- The paper introduces k-MIP attention to sparsify full pairwise attention, reducing computational complexity while preserving universal approximation capabilities.
- The methodology leverages symbolic matrix representations and GPU optimizations, yielding up to 10× speedups and linear memory scaling for large graphs.
- Empirical results validate the approach on massive datasets, demonstrating state-of-the-art performance and linking expressive power to advanced structural encodings.
Introduction
This paper introduces k-Maximum Inner Product (k-MIP) attention for graph transformers, addressing the critical scalability limitations of full pairwise attention in graph domains. The k-MIP operator replaces the quadratic all-pairs attention pattern with a sparsified selection of the top-k highest inner product node pairs per query. This enables large-scale information exchange while retaining the flexibility to model arbitrary long-range dependencies. The authors integrate k-MIP attention into the modular GraphGPS framework, perform both theoretical and empirical analysis of expressive power, and benchmark the method on multiple challenging datasets.
Methodology
k-Maximum Inner Product (k-MIP) Attention
Standard multi-head self-attention scales quadratically with graph size N, being infeasible for graphs with more than a few thousand nodes. The k-MIP mechanism selects, for each query, only the top-k keys with highest inner product scores, setting all other attention logit entries to −∞ prior to the softmax. This drastically reduces the number of pairwise computations, making runtime and memory linear in N. The implementation leverages symbolic matrix representations (KeOps-style) for on-the-fly computation, avoiding the materialization of N2 attention scores in memory.
Theoretical analysis rigorously establishes that this sparsification does not reduce expressivity: k-MIP graph transformers can approximate any full-attention transformer arbitrarily well over compact subsets of the input space.
Theoretical Contributions
Expressive Power and the S-SEG-WL Test
A comprehensive analysis situates the expressive power of GraphGPS-based transformers (including those using k-MIP attention) within the hierarchy of Weisfeiler-Lehman (WL) isomorphism tests. Through a reduction to the S-SEG-WL test, the model class is shown to be upper bounded in distinguishing non-isomorphic graphs by the discrimination power of the chosen structural/positional encoding scheme. This matches and contextualizes prior results for various scalable transformer architectures, affirming that the origin of "super-1-WL" expressivity in graph transformers lies fundamentally in non-trivial encodings, not in the global attention architecture itself.
Figure 1: Initial node coloring (iteration 0) provides the foundation for understanding the iterative refinement of graph isomorphism checks employed in expressive power analysis.
Figure 2: Two disjoint 3-cycles serve as canonical examples of graphs not distinguishable by standard 1-WL, highlighting the necessity of more discriminative encodings and higher-order frameworks.
Universal Approximation
The k-MIP Approximation Theorem formalizes that for any permutation-equivariant, continuous function implementable by a full-attention transformer, there exists a k-MIP transformer (with sufficiently large, but still constant—possibly large—depth, head count, and width) that can approximate it arbitrarily well on any compact input set. This is an essential claim ensuring that the memory and runtime reduction of k-MIP attention does not impose a representational bottleneck at the model class level.
Algorithmic and Implementation Details
The k-MIP operator is efficiently implemented using symbolic (formula-based) matrix representations. Rather than storing all N2 possible attention scores, only those corresponding to the top-k entries per query are evaluated as needed. The GPU registers and shared memory are exploited for parallelized, in-place reduction operations, yielding practical speedups of up to 10× over full attention, and enabling experiments on graphs with >500k nodes on commodity (A100) GPUs.

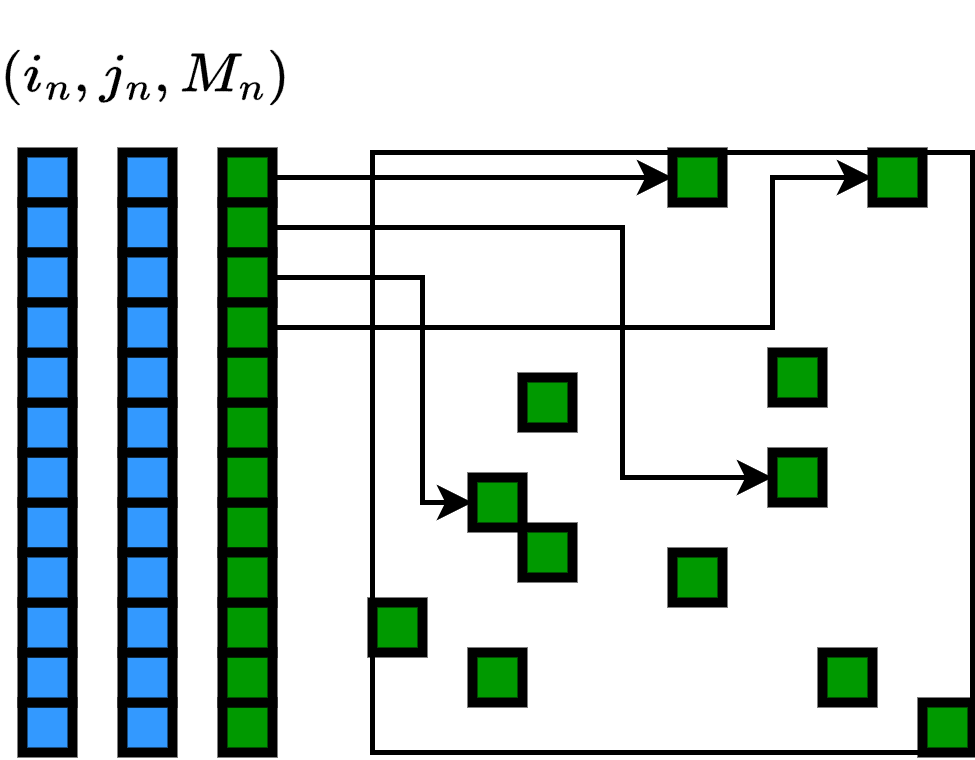
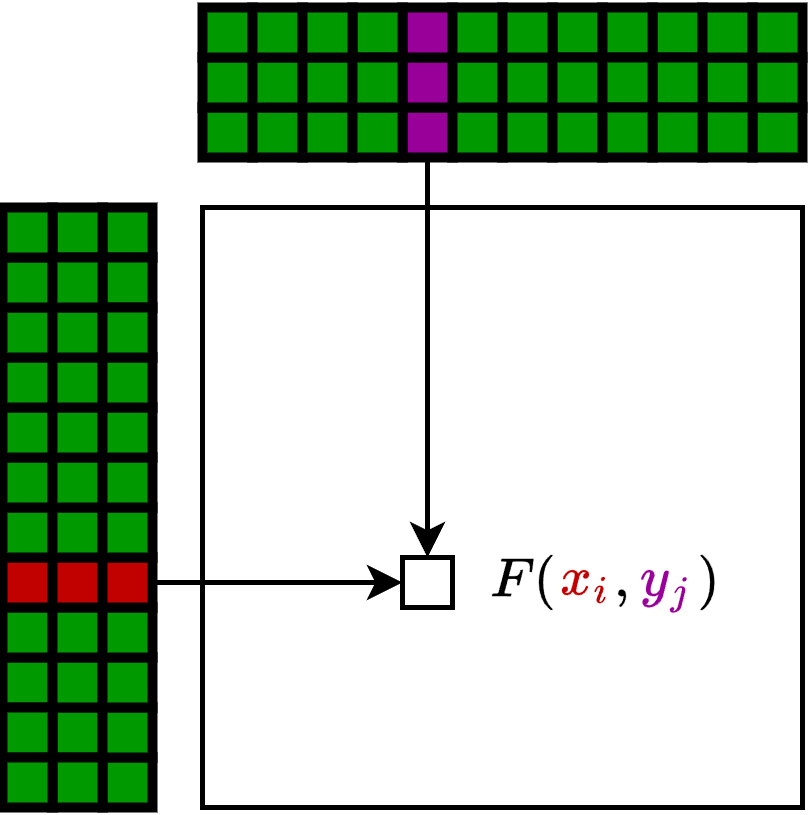
Figure 3: Dense matrix visualization contrasts with the symbolic matrix approach, where memory efficiency is achieved by formulaic lazy evaluation of attention scores.
Empirical Results
Efficiency and Scaling
Batched experiments systematically compare k-MIP with dense full attention (and with a naive non-symbolic k-MIP implementation) across increasing N up to N0. k-MIP achieves linear memory scaling and significant speedup, while dense variants run out of memory at N1.
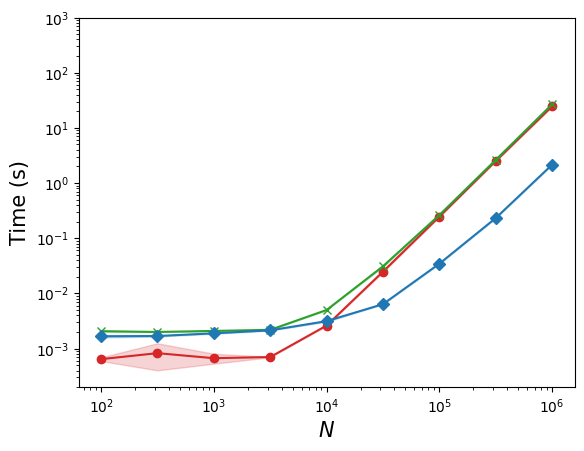
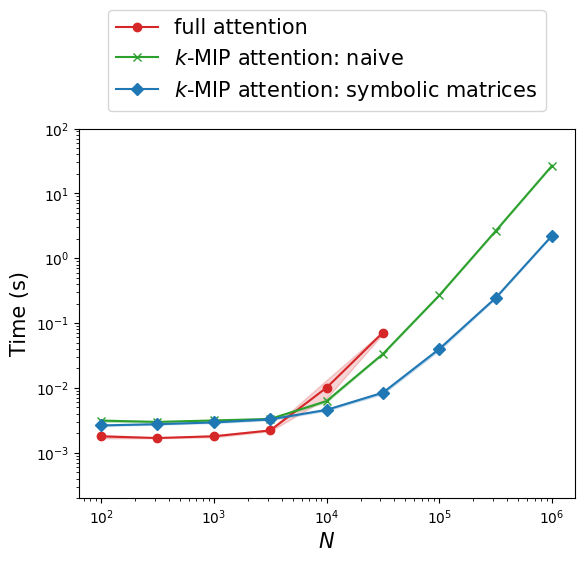
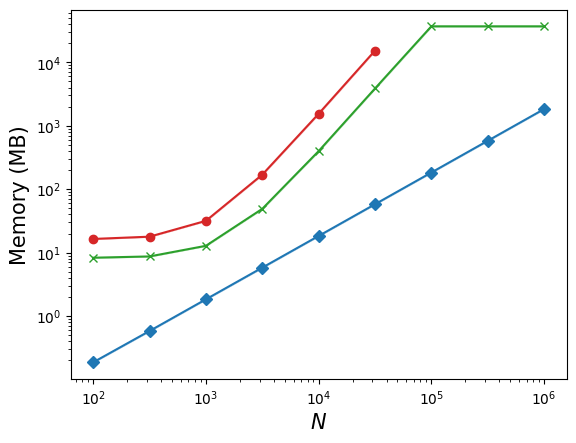
Figure 4: Inference runtime as a function of node count, highlighting the linear memory scaling and significant runtime benefits of k-MIP attention.
Large-Scale Graph Learning
On benchmarks including the Long Range Graph Benchmark (LRGB), City-Networks, and point cloud segmentation datasets (ShapeNet-Part, S3DIS), GPS+k-MIP consistently performs among the top scalable graph transformer architectures. Importantly, on the largest tested graph (London road network, 569k nodes), GPS+k-MIP is the only non-linearized transformer able to train within feasible resource constraints, while BigBird, Exphormer, and standard GPS+Transformer all run out-of-memory.
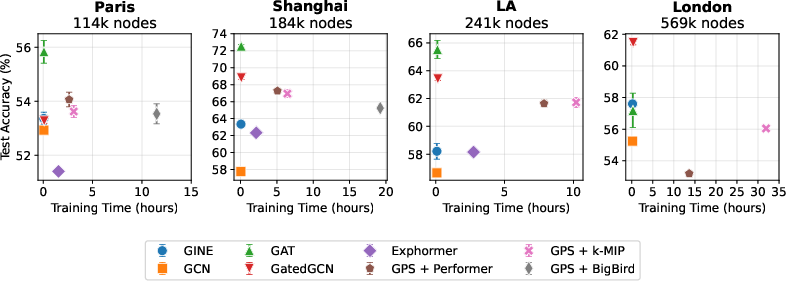
Figure 5: Training time versus accuracy tradeoffs across City-Networks datasets, demonstrating scalability and top-tier accuracy of GPS+k-MIP in practical scenarios.
Influence of N2 and Approximation Quality
Extensive ablations document the impact of N3 on accuracy-efficiency tradeoffs. While larger N4 increases runtime, performance converges beyond moderate values; thus, appropriate selection of N5 tailors the resource profile for a given task.
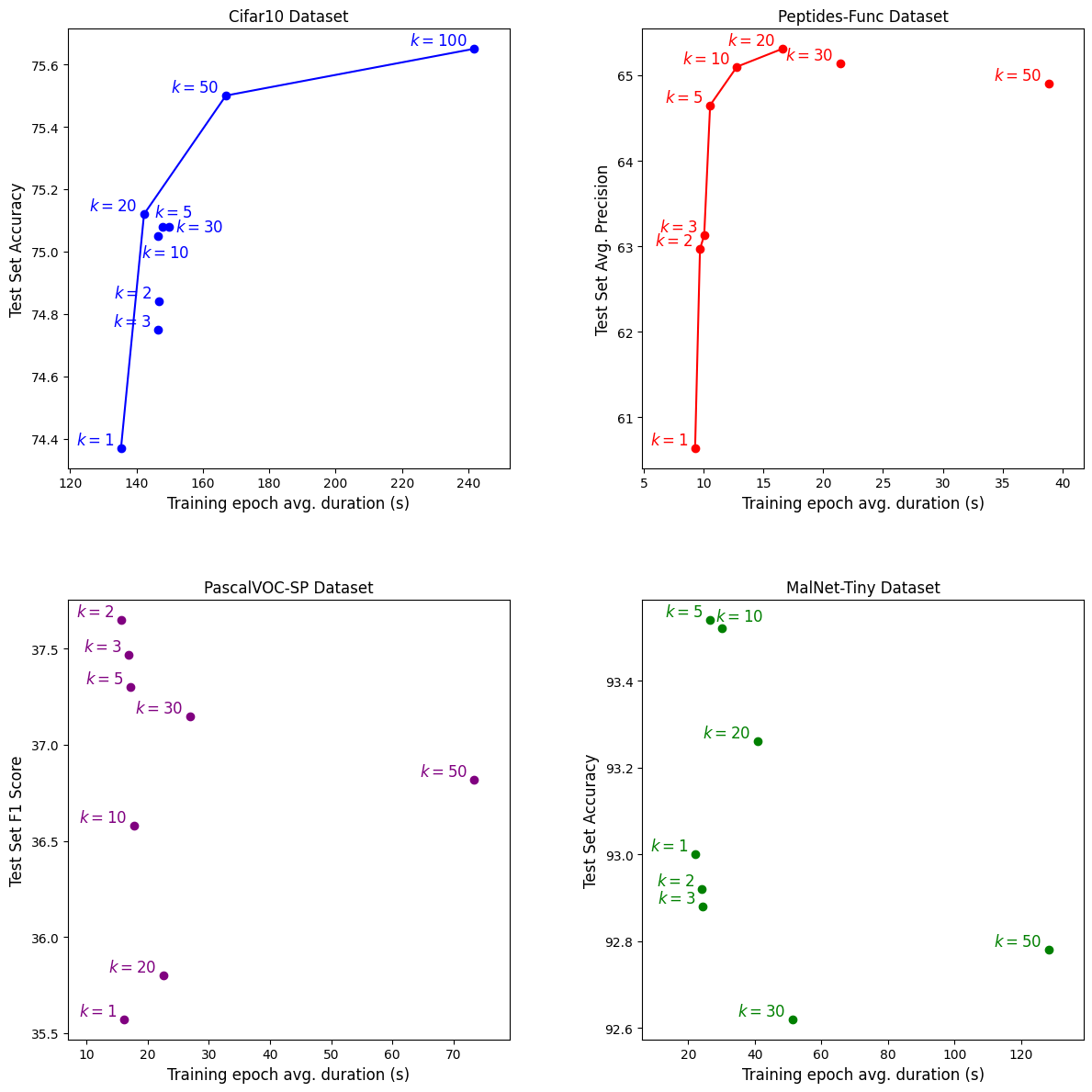
Figure 6: Scatter plots showing the tradeoff between test performance and training epoch duration for varying N6 on benchmark datasets, elucidating Pareto frontiers and optimal operating points.
Additionally, detailed analysis shows that the layerwise k-MIP operator is not a direct local approximation to the dense attention mechanism (L2 output discrepancies remain substantial for moderate N7), but aggregation across layers restores approximation power.
Implications and Outlook
The main practical implication is that global-attention-based graph transformers are, from an expressivity perspective, no longer limited by the all-pairs computational bottleneck. With k-MIP, very large graphs can be processed on single-GPU hardware without loss of theoretical power. The upper bound established via S-SEG-WL test highlights the centrality of positional and structural encodings for task-specific representational requirements: increased discriminative encodings can lead to expressiveness exceeding standard 1-WL, but overfitting risks and computational costs (especially for spectral encodings) become relevant in massive graph regimes.
Theoretically, this work clarifies a longstanding question about the relationship between efficient “sparse” attention mechanisms and full-attention universal function approximation. The construction in this paper demonstrates that sparse top-N8 connectivity, when learnable and adaptive, does not fundamentally restrict the model’s capacity, complementing prior claims for generic sparse transformers with results tailored for permutation-equivariant graph domains.
For future research, further hardware-level optimizations (e.g., Tensor Core-aware primitives or combinatorial sampling strategies) could yield additional runtime and memory improvements, perhaps rivaling or surpassing low-precision optimized dense solutions. It will also be important to explore learnable and adaptive N9 schedules, as well as integrating richer encoding schemes, as practical solutions for real-world graphs where long-range dependencies are non-uniformly distributed.
Conclusion
k-Maximum Inner Product attention is a scalable, flexible, and theoretically sound mechanism for enabling global information exchange in graph transformers at unprecedented node counts, without sacrificing expressiveness. Integrating k-MIP in the GraphGPS framework rigorously preserves universal approximation capability while confining architectural discriminative power within analytically tractable S-SEG-WL bounds. The empirical evaluation on a wide range of datasets validates both the efficiency and practical utility of the approach, establishing it as a robust solution for large-scale graph learning tasks.

