- The paper introduces FinLongDocQA and FinLongDocAgent to benchmark and improve multi-table numerical reasoning in long financial reports.
- It employs a multi-agent, multi-round RAG framework to iteratively refine evidence retrieval, mitigating context rot and numerical inaccuracies.
- Empirical results demonstrate superior performance over standard methods, highlighting challenges in assembling dispersed evidence for complex financial analysis.
Document-Level Numerical Reasoning across Single and Multiple Tables in Financial Reports
Introduction and Motivation
This work addresses the significant challenge of performing robust, document-level numerical reasoning over long and complex financial reports, with a particular focus on scenarios where evidence required to answer a question is distributed across multiple tables and narrative text. Existing benchmarks in financial QA primarily limit their scope to single-table settings or require only localized retrieval within small contexts, failing to reflect the practical analytical demands encountered in financial statement analysis where synthesizing information from disparate sections is routine. As contemporary LLMs extend context windows, context rot and evidence localization in long documents remain unresolved, especially for cross-table arithmetic that is prone to cascading errors and information loss.
FinLongDocQA: A Benchmark for Long-Document, Cross-Table Financial Reasoning
The core contribution is the introduction of FinLongDocQA, a large-scale benchmark dataset explicitly targeting both single-table and cross-table numerical reasoning within full-length annual reports. The dataset comprises 1,456 S&P 500 annual reports (2022–2024) and 7,527 high-quality QA instances, selected and filtered to ensure that multi-table, multi-hop reasoning is necessary for solution validity. Each QA pair is annotated with page-grounded evidence and executable programs, enabling rigorous evaluation of both retrieval and answer accuracy.
The dataset construction pipeline systematically balances automatic generation via LLMs, rule-based filtering to ensure multi-hop evidence requirements and answer validity, and a demanding manual review to enforce financial relevance and prevent annotation shortcuts or ambiguity. Notably, the dataset features significant numbers of QA pairs whose gold supporting evidence spans substantial page ranges (mean evidence page occurrence: 2.02, max: 4), challenging retrieval systems to locate relevant tables and text distributed throughout the report.

Figure 1: An example QA instance from FinLongDocQA, in which relevant tables and narratives span multiple sections of the annual report.
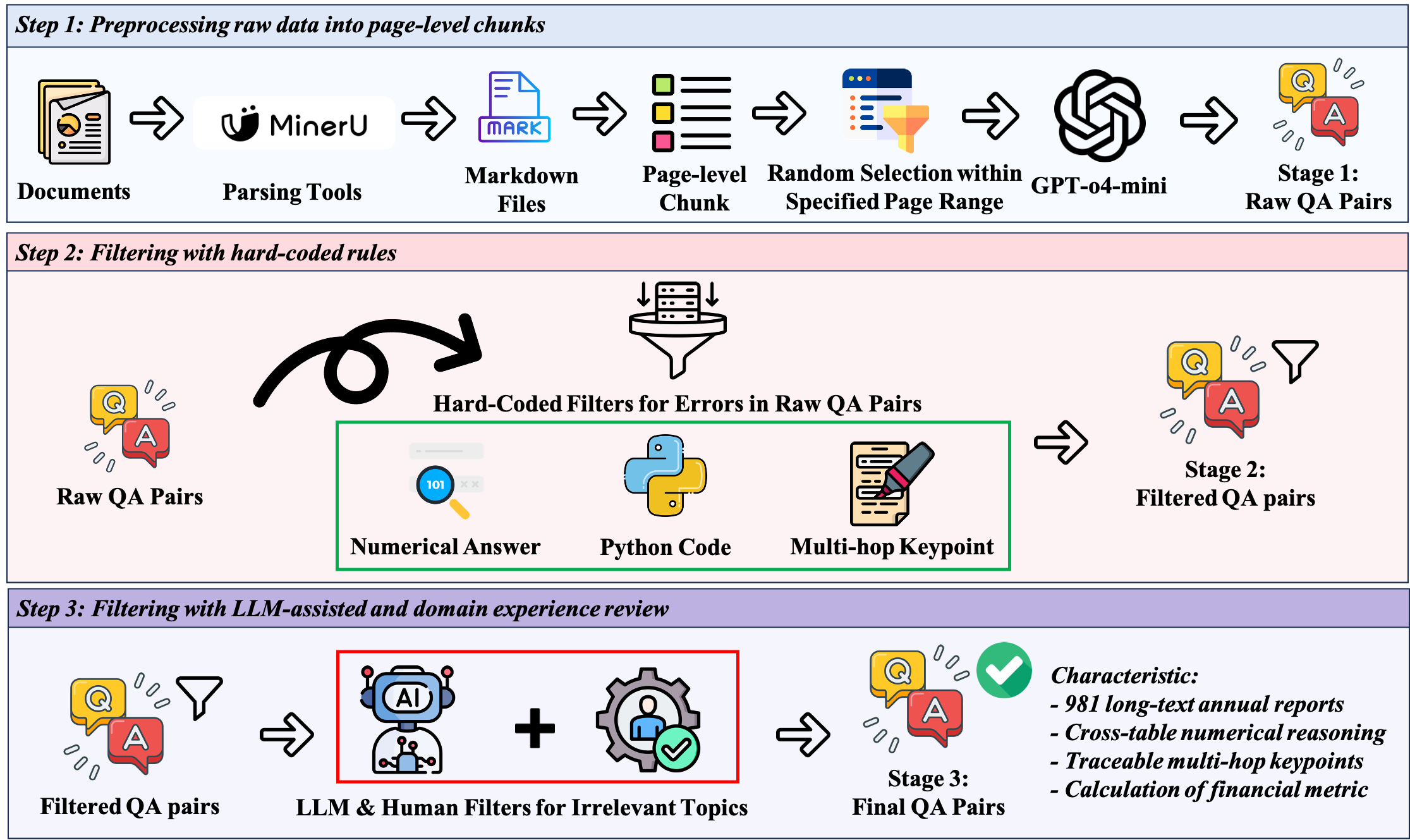
Figure 2: Construction pipeline for FinLongDocQA, highlighting the integration of large-scale LLM-driven generation, automated filtering, and human review for high-quality multi-table QA.
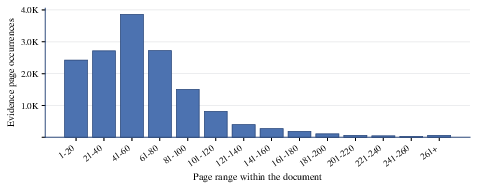
Figure 3: Evidence page distribution, illustrating that supporting information is often widely dispersed throughout the documents.
Challenges in Financial QA over Long Documents
Through extensive empirical evaluation of both closed-source (e.g., GPT-4o-mini, Gemini-3-Flash) and open-source (e.g., Qwen3-Thinking 30B, DeepSeek-v3.2) LLMs, two principal technical bottlenecks are identified:
- Evidence localization under context rot: With model input lengths often exceeding 129k tokens, relevant tables and text are frequently missed or poorly weighted due to the context rot phenomenon, resulting in limited or noisy retrieval—this is exacerbated as supporting evidence becomes increasingly distant or diffuse.
- Multi-step numerical reasoning errors: Even when the correct evidence is retrieved, LLMs demonstrate persistent failure modes in accurate numerical calculation, including operand selection errors, misapplication of formulas, inconsistent use of units, and arithmetic mistakes.
FinLongDocAgent: Multi-Agent Multi-Round RAG Architecture
To address these challenges, the authors propose FinLongDocAgent—a multi-agent, multi-round Retrieval-Augmented Generation (RAG) system that more faithfully mimics the iterative, evidence-driven workflow of human financial analysts. The agentic framework decomposes the task into three specialized agents: an Expansion Agent for query reformulation and operand enumeration, a Solving Agent for stepwise reasoning using contextually retrieved pages, and an Evaluation Agent for explicit verification of answer completeness and operand correctness.
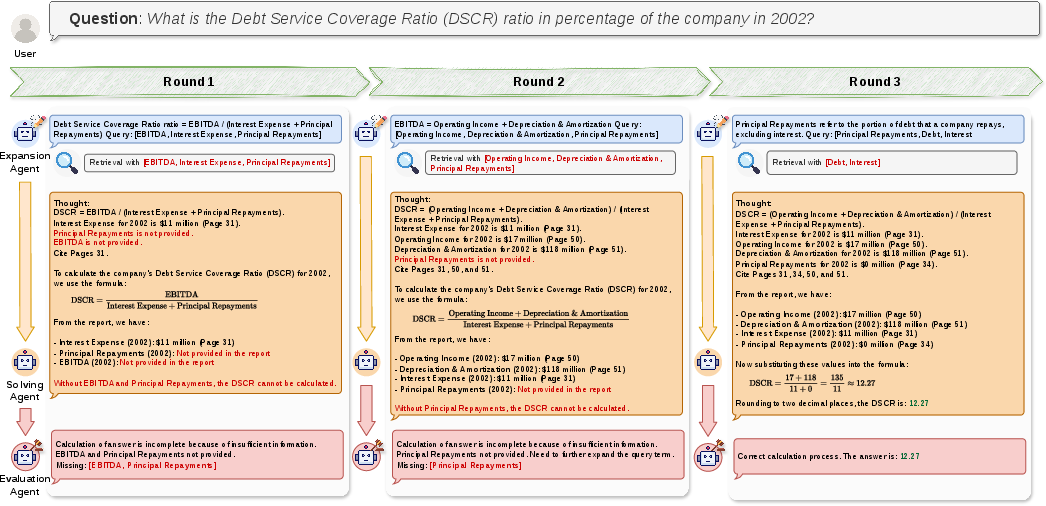
Figure 4: Illustration of the FinLongDocAgent pipeline, with multi-agent, multi-round evidence retrieval, intermediate computation, and explicit verification loops.
This iterative approach ensures efficient context filtering, progressive expansion of evidence coverage, and robust error detection, outperforming both standard dense and graph-based RAG methods in long-document scenarios.
Experimental Results and Analysis
The experimental protocol benchmarks a range of models and retrieval strategies. Key findings are:
- Access to document evidence is indispensable: Models without context or with only question input perform essentially at chance, confirming the necessity of retrieval-based approaches for this benchmark.
- Single-round dense RAG outperforms graph-based RAG: Direct dense retrieval (e.g., BGE-M3 retriever) consistently yields higher evidence recall compared to graph-based approaches (e.g., GraphRAG, HippoRAG2), likely due to implicit structure and non-standard linkage conventions in real-world financial reports.
- FinLongDocAgent achieves state-of-the-art performance under multi-table QA: On Gemini-3-Flash, FinLongDocAgent achieves 41.34 EM, 43.54 Tol. Acc, and 51.29 F1—substantially higher than baselines. Gains persist across all backbone LLMs and are especially pronounced as the number of tables required per question increases.
- Performance decays with cross-table complexity: As question difficulty and the number of evidence tables grow, all methods experience lowered accuracy, but the relative advantage of FinLongDocAgent over single-round and non-agentic methods widens.
- Ablation indicates benefit from iterative query refinement and explicit verification: Removing the Expansion agent or Evaluation agent from FinLongDocAgent degrades exact match by up to 8.31 points, highlighting the centrality of agentic design for evidence sufficiency and reasoning correctness.
Retrieval and Evidence Localization
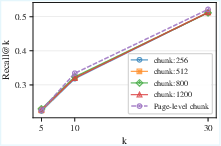
Figure 5: Recall@k for different chunk sizes, illustrating the non-triviality of localizing all required evidence even with sophisticated retrievers.
Despite high-capacity retrievers, Recall@30 remains well below ceiling (~62.22 for BGE), and error analysis (Table 7 in the paper) reveals that the majority of failures are attributable to incomplete operand retrieval, improper evidence use, or value extraction errors. Increasing the per-query retrieval budget yields only marginal improvements, further motivating iterative, agent-driven chunk selection.
Implications and Future Directions
The introduction of FinLongDocQA marks a decisive step in the rigorous evaluation of document-level numerical reasoning for finance. Practically, this enables more realistic testing of LLMs and RAG systems in high-stakes, regulation-driven domains where the provenance, correctness, and consistency of derived metrics are critical.
Theoretically, the bottlenecks exposed by this work—retrieval under severe context rot, evidence synthesis from heterogeneously structured tables, and robust verification in the face of accumulating arithmetic and mapping errors—define key directions for future research:
- Structure-aware retrieval and representation: Future systems must move beyond flat page/chunk retrieval and integrate document structure, table schema induction, and narrative-table linkage.
- Grounded program induction: Explicit program-of-thought or neural–symbolic approaches capable of producing and executing intermediate calculations grounded on retrieved content promise increased reliability.
- Agent orchestration and resource management: As multi-agent multi-round designs show benefit, further work on agent coordination, resource schedulers, and error diagnosis frameworks is warranted.
- Generalization to multimodal and international corpora: Extending FinLongDocQA methodology to include images, non-English filings, and less-scripted report formats will promote even broader applicability.
Conclusion
This paper systematically advances the state-of-the-art in document-level numerical reasoning over financial reports by introducing the FinLongDocQA benchmark and the FinLongDocAgent multi-agent framework. Empirical evidence demonstrates that classical QA and standard RAG pipelines fail to meet the demands of cross-table, multi-hop reasoning in long financial documents, while iterative, agent-based retrieval with explicit verification both improves final QA accuracy and exposes new research challenges. The findings underline that further progress in AI for finance hinges on innovations at the intersection of large-context retrieval, structured grounding, and agentic reasoning.