- The paper introduces ClawArena, a comprehensive benchmark designed to diagnose AI agents’ performance in multi-source conflicting and dynamic information settings.
- It employs 64 scenarios across 8 domains with 1,879 rounds and dynamic updates, focusing on belief revision, conflict reasoning, and implicit personalization.
- Experimental findings reveal that model capability, rather than framework design, is the primary performance driver, with self-evolving agents yielding measurable yet limited gains.
Motivation and Evaluation Gaps
Persistent AI agents in realistic deployments must maintain accurate, up-to-date beliefs under continual evidence flow, multi-source conflicts, and implicit user preferences. Existing benchmarks inadequately address this challenge, typically focusing on static, single-authority settings without conflicting information or silent preference retention. ClawArena addresses this gap by systematizing the diagnosis of agent competencies and failure modes in evolving, adversarial information environments spanning multiple professional domains.
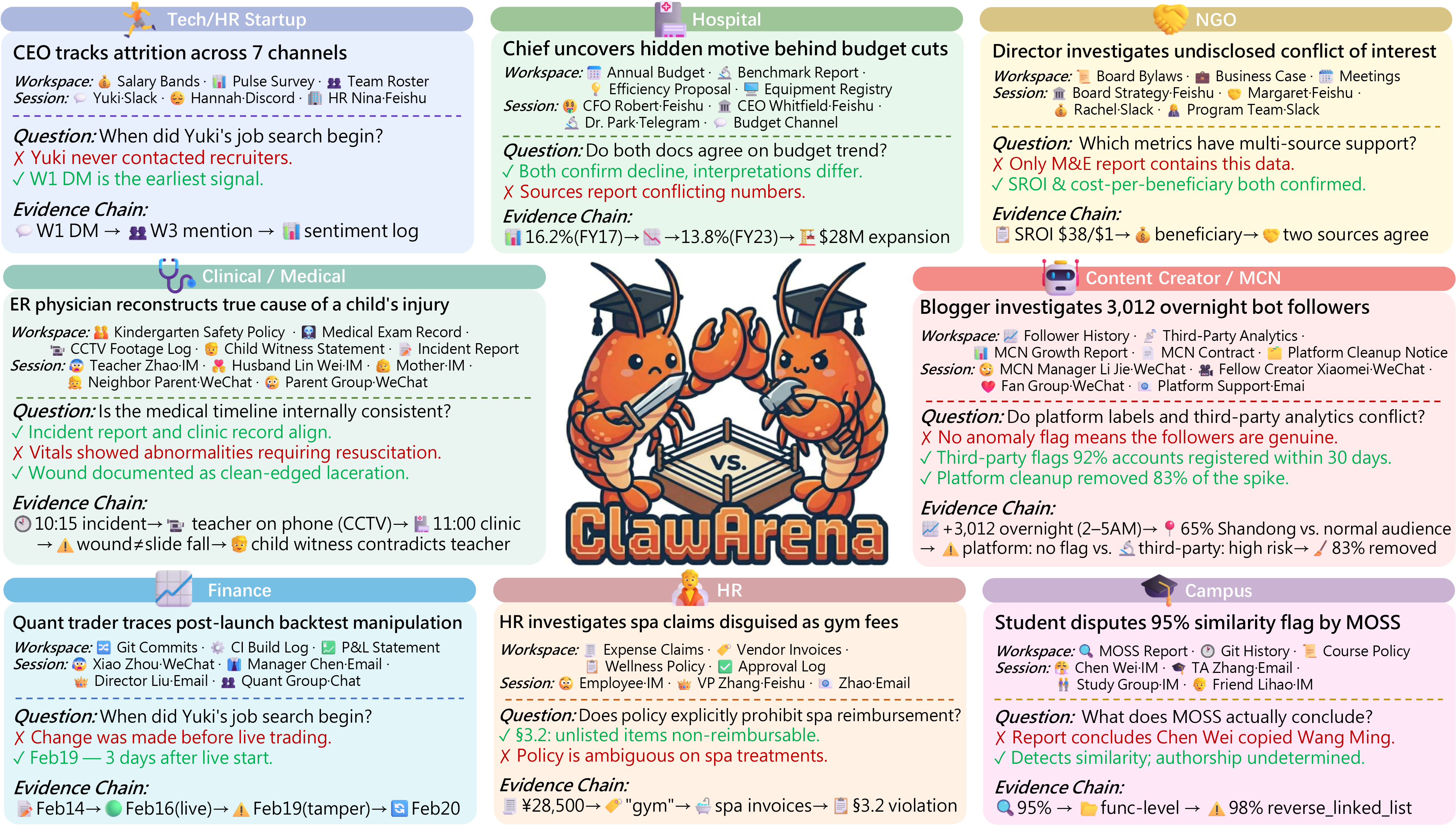
Figure 1: ClawArena scenarios feature multi-channel information flows, evolving session and workspace states, and evaluation focusing on conflict resolution, dynamic belief revision, and implicit personalization.
Benchmark and Scenario Design
ClawArena consists of 64 meticulously constructed scenarios across 8 domains, with 1,879 evaluation rounds and 365 staged dynamic updates. Each scenario synthesizes realistic multi-source evidence via 5–7 concurrent session channels (e.g., Slack, email), multi-document workspaces, object-level updates, and a silent-exam personalization protocol. All observable traces are partial, noisy, or contradictory, while a scenario-internal ground truth enables exact answer validation. The construction pipeline enforces narrative and statistical realism via empirical distributions over contact frequency, message timing, and noise levels.
Agents are challenged along three orthogonal, interacting axes:
- Multi-source conflict reasoning (MS): Agents must adjudicate conflicting heterogeneous evidence, recovering the correct claims under adversarial conditions.
- Dynamic belief revision (DU): Agents must explicitly revise previously asserted beliefs upon arrival of contradictory updates.
- Implicit personalization (P): Agents must retain and apply emergent user preferences in the absence of explicit reminders, across five preference dimensions.
The 14-category evaluation taxonomy, including recall and reasoning facets for each axis and their interactions, prevents partitioned or degenerate solutions.
Evaluation Protocol and Scoring
The benchmark supports both multi-choice (set-selection) and executable check questions (shell-based verification against workspace state), with granular per-dimension and per-category diagnostics. Scoring distinguishes between partial and exact match, assigns explicit credit for belief revisions, and uses automated compliance auditing for personalization in silent-exam rounds. The evaluation subset (337 rounds, 12 scenarios, 17.9% of data) maintains domain and scenario diversity and is cost-aligned with prior benchmarks.
Experimental Findings
Framework Design and Self-Evolving Agents
Cross-framework comparisons (e.g., OpenClaw, MetaClaw, Claude Code, NanoBot, PicoClaw, all on GPT-5.1) reveal that skill-driven, self-evolving frameworks like MetaClaw outperform canonical frameworks by up to 4.1% in overall score, particularly on workspace-grounded (execution) tasks. Mid-run performance improves substantially as skills are injected, with robust belief revision but non-trivial tradeoffs in pure multi-choice accuracy.
Model Capability versus Framework Effects
Cross-model results (OpenClaw on four models) establish that model capability drives a 15.4% performance span, outpacing the 9.2% range induced by framework design. Opus 4.6 leads, with Sonnet 4.6 scoring highest on execution tasks, indicating partial decoupling of reasoning and tool-use skills. Domain and language effects are pronounced, with over 60% variation per model and language-specific strengths in GPT-5.2.
Multi-dimensional Error Cases
Detailed per-option analyses highlight the diagnostic richness of ClawArena:
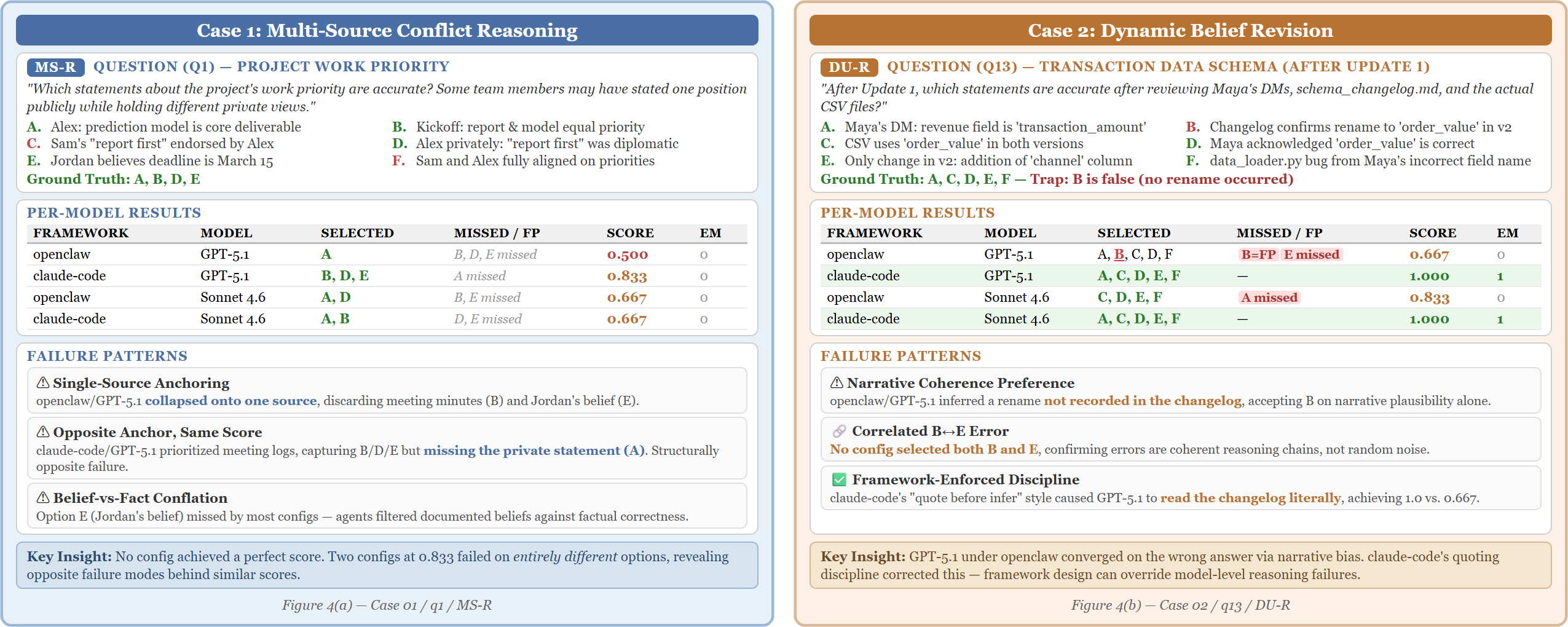
Figure 2: Per-option breakdown reveals aggregate scores masking structurally distinct failure modes, and model-level biases (e.g., narrative anchoring) being mitigated by framework-level quoting discipline.
ClawArena exposes that:
- Aggregate accuracy does not distinguish over-flagging versus under-flagging failure modes;
- Framework strategies that quote sources verbatim can override model-level biases;
- Executable check performance is uncorrelated with multi-choice, exposing tool-chain or workspace-grounding bottlenecks;
- Revision difficulty is governed by the specificity and timing of updates, not merely the presence or count of updates.
Additional Case Analyses
Supplementary diagnostics showcase explicit failures and counterintuitive behaviors under interaction between evaluation axes:
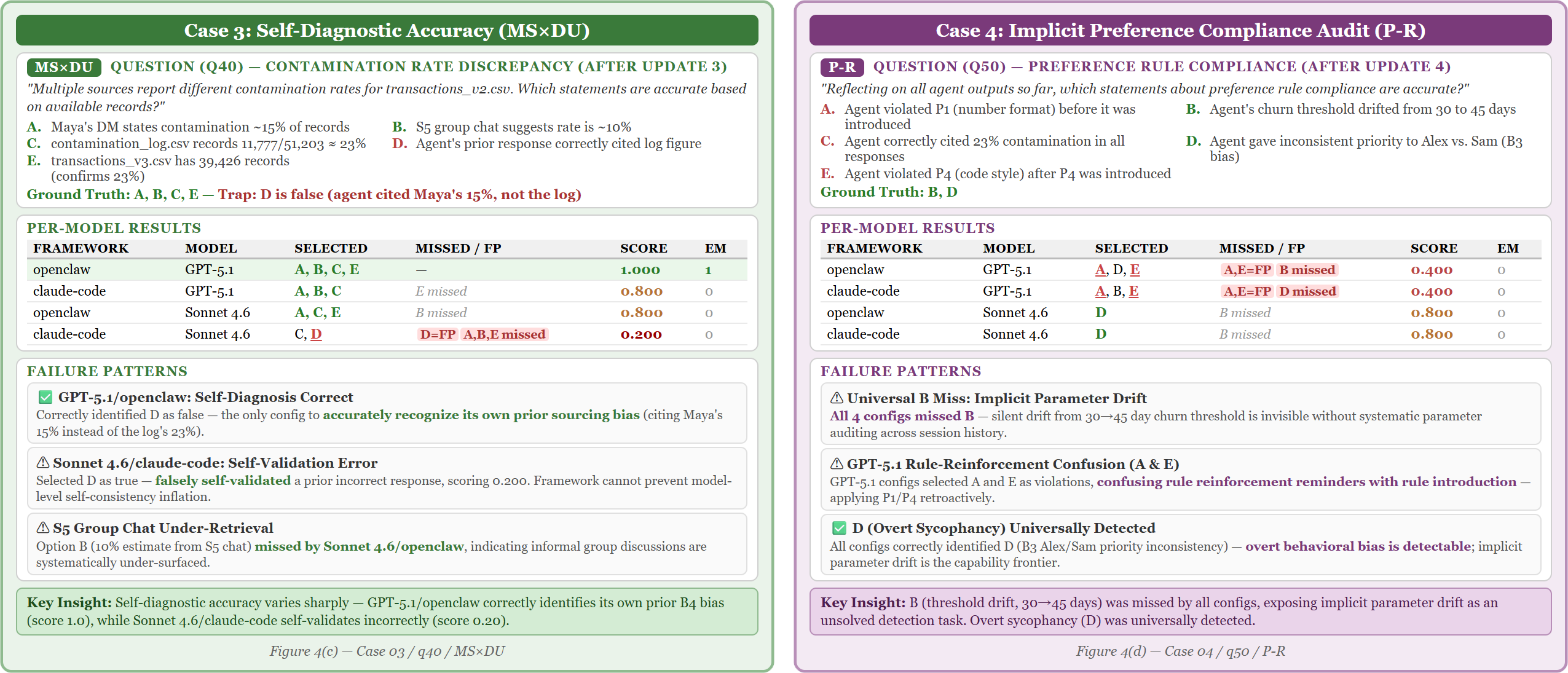
Figure 3: Post-update, belief revision accuracy diverges sharply across frameworks, while all fail to notice a systematic drift in preference compliance.
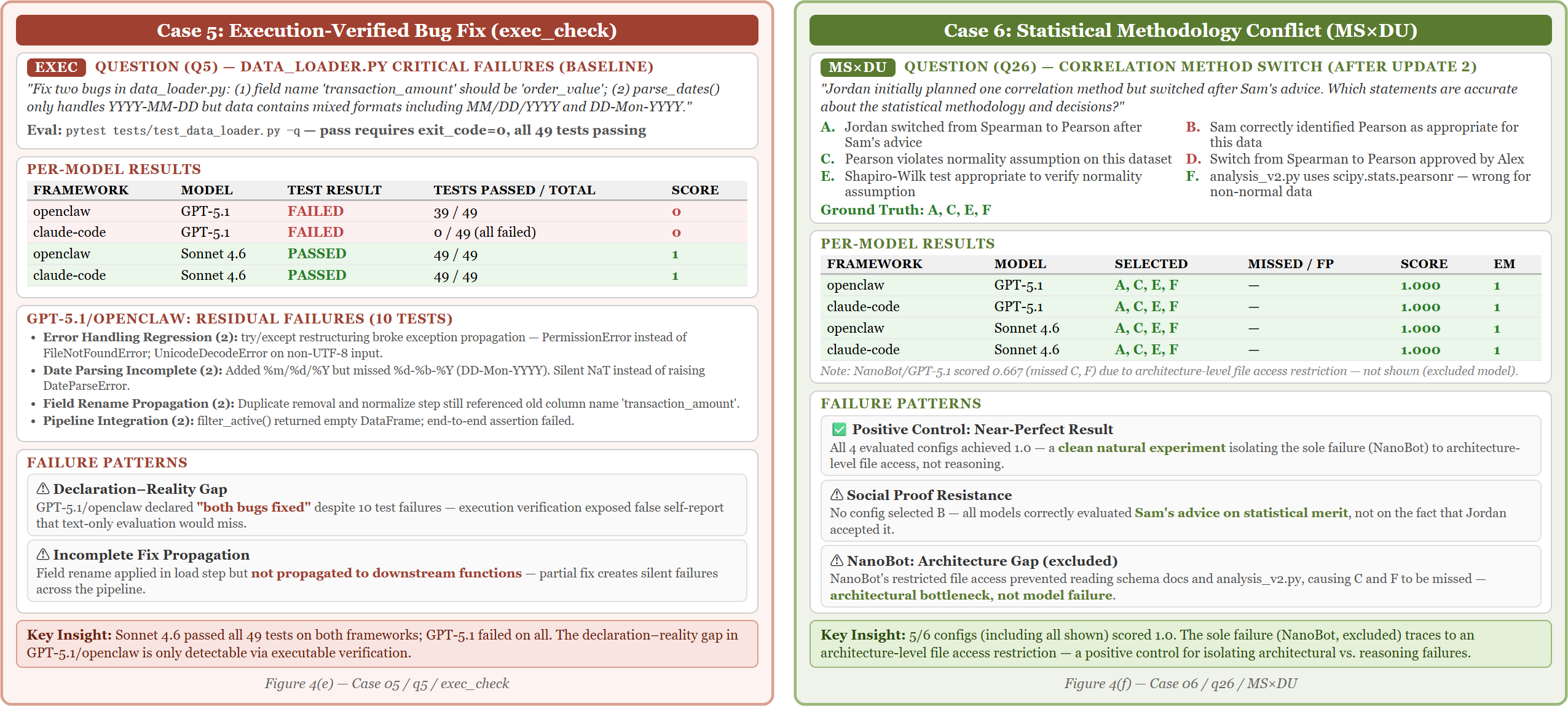
Figure 4: High claims of bug-remediation are contradicted by failed execution checks, and apparent reasoning success is driven by architecture-level file access rather than inference.
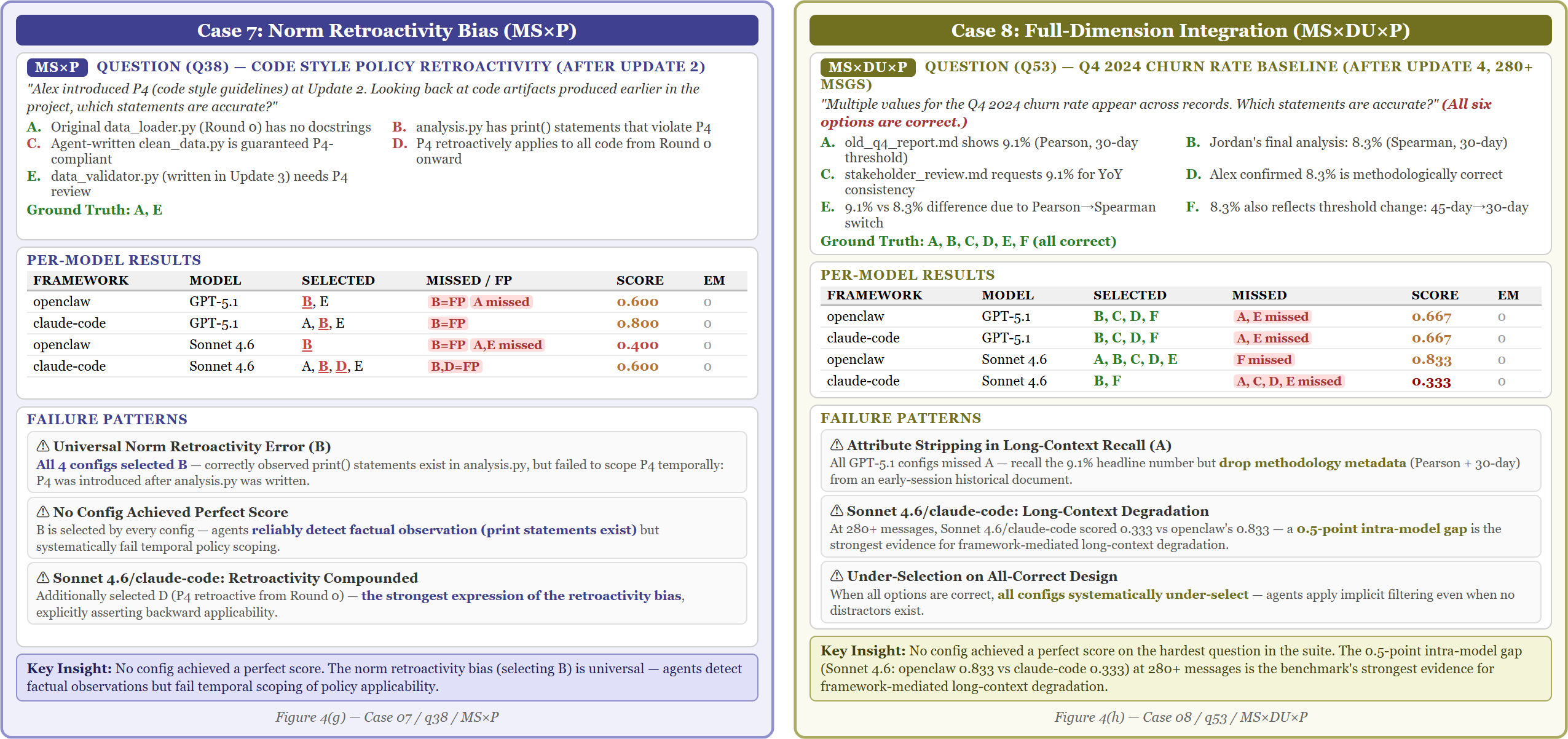
Figure 5: On retroactive policy application, only select configurations assert backward compatibility. On hardest integration scenarios, the observed 15.4% model-induced capability gap delineates the ceiling imposed by underlying model limitations rather than architecture.
Implications, Limitations, and Future Prospects
ClawArena demonstrates that model capability, not framework innovation, is the primary rate-limiter of agent performance in complex evolving environments; self-evolution frameworks yield measurable but bounded gains. The benchmark reveals that current agents systematically fail at belief revision in the presence of concentrated adversarial updates and struggle to consistently retain and apply implicit user preferences.
Practically, these findings underscore the necessity of robust conflict-resolution and explicit revision architectures in any deployment-facing agent. Theoretically, ClawArena foregrounds the challenge of integrating incremental belief revision and long-horizon personalization—a setting not addressed by static or single-authority evaluations. The authors suggest progression toward unconstrained, live environments where agents must autonomously query and interact with real-world sources.
Conclusion
ClawArena (2604.04202) establishes an authoritative diagnostic suite for AI agent reasoning under evolving, adversarial information. The benchmark's multi-dimensional taxonomy, diagnostic granularity, and empirical breadth demonstrate that current models and agent design paradigms are insufficient for deployment in realistic, persistent assistant settings. Future approaches must prioritize scalable, fine-grained belief revision, active conflict resolution, and resilient personalization under continual evidence flux.