- The paper introduces a formal framework defining systematic understanding in deep networks through internal models and stable bridge principles.
- It employs case studies like torus regression and grokking in modular arithmetic to illustrate how deep models internalize structure.
- The analysis highlights that despite strong local generalization, deep learning representations remain fractured, symbolically misaligned, and non-reductive.
Modeling Systematic Understanding in Deep Learning Architectures
Introduction
The paper "A Model of Understanding in Deep Learning Systems" (2604.04171) presents a rigorous framework for analyzing and defining systematic understanding in machine learning agents, specifically in deep neural network architectures. Departing from anthropocentric or solely behavioral notions, the author develops a philosophically thin but technically precise explication: systematic understanding occurs when an agent system possesses an adequate internal model that robustly tracks non-trivial regularities in a target system, is connected by stable bridge principles, and supports reliable prediction distinct from rote memorization or interpolation.
This framework is instantiated with respect to deep networks, where the author diagnoses a distinct pattern termed the Fractured Understanding Hypothesis (FUH): deep learning systems acquire genuine, but typically fragmented, symbolic, non-reductive, and weakly unified forms of understanding, in contrast to the ideal of unified, symbolic, and reductive scientific knowledge.
The proposed framework decomposes systematic understanding into several necessary components:
- Adequate Internal Model: The agent system must embody a subsystem that tracks relevant regularities in the target (property p of system T), with compression exceeding brute memorization (formalized via minimum description length and information-theoretic criteria).
- Bridge Principles: Robust interfaces or mappings exist that connect internal model variables to properties of the target system, such that predictions can be systematically derived.
- Prediction Without Memorization: Internal compression is robust across structure-preserving perturbations; mere lookup-tables or sample-specific memorization are explicitly excluded via operational robustness tests and formal description length proxies.
- Kinds of Understanding: The framework formally distinguishes between structural, reductive, and causal understanding, with the primary focus on the structural: the existence of a homomorphism or analogous mapping between internal and external relations governing property p.
The framework is deliberately non-anthropocentric, avoiding appeals to qualitative experience, introspection, introspectable semantics, or language-specific intentionality.
Deep Learning Systems as Spline Approximators
The author provides a technical account of feed-forward neural networks as universal function approximators, especially in the setting where activation functions are piecewise-linear (e.g., ReLU). The learned function fθ(⋅) partitions input space into polytopal regions, each governed by an affine mapping, and thereby implements a highly expressive multivariate spline.


Figure 1: Ground truth surface.
This explicit architectural affordance is pivotal in the subsequent diagnosis: any internalized regularity in the target system must be encoded via explicit parameters determining how spline "patches" are orchestrated to fit the target data. This structure provides the necessary (if not always sufficient) precondition for systematic understanding in the sense defined.
Proxy Debates: Generalization, Memorization, Interpolation, and Extrapolation
The paper dissects much of the confusion and dialectical impasse in the field as arising from the absence of formal definitions of "understanding," leading researchers to rely on proxies such as:
- Generalization vs. Memorization: Deep networks often achieve strong generalization while possessing extremely high capacity (capable of memorization), a phenomenon at odds with expectations from traditional statistical learning theory.
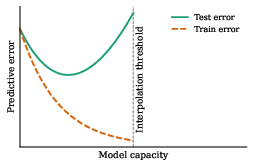
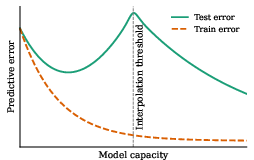
Figure 2: Schematic showing the bias–variance tradeoff with increasing system capacity.
- The Double Descent and Grokking Phenomena: Networks can transition from memorization to generalization even in interpolating regimes, with test accuracy sometimes sharply increasing well after training accuracy saturates.
- Interpolation vs. Extrapolation: The operational criterion—whether successful predictions outside the convex hull or latent manifold of training data constitute actual extrapolation or sophisticated form of interpolation—is formally recast.
The author argues these proxy battles oscillate around the true technical criterion: non-memorizing, pattern-tracking compression of target regularities.
Illustrative Examples: Structural Understanding in Practice
A series of technically detailed examples anchors the conceptual framework:
Topological Structure Learning
A ReLU MLP is trained to regress the implicit equation of a toroidal surface using only local scalar supervision. Post-training, the learned implicit function, when thresholded, yields a surface with the correct topological genus (1), despite no explicit topological loss or supervision being provided.


Figure 3: Ground truth surface.
This demonstrates that neural architectures can encode structural understanding of global invariants from local data—the learned function is homeomorphic to a torus.
Grokking and Modular Arithmetic
A transformer is trained on modular addition. The model initially memorizes training pairs, with test accuracy suppressed. Eventually, the test accuracy exhibits a sharp transition, signaling internalization of an algorithmic, symmetry-respecting mapping (grokking). Frequency analysis of the logits reveals strong spectral concentration, indicating the learned function embodies the correct modular algebraic structure.
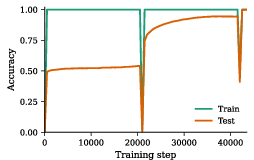
Figure 4: Evolution of training (blue) and test accuracy (red) exposes the characteristic grokking dynamic: test accuracy remains suppressed until a sudden alignment event.
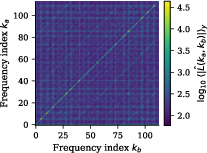
Figure 5: Spectral analysis finds sharp Fourier concentration, consistent with a latent group-structured addition operation.
The Fractured Understanding Hypothesis
Based on these case studies and broader literature, the central claim is formalized:
While deep networks often acquire systematic understanding in the defined sense, their internal representation typically manifests as symbolically misaligned, non-reductive, and fragmented. The underlying dependencies are distributed across piecewise mappings, rather than being organized into a compact, unified set of reusable principles.
Specifically:
- Symbolic Misalignment: Internal representations rarely align with the natural symbolic structure of the target domain; they are arbitrary coordinates in parameter or activation space.
- Non-reductivity: The internal model often lacks a compact reduction to underlying dynamical or generative principles, remaining at the level of patchwork functional dependencies.
- Weak Unification/Fragmentation: Local generalization is strong, but global unification across contexts is brittle, producing Votsis-style "monstrous" theories with weak confirmational linkage.
Strong claim: Even in cases of high predictive performance, the model's understanding is typically fractured, not unified—a pattern not generally alleviated merely by scaling.
Implications and Future Directions
The analysis has several direct implications:
- Interpretability Science: Mechanistic interpretability becomes essential—not for psychological transparency, but to test whether compression is achieved by reusable, unified internal structure or brittle splines with local validity.
- Design of Architectures and Objectives: Progress toward scientific ideal understanding may require explicit architectural constraints (e.g., symmetry bias, causal models), regularization (forcing unification), or integration with symbolic manipulation (neuro-symbolic models).
- AI Safety and Deployment: The fractured nature of understanding in current systems explains sudden failures under distributional shift and motivates research into variable discovery, robust factorization, and causal representation learning.
The author suggests significant progress may arise by coupling deep learning with symbolic regression and explicit causal modeling, or by using hybrid neuro-symbolic architectures.
Conclusion
This work provides a formal explication of systematic understanding suitable for deep learning systems and delivers a detailed diagnosis of their epistemic strengths and limitations. While deep networks can, under the right conditions, internalize non-trivial structure, their default form of understanding is fractured, local, and symbolically misaligned. The framework not only clarifies debate but also identifies research directions for bridging the gap toward unified, transferable machine understanding.