- The paper presents the first unified neural framework that integrates motion planning, rigging, simulation, and rendering into a single pipeline.
- It leverages an action-conditioned diffusion model combined with a point transformer to refine geometry and enhance photorealistic appearance.
- Empirical evaluations demonstrate stable autoregressive avatar synthesis over 2,000 steps, ensuring natural dynamics and improved visual fidelity.
Unified Control of Neural 3D Avatars: An Expert Review of UNICA
Motivation and Context
Traditional pipelines for controllable 3D avatars separate animation, rigging, physical simulation, and rendering into discrete, hand-engineered stages, incurring significant resource costs and limiting flexibility. Existing learning-based methods tend to automate isolated components (skeleton prediction, motion planning, mesh deformation), but fail to unify control and generation, often requiring external sources for user input or action-driven animation. The need persists for an end-to-end neural system capable of interactive, physically plausible, free-viewable avatar generation conditioned directly on symbolic control signals.
UNICA ("UNIfied neural Controllable Avatar") (2604.02799) introduces the first model that unifies motion planning, rigging, physical simulation, and rendering into a single neural framework, driven by discrete, game-style action inputs such as keyboard presses. This design moves beyond skeleton-driven or pose-driven models, offering genuine interactivity and eliminating the reliance on procedural controllers, explicit skeletal hierarchies, or hand-tuned physics, while directly supporting action-conditioned, real-time 3D avatar synthesis.
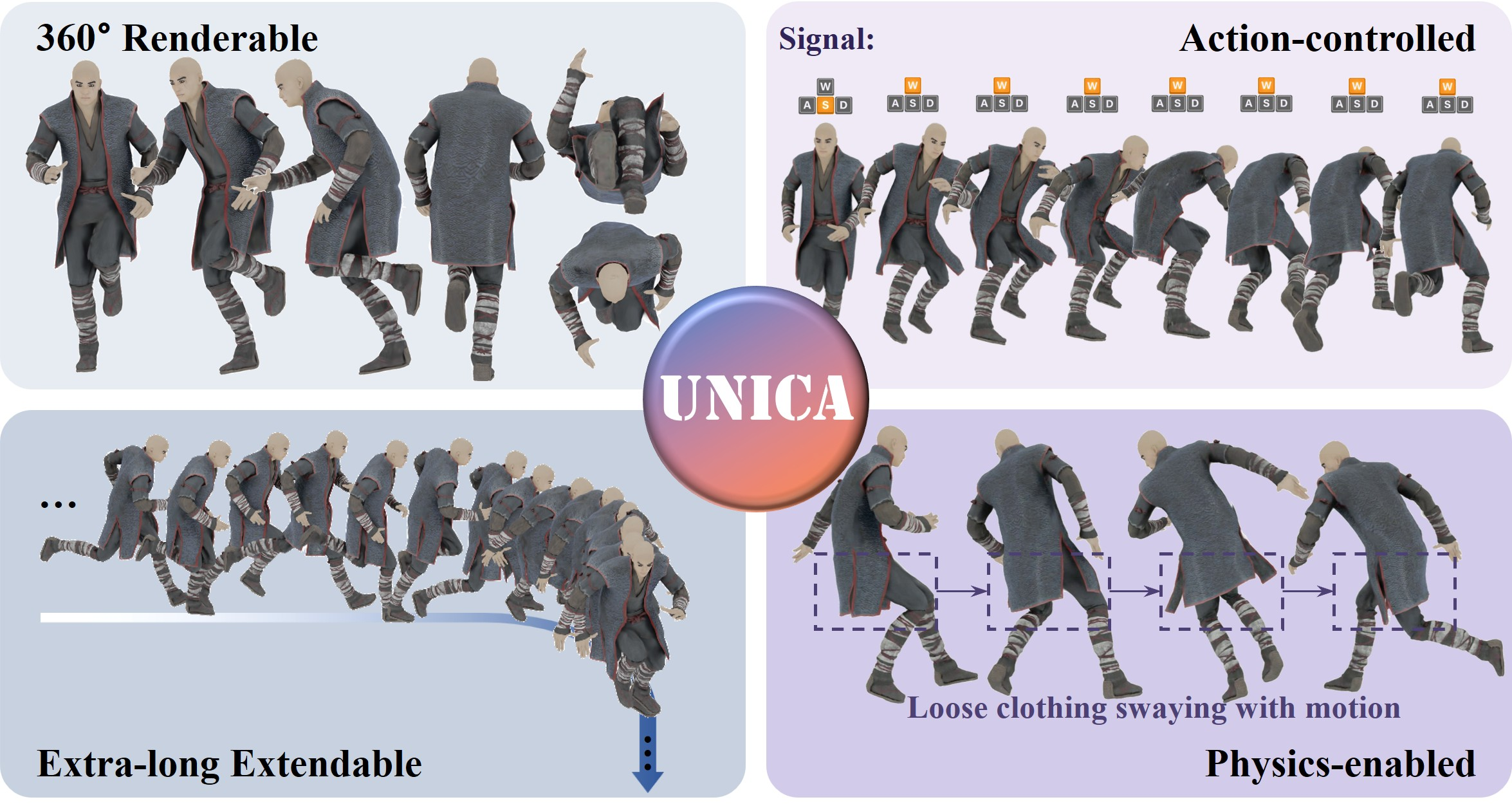
Figure 1: UNICA is a unified model that generates action-controlled, 360∘-renderable 3D avatars with dynamics, unifying a traditional workflow ("motion planning, rigging, physical simulation, rendering") within one neural model.
System Architecture
The architecture of UNICA is a two-stage pipeline combining an action-conditioned multi-frame diffusion model and a point transformer for appearance refinement:
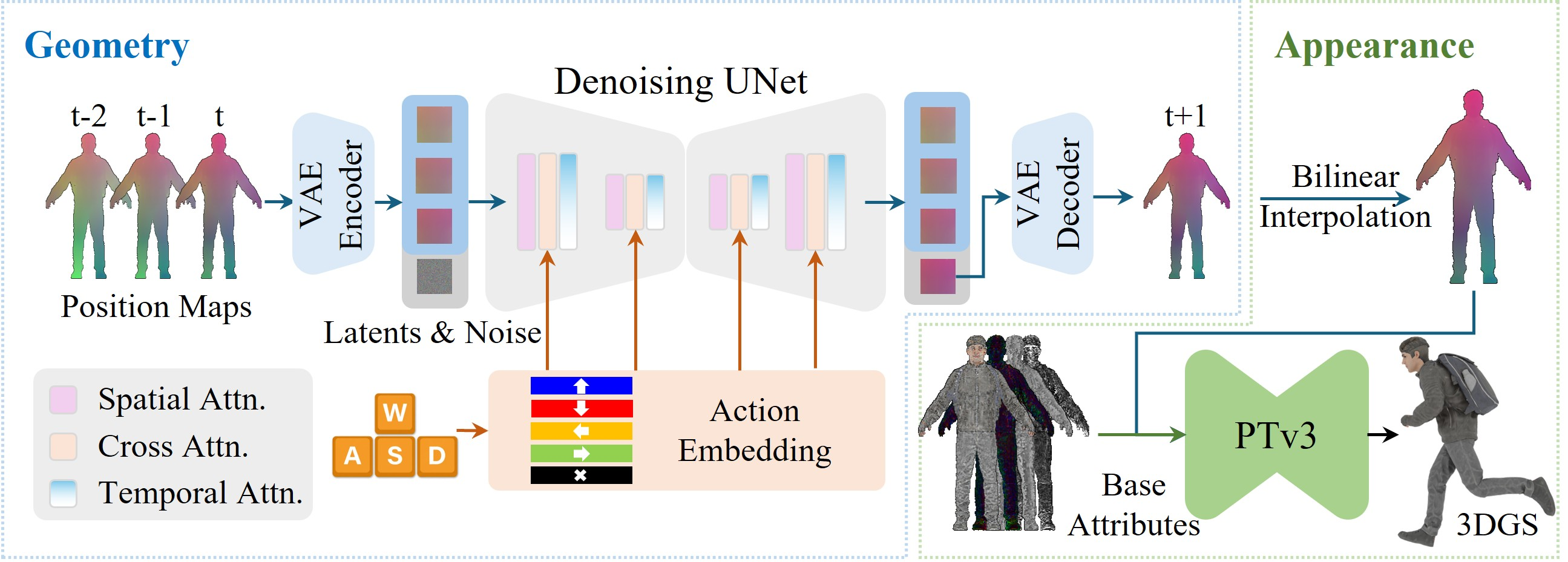
Figure 2: UNICA pipeline. An action-conditioned diffusion model generates geometry in 2D position map space; a Point Transformer refines the coarse geometry into a dense, appearance-rich 3D Gaussian Splatting (3DGS) avatar.
Action-Conditioned Geometry Generation
UNICA employs a UNet-based latent diffusion model over 2D encoded position maps, facilitating compatibility with established image and video diffusion architectures. Each position map compactly encodes full avatar geometry via per-pixel (x,y,z) coordinates across six projected views. Temporal context is captured by stacking three historical position maps along with the noise-initialized frame-to-be-generated, allowing the model to condition on both pose and higher-order motion states (velocity, acceleration).
Discrete action inputs are embedded and incorporated into the diffusion denoiser via cross-attention, enabling explicit control without skeletal pose queries or procedural controllers.
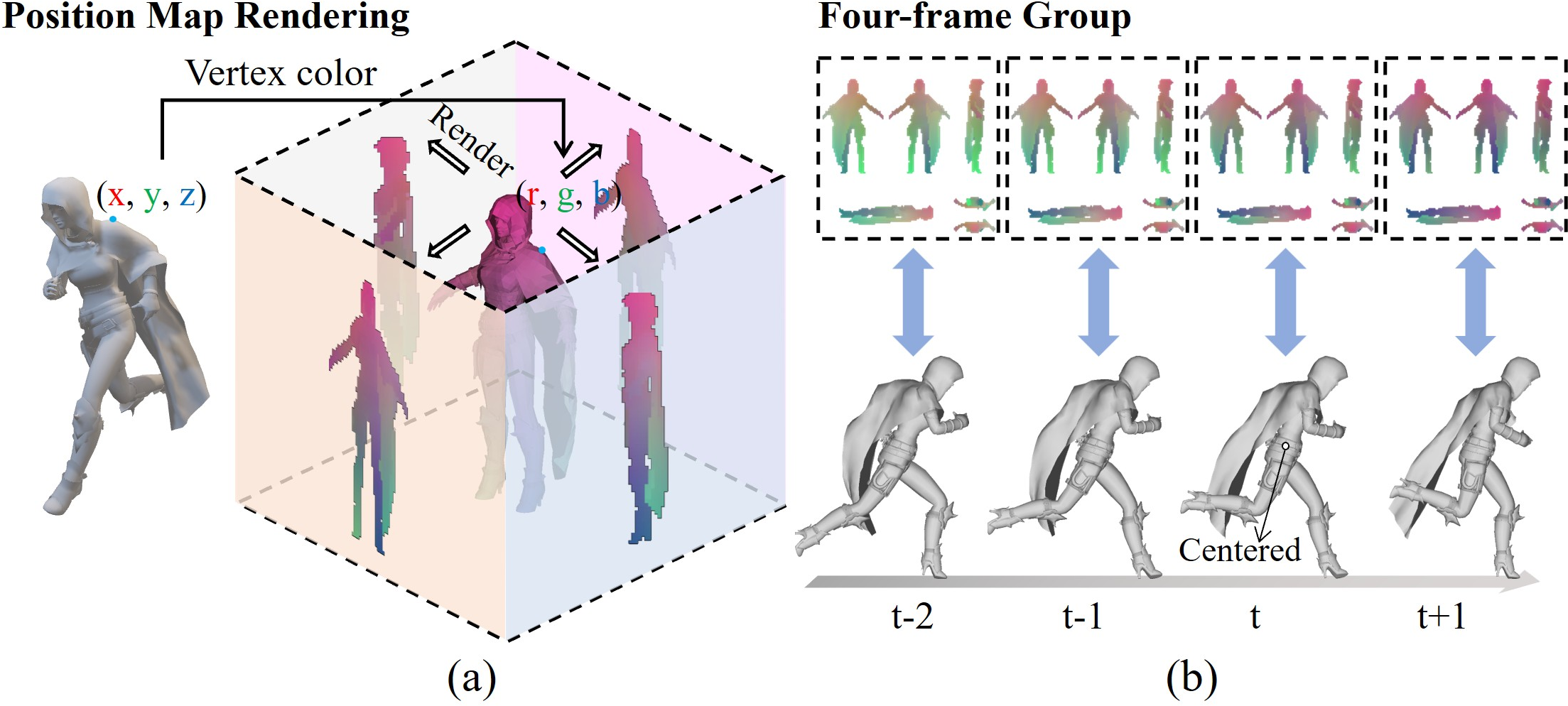
Figure 3: Position map rendering and visualization, showing (a) avatar pose encoding and (b) grouping normalization for temporal coherence.
Appearance Mapping via 3D Gaussian Splatting
For rendering, low-resolution generated geometry is upscaled and combined with avatar-specific, pretrained 3DGS base attributes. A modified Point Transformer V3 (PTv3) maps coarse geometry to high-fidelity, pose-conditioned Gaussian splats, supporting photorealistic, 360∘ novel view synthesis. This design decouples geometric motion inference from appearance refinement, ensuring computational efficiency while preserving detail.
Group Normalization and Progressive 4D Inference
UNICA introduces a group normalization strategy over sliding windows of context frames, enabling coordinate normalization, temporal continuity, and unbounded avatar traversal in world space. During autoregressive inference, relative movements are accumulated, and renormalization maintains input validity, supporting trajectories with arbitrary length and complexity.
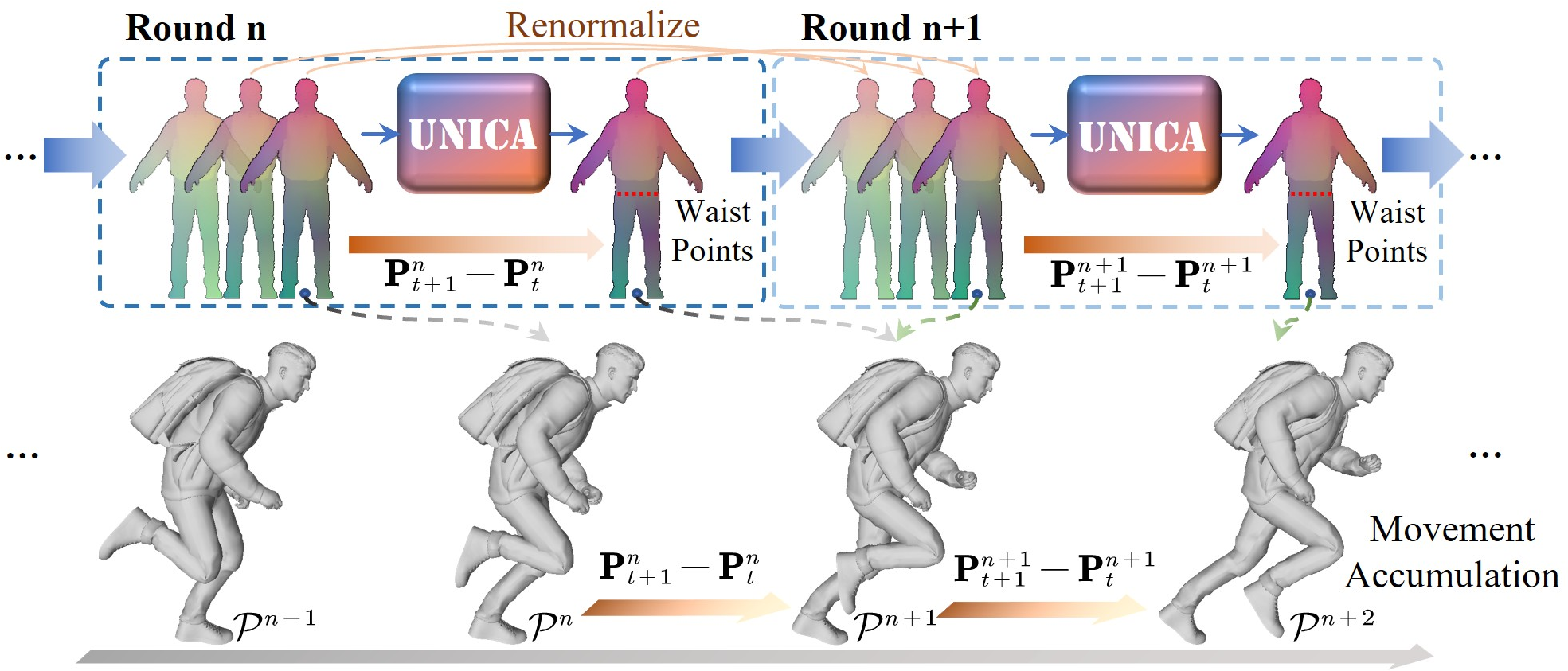
Figure 4: Progressive 4D inference: Each generated movement is accumulated for world-space navigation; renormalization maintains mapping to the input range at every step.
Training Paradigm
Training is staged: VAEs are fit to avatar-specific position maps; the diffusion model is optimized (with classifier-free guidance) in two phases—first on directionally consistent motion, then on direction transitions. Action embeddings are learned jointly with U-Net denoising weights, then frozen for stability when turning frames are oversampled. PTv3 is trained to refine 3DGS for all poses. Importantly, independent noise injection in the context frames regularizes against error accumulation during long rollouts.
Empirical Evaluation
Animation and Stability
UNICA demonstrates stable autoregressive trajectory generation for over 2,000 steps without drift or quality degradation. This is validated by flat FVD curves and human studies confirming prompt, lifelike transitions between user actions (e.g., 180∘ and 90∘ turns with response times matching physical constraints of locomotion).

Figure 5: Avatar animation samples, exhibiting natural physical dynamics and prompt key-press responsiveness.
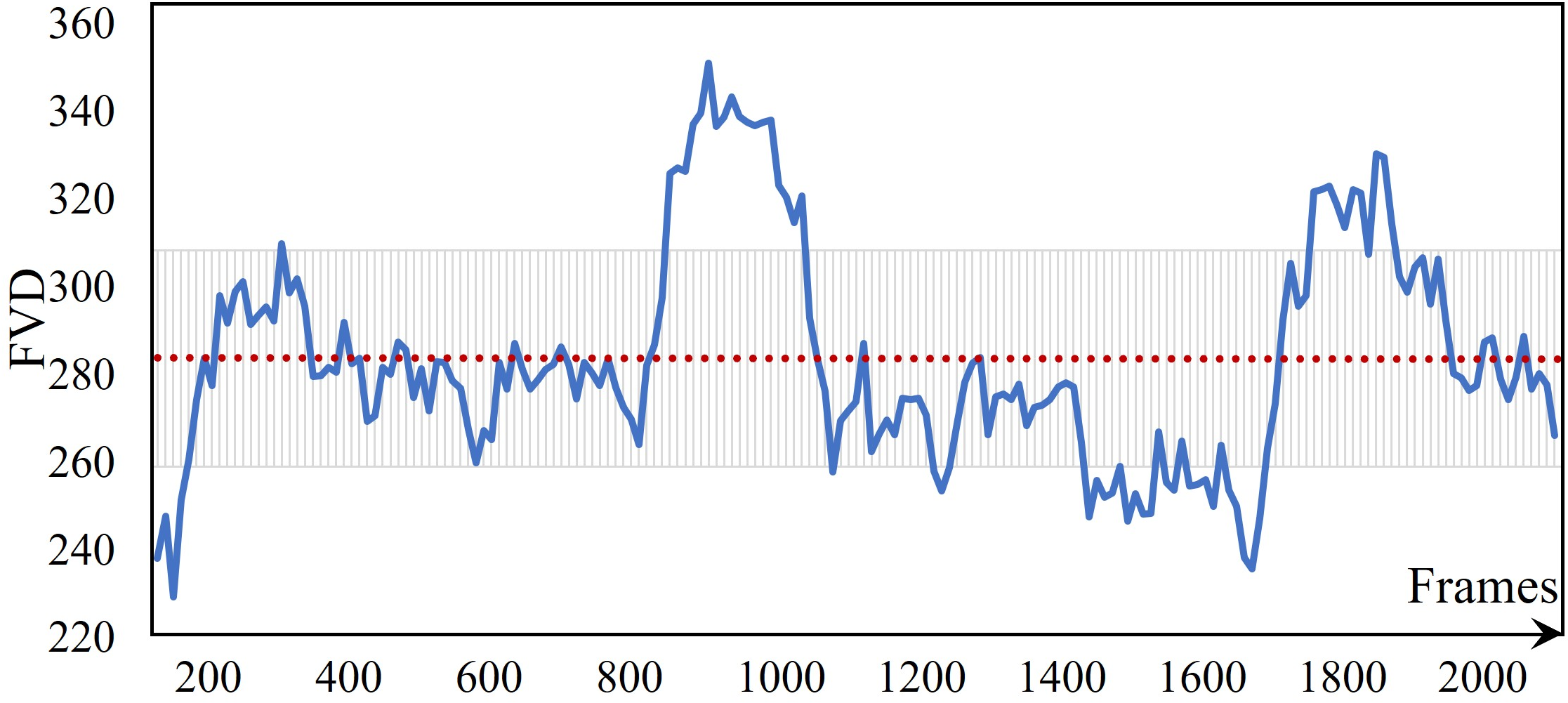
Figure 6: FVD scores remain stable over 2,000-step sequences, showing no drift or quality decay.
Baseline Comparisons
Against Animatable Gaussians, Mixamo, and SV4D 2.0, UNICA achieves superior or comparable performance under both objective metrics (FVD, PSNR, LPIPS) and human evaluations (visual quality, physically plausibility). Notably, while Mixamo provides mesh accuracy via pose-driven animation, it cannot model physical garment dynamics; Animatable Gaussians, relying on SMPL-X tracking, exhibit degraded textures and geometric artifacts under non-trivial clothing or unmodeled poses.
Figure 7: Qualitative comparison across frames/viewpoints with baselines. UNICA preserves facial integrity and clothing dynamics absent in others.
Ablation and Architecture Investigation
Three context frames are validated as the minimal requirement for plausible second-order motion. PCA-based position map alignment corrects inter-view inconsistencies, significantly improving 3DGS reconstructions, particularly during challenging articulated or turned poses.

Figure 8: Ablation demonstrates that PCA alignment suppresses geometric misalignments in multi-view position maps.
Resolution ablations show that low-resolution geometry upsampled for PTv3 suffices for detailed appearance, supporting efficient training and inference without sacrificing rendering fidelity.
Limitations and Future Directions
UNICA's inference speed precludes real-time deployment absent hardware or algorithmic acceleration. The model currently focuses on locomotion; richer action spaces (manipulation, emotion, interaction) remain to be addressed. Artifact reduction in extreme poses (especially for non-body-attached apparel) requires advances in Gaussian orientation modeling or point normal estimation. Finally, scaling controllable avatars to unseen identities, clothes, or body types, as well as real-world generalization, are important open directions.
Theoretical and Practical Implications
UNICA establishes the feasibility of fully unified, end-to-end neural pipelines for interactive 3D avatar synthesis. This compresses the traditional "authoring stack" (rigging, planning, simulation, rendering) into a single system, holding implications for scalability in commercial content creation, personalized gaming characters, and virtual presence in telecommunication or AR/VR platforms. The architecture advances the methodological frontier toward event- or action-conditioned neural world models supporting 3D geometric control beyond pure video or frame synthesis.
The theoretical contribution includes a practical demonstration of diffusion models combined with transformer-based appearance refinement for high-consistency, long-term 4D autoregressive synthesis, including robust solutions to coordinate normalization, principal component-based view alignment, and compositional action conditioning.
Conclusion
UNICA (2604.02799) presents a comprehensive neural system unifying control, generation, and rendering of physically plausible, action-driven 3D avatars in a skeleton-free framework. By combining action-conditioned multi-frame diffusion, efficient low-/high-res separation, and advanced point transformer appearance mapping over Gaussian radiance fields, it demonstrates stable, high-fidelity, key-responsive avatar synthesis for extended rollouts—significantly reducing manual labor in 3D character creation and opening avenues for neural, interactive character embodiment in virtual environments. Future work should seek to generalize this paradigm to richer, open-world action spaces and accelerate inference for practical deployment.

