Detecting and Correcting Reference Hallucinations in Commercial LLMs and Deep Research Agents
Abstract: LLMs and deep research agents supply citation URLs to support their claims, yet the reliability of these citations has not been systematically measured. We address six research questions about citation URL validity using 10 models and agents on DRBench (53,090 URLs) and 3 models on ExpertQA (168,021 URLs across 32 academic fields). We find that 3--13\% of citation URLs are hallucinated -- they have no record in the Wayback Machine and likely never existed -- while 5--18\% are non-resolving overall. Deep research agents generate substantially more citations per query than search-augmented LLMs but hallucinate URLs at higher rates. Domain effects are pronounced: non-resolving rates range from 5.4\% (Business) to 11.4\% (Theology), with per-model effects even larger. Decomposing failures reveals that some models fabricate every non-resolving URL, while others show substantial link-rot fractions indicating genuine retrieval. As a solution, we release urlhealth, an open-source tool for URL liveness checking and stale-vs-hallucinated classification using the Wayback Machine. In agentic self-correction experiments, models equipped with urlhealth reduce non-resolving citation URLs by $6\textrm{--}79\times$ to under 1\%, though effectiveness depends on the model's tool-use competence. The tool and all data are publicly available. Our characterization findings, failure taxonomy, and open-source tooling establish that citation URL validity is both measurable at scale and correctable in practice.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a simple question with big consequences: when AI tools (like chatbots and “deep research” assistants) give you links to back up their claims, do those links actually work and point to real pages? The authors check how often these citations are broken or totally made up, and they build a small tool that helps catch and fix bad links.
Key ideas and terms (in plain language)
- Citation URL: A web link the AI uses to “prove” something it said.
- Non‑resolving URL: A link that doesn’t load (like typing an address that leads to a dead end).
- Hallucinated URL: A link that seems real but never existed at all (no record of it anywhere).
- Stale URL (link rot): A link that used to work but doesn’t anymore (like a store that closed down).
- Wayback Machine: An internet “time machine” that archives old versions of web pages so you can see if a page ever existed.
In short: non‑resolving = broken right now; hallucinated = probably never real; stale = used to be real but is now gone.
What questions did the researchers ask?
They studied six easy-to-understand questions:
- How common are bad or made‑up links in AI citations?
- Do “deep research” agents (that write long reports) make better or worse links than regular search‑assisted chatbots?
- Does link reliability change by subject area (like business vs. medicine)?
- When links fail, how much is because they were invented vs. because they rotted over time?
- Does giving more citations make each individual citation more trustworthy?
- Can a simple, after‑the‑fact link checker reduce bad links?
How did they do the study?
- Two datasets of questions:
- DRBench: 100 research queries (English and Chinese) to compare many models.
- ExpertQA: 2,177 expert‑written questions across 32 school/college subjects (like Business, Theology, Medicine).
- Models tested:
- “Deep research” agents from big providers that search in multiple steps and write long reports with lots of links.
- “Search‑augmented” chatbots that do a more basic search and give a few links.
- What they measured:
- They pulled out every URL the models cited (over 220,000 unique links across both datasets).
- They tried to load each link. If it failed (server errors/timeouts), they marked it non‑resolving (broken).
- For broken links, they checked the Wayback Machine. If there was no trace of the link at any time, they called it hallucinated (likely never existed). If there was a past snapshot, they called it stale (link rot).
- A small tool they built: urlhealth
- Think of it as a “link health check.” It labels links as LIVE, DEAD (stale), LIKELY_HALLUCINATED, or UNKNOWN.
- They then let models use this tool to check and fix their own citations in a self‑correction loop (try link → check → replace if bad → repeat).
Analogy: Imagine a student writing a report with addresses for each fact. The researchers walked to each address to see if a building exists. If the building’s gone but used to be there, that’s link rot. If there’s no record the building ever existed, the student made it up.
What did they find?
Here are the main takeaways, translated:
- How common are problems?
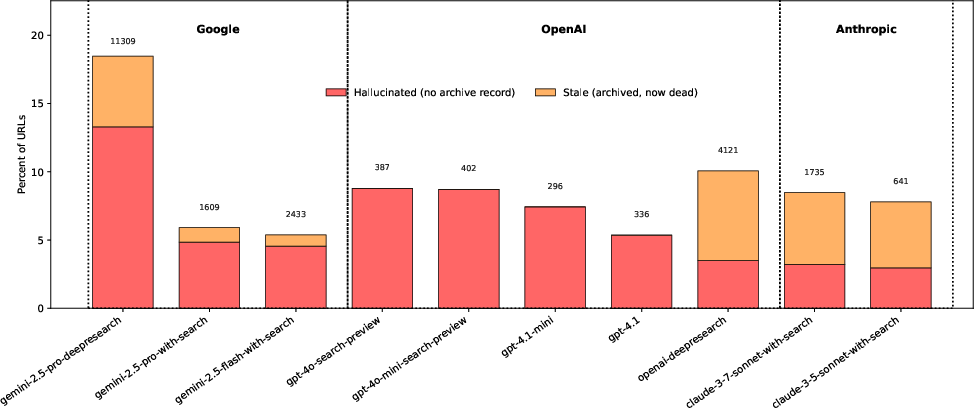
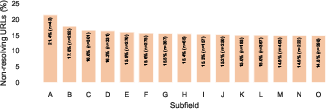
- Across many models, 5–18% of cited links didn’t work when tested.
- Of those, 3–13% were hallucinated (likely never existed at all).
- Deep research vs. search‑augmented chatbots
- Deep research agents gave many more links per answer (sometimes over 100!) but had higher rates of made‑up links.
- So, fancy multi‑step research didn’t automatically mean better citations.
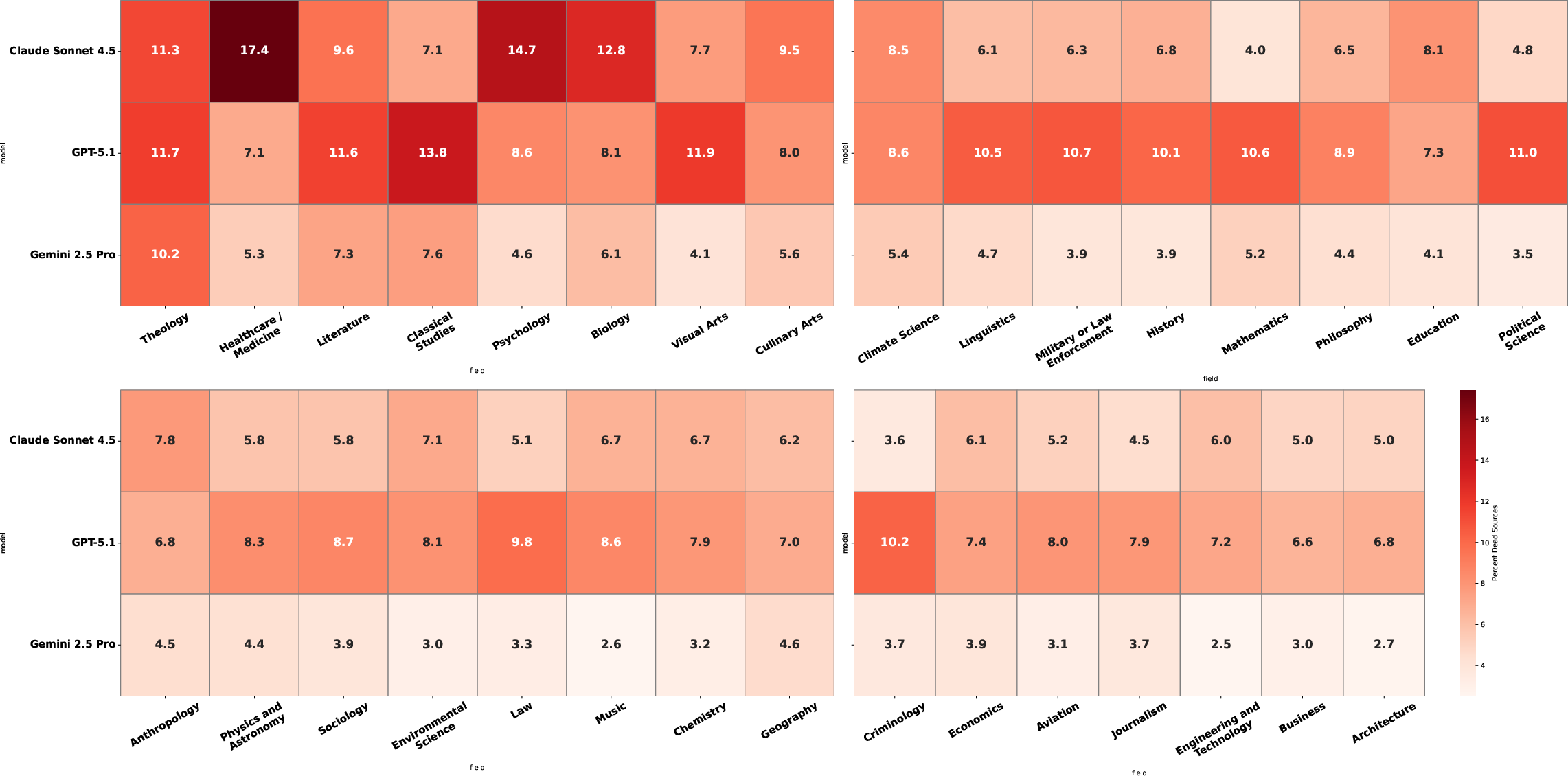
- Differences by subject
- Some fields were safer than others. For example, Business had fewer broken links (~5%), while Theology was higher (~11%).
- Medicine/Healthcare also had more trouble—worrying because mistakes here can be risky.
- Why links fail: made‑up vs. link rot
- Some models’ broken links were almost all hallucinated (invented).
- Others had many stale links, meaning they probably did real web searches but relied on pages that later disappeared.
- This matters because the fix is different: hallucinations need better grounding; stale links need freshness checks.
- More citations ≠ better citations
- Producing more links didn’t make each link more reliable. In fact, the models that cited the most often had higher error rates per link.
- Can we fix this?
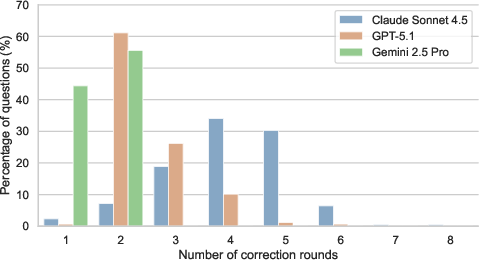
- Yes. When models used the urlhealth tool to check and replace their own links, bad links dropped by 6–79×, down to under 1% in final answers.
- However, this worked best when the model was good at using tools. Smaller/weaker models sometimes checked links but didn’t correct them properly.
Why is this important?
- People trust citations. Lawyers, researchers, and doctors have already run into problems because AI tools made up references.
- The study shows:
- The problem is measurable: we can check links at scale and tell whether they’re broken, stale, or invented.
- The problem is fixable: a simple, open‑source link checker plus a self‑correction loop can cut bad links to almost zero in the final output.
- What should happen next?
- AI systems should only cite links they actually visited (to prevent making up URLs).
- Tools like urlhealth should be used automatically after generation.
- Future work should also check that quoted text really appears on the cited page and that details like authors and DOIs are real—not just the URLs.
Bottom line
AI tools often include citations, but some are broken and some never existed. This study shows how often that happens across different systems and subjects, and it offers a simple, effective way to catch and fix these problems. With better design and automatic link checking, AI‑generated citations can become much more trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps that remain unresolved and can guide follow-up research.
- Dependence on the Wayback Machine as a proxy for existence: quantify and correct archive-coverage bias by triangulating multiple archives (e.g., Memento aggregator, archive.today, Perma.cc, Common Crawl), and build a human-validated gold set to calibrate false stale/hallucinated classifications.
- Ambiguity in bias direction for hallucination estimates: disentangle competing biases (archive incompleteness, 403 exclusions, UNKNOWN handling, soft-404 archiving) via controlled audits so that reported hallucination rates can be stated with known confidence bounds and correction factors.
- Handling of HTTP 3xx/soft-404/paywalls: rigorously evaluate redirect-following, soft-404 detection (e.g., content-based heuristics for 200-but-missing pages), and paywall interstitials; standardize live/non-live decisions across these cases.
- 403 bot-blocking treatment: replace blanket exclusion with robust verification (headless browser with JS execution, cookie/session handling, IP rotation, and human-in-the-loop rechecks) and quantify how reclassification affects model-level rates.
- Point-in-time measurement: conduct longitudinal URL re-checks to separate genuine link rot from transient failures and to estimate domain- and site-specific decay curves.
- Language and region coverage: extend beyond English-dominated data to non-English and low-resource web ecosystems (including Chinese beyond DRBench’s limited scope), and measure whether URL validity patterns generalize across locales and scripts (e.g., IDNs).
- Beyond existence to support: build a scalable benchmark that jointly tests (a) URL existence, (b) snippet faithfulness (quoted text actually present), and (c) bibliographic metadata validity (authors, DOIs, venue), enabling end-to-end attribution evaluation.
- DOI-aware verification: add DOI resolution checks (via Crossref/doi.org) and quantify DOI hallucination vs URL hallucination, especially for academic fields with heavy DOI usage.
- Generation-time grounding constraints: experimentally verify whether constraining models to emit only URLs they actually visited (and logged) reduces hallucination; test with instrumented open-source agents and ablations (visited-only vs free-form URL emission).
- Architecture causality: move beyond provider-level speculation by running controlled agent designs (single-shot RAG vs multi-step deep research with/without memory blending) to isolate which components drive fabrication vs stale-link failure modes.
- Tool-use competence: systematically study prompting, planning, and training strategies (e.g., supervised fine-tuning or RL on tool feedback) that increase models’ ability to act on verification results instead of repeatedly proposing flagged URLs.
- Cost/latency trade-offs: quantify the time, token, and API costs of verification/correction loops and identify Pareto-efficient strategies that balance responsiveness with reliability at deployment scale.
- urlhealth validation: report precision/recall against a large, stratified, human-labeled corpus; document error modes (e.g., misclassified redirects, soft-404s) and specify default retry, backoff, and timeout policies that optimize accuracy.
- Redirect canonicalization: implement and evaluate URL normalization (scheme/domain canonicalization, trailing slashes, parameter sorting/removal, percent-encoding, punycode) and multi-hop redirect following to reduce false non-resolving counts.
- URL extraction robustness: assess regex-based parsing errors (truncation at punctuation, missing schema, markdown formatting artifacts) and compare against structured extraction from model function-calls or HTML-aware parsers.
- Unit of analysis and statistical independence: re-analyze with cluster-aware methods (by question, session, or model run) and report uncertainty under hierarchical models to avoid overstating significance from URL-level independence assumptions.
- Weighting by citation vs unique URL: quantify differences between per-citation and per-unique-URL rates (and per-question weighting), and standardize reporting so that models cannot “game” reliability via duplicate or repetitive URLs.
- Domain/site-level risk modeling: produce host- and TLD-level failure profiles (forums, news, publishers, preprints, social platforms) to guide retrieval-time filtering or trust scoring and to inform domain-aware mitigation.
- Prompting levers: experimentally assess whether instructions (e.g., cap number of citations, prioritize high-trust domains, require verification before emission) measurably reduce hallucinations without harming answer quality.
- Quality trade-offs: measure how verification and stricter citation policies affect answer helpfulness, coverage, and factuality; report user-centered metrics alongside URL validity.
- Archiving at generation time: test agents that automatically archive cited pages (e.g., Perma.cc, Wayback “Save Page Now”) and cite archival URLs, measuring impact on link rot and long-term reproducibility.
- Vantage-point diversity: evaluate URL health from multiple geographies, networks, and user agents to account for geo-fencing, regional blocking, or CDN inconsistencies that confound liveness classification.
- Provider comparability: control for API configurations, browsing capabilities, and search stack settings across models, or replicate findings on open-source systems with fully transparent retrieval logs.
- Field-level causal factors: move from descriptive field variation to causal analysis by decomposing rates into site mix, paywall prevalence, content churn, and citation-length preferences to identify actionable levers per discipline.
- Reddit and rate-limited platforms: replace ad hoc assumptions (e.g., blanket “alive”) with platform-aware verification (official APIs, authenticated sessions) and quantify sensitivity of results to these choices.
- Training-time mitigation: explore fine-tuning or RL objectives that penalize unverifiable URLs and reward verified-citation emission, comparing training-time vs post-hoc tool-based mitigation.
- Adversarial and cloaked content: study robustness to sites serving different content to bots/users (cloaking), CAPTCHAs, and anti-scraping defenses; develop detection and safe-fallback behaviors.
- Reproducibility over time: document how model updates, search index freshness, and API changes alter citation validity, and provide versioned benchmarks to enable longitudinal comparability.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases derived from the paper’s findings and the open-source urlhealth tool. Each item notes sectors, candidate products/workflows, and feasibility considerations.
- Industry: LLM product teams (search, chat, “deep research” modes)
- Application: Post-generation citation verification and self-correction loop
- What: Integrate urlhealth as a function/tool-call to check each emitted URL (LIVE, DEAD/stale, LIKELY_HALLUCINATED, UNKNOWN), replace or remove non-live links, and prefer archival snapshots when needed.
- Sectors: Software, search engines, consumer AI assistants.
- Tools/workflows: Function-calling orchestration (e.g., LangChain/LlamaIndex tools), UI badges (“verified”, “archived”), automatic retries, domain allow-lists.
- Assumptions/dependencies: Model must competently use tools (paper shows large gap between smaller vs frontier models); Wayback coverage is incomplete; handling 403/UNKNOWN often needs headless browser checks and/or human-in-the-loop.
- Application: Reliability-aware ranking and throttling for citations
- What: Enforce per-response caps, down-rank unverified domains, and block emission of URLs that weren’t actually visited during retrieval.
- Sectors: Search, enterprise research assistants.
- Tools/workflows: Internal policy: “emit URLs only from visited pages,” logging of visited URLs, server-side gating.
- Assumptions/dependencies: Requires retrieval architecture control (provider-side change for hosted LLMs); may reduce recall or perceived “thoroughness.”
- Application: Monitoring dashboards and SLAs for citation health
- What: Track KPIs such as % non-resolving, % hallucinated, % stale by model, domain, and release; alerting on regressions.
- Sectors: Software quality, MLOps, AI governance.
- Tools/workflows: Batch verification pipelines, A/B tests of retrieval variants, regression gates before deployment.
- Assumptions/dependencies: Compute/bandwidth for URL probes; rate limits and bot-blocking; need to exclude paywalled 403s from false positives.
- Academia and publishing
- Application: “Preflight” citation checks in editorial pipelines
- What: Auto-scan submissions and reviews for dead or hallucinated URLs; suggest archived links; flag fabricated references for manual review.
- Sectors: Academic journals, conferences, university presses.
- Tools/workflows: Manuscript submission plug-ins, GitHub Actions/pre-commit hooks for Markdown/LaTeX; integration with Perma.cc and Wayback to auto-archive.
- Assumptions/dependencies: Not all citations are URLs (needs planned extension to DOIs/PDF quotes); policies for replacing vs supplementing links with archives.
- Application: Classroom and LMS use for AI-assisted writing
- What: Instructors and students validate AI-generated citations; assignments require “verified or archived” proofs.
- Sectors: Education.
- Tools/workflows: LMS plugin; browser extension for students; rubric item for “citation existence.”
- Assumptions/dependencies: Campus networks may block bot traffic; training and awareness for students.
- Legal and compliance
- Application: Mandatory URL verification in filings and briefs
- What: Courts and law firms auto-check links in filings; attach archived snapshots to mitigate link rot.
- Sectors: Legal.
- Tools/workflows: E-filing system integration; nightly link health scans; Perma.cc workflow.
- Assumptions/dependencies: Court rule changes or administrative guidance; sensitive documents may restrict archiving.
- Healthcare and life sciences
- Application: Clinical content QA for AI-generated summaries
- What: Verify citations in patient/clinician-facing outputs; prefer DOIs/PubMed and provide archived links for non-resolving cases.
- Sectors: Healthcare.
- Tools/workflows: Post-generation QA step; domain allow-lists (e.g., NIH, PubMed, FDA); fallback to archival or alternative authoritative sources.
- Assumptions/dependencies: Verification of “existence” is not “support for claim”; clinical safety review still required; paywalls and 403s common.
- Journalism, marketing, and documentation teams
- Application: CMS and publishing plugins for link hygiene
- What: Scan posts for dead/likely-fabricated URLs before publish; auto-insert archived URLs; scheduled rechecks to combat link rot.
- Sectors: Media, marketing, software documentation.
- Tools/workflows: WordPress/Drupal plugins; static-site CI jobs; post-publish link monitoring.
- Assumptions/dependencies: Rate limits and bot-blocking; policy on replacing external links; storage for archived snapshots.
- Enterprise knowledge management
- Application: Intranet-aware verification and domain whitelisting
- What: Validate internal links and restrict assistants to whitelisted domains; provide internal archiving for intranet content.
- Sectors: Finance, energy, manufacturing, tech.
- Tools/workflows: Private Wayback-like archiver; SSO-aware headless checks; “verified intranet” badges in outputs.
- Assumptions/dependencies: Privacy and access controls; internal crawling allowances; different error profiles than public web.
- Policy and procurement
- Application: Procurement requirements and disclosure
- What: Require AI vendors to implement citation-verification, report citation health metrics, and archive cited content for public communications.
- Sectors: Government, public health, education.
- Tools/workflows: RFP language; compliance attestations; periodic audits.
- Assumptions/dependencies: Vendor cooperation; standardization of metrics; budget for audits.
- Daily life
- Application: Browser extension to “trust-but-verify” AI citations
- What: Check links in AI answers, list verified vs archived vs likely fabricated, and offer one-click archival.
- Sectors: General consumers, students.
- Tools/workflows: Extension using urlhealth; lightweight headless checks for 403.
- Assumptions/dependencies: API rate limits; UX clarity around UNKNOWN results.
- Developer ecosytem
- Application: Tooling and frameworks integration
- What: Package urlhealth as a LangChain/LlamaIndex tool, a pip package, and CI action; pre-commit hooks for Markdown/README files.
- Sectors: Software.
- Tools/workflows: agentskills.io skill; GitHub Actions; build pipelines.
- Assumptions/dependencies: Maintenance of tool APIs; stability of Wayback API.
Long-Term Applications
These opportunities require further research, scaling, or architectural changes beyond post-hoc verification.
- Generation-time grounding constraints
- What: Only emit URLs actually visited by the browsing/retrieval module; decode from a restricted candidate set of verified sources.
- Sectors: Search, consumer and enterprise assistants.
- Potential products/workflows: “Visited-only” URL decoder heads; provenance tokens attached to citations.
- Assumptions/dependencies: Deep integration with provider’s retrieval stack; potential creativity/coverage trade-offs.
- Cryptographic/provenance proofs for citations
- What: Signed attestations from the retriever/browser that a URL was accessed with timestamp and content hash.
- Sectors: Legal, healthcare, scientific publishing, finance research.
- Potential products/workflows: W3C Verifiable Credentials for citations; chain-of-custody logs.
- Assumptions/dependencies: Standards consortium; retriever instrumentation; privacy and IP considerations.
- Beyond URLs: verifying quotes and bibliographic metadata
- What: Automatic detection of fabricated snippets and invented bibliographic entries; match quoted spans to source documents; DOI verification.
- Sectors: Academia, legal, healthcare, media.
- Potential products/workflows: PDF/OCR quote matchers, Crossref/Scite integrations, “evidence alignment” scorers.
- Assumptions/dependencies: Reliable access to full text (paywalls); high-accuracy text alignment; handling paraphrase and context.
- Automatic repair and substitution agents
- What: When a link is dead, auto-replace with archived versions or authoritative alternatives; maintain link health over time.
- Sectors: Media, documentation, enterprise portals.
- Potential products/workflows: Background link-rot daemons; editorial approval queues; audit trails.
- Assumptions/dependencies: Editorial policy for replacements; risk of subtle changes in meaning across sources.
- Domain-optimized, reliability-first agents
- What: Healthcare/legal/finance-specialized assistants with strict domain allow-lists, archival-by-default, and elevated verification thresholds.
- Sectors: Healthcare, legal, finance.
- Potential products/workflows: “High-assurance” modes; integration with PubMed, FDA, EDGAR, court databases.
- Assumptions/dependencies: Licensing/access to authoritative databases; throughput/latency trade-offs.
- Industry standards and regulation
- What: Certification and reporting standards for citation existence; labels for “verifiable citations”; sector-specific compliance (e.g., clinical decision support).
- Sectors: Government, regulators, standards bodies.
- Potential products/workflows: ISO/NIST-like benchmarks; external audits; transparency reports.
- Assumptions/dependencies: Consensus on metrics (e.g., % hallucinated vs stale), treatment of paywalled content, archiving policies.
- Training-time interventions
- What: Fine-tune or reinforce models using urlhealth feedback to penalize fabricated URLs; curriculum including negative examples; reward grounding.
- Sectors: Foundation model providers, enterprise finetuning.
- Potential products/workflows: RLHF with “citation existence” reward; synthetic datasets labeled by urlhealth; guardrail policies.
- Assumptions/dependencies: Access to base models; compute costs; avoiding over-optimization that harms coverage.
- Improved archival infrastructure and APIs
- What: Real-time, privacy-aware archiving at the moment of citation; better coverage of non-English and niche domains; intranet archiving.
- Sectors: Libraries, government, enterprises.
- Potential products/workflows: “Archive-on-cite” services; enterprise Wayback equivalents.
- Assumptions/dependencies: Coordination with archive operators; legal constraints; storage and cost.
- Reliability scoring and routing
- What: Per-domain and per-model “citation reliability scores” used to route prompts to models/pipelines that minimize hallucinated URLs for a given field.
- Sectors: AI platforms, enterprises with mixed-model fleets.
- Potential products/workflows: Dynamic router combining domain detection + reliability profiles; cost-quality policies.
- Assumptions/dependencies: Ongoing benchmarking; drift monitoring; multi-provider integrations.
- Education and literacy at scale
- What: Curriculum and certifications for “AI citation hygiene”; institutional policies mandating verification in AI-assisted writing.
- Sectors: Education, professional training.
- Potential products/workflows: MOOCs, micro-credentials, plug-ins for writing tools.
- Assumptions/dependencies: Adoption incentives; alignment with academic integrity policies.
- Privacy-preserving and offline verification
- What: On-device or VPC-contained verification for sensitive environments (e.g., regulated industries, defense).
- Sectors: Defense, finance, healthcare.
- Potential products/workflows: Local archival mirrors; allow-listed probe services; zero-data retention policies.
- Assumptions/dependencies: Infrastructure costs; limited coverage vs public web.
Cross-Cutting Assumptions and Dependencies
- Archive coverage and bot-blocking: Wayback coverage is incomplete and non-uniform; many 403/UNKNOWN cases require headless-browser checks or human review.
- Tool competence: Efficacy depends on the model’s ability to invoke and act on tool outputs; smaller models may fail to correct even after verification.
- Paywalls and licensing: Access to full text (for quote/metadata verification) may require subscriptions; policies vary by publisher.
- Latency/cost: Verification increases latency and API costs; batching and caching may be needed for production.
- Safety and accuracy: Existence of a URL is not evidence sufficiency; claim support verification remains necessary, especially in healthcare and legal settings.
- Provider integration: Some high-impact mitigations (restricting URL emission to visited pages) require changes within proprietary retrieval architectures.
Glossary
- Agentic self-correction: An iterative process where an agent-equipped model verifies and amends its own citations using tools. "We evaluate urlhealth as a tool within an agentic self-correction loop."
- Attributable to Identified Sources (AIS): A framework for evaluating whether generated statements are supported by identified sources. "defined Attributable to Identified Sources (AIS), noting non-resolving links as an edge case;"
- Bootstrap 95% CIs: Nonparametric, resampling-based confidence intervals indicating uncertainty in estimates. "All intervals are bootstrap 95% CIs."
- Bot-blocking: Server-side measures that block automated requests, often returning HTTP 403. "403 responses, which often reflect bot-blocking rather than genuinely dead pages."
- Deep research agents: Multi-step retrieval-and-synthesis systems that produce long-form, cited reports. "Deep research agents (gemini-2.5-pro-deepresearch, openai-deepresearch) execute multi-step retrieval and synthesis, producing long-form reports."
- DOI: Digital Object Identifier; a persistent identifier for scholarly documents. "invented bibliographic entries (plausible but incorrect metadata such as wrong authors or non-existent DOIs)"
- DRBench: A benchmark for evaluating deep research agents, used here to measure citation URL validity. "using 10 models and agents on DRBench (53,090 URLs)"
- ExpertQA: An expert-curated question set spanning many fields, used for domain-stratified analysis. "and 3 models on ExpertQA (168,021 URLs across 32 academic fields)."
- Failure taxonomy: A structured categorization of error types to diagnose and mitigate failures. "Our characterization findings, failure taxonomy, and open-source tooling establish that citation URL validity is both measurable at scale and correctable in practice."
- Grounding: Constraining generation to evidence from retrieved sources; here via search integration. "Google Search grounding generates the initial response"
- Hallucinated URL: A cited URL that does not resolve and has no archive record, indicating likely fabrication. "A hallucinated URL is a non-resolving URL for which no archived snapshot exists in the Wayback Machine"
- Headless-browser audit: Programmatic verification using a browser without a GUI to check page accessibility. "A headless-browser audit of 600 stratified-sampled UNKNOWN URLs finds that 89.0% [86.3, 91.5] are live or blocked-but-accessible, with only 11.0% [8.5, 13.7] genuinely dead (Appendix~\ref{app:unknown-audit})."
- HTTP HEAD request: An HTTP method requesting headers only; used to test URL liveness efficiently. "Each URL is tested with an HTTP HEAD request (falling back to GET on 405, 403, or 501 responses)."
- LIKELY_HALLUCINATED (urlhealth category): A urlhealth label for 404 URLs with no Wayback snapshot. "classifies the result into four categories: LIVE (HTTP~200), DEAD (HTTP~404 with a Wayback Machine snapshot, corresponding to stale URLs), LIKELY_HALLUCINATED (HTTP~404 with no archived snapshot), or UNKNOWN"
- Link rot: The natural decay of hyperlinks over time, leading to dead links. "Stale URLs represent natural link rot rather than fabrication."
- Lower-bound estimate: A conservative estimate that likely undercounts the true value due to methodological limits. "this is a lower-bound estimate of hallucination"
- Model-agnostic: Applicable across different model architectures or providers without customization. "an open-source, model-agnostic URL verification tool"
- Non-resolving URL: A URL that fails to load (HTTP 4xx/5xx, connection error, or timeout). "A non-resolving URL is one that returns an HTTP error (4xx or 5xx status code) or fails to connect."
- Operational definition: A precise, study-specific definition used for measurement. "This is an operational definition."
- Parametric memory: Knowledge stored within model parameters rather than retrieved from external sources. "production systems may generate URLs from parametric memory rather than actual browsing."
- Rate-limiting: Server-side throttling that limits automated request rates. "Because Reddit aggressively rate-limits automated URL checks, we classify Reddit URLs as alive"
- Regex: Regular expressions used for pattern-based text extraction. "URLs are extracted from model-generated text via regex matching of https?:// patterns."
- Retrieval-augmented generation (RAG): Generation that incorporates retrieved evidence to inform outputs. "Retrieval-augmented generation (RAG) and web search integration are now standard across all major LLM providers"
- Search-augmented LLMs: LLMs that perform a single web search to inform their answers. "Search-augmented LLMs perform a single query with search integration."
- Sensitivity analysis: A robustness check assessing how results change under alternative assumptions. "A sensitivity analysis treating all Reddit URLs as non-resolving raises GPT-5.1's rate to 26.7% but does not affect the other models; see Appendix~\ref{app:sensitivity}."
- Soft-404: A page that returns a success code but effectively indicates “not found.” "Wayback archiving soft-404 or wildcard-redirect pages"
- Stale URL: A once-valid URL that is now dead but has an archival snapshot (i.e., link rot). "A stale URL is a non-resolving URL that does have a Wayback Machine snapshot"
- Stale-vs-hallucinated classification: Distinguishing dead links due to link rot (stale) from fabricated ones (hallucinated). "stale-vs-hallucinated classification using the Wayback Machine."
- Tool-use competence: A model’s ability to correctly invoke and act on external tool outputs. "though effectiveness depends on the model's tool-use competence."
- Two-proportion z-test: A statistical test comparing proportions between two groups. "two-proportion , "
- UNKNOWN category: urlhealth label for indeterminate cases (e.g., paywalls, timeouts) needing manual review. "the residual UNKNOWN category (non-200, non-404 responses) is 89% live or blocked when probed with a real browser."
- URL liveness checking: Automated verification that a URL currently resolves successfully. "urlhealth, an open-source tool for URL liveness checking and stale-vs-hallucinated classification"
- User-Agent header: An HTTP header identifying the client; here spoofed to reduce false positives. "The User-Agent header mimics a standard browser to reduce false positives."
- Wayback Machine: A large-scale web archive used to check historical existence of URLs. "they have no record in the Wayback Machine and likely never existed"
- Wayback Machine API: The programmatic interface for querying Wayback snapshots. "Each non-resolving URL is then checked against the Wayback Machine API."
- Wildcard-redirect: A server configuration that redirects many paths to a generic page, potentially misleading archives. "Wayback archiving soft-404 or wildcard-redirect pages"
Collections
Sign up for free to add this paper to one or more collections.

