- The paper presents a semi-automated annotation workflow that employs instruction-tuned SLMs to extract key clinical entities from pediatric renal biopsy reports.
- The methodology features iterative stages including section-aware preprocessing, guideline development, optimized prompt engineering, and disagreement modeling with minimal clinician oversight.
- The approach outperforms traditional extraction methods with entity-level accuracy up to 84.3%, demonstrating its feasibility for NHS research environments.
Semi-Automated Annotation of Paediatric Histopathology Reports Using SLMs
Introduction
Structured extraction of clinical information from unstructured Electronic Patient Records (EPRs) is essential for advanced analytics and research in healthcare. While histopathology reports communicate complex diagnostic narratives, their free-form nature and use of domain-specific terminology present significant obstacles for computational approaches to information extraction. This paper presents a workflow leveraging instruction-tuned Small LLMs (SLMs, 1B–5B parameters) in a semi-automated framework for extracting key entities from paediatric renal biopsy reports, explicitly optimizing for environments constrained by privacy, computational resources, and annotation costs (2604.04168).

Figure 1: The general histopathology workflow, with focus on extracting key text spans from clinician reports that are relevant for diagnosis.
Workflow and Methodological Innovations
The proposed annotation pipeline implements four iterative stages with three minimal clinician touchpoints: (1) section-aware preprocessing and exploratory analysis of reports, (2) systematic development of a clinically-grounded entity schema and guidelines, (3) optimized prompt engineering for SLM-based QA, and (4) a disagreement modelling framework for triage and prioritization of clinician review. This highly modular system is instantiated via a project-specific guidelines spreadsheet and end-user Streamlit interfaces, ensuring accessibility for clinical collaborators.
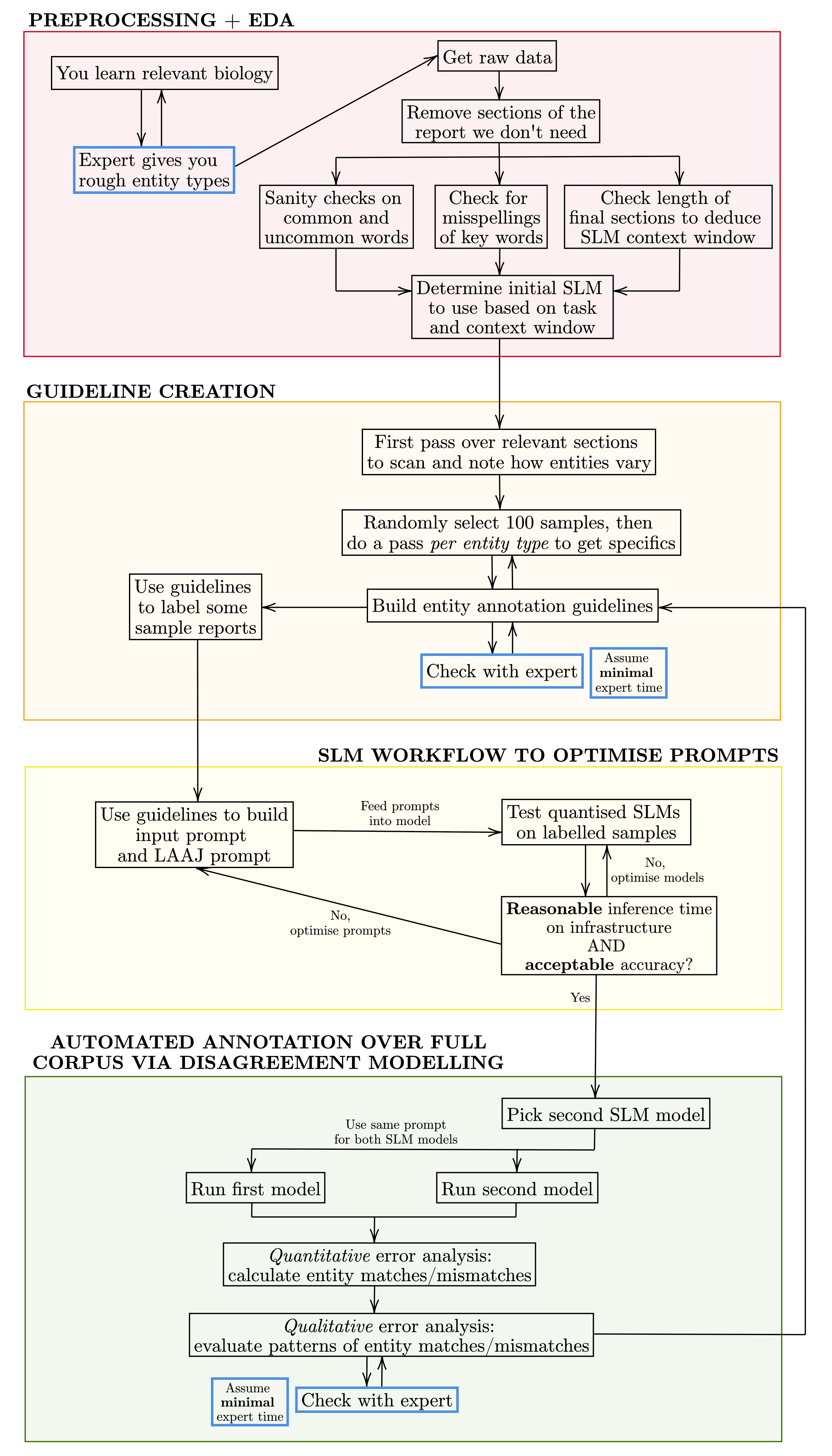
Figure 2: Annotation workflow for medical reports, highlighting three expert touchpoints.
The entity schema, derived from an adaptation of the Banff classification, encompasses both transplant and native biopsies, supporting granular pathophysiological distinctions. Entities span multiple data types, including binary, numeric, categorical, string-simple, and string-complex. The guidelines address data type adaptation, handling missingness, explicit inclusion/exclusion criteria, and mapping of qualitative descriptors, thereby maximizing biological coverage while maintaining annotation tractability.
Prompt engineering exploits a QA framing, integrating few-shot exemplars and domain-specific entity guidelines into system messages for SLMs. The prompt design enables grouping of related entities for efficient inference and reduces annotation ambiguity.
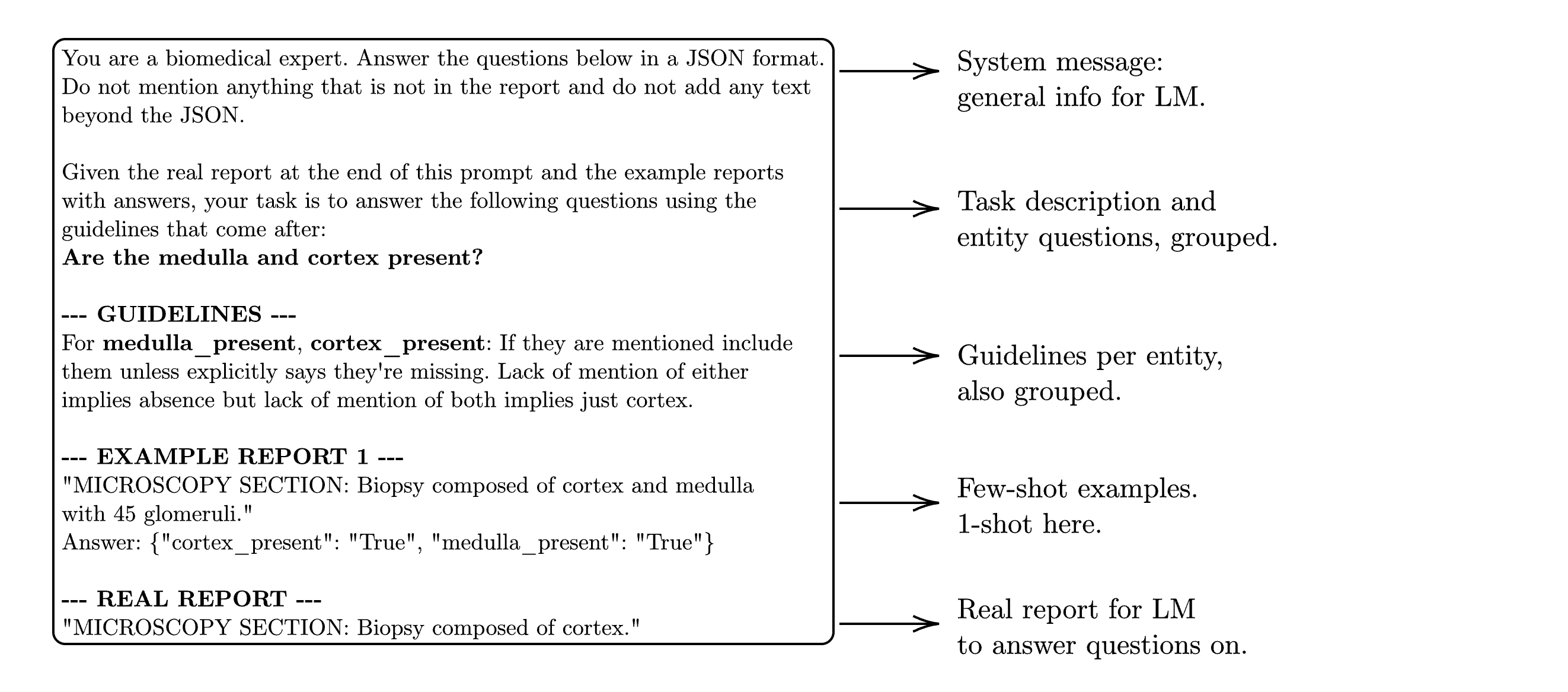
Figure 3: Example entity extraction prompt for grouped entities cortex_present and medulla_present.
LM-as-a-Judge for Evaluation
Exact matching suffices for most entities; however, string-complex predictions (e.g., final diagnosis) require semantic assessment. To this end, the authors devise an LM-as-a-Judge (LAAJ) protocol, systematically engineered through iterative query refinement.

Figure 4: Development pipeline for the final LM-as-a-Judge (LAAJ) query for robust string comparison.
The final LAAJ query incorporates equivalence heuristics, expert affirmation, answer constraints, and if-else logic for edge cases. Residual error rate on held-out entity pairs is ~10%, and inherent non-transitivity in SLM-based semantic similarity evaluation remains a limiting factor.
Experimental Setting and Models
Evaluation is conducted on 400 annotated reports (from a total of 2,111), with a stratified sample for robust schema development. SLMs are run locally in CPU-only environments typical of NHS hardware (16GB RAM). The comparison set comprises five open SLMs (Qwen-2.5 1.5B, Gemma 2 2B, Llama 3.2 3B, Phi-3.5 Mini 3.8B in Q4 and Q8 quantization), baseline token and regex-based approaches (spaCy), and transformer QA backbones (BioBERT-SQuAD, RoBERTa-SQuAD, GLiNER, and NuExtract).
Results
Structured prompt engineering, using either guidelines or few-shot examples, consistently improved SLM extraction performance, with gains ranging from +7% to +38% depending on the model and prompting regime. The highest SLM performance is achieved by Gemma 2 (2B), attaining 84.3% entity-level accuracy, outperforming all traditional approaches: spaCy (74.3%), BioBERT-SQuAD (62.3%), RoBERTa-SQuAD (59.7%), and GLiNER (60.2%).
JSON parsing instability is a critical bottleneck for large-scale deployments; models such as Phi-3.5 Q4/Q8 exhibit catastrophic failure after a threshold number of inferences, likely due to quantization or context length limitations. In contrast, Gemma 2 and Qwen-2.5 maintain near-perfect output integrity.
Entity-Level Analysis
SLMs exhibit pronounced improvements for complex string-based entities, particularly final_diagnosis (SLM: up to 91.8% vs. spaCy: 0.2%), and challenging numerical or binary entities. SpaCy uniquely outperforms SLMs on n_segmental (90% vs. SLM: <89.3%), attributable to the high class imbalance (majority = 0). Overall, the SLM advantage is most evident for tasks with non-standardized phraseology and high context dependence.
Comparative Assessment
In runtime, SLMs require 26–72 seconds per report (on CPU), enabling full dataset inference in under two days. This is tractable in NHS research environments, and the hardware requirements ensure broad deployability.
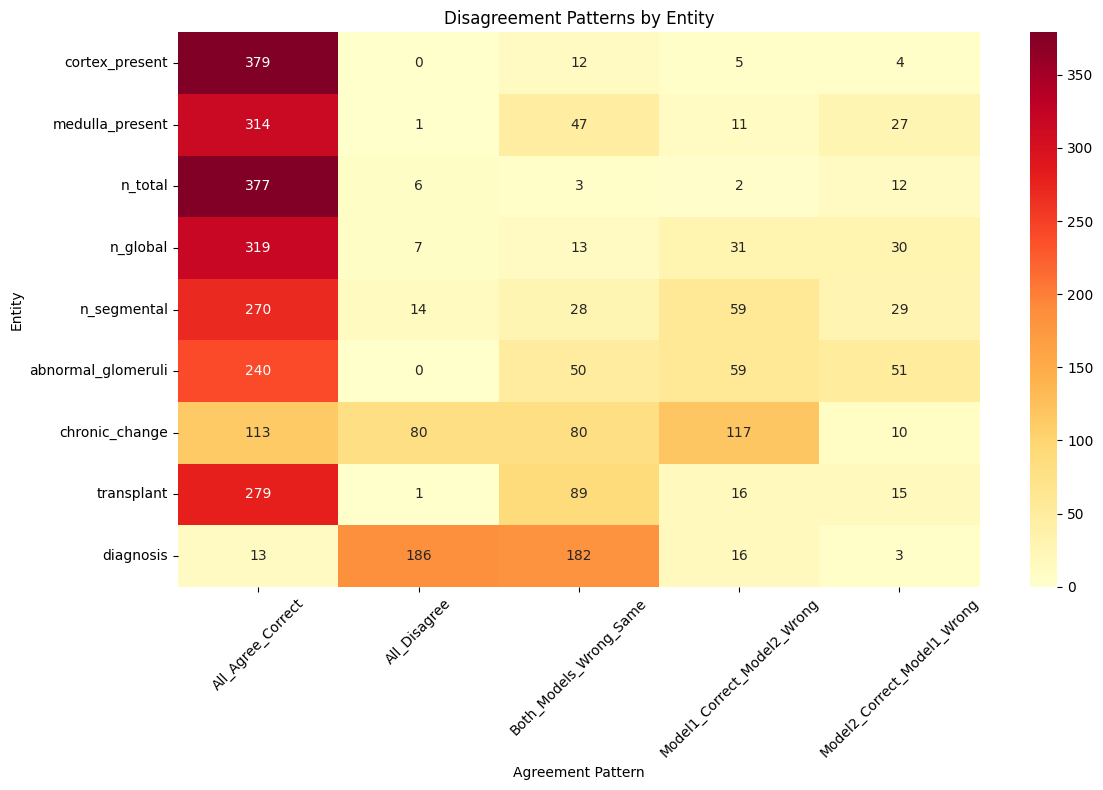
Figure 5: Heatmap visualizing disagreements between top SLM models (Gemma 2 and Llama 3.2) and ground truth, highlighting concordance and characteristic error modes.
Disagreement Modelling
Disagreement modelling across two top SLMs (Gemma 2, Llama 3.2) and ground truth provides actionable triage: 64% complete agreement, 14% systematic errors (both models erroneous in the same manner), and 8% total disagreement. High-disagreement entities (e.g., chronic_change, final_diagnosis) are primarily due to LAAJ limitations, not true semantic divergence.
Clinically prioritized sampling from the flagged reports streamlines clinician-in-the-loop review, optimizing annotation throughput. Notably, overt model failures (e.g., empty predictions) are differentiated from ambiguous semantic cases.
Interface and Usability
Annotation and validation interfaces are user-friendly, facilitating efficient annotation by clinicians and validation workflows for flagged disagreement cases.
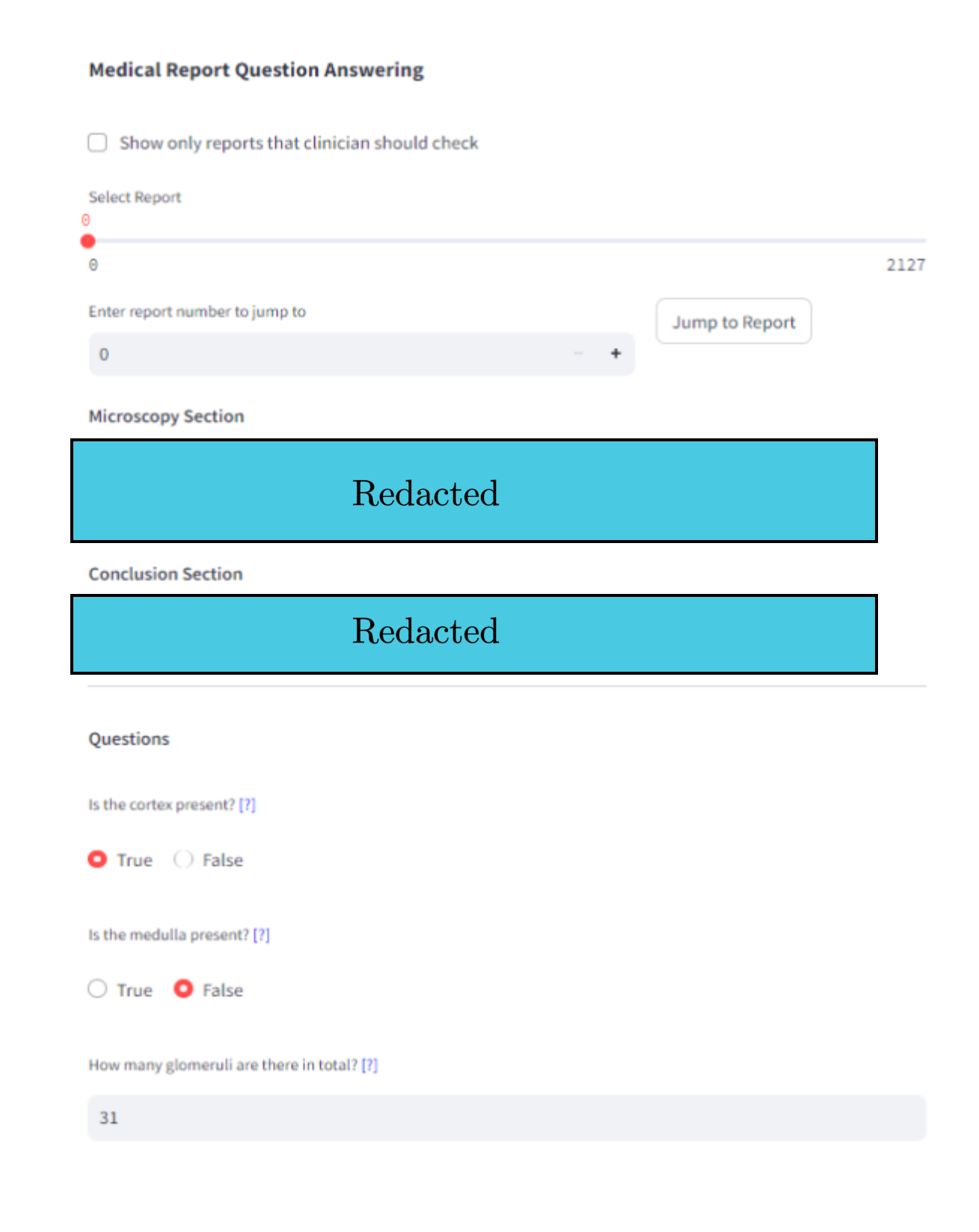
Figure 6: Streamlit app interface for entity-level QA annotation.
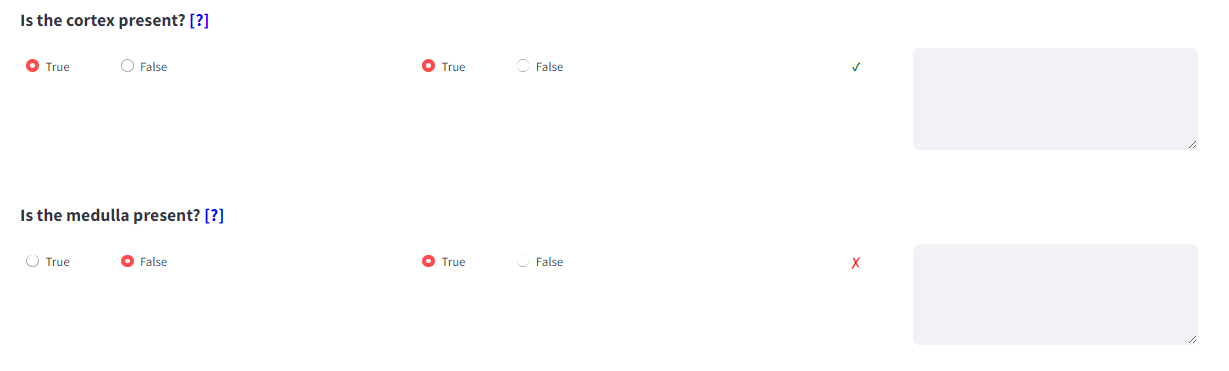
Figure 7: Comparative Streamlit interface for side-by-side model predictions and qualitative error analysis.
Discussion
This study demonstrates that SLMs (≤5B parameters) with well-designed prompts and guidelines can deliver domain-adapted entity extraction in clinical free text that meets practical utility thresholds (>80% accuracy) under realistic local compute constraints. The approach substantially outperforms mainstream biomedical NER and QA baselines for complex, context-dependent entities. For simple binary and majority-class entities, regex and token-extraction methods remain competitive or superior.
A remarkable empirical finding is that prompt guidelines and few-shot examples, when used independently, provide similar accuracy gains, but their combination offers negligible further improvement. This suggests an interaction between explicit instruction and demonstration that saturates model learning capacity in the low-shot regime for SLMs.
While the LAAJ judge mechanism for string semantic equivalence achieves high agreement, transitivity and stringently accurate diagnosis evaluation remain open issues, limiting the workflow's suitability to research but not clinical production contexts.
From a practical perspective, the accessible Python codebase and ready compatibility with ubiquitous NHS infrastructure promote rapid translational adoption. The minimal annotation overhead—three clinician meetings over three months—is a stark contrast to the annotation requirements for end-to-end fine-tuning approaches.
Limitations and Future Directions
The main limitations are the moderate performance ceiling on certain entities (e.g., chronic_change) and the lack of independent validation on previously unseen institutions or less templated pathology domains. The analysis is also limited to pediatric cohorts with a relatively homogeneous clinical pathway.
Promising avenues for extension include:
- Hybrid pipelines (e.g., rule-based extraction for binary/numeric, SLM for context-rich strings)
- Entity schema granularity optimization
- Improved judge models and ensemble evaluation mechanisms, such as JudgeBlender-style approaches
- Deployment in other biomedical areas with standard diagnostic taxonomies
Conclusion
This work establishes, with robust empirical evidence, that SLM-driven workflows, governed by curated guidelines and selective clinician oversight, enable practical and efficient structured annotation of complex medical narratives in resource-limited environments. The approach is widely generalizable to similar annotation tasks in healthcare NLP, balancing accuracy, cost, and privacy imperatives (2604.04168).