- The paper presents gradient-boosted attention, which adds a corrective residual pass to standard attention for improved error correction.
- It employs a per-dimension learned gate that functions as a shrinkage parameter, aligning the model with classical gradient boosting principles.
- Empirical results on WikiText-103 show reduced perplexity from 72.2 to 67.9, outperforming standard and parameter-matched transformer architectures.
Introduction and Motivation
The standard attention mechanism in transformers computes a single softmax-weighted average over values, yielding a one-pass estimate that does not internally correct its own errors. This paper presents gradient-boosted attention, applying the principle of gradient boosting within a single attention layer by introducing a second attention pass that attends to the prediction error of the first and applies a gated, dimension-wise correction. Under a squared reconstruction objective, this mechanism maps directly onto Friedman's gradient boosting machine: each attention pass functions as a base learner, and the per-dimension gate corresponds to the shrinkage parameter. The architecture provides a more flexible and effective error correction mechanism compared to shared-kernel approaches like Twicing Attention.
Mechanism and Theoretical Foundations
Gradient-boosted attention operates by first computing a standard attention pass, resulting in an initial estimate. The residual, i.e., the difference between the input and this estimate, is then fed as the query to a second attention round with its own learned QKV projections. A per-dimension learned gate modulates the amount of correction applied. Crucially, this second round can attend to tokens that received negligible weight in the initial pass, circumventing the limitations of residual correction with shared attention matrices.
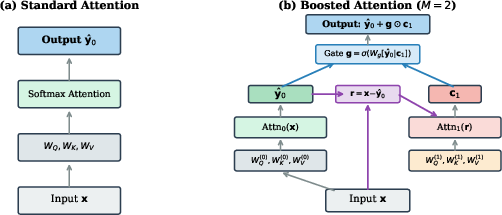
Figure 1: (a) Standard attention computes a single softmax-weighted average. (b) Gradient-boosted attention adds a correction pass attending to the prediction error through separate projections and a learned gate.
Iterating standard attention operations, akin to finding the Hopfield network fixed point, is fundamentally flawed for tasks where query information must be preserved. The paper formally proves that a single attention step destroys all query information orthogonal to the stored-pattern subspace; iterative convergence contracts queries to fixed points determined solely by the stored patterns and temperature, erasing within-region variations. Empirical results confirm that Deep Equilibrium Model training does not alleviate this loss—converged attention degrades retrieval accuracy to near-random levels, while the one-step output preserves task-relevant information.
Architectural Details and Connections to Gradient Boosting
The forward computation in boosted attention proceeds by sequential residual fitting:
- Initial pass: Estimate via standard attention.
- Residual computation: Negative gradient under squared loss, x−F.
- Correction pass: Attend to the residual using separate learned projections.
- Gated update: Apply a learned, per-dimension gate as a shrinkage parameter.
This construction mirrors Friedman's MART, with the gate generalizing η from scalar to per-dimension and input-adaptive.
Empirical Evaluation
On WikiText-103, gradient-boosted attention achieves a test perplexity of 67.9, outperforming standard attention (72.2), Twicing Attention (69.6), and a parameter-matched wider model (69.0). Two rounds capture most of the improvement, validating the boosting principles observed in classical ML.
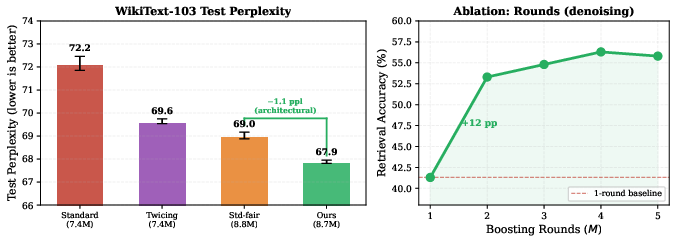
Figure 2: Left: WikiText-103 test perplexity. Gradient-boosted attention outperforms baselines. Right: Synthetic denoising task—boosting rounds capture most of the benefit after two passes.
Ablations confirm that the architectural improvement is not simply due to increased capacity; a parameter-matched wider model lacks the error-correction mechanism and underperforms. The effect of boosting rounds shows diminishing returns past two iterations, and the correction mechanism provides maximal benefit in more difficult denoising settings.
Analysis of Learned Behavior
The gate values exhibit layer-dependent magnitudes and per-dimension selectivity—layer 1 applies the strongest corrections with high variation across dimensions.
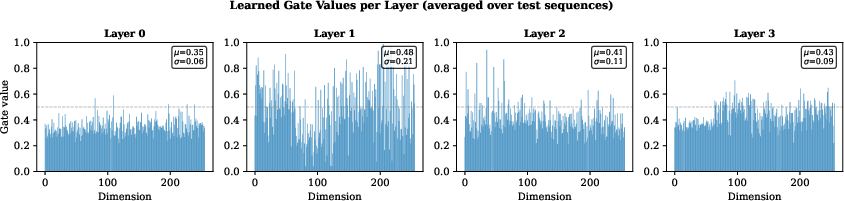
Figure 3: Learned gate values per dimension for each transformer layer, showing depth-dependent selectivity in correction magnitude.
Attention entropy analysis reveals that the correction round generally attends more sharply, especially in deeper layers, aligning with higher gate values.
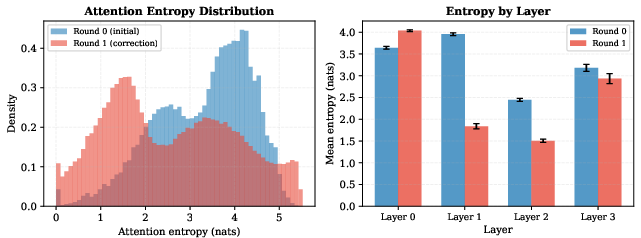
Figure 4: Left: Correction attention distributions are lower entropy than initial attention. Right: Layer-wise mean entropy confirms sharper focus where corrections are largest.
Qualitative token-level corrections illustrate the correction mechanism’s capacity to recover prediction errors by sharply attending to relevant context overlooked in the initial pass.
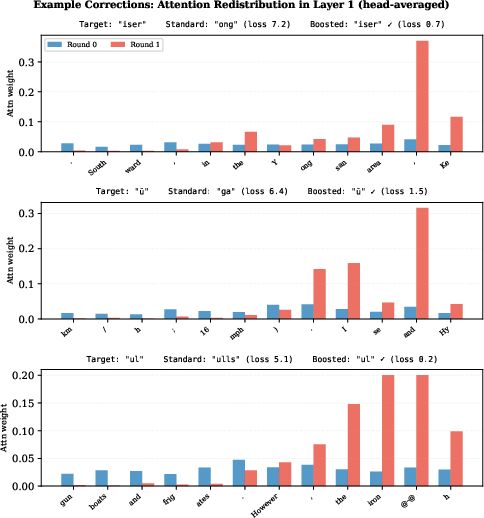
Figure 5: Examples where the gradient-boosted correction concentrates attention and resolves prediction errors, outperforming standard attention.
Implications, Limitations, and Future Directions
The results provide evidence that residual fitting within a single attention layer yields architectural gains independent of mere parameter count. The correspondence to gradient boosting provides a theoretically principled framework for sequence modeling, linking transformers with classical ensemble methods. This mechanism is expected to be most effective when the base learner (attention) is moderately strong—future scaling studies will clarify its efficacy in larger models.
Practical adoption may face hurdles in compute overhead, though shared key-value computations offer avenues for efficiency. The method’s drop-in compatibility with existing transformer architectures and independence from large-scale pretraining make it promising for fine-tuning and offline enhancement. Extensions may involve adaptive boosting rounds, joint noise cancellation (e.g., with Differential Transformer), and interpretability studies of correction specialization.
Conclusion
Gradient-boosted attention leverages sequential residual correction within a single transformer layer, realizes the gradient boosting paradigm via learned corrective attention, and demonstrably outperforms both standard and shared-kernel attention alternatives. The theoretical analysis and empirical validation underscore the significance of separate projections and adaptive gating in recovering information inaccessible to classical and iterative approaches, providing a new architectural inductive bias for sequence modeling.