- The paper demonstrates that DCO methods can achieve up to 2x speedups on moderate dimensions but struggle on low and ultra-high dimensions.
- The study benchmarks simple, hypothesis testing, and classification-based approaches, revealing performance variances with hardware acceleration and query distribution.
- The research concludes that no single DCO method is universally optimal, emphasizing a need for hardware-aware and adaptive algorithm designs.
Distance Comparison Operations (DCOs) in Vector Similarity Search: Merits and Limitations
Introduction
Distance Comparison Operations (DCOs) have recently become a focal point in vector similarity search, a core primitive in neural retrieval, RAG, and large-scale recommendation systems. Unlike traditional focus on index structures, DCO methods attempt to accelerate similarity search by early termination in distance evaluation, using only partial dimensions or learned/predicted distance bounds to avoid full-dimensional computations. This essay provides an in-depth analysis of the comprehensive benchmark study "Distance Comparison Operations Are Not Silver Bullets in Vector Similarity Search: A Benchmark Study on Their Merits and Limits" (2604.02801), with focus on the precise empirical evaluation, theoretical and practical ramifications, and resultant guidelines for DCO deployment.
DCO Taxonomy and Methodological Landscape
The paper identifies three primary classes of DCO methods: simple (full and partial dimension scanning), hypothesis testing, and classification-based approaches.
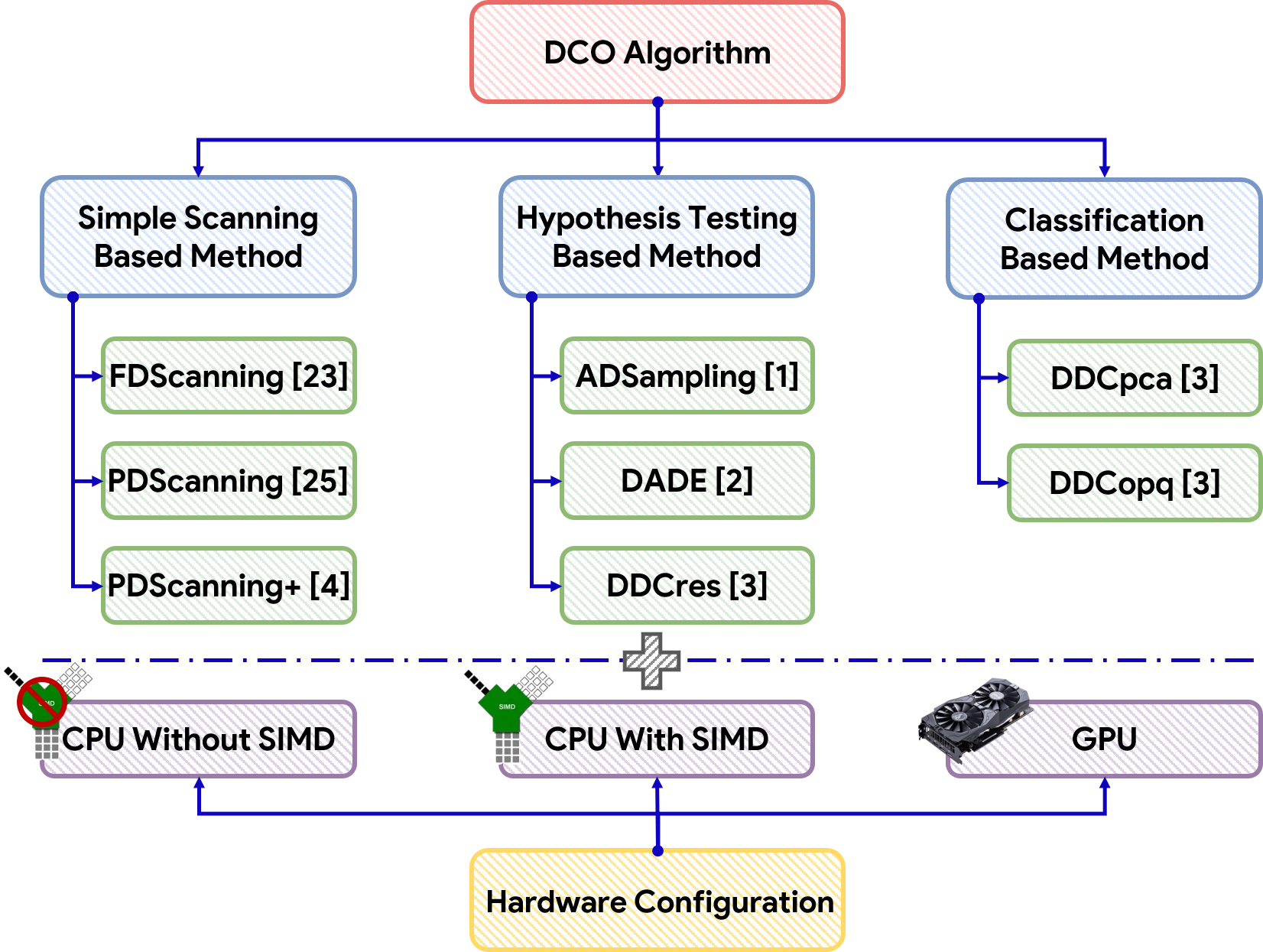
Figure 1: The taxonomy of existing DCO methods highlights the division into simple, hypothesis, and classification-based strategies.
- Simple methods (FDScanning, PDScanning, PDScanning+): Iterate over dimensions, terminating early if possible. Optimizations via SIMD and PCA can further accelerate partial scanning.
- Hypothesis testing methods (ADSampling, DADE, DDCres): Estimate residuals or projected bounds using random projections or PCA, invoking stopping rules via probabilistic inequalities.
- Classification-based methods (DDCpca, DDCopq): Pose the DCO as a binary classification problem, often requiring offline model training for each k, tightly coupled to both index structure and hardware.
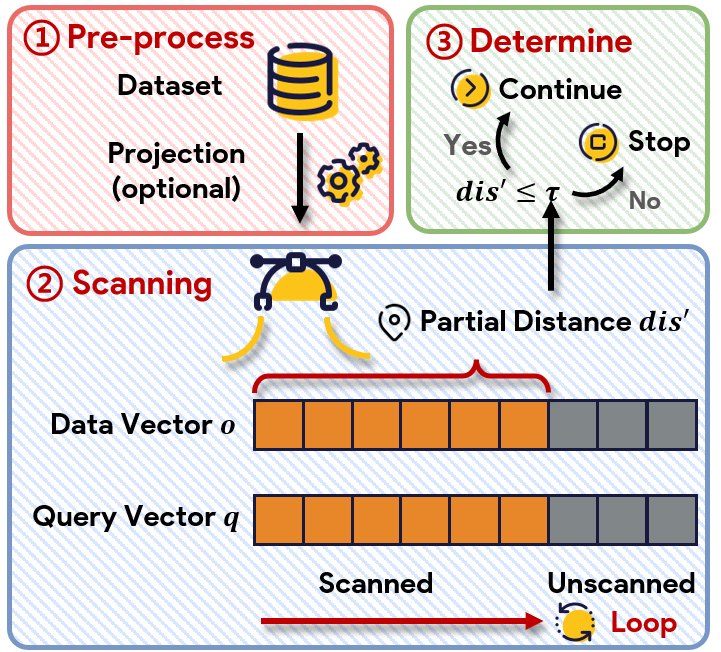
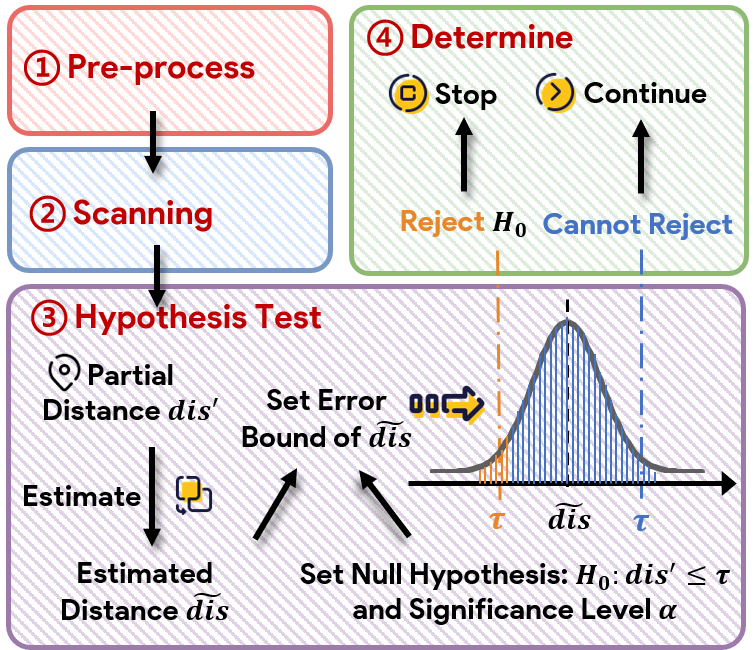
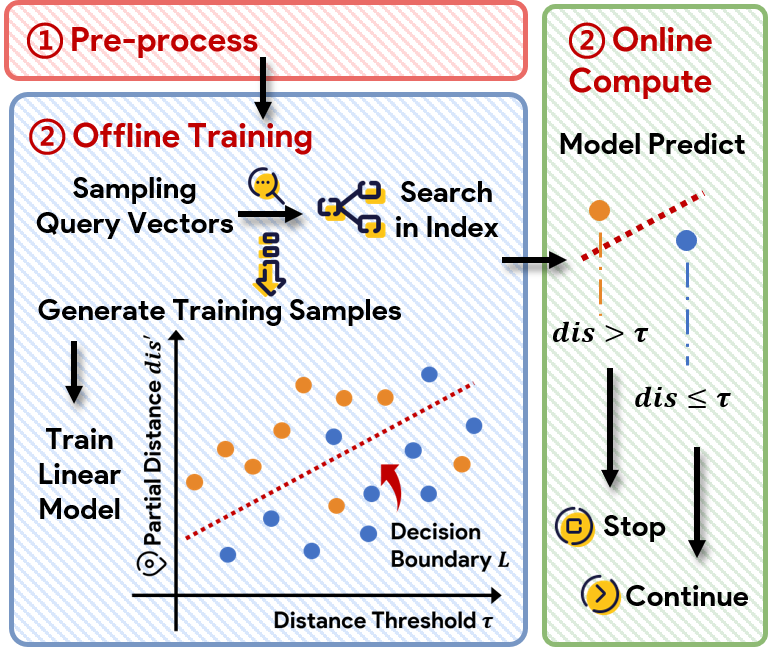
Figure 2: The core "simple method" workflow for DCOs, scanning and early stopping per-dimension.
Experimental Protocol and Coverage
The evaluation in (2604.02801) is distinct in breadth: it spans 8 DCO algorithms, 10 datasets (ranging 96–12,288 dimensions and sizes up to 108 vectors), and various hardware including CPU (with/without SIMD) and GPU. Crucial scenarios include in-distribution queries, extreme out-of-distribution (OOD) queries (especially on multimodal data), index construction, and dynamic updates (insertions).
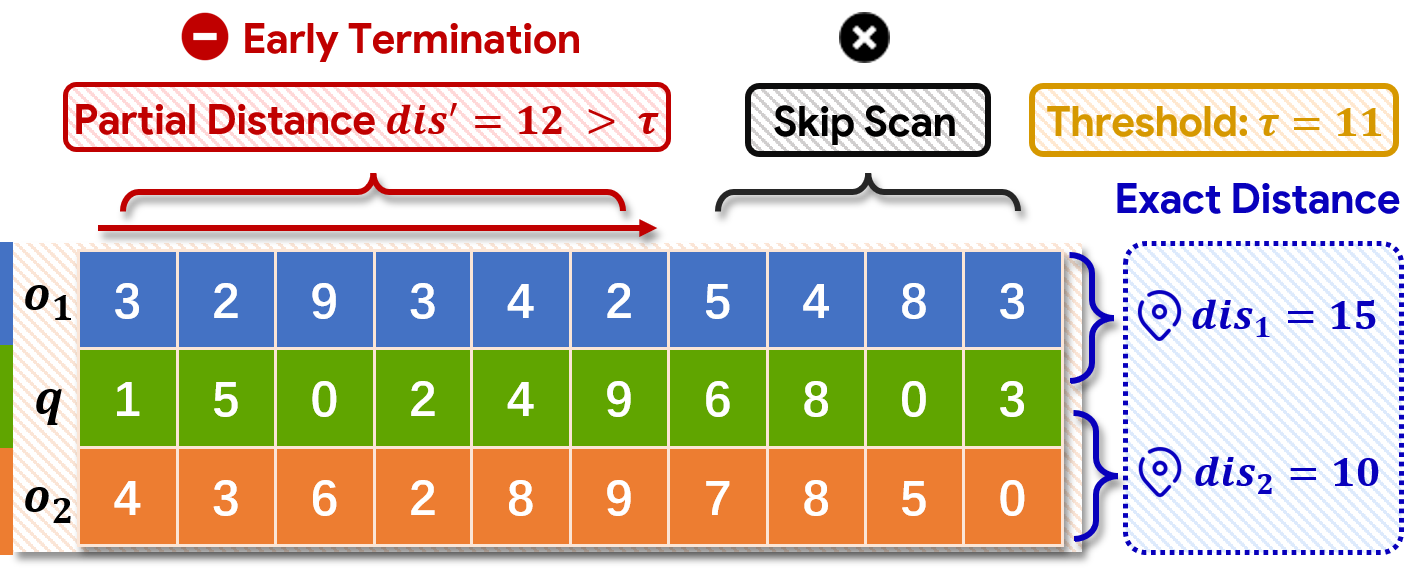
Figure 3: Examples of DCO instances, demonstrating early distance comparison without full scan.
Critical Results and Empirical Findings
Dependence on Dimensionality
The benchmark demonstrates that DCO efficacy is tightly dimension-dependent:
- On moderate dimensions (∼100–1000), well-optimized DCOs can outperform FDScanning, with speedups up to 2×.
- On low (≪100) or ultra-high (≫1000) dimensions, overheads of decision logic (e.g., projections, model inference) dominate, marginalizing or reversing any purported speedup.

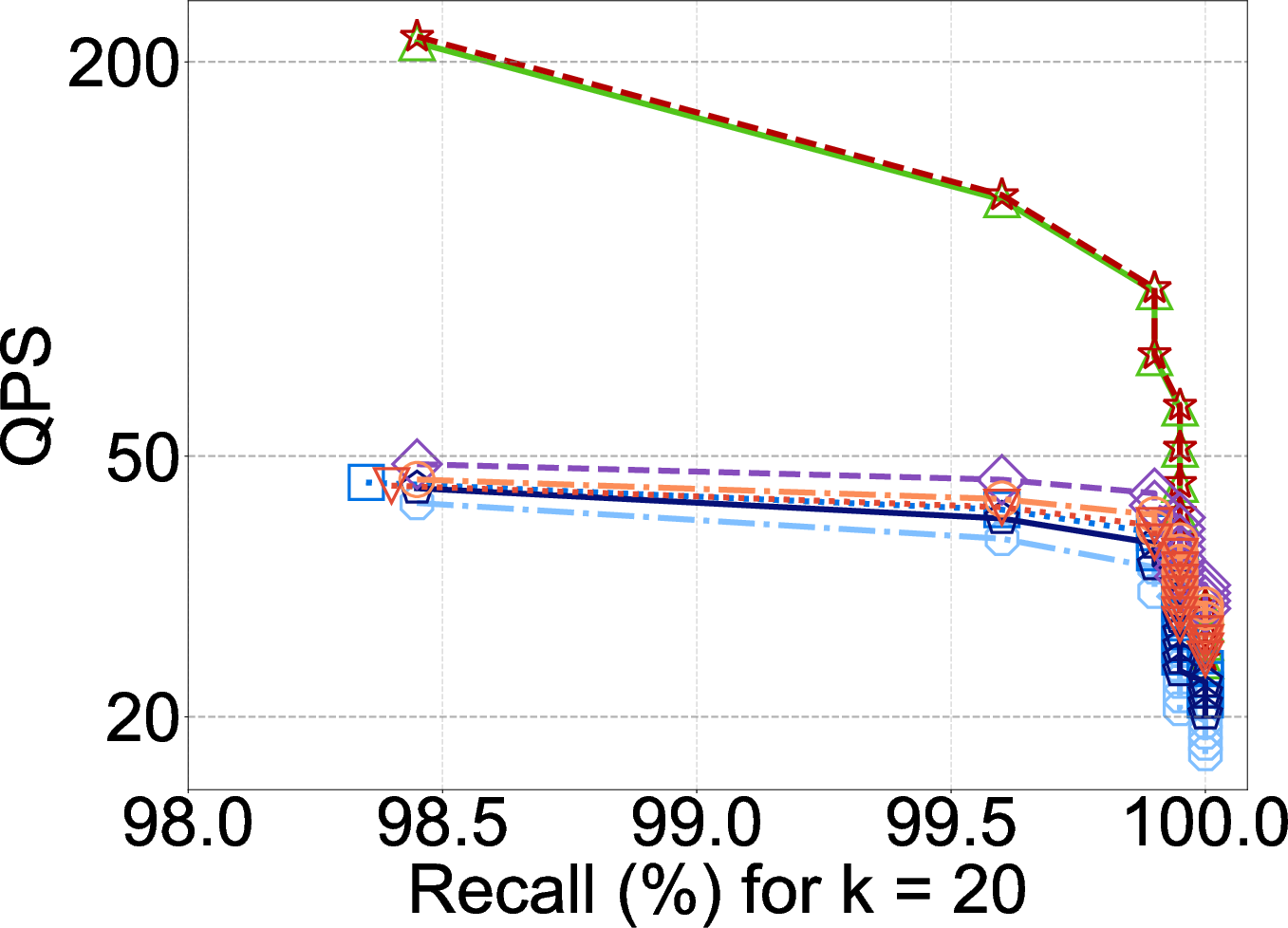
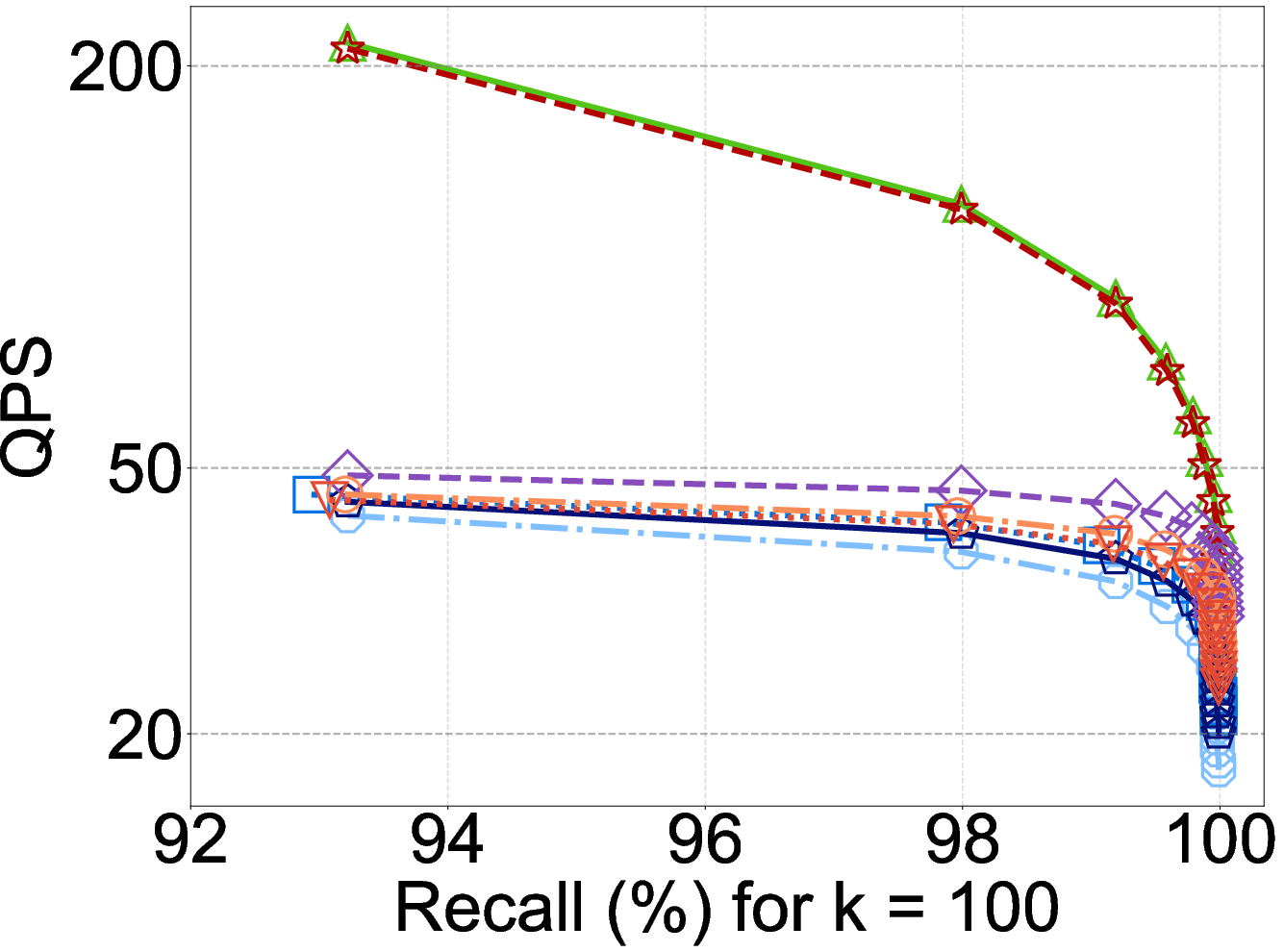
Figure 4: On ultra-high-dimensional datasets like XUltra (12,288d), FDScanning and basic PDScanning outperform SOTA DCOs due to overwhelming preprocessing costs.
Robustness and Practicality under OOD and Hardware Variance
Experiments on OOD queries reveal severe degradation for hypothesis and classification DCOs, often falling behind FDScanning in QPS due to reduced prediction accuracy and limited dimension pruning.
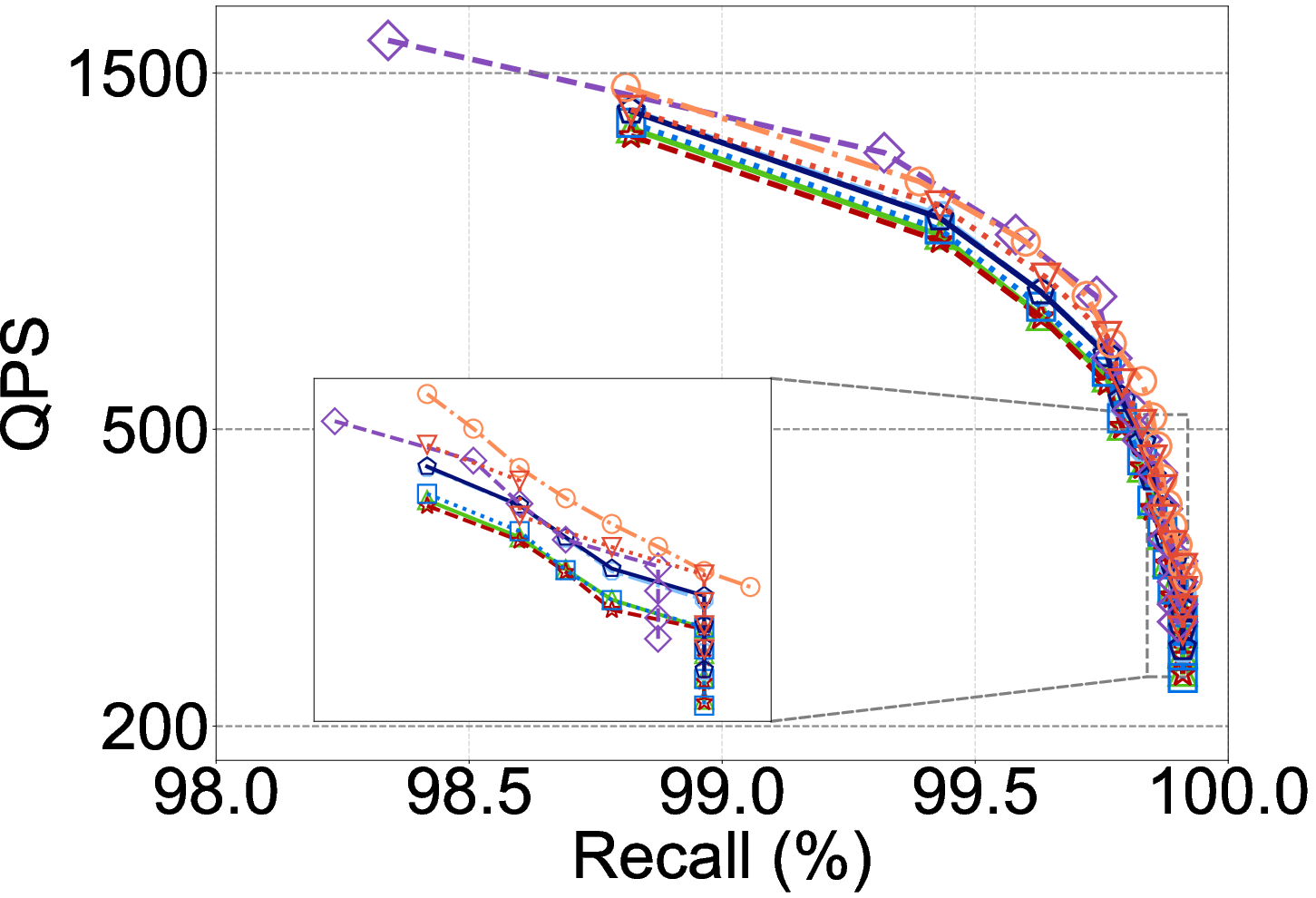
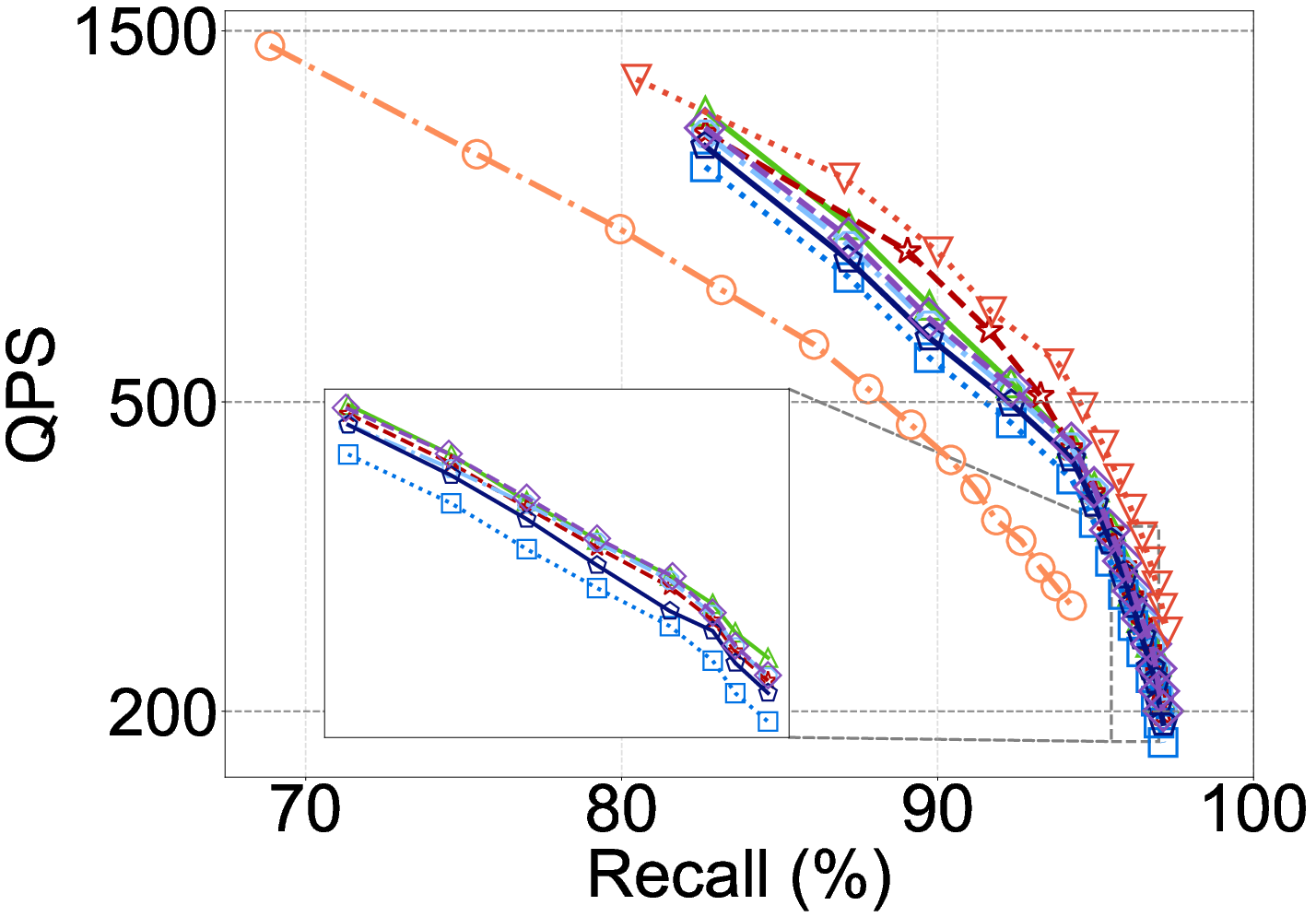
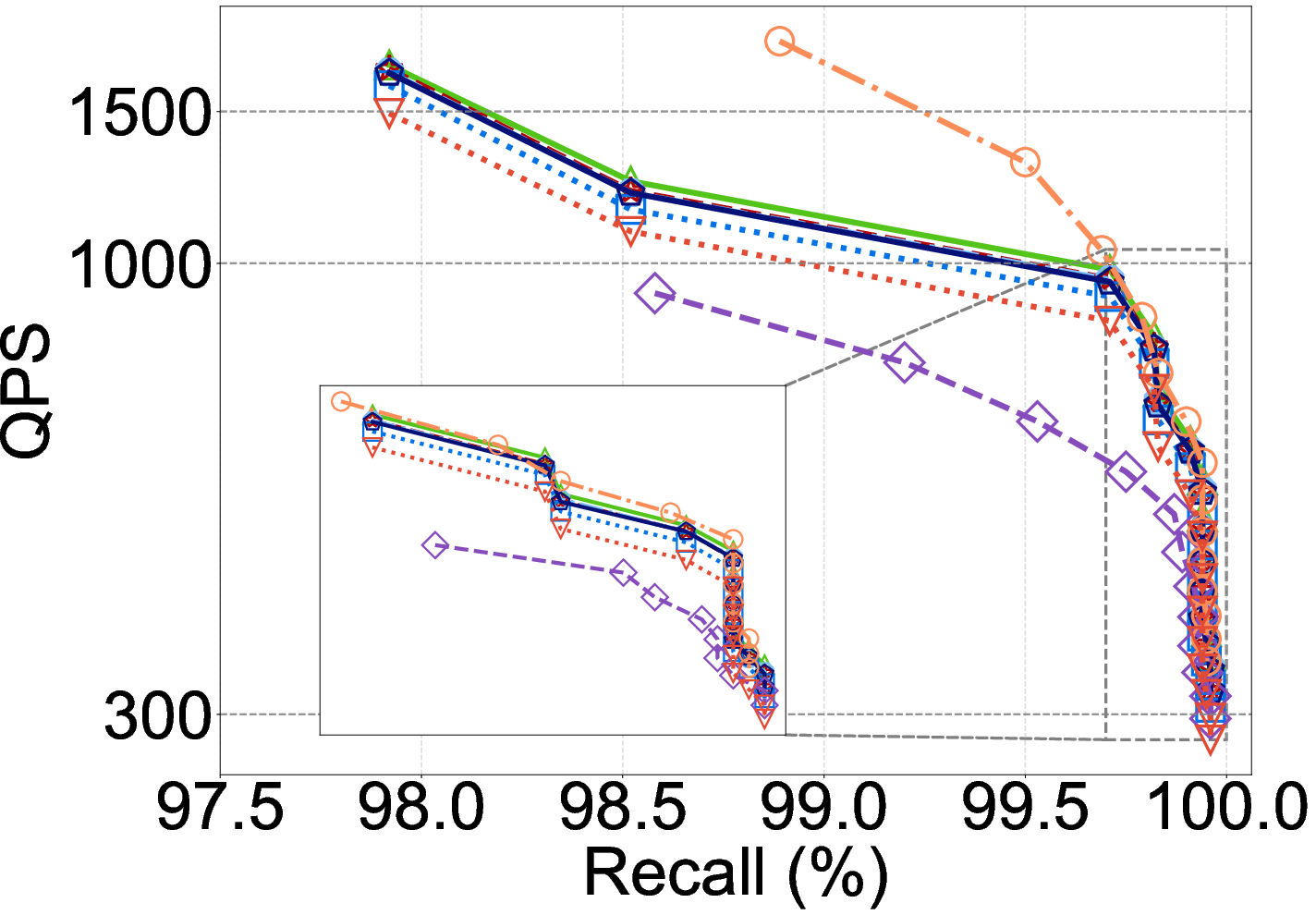
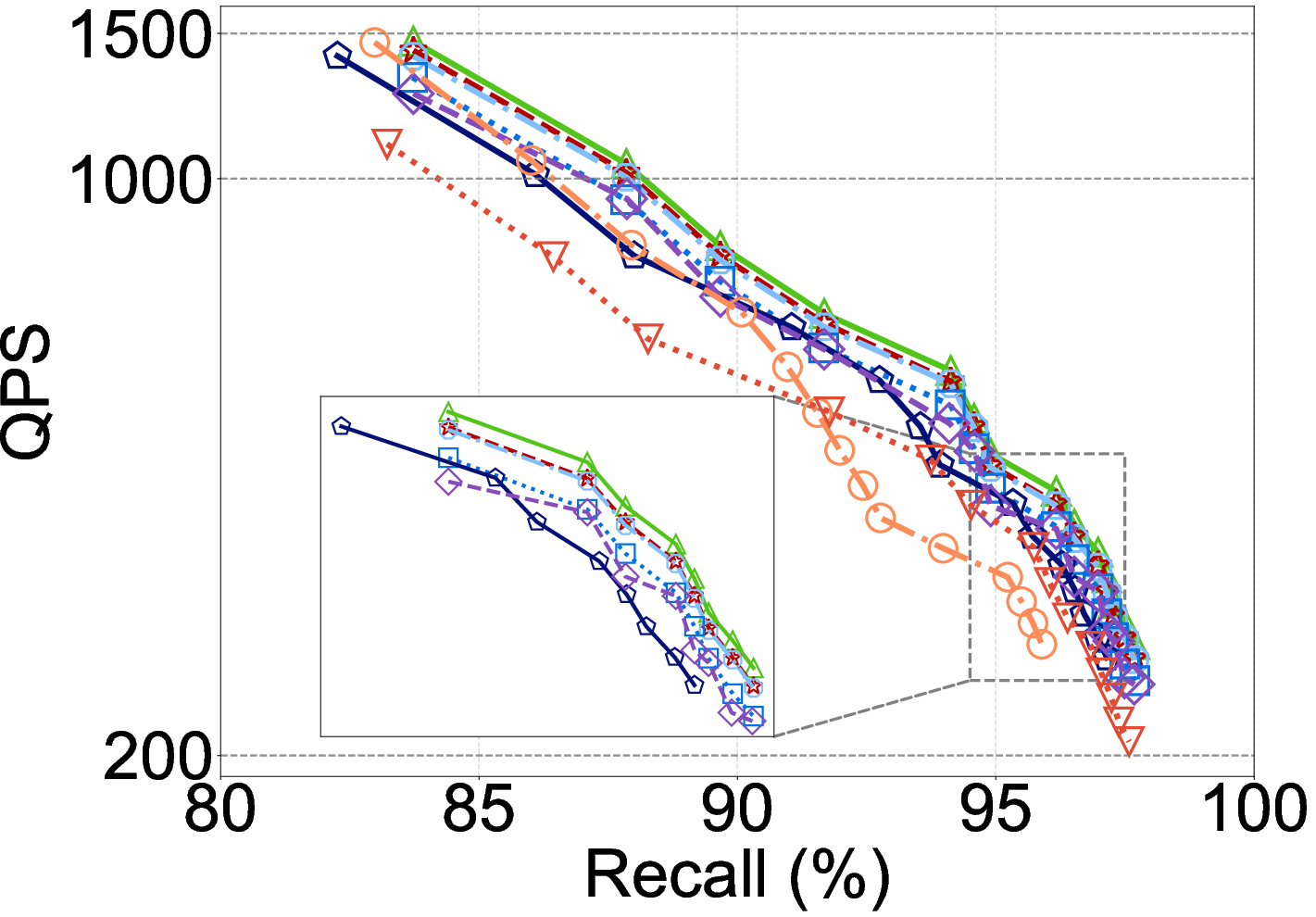
Figure 5: DCO method efficacy on the Laion dataset (in-distribution): SOTA DCOs show benefit, but this collapses under OOD.
Moreover, SIMD and GPU support on modern hardware substantially increases throughput for all methods, but narrows or inverts DCO advantage:
- With SIMD, FDScanning’s QPS is dramatically increased, closing the gap to DCOs. On certain settings, enabling SIMD flips DDCopq and similar DCOs from slowest (CPU w/o SIMD) to fastest methods.
- On GPU-accelerated IVF, batch parallelism can make DCO overheads negligible versus FDScanning, allowing high-dimensional matrix operations to amortize projection/model cost.
Index Construction and Dynamic Operations
DCOs provide nontrivial acceleration for index building (notably HNSW and IVF), shown to reduce construction time by 30–60% on high-d datasets, with negligible fidelity loss in search results.
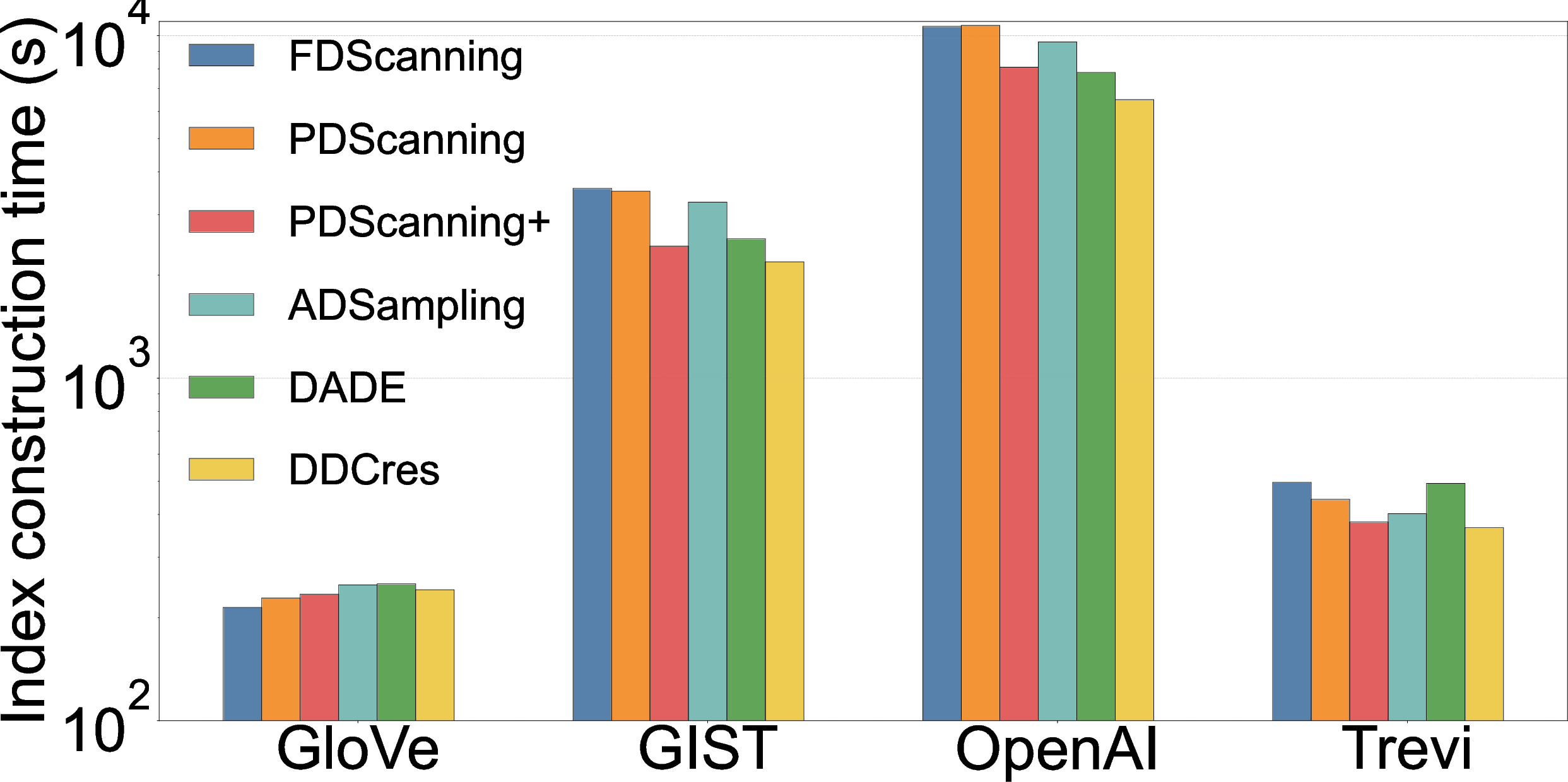
Figure 6: DCOs deliver index construction speedups, especially for high-dimensional data.
Dynamic updates are also accelerated by DCOs; performance, however, hinges on the stability of dimension pruning ratios as datasets grow and on the availability of sufficient training data for classification-based DCOs.
No Universal Winner
There is no globally dominant DCO method: the optimal DCO depends on the interplay of vector dimension, query distribution, hardware, index, and whether the operational bottleneck is memory access, compute, or decision logic.
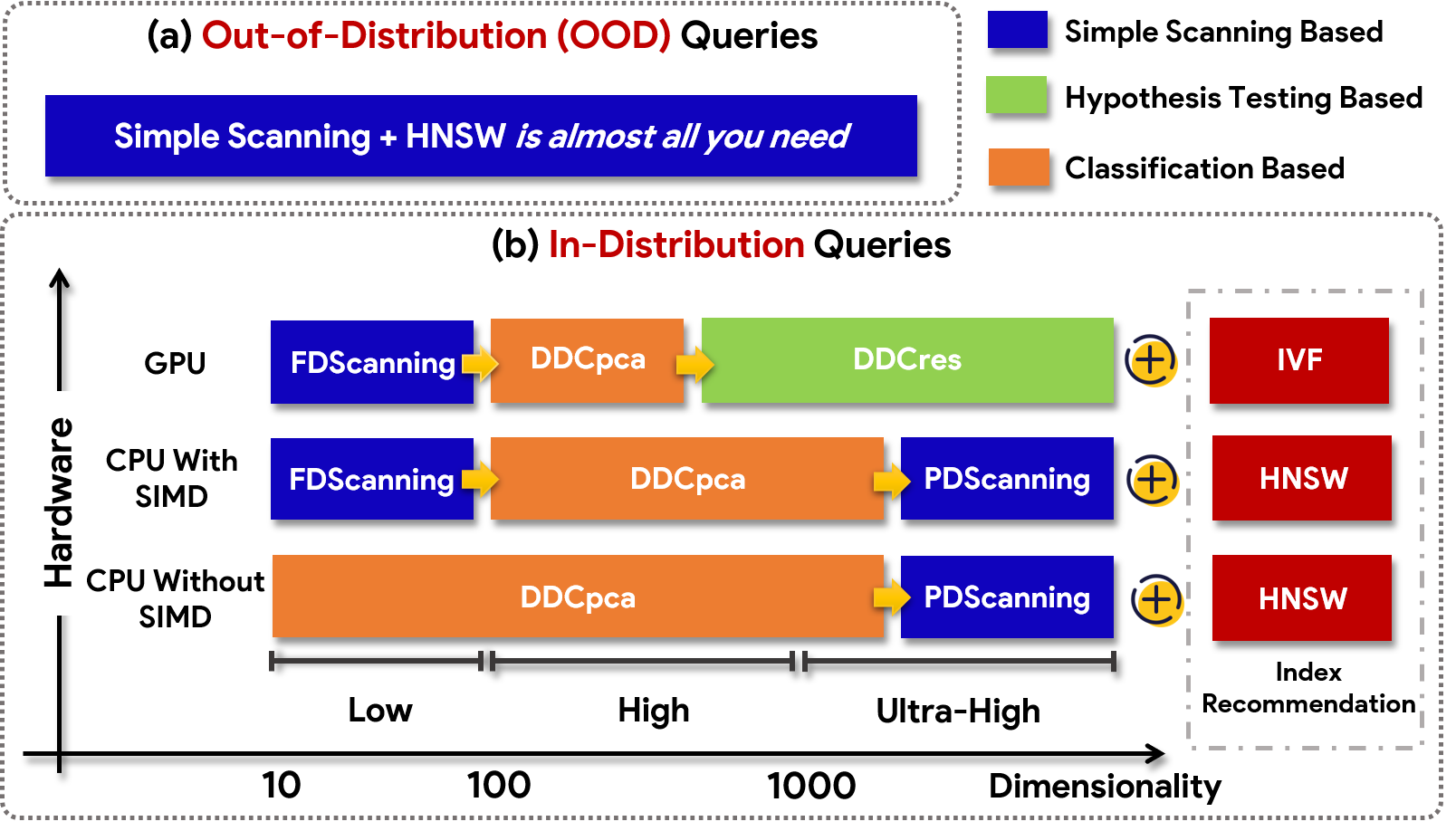
Figure 7: High-level guidelines for DCO method selection, emphasizing the role of dimensionality, hardware, and distribution.
Theoretical and Practical Implications
Limits of Generalization
The empirical observations highlight several theoretical constraints of current DCO paradigms:
- Most methods favor Euclidean/IP metrics due to mathematical tractability—the extension to arbitrary metrics is nontrivial.
- Classification/hypothesis-testing DCOs generally assume stationary data/query distributions, failing in OOD or highly nonstationary workloads.
- O(D2) pre-processing (PCA, feature rotation, model inference) rapidly dominates as dimension increases, contravening scalability in typical deep embedding spaces.
Hardware-Aware Algorithm Design
Performance gains from SIMD and GPU acceleration suggest that low-level hardware features must be a primary consideration. Algorithmic design in this context should target memory coalescence, vectorized arithmetic, and cache locality—perhaps combining early-termination logic with direct vector math rather than complex probabilistic bounds.
Directions for Future Research
Findings in (2604.02801) motivate immediate challenges:
- Dimension-Adaptive DCOs: Design DCO logic explicitly parameterized by dimensionality, perhaps switching mechanisms or pruning strategies dynamically.
- Robust OOD DCOs: Deriving data-agnostic or robust learning-based DCOs with provable performance under distributional shift.
- Heterogeneous Metric Support: Extending to non-Euclidean and application-specific metrics common in domain-adapted embeddings.
- Hardware-Algorithm Co-design: Treating SIMD/GPU as algorithmic primitives, not afterthoughts, in both theoretical and empirical analysis.
Conclusion
The benchmark and analysis in "Distance Comparison Operations Are Not Silver Bullets in Vector Similarity Search" demonstrate that, despite promising gains in select regimes, modern DCO methods are not ready for universal adoption in production vector DBMS. For many scenarios—especially extreme dimensionality, OOD, or hardware-accelerated deployments—simple FDScanning or PDScanning remain competitive or superior. The study not only cautions against overgeneralization from narrow benchmarks but also seeds new lines of investigation in hardware-aware, OOD-robust, and dimension-adaptive approximate search.
Reference:
"Distance Comparison Operations Are Not Silver Bullets in Vector Similarity Search: A Benchmark Study on Their Merits and Limits" (2604.02801)