- The paper presents LISO, a Laplace-based importance sampling estimator that achieves improved error decay rates for zero-order global optimization over standard random search.
- The method uses weighted averaging and an adaptive sampling scheme to refine the search for the global minimizer without incurring extra function evaluations.
- Empirical and theoretical analyses demonstrate that LISO significantly outperforms grid search and traditional Evolution Strategies, especially in high-dimensional, nonconvex landscapes.
Importance Sampling Optimization with Laplace Principle: An Expert Analysis
Problem Statement and Motivation
The paper "Importance Sampling Optimization with Laplace Principle" (2604.02882) addresses zero-order global optimization of nonconvex functions in Rd where gradient information is unavailable or impractical to compute. This paradigm is central to hyperparameter tuning in machine learning, policy search in RL, and parameter estimation in dynamical systems. Classical approaches such as grid search and random search select the best-performing configuration from a finite sample, but these methods exhibit poor scaling with dimensionality, specifically an error decay rate of O(n−1/d) for n sample evaluations.
The paper proposes a novel refinement: instead of taking the argmin of observed function values, evaluated points are combined via a weighted average, with weights derived from importance sampling using the Laplace principle. This construction is computationally frugal and compatible as a post-processing step atop random search, requiring no additional function evaluations. Moreover, an adaptive, iterative extension—reminiscent of Evolution Strategies (ES)—further refines sampling to exploit prior results.
Algorithmic Contributions
The core algorithm, termed Laplace Importance Sampling Optimization (LISO), implements the following estimator:
xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),
where α>0 controls concentration, and q0 is the initial sampling distribution. This estimator is inspired by approximating the expectation under the Boltzmann distribution πα(x)∝exp(−αf(x)); for large α, πα concentrates near the global minimizer x∗ by the Laplace principle.
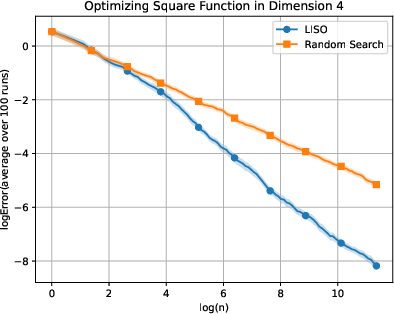
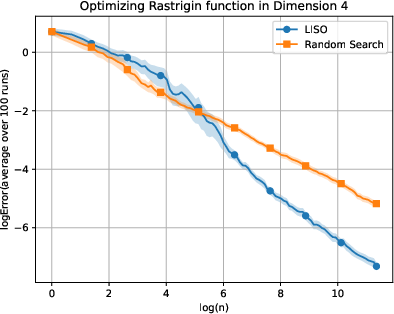
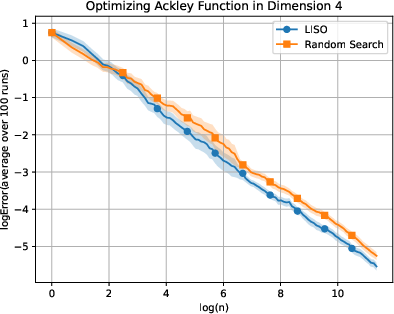
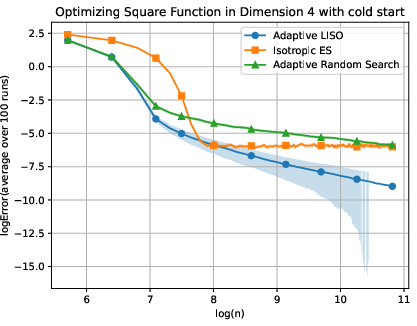
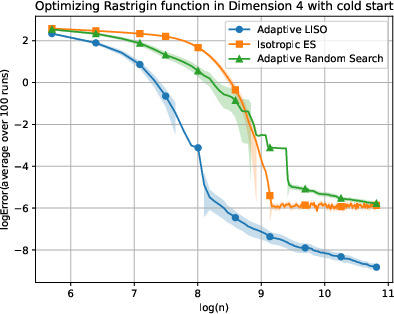
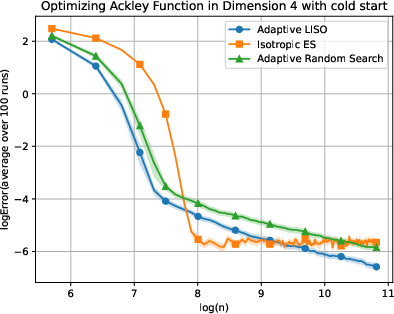
Figure 1: Comparative performance plots for static (top) and adaptive (bottom) methods on toy functions O(n−1/d)0, O(n−1/d)1, O(n−1/d)2 in O(n−1/d)3.
The adaptive variant iteratively updates the sampling policy as a mixture of a Gaussian centered at the previous weighted estimate and the original distribution, fostering both exploitation and exploration:
O(n−1/d)4
where O(n−1/d)5 is updated at each stage using the same importance sampling scheme.
Theoretical Analysis
The paper establishes rigorous error bounds for the LISO estimator under smoothness and integrability assumptions on O(n−1/d)6 and O(n−1/d)7. The main result (informally, Theorem 1) states that for O(n−1/d)8 samples and optimal O(n−1/d)9,
n0
which asymptotically outperforms random search and grid search rates of n1 whenever n2. The proof leverages the Laplace principle: for large n3, integrals of n4 are dominated by neighborhoods near n5, leading to reduced bias and variance in the estimator.
In greater generality, the adaptive LISO mechanism maintains similar theoretical guarantees regardless of the family of sampling policies, assuming heavy-tailedness to ensure sufficient exploration. The analysis highlights the crucial dependence of the error rate on the probability mass of n6 (or n7) near n8; adaptive strategies are theoretically motivated to increase this mass iteratively.
Numerical Experiments
Empirical results are presented on canonical optimization benchmarks: Sphere (n9), Rastrigin (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),0), and Ackley (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),1) functions. Static non-adaptive and adaptive methods are compared over various dimensions (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),2). The paper benchmarks LISO and adaptive LISO against random search, adaptive random search (selecting the best-so-far), and isotropic ES (a simplified CMA-ES variant).
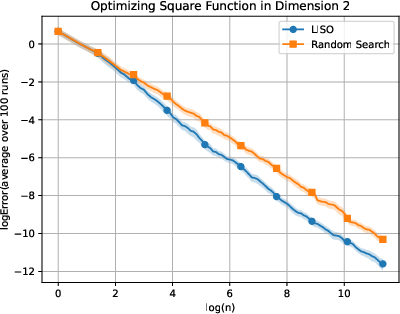
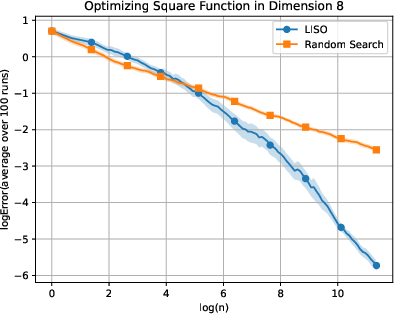
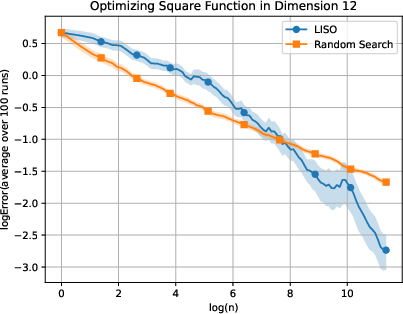
Figure 2: Static performance on the Square (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),3) function for varying dimension.
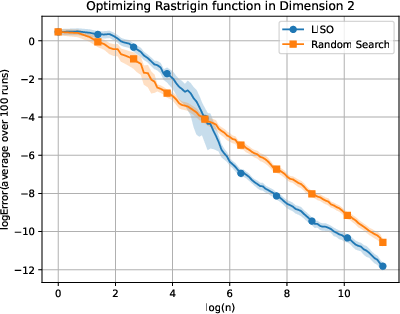
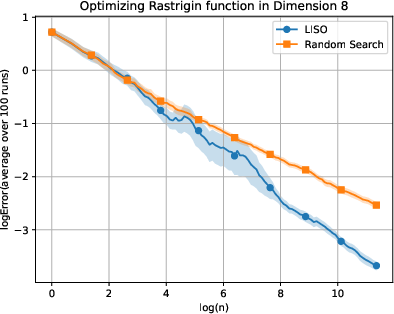
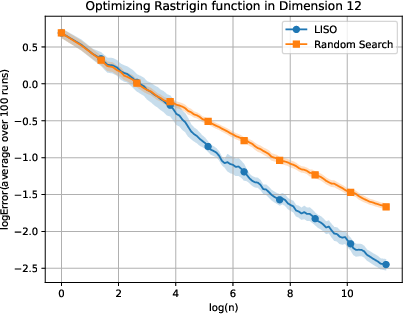
Figure 3: Static performance on the Rastrigin (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),4) function for varying dimension.
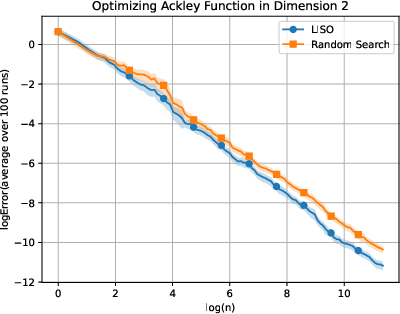
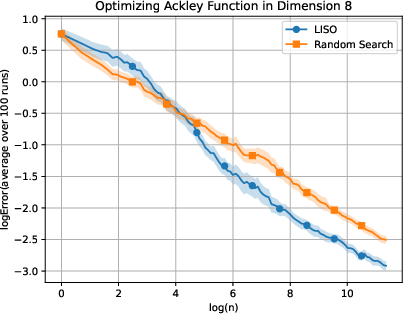
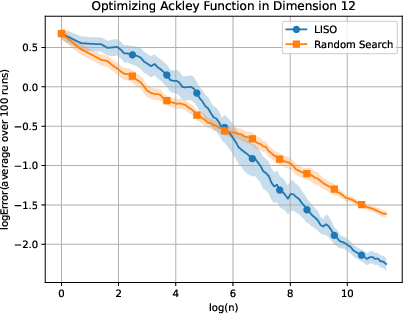
Figure 4: Static performance on the Ackley (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),5) function for varying dimension.
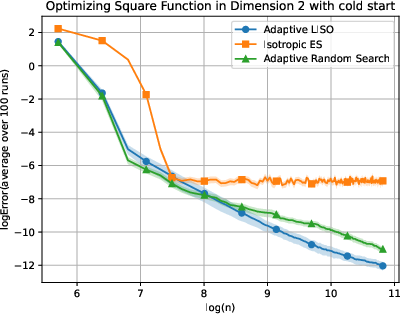
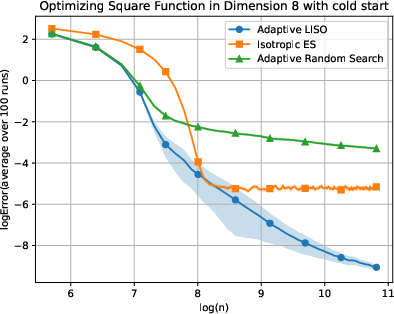
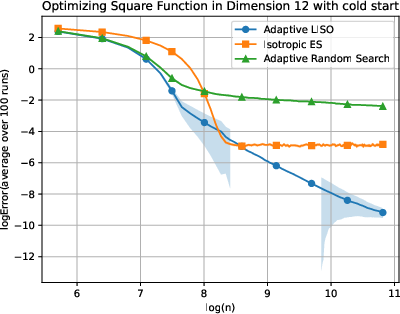
Figure 5: Adaptive LISO performance on the Square (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),6) function with cold start.
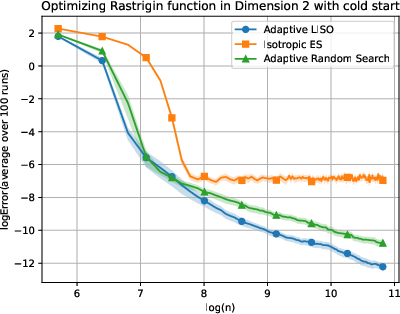
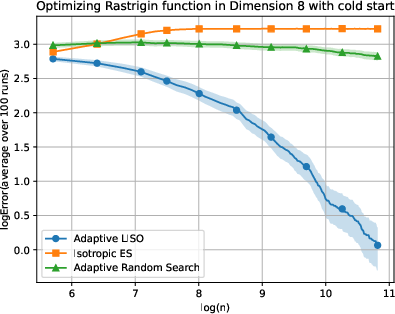
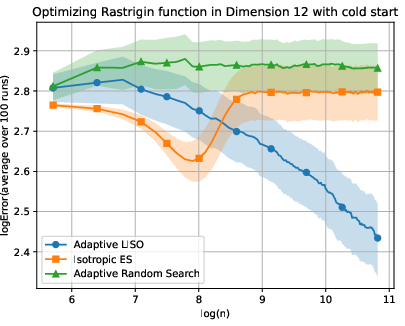
Figure 6: Adaptive LISO performance on the Rastrigin (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),7) function with cold start.
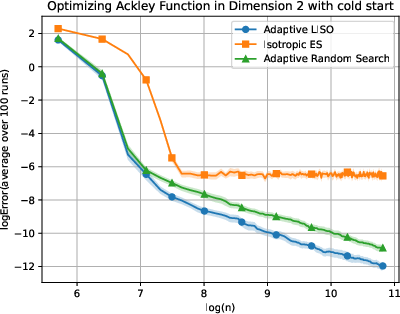
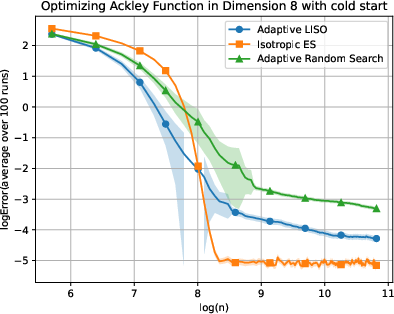
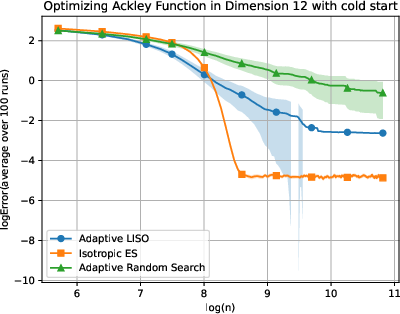
Figure 7: Adaptive LISO performance on the Ackley (xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),8) function with cold start.
LISO exhibits superior sample efficiency in both static and adaptive settings, especially for quadratic functions where the Laplace principle holds exactly: empirical decay rates mirror theoretical predictions. On multimodal landscapes (Rastrigin, Ackley), adaptive LISO demonstrates rapid convergence phases as the sampling centroid moves closer to the minimizer, outperforming non-adaptive methods and rank-based averaging strategies utilized in ES.
The study notes that ES methods progress faster during exploratory phases but eventually plateau due to limited particle count, whereas adaptive LISO maintains consistent improvement, leveraging an evolving particle base.
Implications, Limitations, and Future Directions
The main implication is that Laplace-based importance-sampled averaging achieves faster convergence in global optimization than argmin-based random search, with profoundly better scaling in high dimensions. Because this approach is compatible as a post-processing tool, it could enhance existing optimization pipelines in machine learning, reinforcement learning, or scientific parameter estimation, especially when function evaluation dominates computation.
From a theoretical standpoint, the results articulate the fundamental advantage afforded by the Laplace principle in concentration of measure for optimization, provided local convexity and smoothness near the global minimizer. The method also suggests potential integration into more sophisticated adaptive frameworks (e.g., full CMA-ES with covariance updates), extending utility to ill-conditioned or anisotropic surfaces.
Limitations arise from the assumptions: uniqueness of xn=∑i=1nwi∑i=1nwiXi,wi=q0(Xi)exp(−αf(Xi)),9 and local strong convexity are essential, both for theoretical error bounds and practical efficacy. Functions with multiple minima or lacking any convex neighborhood may not be amenable; future work is required to extend results to Polyak-Łojasiewicz or more general classes.
Possible future avenues include:
- Covariance adaptation in the sampling distribution, enabling tailored exploitation in the presence of ill-conditioned or correlated landscapes
- Application to non-unique minimizers and analysis under weaker convexity
- Integration with model-based optimization (e.g., Bayesian optimization) for hierarchical or mixed-variable problems
Conclusion
"Importance Sampling Optimization with Laplace Principle" (2604.02882) presents a principled, computationally efficient global optimization scheme that leverages importance-sampled averaging based on the Laplace principle. Theoretical analysis shows substantially improved scaling with sample count and dimension relative to classical random search, and empirical evaluation validates these findings across multiple benchmark functions. The simplicity and practical compatibility of the method make it a promising augmentation for randomized optimization algorithms under the zero-order, expensive-evaluation regime. Further refinement is possible via adaptive covariance schemes, extension to broader function classes, and deeper integration into advanced optimization workflows.

