- The paper introduces a comprehensive benchmark, Graphic-Design-Bench, that evaluates AI across 49 design tasks including layout, typography, SVG graphics, template semantics, and animation.
- The paper employs detailed component-level annotations from the LICA dataset, using metrics such as mIoU, SSIM, and CLIPScore to reveal critical performance deficits in spatial reasoning and typographic fidelity.
- The paper demonstrates that current multimodal models perform poorly on structured design challenges, underscoring the need for specialized pretraining and domain-calibrated evaluation frameworks.
Graphic-Design-Bench: A Comprehensive Benchmark for Evaluating AI on Graphic Design Tasks
Introduction and Motivation
The "Graphic-Design-Bench: A Comprehensive Benchmark for Evaluating AI on Graphic Design Tasks" systematically addresses the deficit of structured, design-native evaluation frameworks for AI in the professional graphic design domain. Unlike prior benchmarks focused on natural-image understanding or generic text-to-image generation, GraphicDesignBench (GDB) targets the high-dimensional setting of real-world layered design, accounting for composite layouts, typographic fidelity, structured vector graphics, and animation—all of which embody non-trivial, multiscale constraints that conventional metrics and datasets fail to capture.
Benchmark Design and Structure
GDB is constructed on the LICA layered-composition dataset, which provides component-level annotations, including bounding boxes, type, z-order, typography specs, vector metadata, and animation parameters. This enables explicit evaluation of both perception and generation tasks in a manner that is fundamentally inaccessible with flat raster datasets, thereby facilitating tasks such as partial layout completion, typography extraction, style-consistent template variation, and temporally structured video synthesis.

Figure 1: LICA samples from the core benchmark set illustrate the diversity of layouts, component hierarchies, and task-relevant annotations present in the corpus.
GDB consists of 49 tasks across five axes: layout, typography, SVG vector (infographics), template/semantics, and animation, each assessed under understanding and generation paradigms, yielding both domain breadth and task granularity. Metrics are selected from a suite of design-specific quantitative measures including mIoU, SSIM, CLIPScore, OCR, JSON/SVG validity, and human-aligned preference models (NIMA, HPSv3, M-Judge), as well as new diagnostics for compositional fidelity.



Figure 2: Example design templates illustrating the spectrum of layout properties—aspect ratio diversity, frame/crop configuration, spatial complexity, and decorative treatments.
Comparative Evaluation of Frontier Models
A spectrum of multimodal LLMs and generative backbones (Gemini-3.1, GPT-5.4/1.5, Claude-Opus-4.6, Sora, Veo) are used to baseline GDB. Each model is evaluated for both perception (e.g., type/class/position recognition, intent classification) and synthesis (e.g., intent-to-layout generation, style completion, Lottie/SVG code generation) under standardized prompt and API-driven settings.
Key findings:
- Substantial performance deficits: Across nearly all fine-grained design tasks, state-of-the-art models produce outputs far from usable performance. For example, in layout component detection, the leading model achieves only 6.4% [email protected]—orders of magnitude below natural-image detection baselines. Typography tasks, such as font family classification, reach only 23.7% top-1 accuracy across 167 classes, with highly skewed macro-F1, while text color ΔE ranges up to 52 units on weak models.
- Task stratification: High-level semantic tasks (e.g., coarse template categorization with constrained vocabulary) are in the "partially solved" regime (>70% accuracy). However, as tasks require compositional or structure-dependent outputs (multi-element completion, layered inpainting, animation keyframe ordering), performance quickly degrades.
- Intersectional limitations: Tasks requiring precise spatial grounding, typographic recovery, SVG code synthesis, or temporal structure (animation) universally expose bottlenecks. LLMs display systematic errors: element overcounting by orders of magnitude, consistent confusion in geometric reasoning, and failure to confine edits to prescribed regions.



Figure 3: Representative failure cases for layout understanding—including aspect ratio misclassification, severe overcounting, type collapse.


Figure 4: Layer order prediction failure—incorrect z-ordering that disrupts layout usability.

Figure 5: Partial layout completion—models fail at multiple-object placement, ignoring contextual cropping and introducing unnatural object positioning.
For generation tasks, such as intent-to-layout, high-level metrics (CLIP, PickScore, ImageReward) can mask critical deficiencies in text fidelity, hierarchy, and usability, emphasizing the necessity for domain-calibrated ground truth and human preference circuits. Similarly, in aspect-ratio retargeting, models diverge markedly in asset recall, hallucination rates, and text preservation, demonstrating complementary but incomplete strengths.
Domain-Specific Results
Layout and Spatial Reasoning
Despite advances in multi-modal perception, current AI models cannot reliably parse or synthesize structured layouts. Tasks probing component localization, stacking, frame/crop inference, and multi-aspect adaptation reveal unresolved gaps, especially in multi-element and structurally entangled contexts.
Typography
Extraction and rendering of typographically faithful text remain unsolved in the majority of sub-tasks. Fine-grained fonts, colors, weights, alignments, and styled spans are not comprehensively recoverable. Styled text generation in layout-constrained regions is particularly fraught: models frequently spill beyond mask boundaries, hallucinate or reflow text content, or modify nearby non-target elements, making the required precision for real-world editing unattainable.

Figure 6: Visualization of typography attributes—font family, size, weight, color, alignment, spacing, and rotation.



Figure 7: Typography task failures—misclassification of font category, color inversion, and non-detection of curved text.


Figure 8: Text parameter misprediction: incorrect sizing and placement lead to visual misalignments and composition defects.
Infographics (SVG/Lottie) and Structured Code Generation
SVG understanding and editing tasks show that models are more consistent in perceptual and semantic Q/A from code (up to 93.7% accuracy on semantic questions), but bug fixing and multi-operation edits encounter non-trivial error rates and output invalidity. In SVG and Lottie generation, compositional fidelity is strongly input-modality dependent; text-to-SVG yields schematic but not pixel-faithful results, while image-to-SVG improves up to 0.918 SSIM (GPT-5.4), but with persistent geometric/gradient inaccuracies. Lottie generation exposes severe breakdowns in animation structure, compositional layering, and sequence control.

Figure 9: Text-to-SVG and image-to-SVG generation examples exhibit failures in background assignment and artifact introduction, even in the presence of explicit textual or visual specification.
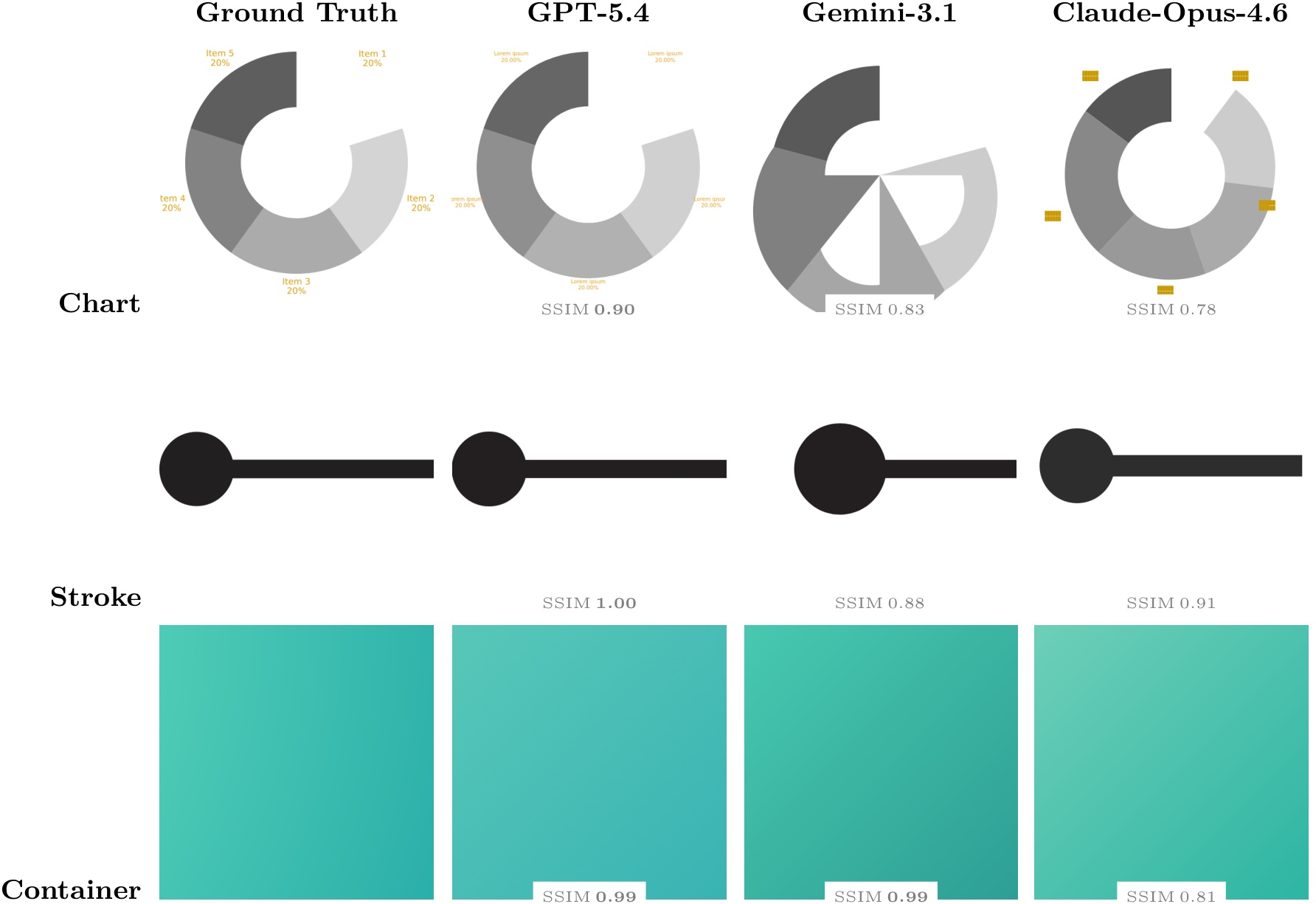
Figure 10: Image-to-SVG across element types; even top-performing models miss central features (holes, labels) and have difficulty with gradient mapping.
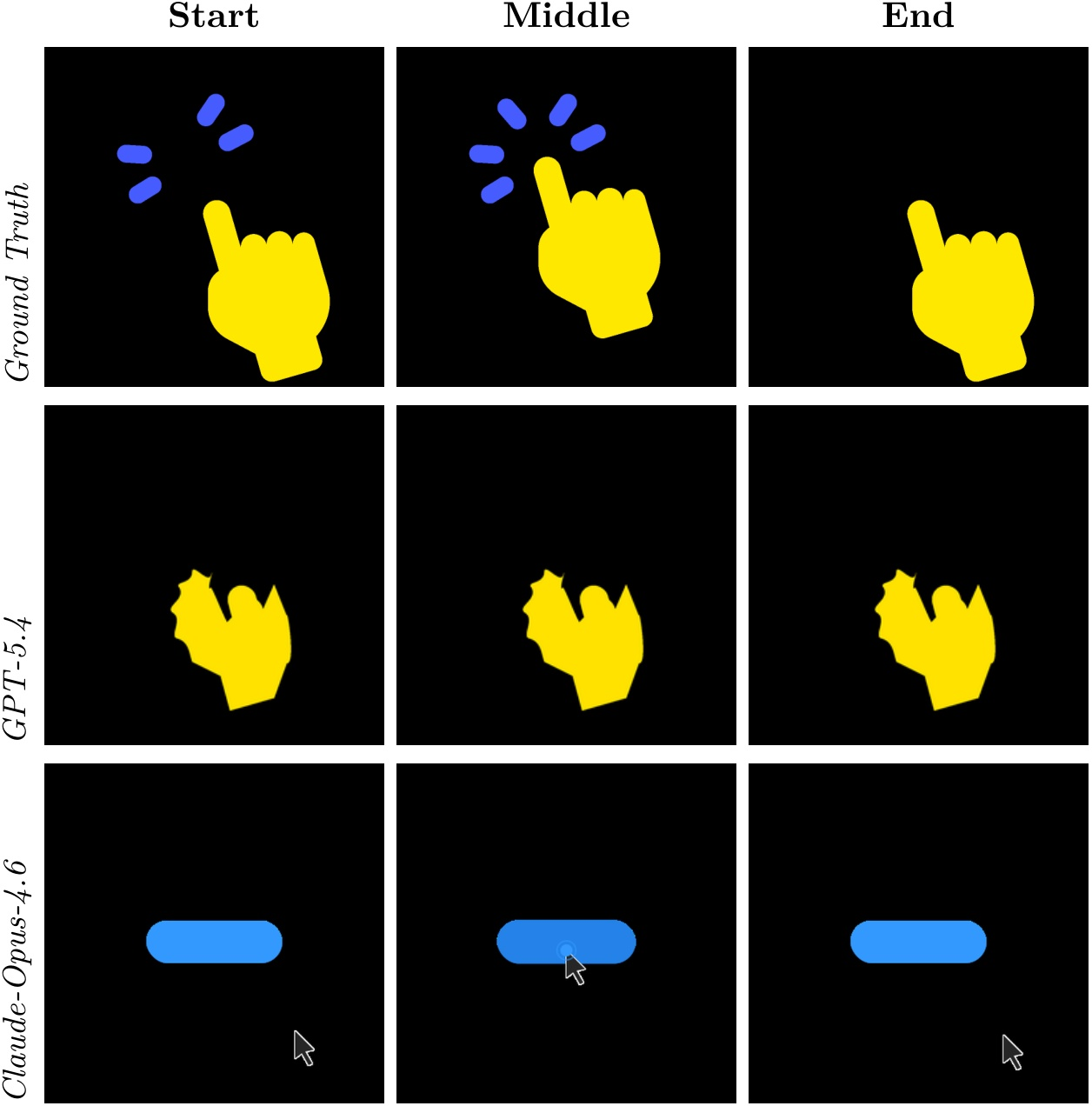
Figure 11: Lottie generation incapacity—none of the evaluated models reproduce animation structure or layer choreography correctly.
Template Semantics
Model performance in free-text user intent assignment saturates near the practical ceiling of current annotation granularity. However, template variant understanding exposes a preference for superficial (font similarity, palette) over deeper structural alignment—non-LLM feature-based baselines perform competitively in clustering and retrieval, exceeding LLMs in some cases. Category classification is highly sensitive to label constraint; unconstrained, models fail due to label aliasing rather than core perceptual deficits.
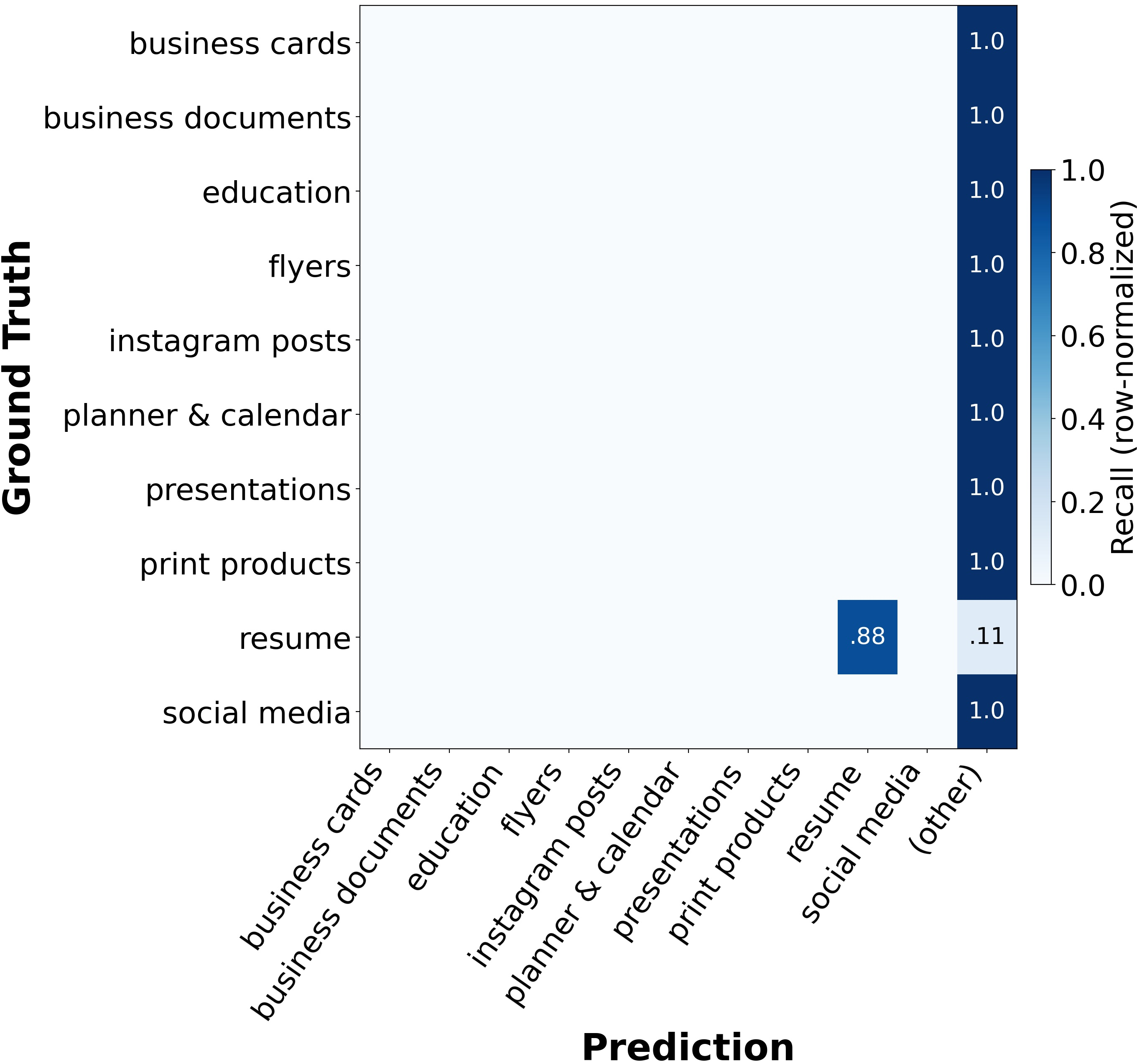
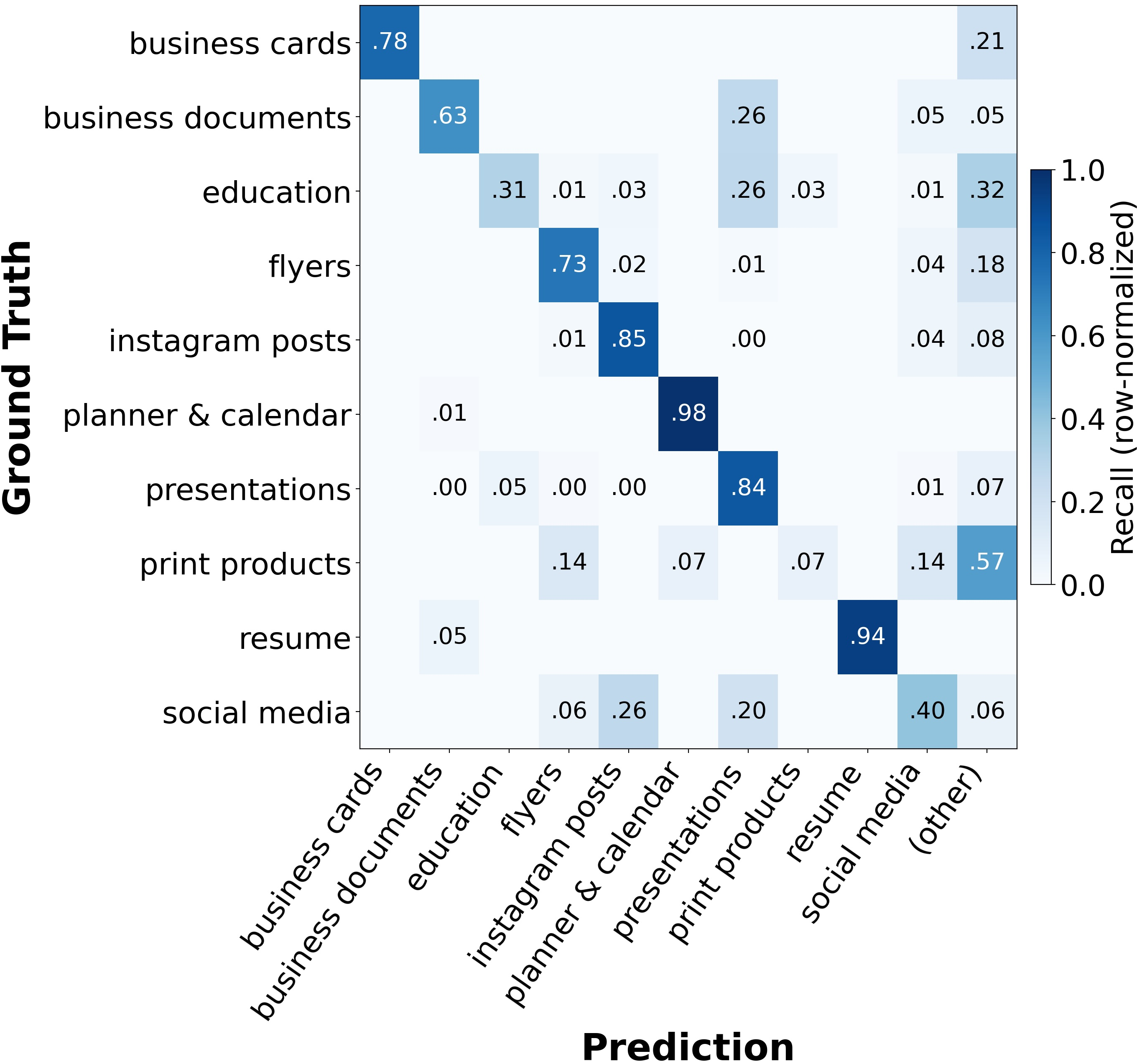
Figure 12: Open-vocabulary classification exposes label aliasing challenges.
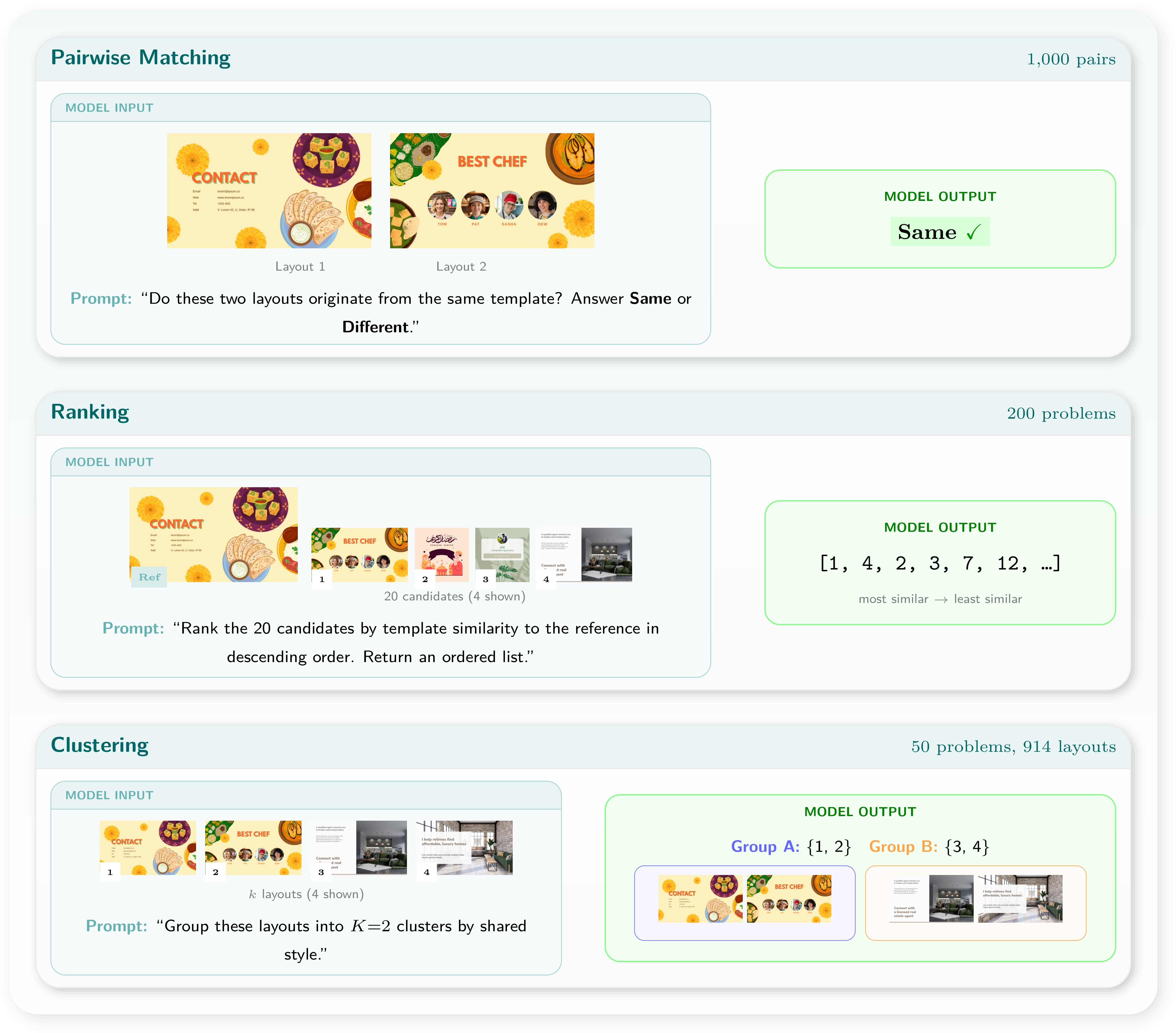
Figure 13: Task structure for template variant understanding—matching, ranking, clustering across groups.

Figure 14: Failure cases where shared palettes or surface content dominate over core structure.
Animation and Video
Temporal tasks (keyframe ordering, motion type classification, interval estimation, specification-grounded animation synthesis) are uniformly in the "unsolved" regime. Models outperform random guessing, but exact matches and per-component accuracy remain weak, especially in multi-element scenes. Even with explicit parameterization and a unique ground-truth association for each component, grounding and motion individuality remain unachievable.
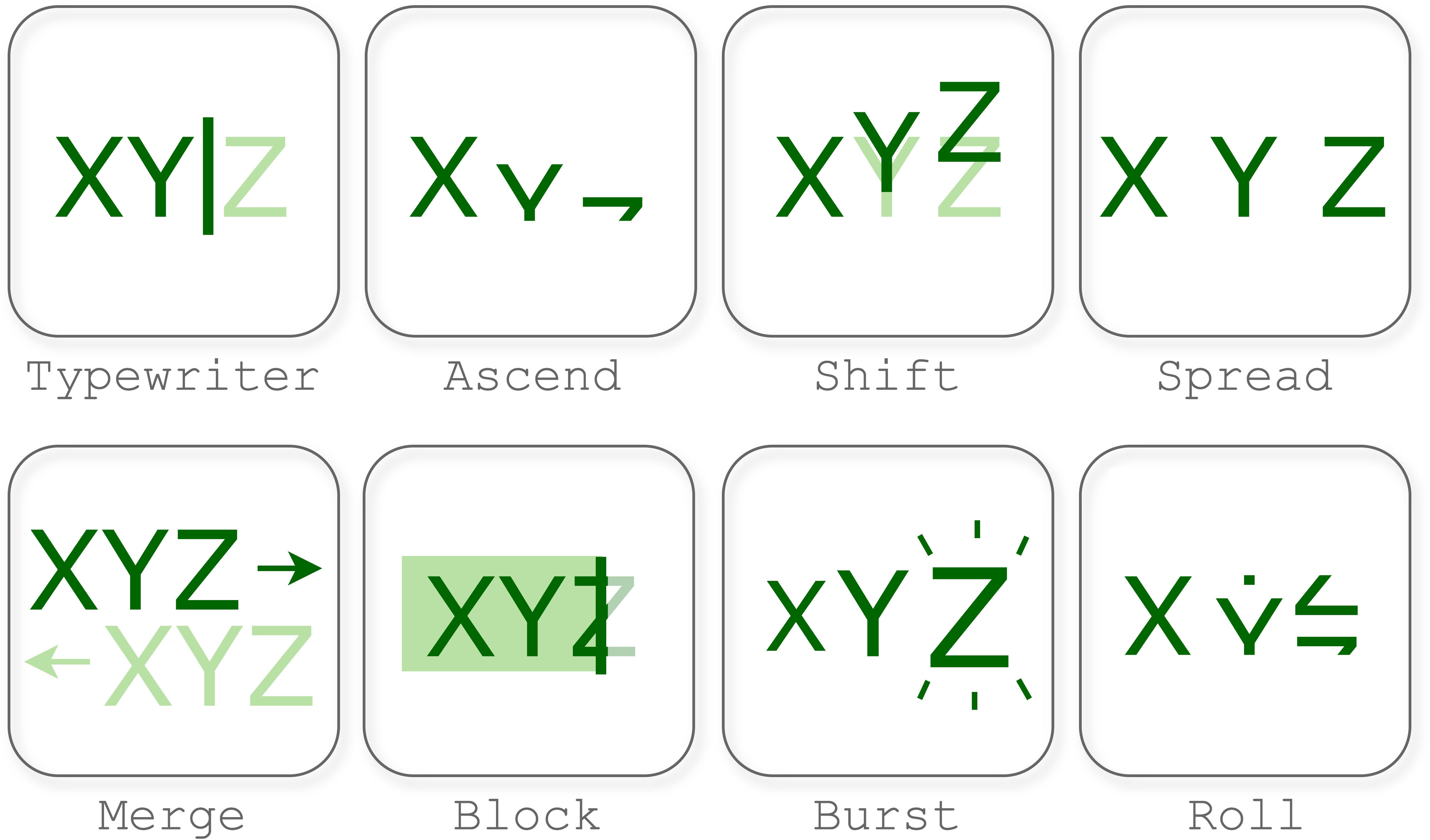
Figure 15: Sample overview of canonical animation motion types.
Implications and Forward Directions
GDB’s results delineate the boundary between current AI capabilities and the precise, context-dependent structure required for design collaboration. The research makes several claims grounded in large-scale empirical analysis:
- Current multimodal LLMs exhibit critical limitations in spatial reasoning, typographic fidelity, structure-aware synthesis, and compositional animation control that are not apparent on standard vision-language or image-generation benchmarks.
- Performance in high-level semantic tasks (template/intent recognition, open-vocab tasks) saturate under label-constrained regimes but do not translate into precise, actionable generation or editing competence.
- Effective, extensible design benchmarks must incorporate structured, domain-aligned metrics rather than solely relying on FID/CLIPScore or pixelwise proxies, and must explicitly report failure under regime shifts (e.g., composition complexity, style diversification, temporal structure).
GDB is constructed as a reproducible, extensible evaluation framework. This structure is designed to facilitate robust assessment across both closed- and open-source models, stimulate the creation of specialized design task training curricula, and prioritize directionality in capability transfer (e.g., advancing from typography understanding to multi-element layout generation). Substantial progress requires design-specialized pre-training, high-fidelity context encoding, hierarchical structural supervision, and richer input/output interface design (structured tokens, functional APIs, etc.).
Conclusion
GDB establishes a comprehensive, multidimensional testbed that rigorously exposes the structural, perceptual, and compositional requirements for AI collaboration in professional graphic design. Only 2 out of 49 tasks are characterized as mostly solved; the majority expose broad, critical capability gaps unobservable in existing image or VQA benchmarks. Future directions must address both modeling (structural pretraining, compositional reasoning architectures) and evaluation (domain-expert human judgment, actionable error taxonomy, open-source baselines) dimensions. Bridging these gaps is essential for reliable, designer-facing AI integration in practical visual communication workflows.

