- The paper demonstrates that truth directions in LLMs are constrained by layer and task-specific complexities, rejecting claims of universal truth separability.
- The methodology employs linear logistic probes across diverse datasets and layers, showing rapid declines in generalization for tasks requiring intermediate computation.
- Findings indicate that truth representations are highly prompt-dependent, urging caution when using linear probing for safety-critical truth evaluations.
Testing the Limits of Truth Directions in LLMs
Introduction
"Testing the Limits of Truth Directions in LLMs" (2604.03754) provides a comprehensive investigation into the geometric and generalization properties of linear truth directions in modern instruction-tuned LLMs. Building on previous work that identified linear separability of true/false statements in LLM activation space, the paper systematically evaluates the scope and boundaries of such truth representations as a function of layer, task family and difficulty, and prompt/template type. The core finding is a falsification of universal claims about truth directions: truth separability and generalizability are sharply constrained by the computational properties of the task, the layer being probed, and the interaction with instruction prompts.
Methodology
The authors implement a multilayer probing study across a broad suite of datasets. Fact-oriented datasets (F0--F5) test recall, negation, conjunction, and counting over cities; arithmetic datasets (A1--A3) probe multi-step numerical computation. To isolate locus and properties of truth encoding, linear logistic probes are fitted to centered, final-token residual stream activations from every layer. The models probed are Llama-3.1-8B-Instruct and related variants. Prompting effects are controlled by contrasting passive and explicit truth-evaluation instruction templates.
Performance, generalization, and geometric consistency are measured via AUROC and cosine similarity. Probes are tested for in-domain accuracy, cross-task and cross-prompt generalization, and their geometric evolution is visualized in the subspace spanned by truth directions and principal orthogonal variance.
Layer-Dependence and Task-Specificity of Truth Directions
A major result is the pronounced layer-dependence of truth directions (Figure 1). For factual recall tasks (F0--F2), the probe achieves almost perfect AUROC in early and mid layers; for arithmetic and counting tasks, the emergence of linearly separable truth directions is delayed until much deeper layers. Critically, there is no single layer where truth is uniformly encoded across all tasks, contradicting claims of universal, task-independent separability.
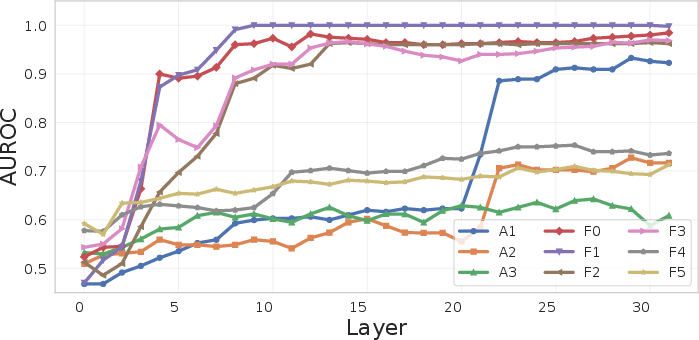
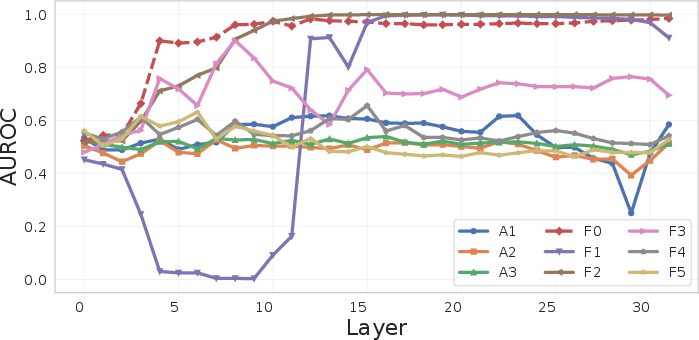
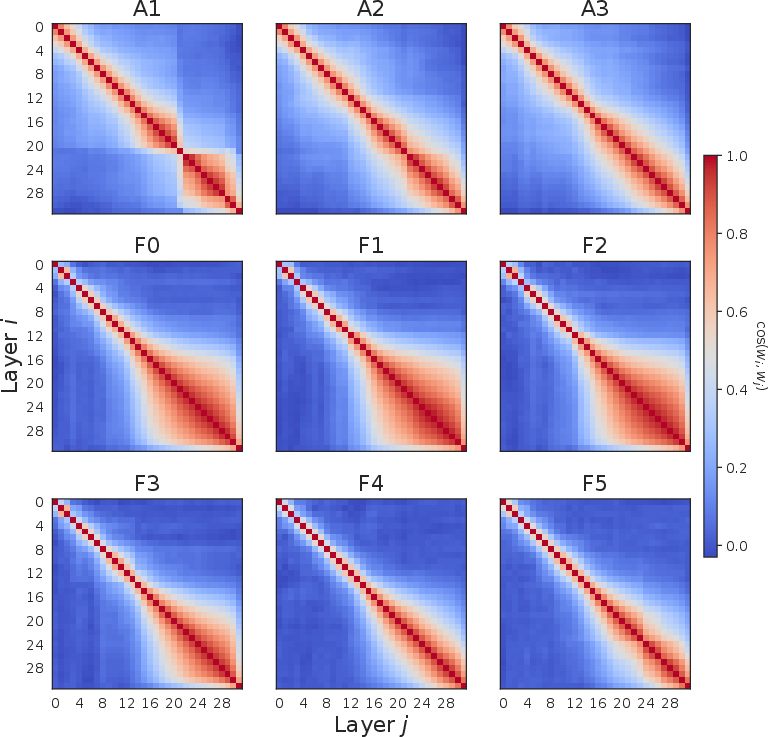
Figure 1: Layer dependence of truth directions; (a) in-domain test AUROC, (b) F0-probe generalization, (c) inter-layer probe similarity.
Early layers capture superficial features such as sentence polarity, reflected in the failure of affirmative-trained probes to generalize to their negated variants, where AUROC can fall to zero (systematic label inversion). The polarization phenomenon is quantified by decomposing the variance along polarity-sensitive and polarity-invariant directions, demonstrating that in mid-model layers, a transition occurs from polarity-dominated to fact-truth-dominated separation.
Activation-space geometry sharply evolves across the depth of the transformer: in early layers, probe directions are misaligned between tasks and transition to stability only in later layers. Arithmetic truth, which requires the LLM to compute and retain intermediate values, manifests as a later and less sharply defined direction, consistent with recent studies on the emergence of reasoning capabilities in LLMs.
Effects of Task Difficulty
Truth direction generalization degrades rapidly as soon as factual evaluation requires nontrivial intermediate computation, such as counting over more than two items or multi-step arithmetic. This is evident both quantitatively and geometrically.
For instance, in counting tasks, generalization from a length-2 to length-3 list causes AUROC to drop from near-perfect to ~0.75, with further increases in difficulty causing additional degradation (Figure 2). Training on a source task of higher complexity fails to restore generalization to still more complex targets, establishing counting and intermediate state tracking as hard boundaries for truth direction transfer.
More generally, in 2D projections of activations onto the learned truth direction and principal orthogonal direction, easy tasks (single-fact recall or single-operation arithmetic) exhibit clean separability, but as task complexity increases (multi-fact counting, chained arithmetic), true and false activations become inseparably entangled in the residual space (Figure 3).
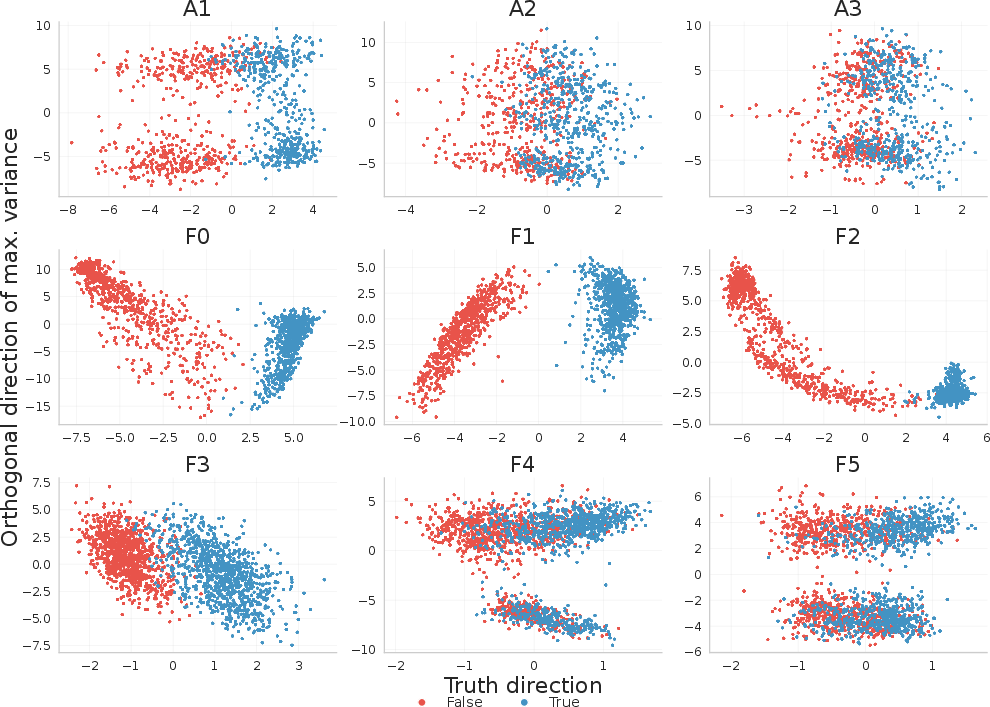
Figure 3: Projections of layer-25 activations reveal separability in simple tasks but entanglement as task complexity grows.
This fine-grained dissection reveals that limitations of probe generalization on real-world datasets, such as MMLU, are a direct consequence of intrinsic task computational difficulty, not simply data or domain shift.
Prompt/Instructional Sensitivity of Truth Geometry
Prompt engineering, specifically the inclusion of explicit correctness-evaluation instructions, is found to induce a substantial reorientation of truth directions across layers and tasks. Truth directions learned in a passive template (no prompt) are misaligned (low cosine similarity) with those arising in explicit-evaluation conditions (Figure 4) and generalize poorly across prompt types, especially for arithmetic and complex factual tasks.
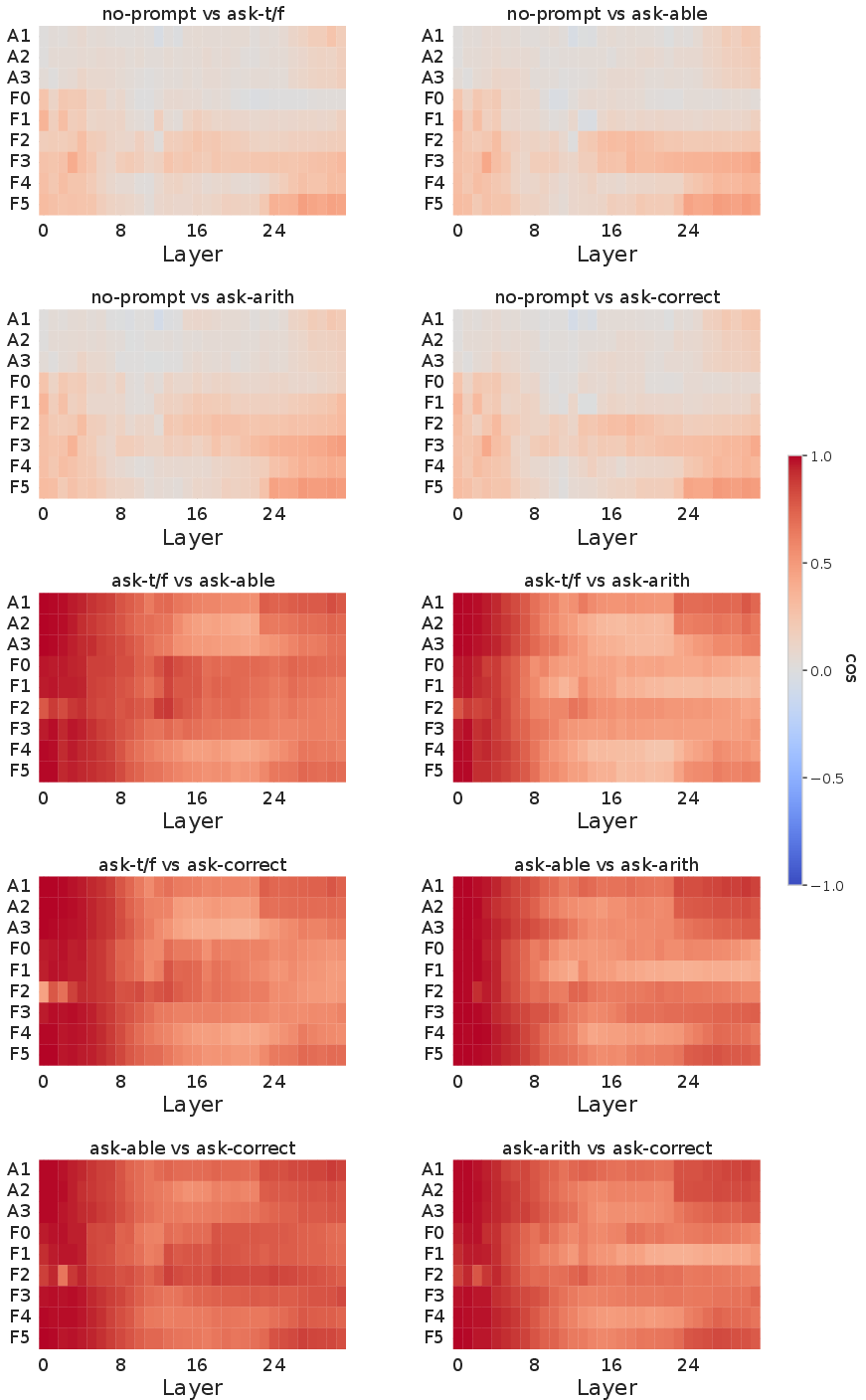
Figure 4: Cosine similarity between truth probes trained under different prompt templates across layers and tasks indicates major misalignment induced by instruction changes.
Moreover, the emergence of linearly separable truth lags by several layers under instruction prompts compared to no-prompt settings in arithmetic and hard factual tasks, further demonstrating the fragility of truth geometry to template framing (Figure 5).
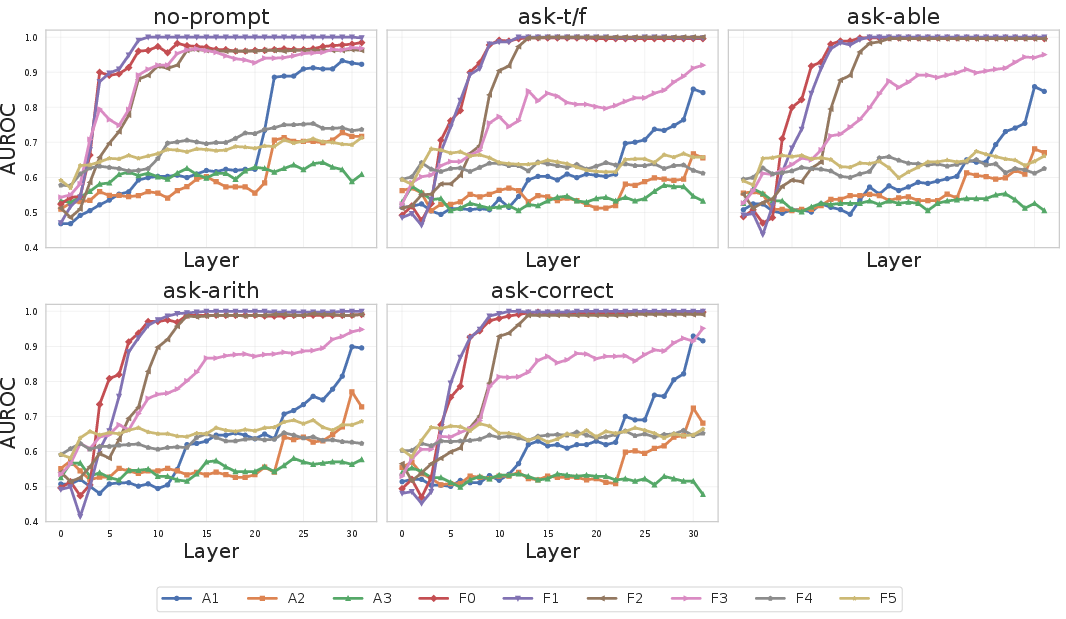
Figure 5: In-domain test-set AUROC per layer across all prompt templates, with prompts delaying the emergence of truth directions.
Experimentation with control prompts (neutral, or random token prefixes) confirms that the observed effects derive from the semantics of truth-evaluation instructions, rather than simple prompt length or syntax. Interestingly, in some cases, explicit truth evaluation can enhance certain cross-task generalizations (e.g., arithmetic to factual), but this improvement never bridges the gap for tasks requiring substantial intermediate computation or more abstract reasoning.
Implications
The results demonstrate that previously reported universal linear truth directions are, in fact, highly fragile and contextually contingent. Truth signals are only robust and generalizable for tasks requiring shallow factual retrieval without intermediate computation. Linearity rapidly breaks down once tasks engage latent reasoning or counting, and probe directions are neither prompt-invariant nor temporally stable across transformer depth.
Practically, as LLMs are increasingly deployed in safety-critical, reliable truth-verification, these results caution against naive use of linear probing for truthfulness assessment, especially when prompt engineering or user instructions induce unpredictable shifts in model internals. Theoretically, the results articulate a key failure of compositionality in current LLM architectures, spotlighting the challenge of achieving robust, directionally consistent representations for complex, multi-step forms of truth.
The findings also interface with the emerging literature on spectrum-of-truth representations [Ying et al., 2026], task-specific orthogonality of truth geometries [Azizian et al., 2025], and the brittleness of knowledge encoding in the presence of task or context shift [Haller et al., 2025].
Conclusion
This work establishes significant boundaries on the universality and robustness of truth directions in LLMs. Truth is linearly encoded and generalizable only for tasks reducible to surface-level factual recall; any requisite for intermediate computation or counting abolishes probe transfer. Truth geometry is prompt-dependent and layer-specific, resulting in multiple, context-specific representations within the same model. These constraints must inform both deployment and further development of truth assessment mechanisms and expose open questions regarding the emergence and stability of semantic representations in deep generative models. Future research should prioritize disentangling the relationship between input- and output-encoded truth, model architectural inductive biases for compositional reasoning, and the development of probe-invariant methods for inspecting LLM internal states.