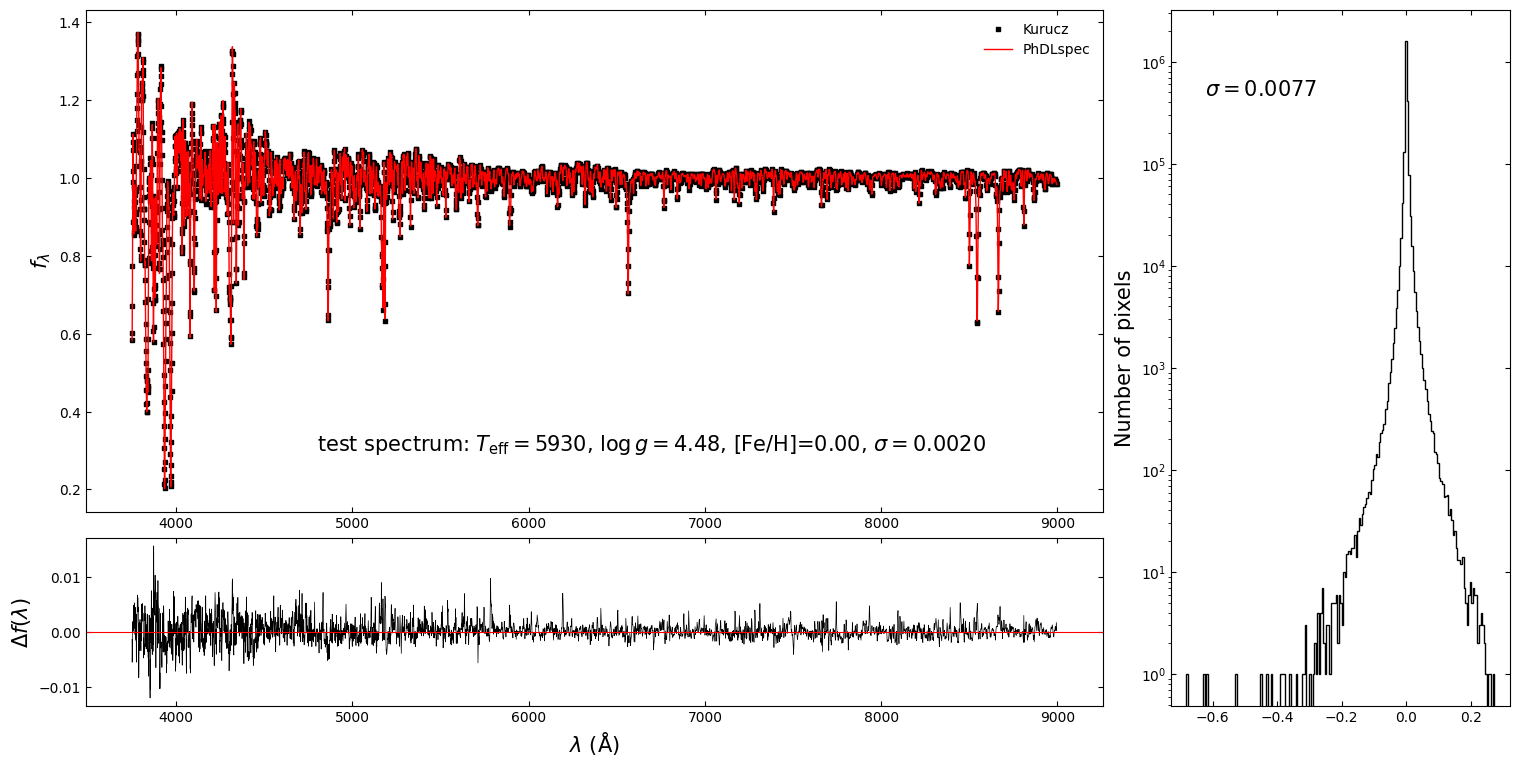
Figure 2: Kurucz spectra (black squares) vs. PhDLspec predictions (red), and the distribution of pixel-wise residuals for a test set. Sub-percent dispersion is achieved.
For metal-rich test stars (−1<[Fe/H]), abundance label recovery yields standard deviations of <0.1 dex for main atmospheric and α-elements, 0.1–0.2 dex for neutron-capture elements, and larger for less-constrained labels. The model achieves a dispersion of 28 K in Teff, 0.11 dex in ≳0 and 0.12 dex in Fe/H, demonstrating high-fidelity label recovery.
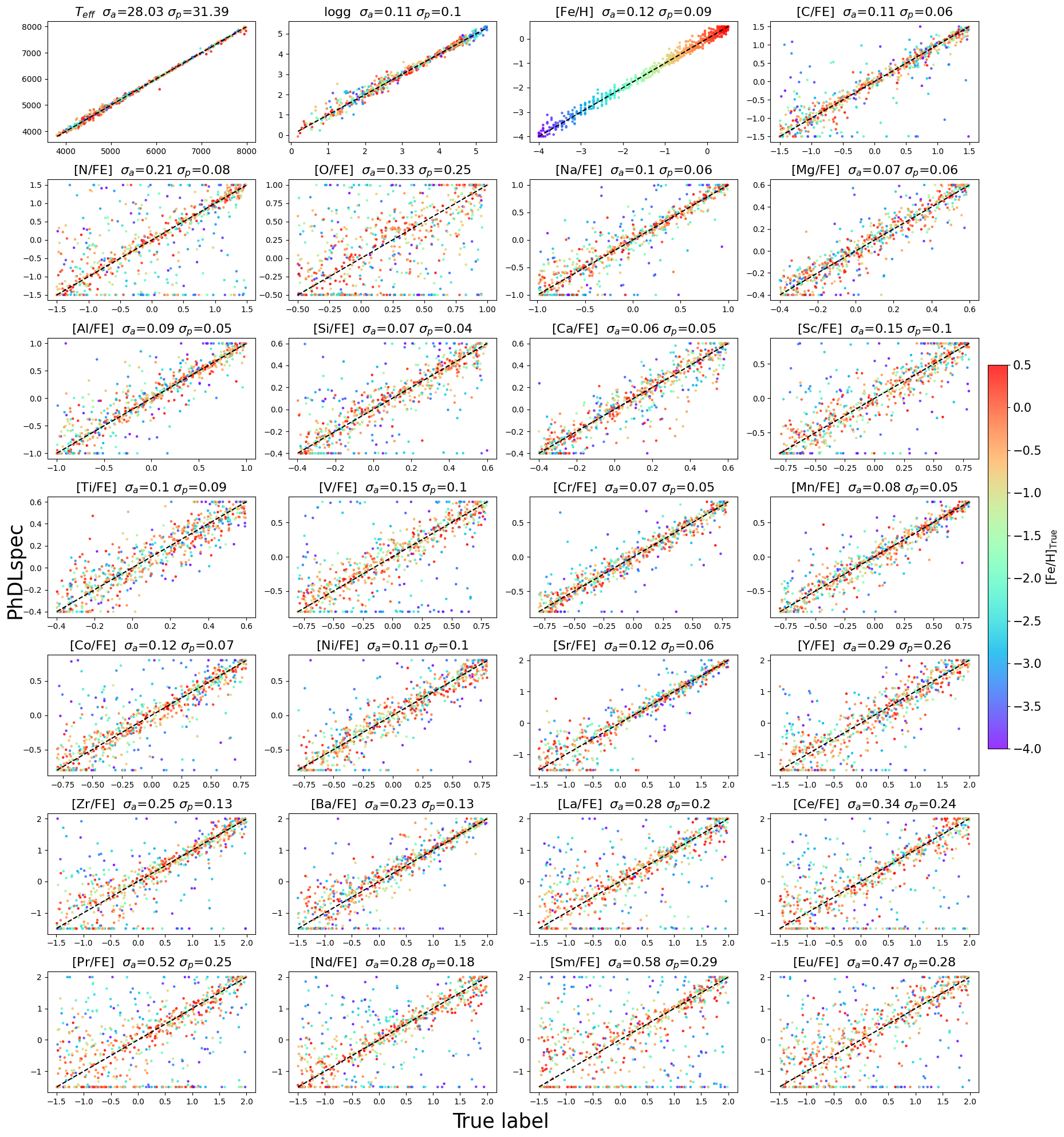
Figure 3: Comparison between PhDLspec inferred labels and ground-truth for the test set. The color scale indicates [Fe/H]. Dispersion values for various element groups are quantified for the full and metal-rich subsets.
Physical gradient recovery is superior in PhDLspec compared to standard transformers lacking physical loss terms, particularly pronounced in weak-feature and cool star regimes:
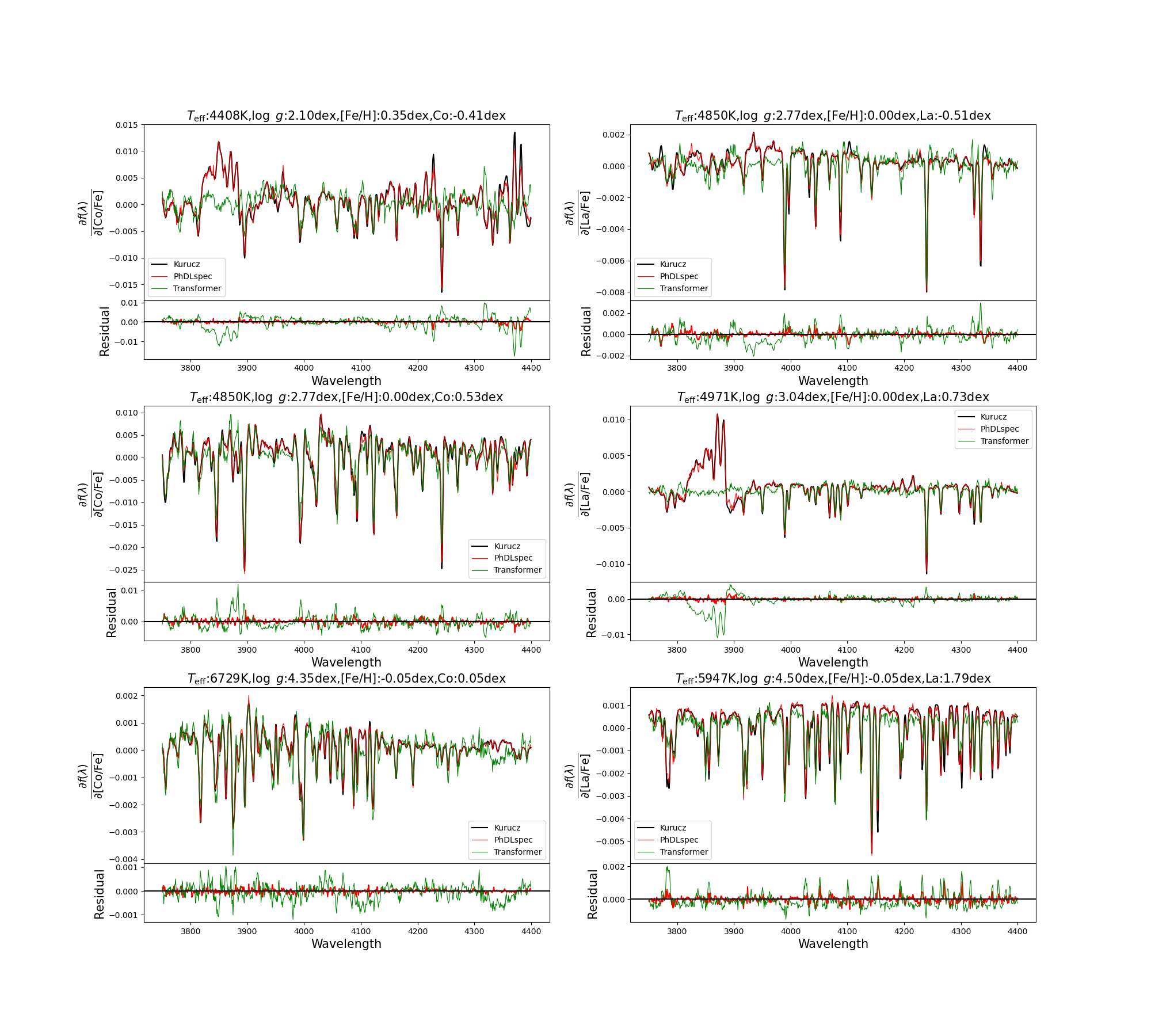
Figure 4: Predicted vs. ab initio partial derivatives for [Co/Fe] and [La/Fe]. PhDLspec (red) recovers spectral gradients significantly better than a standard transformer (green).
Systematics, Calibration, and Validation
Despite broad spectral precision, model-driven synthesis is known to exhibit systematic offsets due to inaccuracies in the underlying radiative transfer and line lists. The authors implement an extensive calibration protocol leveraging:
- Cross-survey comparison with high-resolution APOGEE and GALAH labels,
- Zero-point corrections and trend removals as a function of ≳1 and ≳2 using wide binaries and open cluster (M67) members,
- Assessment of covariance structure to quantify degeneracies and inter-parameter correlations (Figure 5).
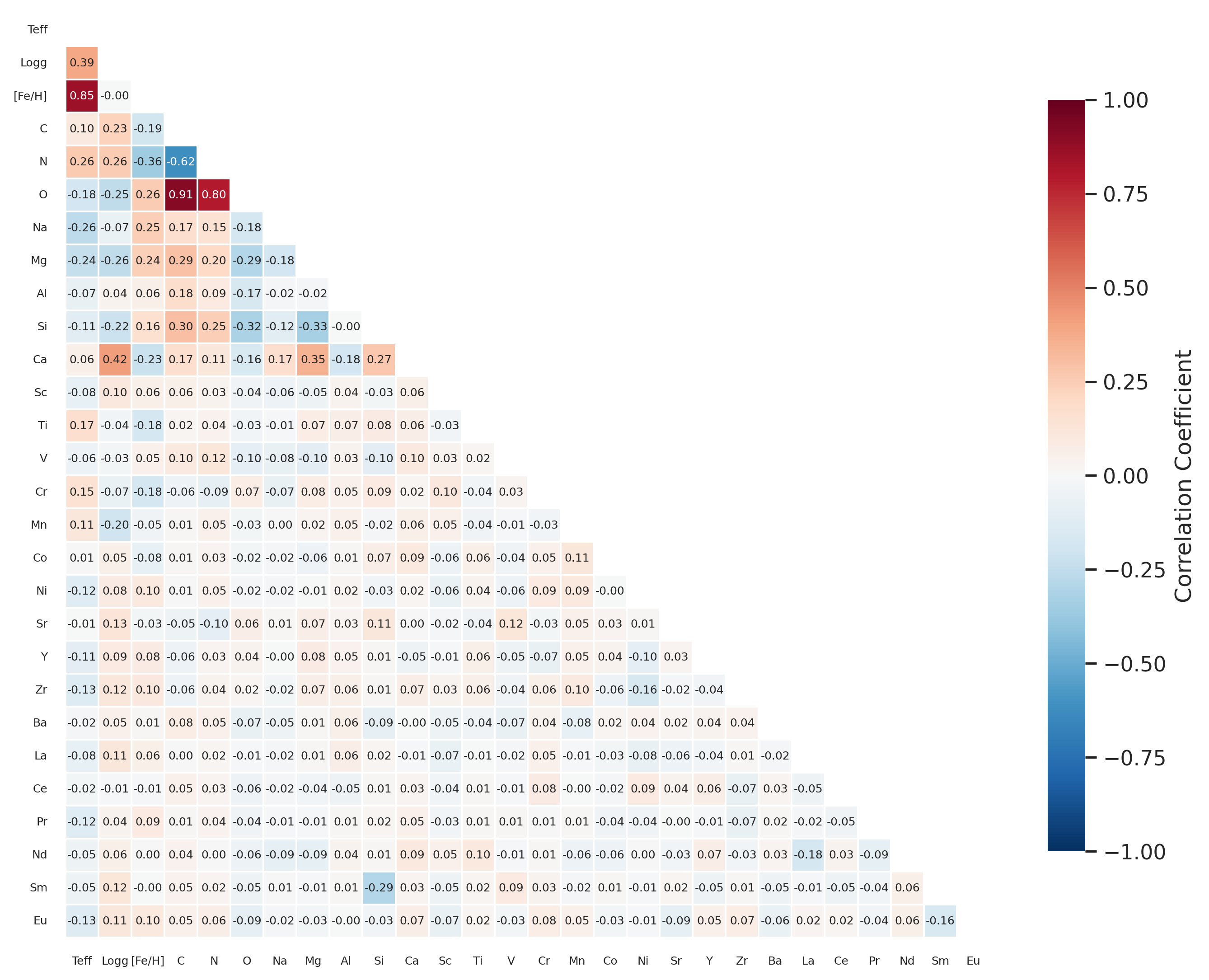
Figure 5: Pearson correlation matrix between labels, highlighting strong degeneracies among C-N-O, [Fe/H], and ≳3-elements.
Sky-calibrated abundances are systematics-corrected, with validated dispersions in chemically homogeneous populations: 0.03–0.04 dex for robust abundance indicators (Mg, Si, Ca, Ti, Cr, Ni) in M67 (Figure 6), and 0.05–0.1 dex for others. Systematically poor performance, larger scatter, or outliers are restricted to heavy/neutron-capture elements with intrinsically weak spectral features, where the model’s uncertainty metric and quality flags provide critical diagnostic information.
Application to LAMOST Subgiant Survey
A major application consists of the derivation of homogeneously-calibrated elemental abundances for 25 elements across 116,611 subgiant stars with high-precision ages. Trends are found to match those of high-resolution samples, and detailed abundance distributions reveal, e.g., the Milky Way’s bimodal ≳4-sequence in [Mg/Fe] and Ti/Fe, with systematic differences and increased scatter only in metal-poor, noise-dominated, or weak-feature elements.
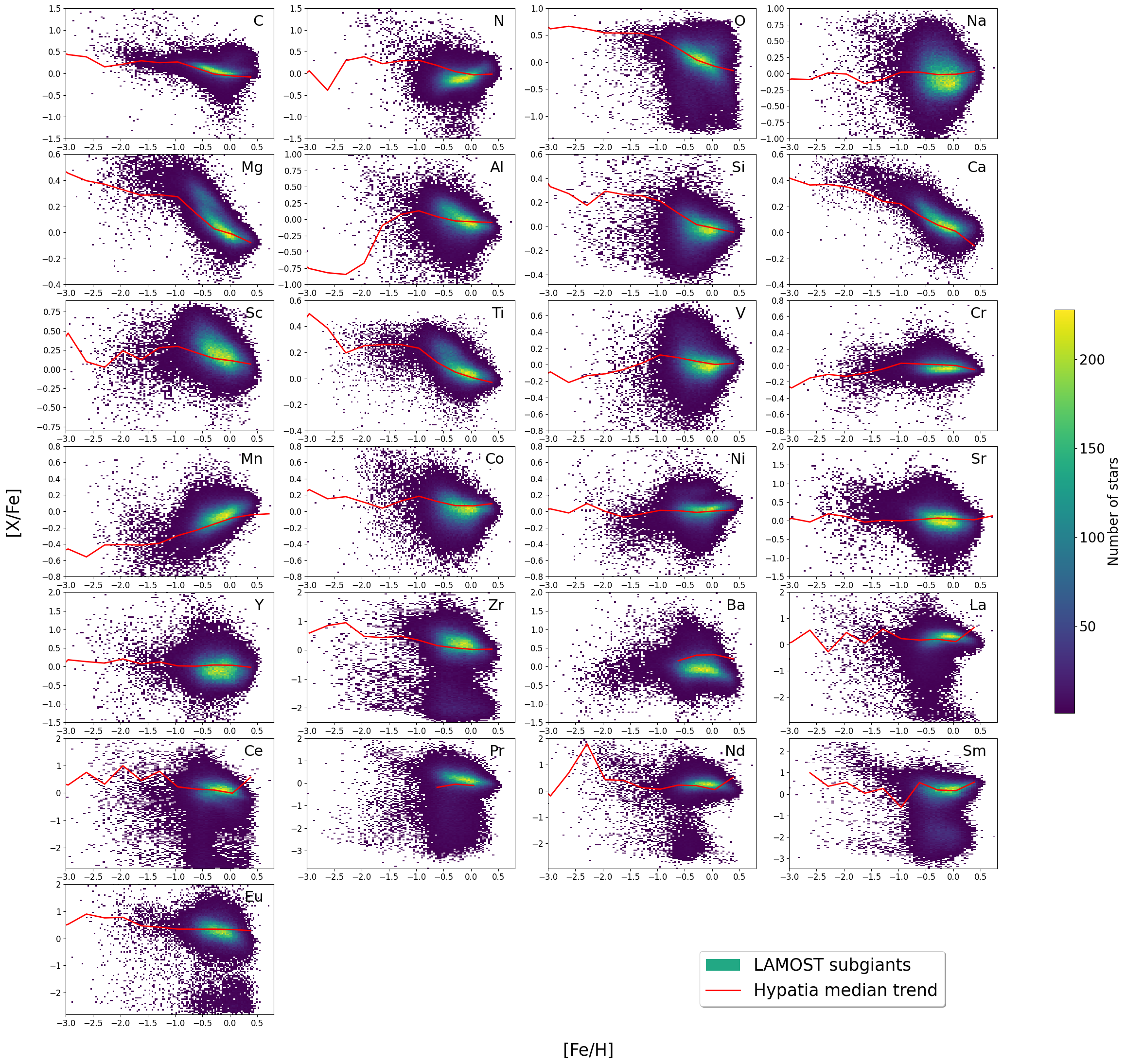
Figure 7: Density distributions for elemental abundances in subgiants. Red dashed trend line marks the median from the Hypatia high-resolution catalog; PhDLspec tracks major chemical evolution features.
Numerical Results and Comparative Claims
- Spectral emulation:
- Median residual: 0.2% (pixel level); dispersion for ≳5 K: 0.46%.
- Abundance precisions after calibration:
- ≳6- and Fe-peak elements: typically ≳70.1 dex; neutron-capture: 0.2–0.3 dex.
- Parameter covariance:
- Confirms tight coupling of elemental and atmospheric labels in blended, low-resolution regime.
- Calibration outcome:
- Post-correction residuals: ≳80.05 dex in [X/Fe] for Mg, Si, Ca, Ti, Cr, Ni; slightly higher for C, N, Al, Sc, V, Mn, Co, Ba, Nd.
The method’s claims are supported by one-to-one comparison with ground-truth labels from state-of-the-art surveys and detailed analysis of homogeneous populations.
Implications and Prospects
PhDLspec demonstrates the feasibility of physically-interpretable, flexible deep learning architectures for massive spectroscopic label inference under the full complexity of blended, high-dimensional parameter spaces, tightly integrating ab initio priors with state-of-the-art self-attention models. This approach circumvents both the template-library bottleneck of traditional spectral fitting and the “black box” limitations of purely empirical machine learning.
As next-generation low- and intermediate-resolution surveys (e.g., DESI, 4MOST) deliver increasingly complex and vast datasets, the philosophy underlying PhDLspec—incorporating physical derivatives as “differentiable physical bottlenecks” into general-purpose deep neural models—provides a robust, extensible path forward for precision Galactic archaeology and stellar population studies.
Extension to larger and more diverse spectral libraries, improved radiative transfer, and domain adaptation for model–data mismatches are natural avenues for development. The architecture’s scalability on modest GPU hardware makes it directly amenable to broad adoption.
Conclusion
PhDLspec implements a scalable and physically-constrained transformer-based approach for comprehensive stellar label inference from low-resolution, blended spectra, achieving robust sub-percent spectral prediction accuracy and ≳90.1 dex abundance precision for key elements. Its calibration pipeline corrects for systematic offsets inherent in ab initio modeling, and its large-scale catalog application releases a fundamentally new dataset for the field. The methodology exemplifies the power of integrating differentiable physics into deep architectures and sets a new standard for high-dimensional spectral analysis in survey astrophysics (2604.02730).