- The paper introduces a formal methodology based on actual causality to define, extract, and measure minimal sufficient audio signals using frequency masking and intervention analysis.
- The experiments reveal low transferability of minimal sufficiencies in music genre and emotion tasks while demonstrating high agreement in deepfake detection, exposing outlier 'flat-earther' models.
- The findings underscore the importance of causal analysis in assessing model trustworthiness and identifying potential vulnerabilities for adversarial audio attacks.
Introduction and Motivation
This paper addresses the underexplored question of whether minimal sufficient audio signals—those subsets of the frequency domain strictly necessary for a target model’s classification—transfer to other models trained for the same task. Using causal inference grounded in the formalism of actual causality, the authors systematically define "sufficiency" and "completeness" for signals, operationalize metrics of transferability, and conduct experiments across three application domains: music genre classification, voice emotion recognition, and audio deepfake detection.
The approach rests on actual causality, not on human interpretability or post hoc explanations. Sufficient subsets in the frequency domain are identified via frequency masking and intervention analysis; a subset is minimal if its removal (or replacement) alters the model output. To guarantee rigor, sufficiency and completeness are precisely defined: a complete subset is simultaneously sufficient and necessary and may also enforce a minimal confidence constraint, denoted as δ-completeness. Crucially, the framework does not assume uniqueness—multiple disjoint subsets can satisfy the sufficiency definition per input.
For transferability, the paper proposes a robust metric: a sufficient signal from model f is transferable to a set of models M if their top-1 prediction matches f’s and the output entropy (H) is below a task-adaptive threshold ϵ⋅log(n), where n is the number of classes, ensuring nontrivial confidence.
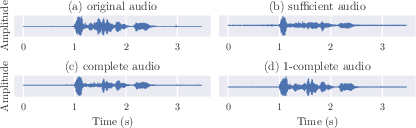
Figure 1: Partitioning of the 'disgust' audio signal into sufficient, complete, and 1-complete signals, highlighting minimality conditions and the focus of transfer analysis.
Experimental Design
Thirteen models with divergent backbones and supervised learning protocols are benchmarked across four datasets: RAVDESS (emotion), GTZAN (genre), ASVspoof2019, and ITW (deepfake detection). All frequency domain manipulations ensure periodicity, and post hoc manipulations enforce minimum confidence on occlusion outputs to avoid spurious results. The sufficiency discovery uses the f tool, leveraging actual causality and stable subset selection for reproducible and minimal explanations.
For each dataset and model, both sufficient and complete signals are extracted. Their transferability rates (α) are measured across the model ensemble. In the spoof detection context, the analysis is extended to composite signals, spectral entropy, and power spectral density.
Main Results: Transferability Patterns and Outlier "Flat-Earther" Models
Emotion (RAVDESS) and Genre (GTZAN) Classification
Transferability rates for minimal sufficiencies are generally low for music genre classification (mean ≈0.26) and lower for voice emotion ($0.11$–f0, depending on signal definition and model pairing). Complete signals exhibit marginally higher transferability than sufficiencies, but paired tests do not always reject the null hypothesis of similar means.
Strong inter-model variance is observed (e.g., VCf1 shows consistently atypical transfer behavior—its sufficiencies are nontransferable and it seldom accepts those from peers). Such outlier models are termed "flat-earthers"—a model may externally appear performant (similar test accuracy), yet its information consumption diverges fundamentally.
Deepfake (Spoof) Detection
In contrast, spoof detection tasks report higher transferability rates (often f2 between similar models, sometimes over f3), but again selective nontransfer (e.g., SPf4) is observed. Here, overfitting artifacts and training set overlap influence not only accuracy but the transferability landscape, with models trained on ASVSpoof2019 transferring poorly to the OOD ITW dataset.
Composite sufficient signals for "real" and "fake" classes reveal systematic spectral structure differences across models and datasets. Notably, spectral entropy and power distribution diverge between the categories, with the sign and magnitude model-specific.
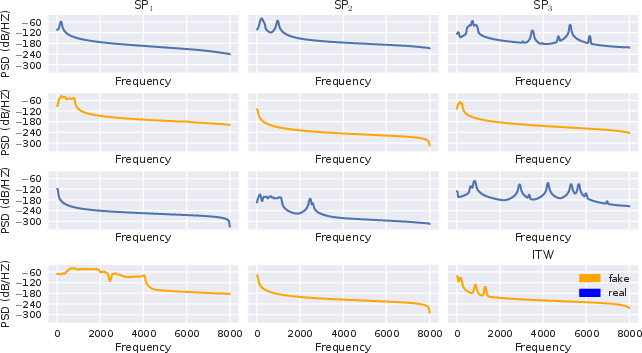
Figure 2: Power spectral density for real and fake sufficiency composites on ASVSpoof2019 (top) and ITW (bottom), illustrating model-dependent distinctions.
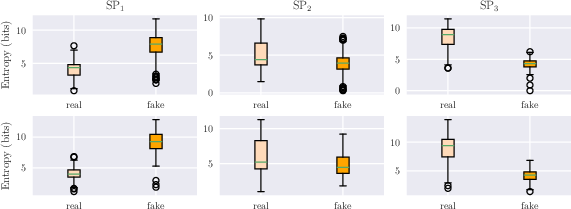
Figure 3: Spectral entropy distributions for real vs. fake, highlighting inter-model and dataset specificity in entropy patterns.
Statistical significance is robust (Mann-Whitney U test, f5 in all cases).
Speech Recognition Probes
Textual fidelity of sufficient and complete signals—measured with Levenshtein ratio using an external ASR model—remains very high (f6). However, the STOI measure on "inverse" signals (input with the complete signal excised) varies substantially. For SPf7, intelligible speech remains, indicating an incomplete accounting of speech-relevant frequencies in the purportedly complete signal; for SPf8 and SPf9, the opposite is the case.
Theoretical and Practical Implications
The divergence in sufficiency transfer rates across tasks indicates that high accuracy does not imply internal agreement between architectures, nor does training on the same data guarantee shared representations. The presence of "flat-earther" models, indistinguishable by traditional performance metrics but revealed by transfer analysis, undercuts naive assumptions that classifier congruence means mechanism-level alignment.
Pragmatically, when deploying ensembles (especially for sensitive tasks such as deepfake or fraud detection), relying solely on accuracy or F1 measures may mask substantial internal logic heterogeneity, which could have significant consequences in adversarial settings or deployment on out-of-distribution data. In particular, higher spoof task transferability suggests these models focus on shared low-level artifacts, possibly induced by generative modeling procedures, in line with independent studies of FFT artifacts in "fake" audio.
Theoretically, this work highlights the utility of actual causality for probing model epistemology. The observation that sufficient and complete signals are often not unique and may not overlap across architectures provides a compelling argument for further formalism in understanding model "reasons," especially when model populations are used.
Adversarial Transfer and Black-Box Attacks
The observed transferability rates (M0–M1) map closely to rates reported in black-box adversarial attacks on audio models, suggesting that minimal sufficiencies may often serve as a substrate for attack design. Establishing this link more concretely—by empirically verifying that transferable sufficiencies correspond to interpretable black-box vulnerabilities—would be an important direction for future research.
Future Directions
Several critical questions remain:
- Multiplicity of Sufficiencies: The analysis here considers one sufficiency per (model, input) pair. Systematic analysis of the full space of minimally sufficient signals would inform the lower bound of model agreement.
- Task-Specific Inductive Biases: Spoof detection’s high transferability (relative to genre and emotion) must be dissected in terms of input entropy, label space, and latent task difficulty.
- Purpose-Built Deepfake Detectors: Comparing generic pre-trained and fine-tuned models to architectures designed ab initio for deepfake discrimination could validate whether the observed transfer patterns are architectural or data-driven.
- Link to Explanatory Stability: The links between transferability, adversarial vulnerability, and explanation stability remain largely uncharted and are ripe for formalization.
Conclusion
This paper delivers a theoretically rigorous and empirically thorough analysis of the transferability of causal audio sufficiencies and necessity signals across contemporary deep models. It introduces a formal framework for sufficiency transfer, demonstrates significant inter-model heterogeneity—even among high-performing models—and identifies categories of outlier architectures whose internal reasoning is non-transferable but conventionally "valid" by standard metrics. These insights demand a more nuanced perspective on evaluations of model trustworthiness, robustness, and alignment, especially in settings where model disagreement or adversarial exposure is expensive.