- The paper demonstrates that RL post-training with hallucination-inductive regimes improves multimodal reasoning by amplifying textual reasoning over direct visual cues.
- It employs modality-specific corruption strategies—blank image, random image, and textual removal—to isolate and diagnose the reliance on visual versus textual inputs.
- Results indicate that scaling up models amplifies the efficacy of RL, challenging traditional assumptions about visual grounding and underscoring the need for modality-aware objectives.
Hallucination-Inductive Training in RL-Finetuned Multimodal Reasoning Models
Introduction
The influence of reinforcement learning (RL) on post-training Multimodal LLMs (MLLMs) is extensively documented in terms of empirical performance gains. However, the mechanism by which RL-based post-training actually enhances multimodal reasoning—specifically, whether it fosters genuine utilization of visual information or primarily improves internal textual reasoning—remains underexplored. The work “Understanding the Role of Hallucination in Reinforcement Post-Training of Multimodal Reasoning Models” (2604.03179) introduces a systematic analytical approach to dissect this question via the Hallucination-as-Cue framework.
The Hallucination-as-Cue Framework
This framework is built on modality-specific input corruptions designed to encourage or expose the generation of hallucinated content. Three key corruption strategies are employed:
- Blank Image Replacement (BI): Visual inputs are eliminated by replacing images with blanks, isolating reasoning to the text modality and any self-generated visual information.
- Random Image Replacement (RI): Visual input is decoupled from text by introducing random, mismatched images.
- Textual Removal (TR): All descriptive text is removed, leaving only the visual input.
This setup enables analysis of both training and inference in highly adversarial, hallucination-inductive regimes to differentiate visual grounding from textual or prior-induced reasoning.
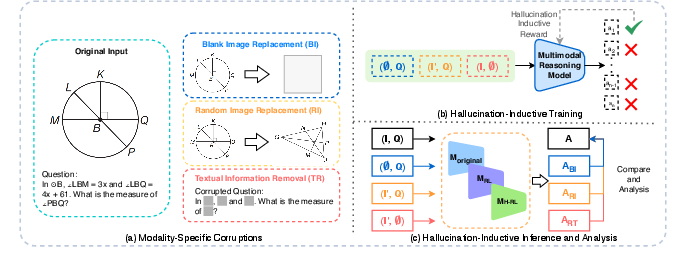
Figure 1: The Hallucination-as-Cue framework introduces modality-specific corruptions, hallucination-inductive training, and systematic inference analysis for diagnosing reliance on language or vision.
Experimental Findings
RL Training in Hallucination-Inductive Regimes
Contrary to prevailing assumptions, RL-based post-training with severely corrupted data consistently yields improvement in both training and test set accuracy for visual reasoning, even surpassing standard training in certain scenarios for larger MLLMs. For instance, RL-trained Qwen2.5-VL-7B with random image replacement achieved higher average accuracy across several mathematical visual reasoning benchmarks than the same model trained with clean data.
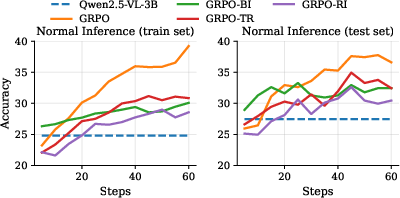
Figure 2: Accuracy of various training regimes (standard, BI, RI, TR) on uncorrupted data, demonstrating robust improvements with hallucination-inductive training.
This effect is prominent for both smaller and larger models, though scaling amplifies the impact—larger models benefit more from hallucinated trajectories, indicating that RL predominantly leverages and amplifies the intrinsic step-by-step reasoning ability of the underlying LLM. Hallucination-inductive RL training does not simply overfit to noise; instead, it advances general reasoning reliability.
Inference under Corruption and Dataset Analysis
Evaluation under corrupted conditions shows significant but non-catastrophic degradation in reasoning accuracy. Notably, models post-trained with hallucination-inductive RL maintain performance advantages over the base model, confirming that RL improves priors for generating correct answers even in the absence of modal grounding.

Figure 3: Accuracy on corrupted data after different training regimes, underscoring resilience to input distortion afforded by RL.
Interestingly, for complex benchmarks such as MathVision, even Blank Image Replacement can improve accuracy over uncorrupted inference in smaller models, implying that visual signals can sometimes act as distractors rather than aids—especially when textual signals contain sufficient priors. This phenomenon attenuates with scale and RL post-training, which increasingly exploit available visual signals when models are sufficiently strong.
Fine-grained benchmark analysis confirms that the negative impact of visual corruption is largest for vision-intensive questions, and RL maximizes generalization to both text- and vision-dominant reasoning. Text-dominant problems suffer the least under visual removal, reinforcing the hypothesis that RL-driven models rely primarily on learned textual patterns unless forced otherwise.
Implications, Contradictions, and Model Scaling
The empirically demonstrated finding that RL-trained MLLMs with hallucination-inductive data can match or outperform those trained with clean aligned inputs is both strong and counter to the typical assumption that RL in MLLMs improves visual grounding. Instead, RL is shown to mostly amplify the model's general reasoning prior. This insight calls into question the effectiveness of reward design and highlights the need for modality-aware objectives or auxiliary losses to truly enable vision-language alignment.
Moreover, the positive effect of hallucination-inductive data is not bounded to specific datasets but generalizes to compositional and classic reasoning benchmarks, suggesting a pervasive model-inherent ability to bootstrap reasoning via self-generated content.
The study further identifies scaling as a key ingredient: Larger models both generate more positive hallucinated reasoning trajectories and extract greater utility from them during RL—for instance, the Qwen2.5-VL-7B model improves on Blank Image Replacement corrupted data from 9.7% to 14.1% accuracy (compared to 7.6% to 10.4% for the 3B variant).
Theoretical and Practical Implications
The primary theoretical implication is the decoupling of RL-based reasoning improvement from true visual grounding in current reward architectures. The practical takeaway concerns evaluation of MLLMs: high performance in visual reasoning benchmarks does not imply effective visual understanding, especially under reinforcement post-training, unless accompanied by robust modality ablation analyses.
This work motivates more principled, modality-aware RL objectives and diagnostic frameworks for future vision-LLM development. Additionally, the performance of RL-finetuned MLLMs under hallucination offers a testbed for dataset diagnostics and understanding model reliance on spurious statistical correlations.
Conclusion
This work rigorously demonstrates that RL post-training of MLLMs can induce substantial reasoning improvements even absent coherent visual input, scaling positively with model size and generalizing across datasets and problem types. These results challenge the assumption that current RL regimes lead to effective vision-language alignment, and suggest that reward design and evaluation criteria require significant rethinking to disentangle textual and visual reasoning. Future research should prioritize modalities' interaction in both reward functions and benchmark design for genuine multimodal intelligence (2604.03179).

