- The paper demonstrates that reasoning VLMs lose visual grounding—a phenomenon termed evidence collapse—during extended generation, leading to overconfident predictions.
- It employs detailed attention aggregation and area-under-the-curve metrics to quantify the decay in visual engagement across various model architectures.
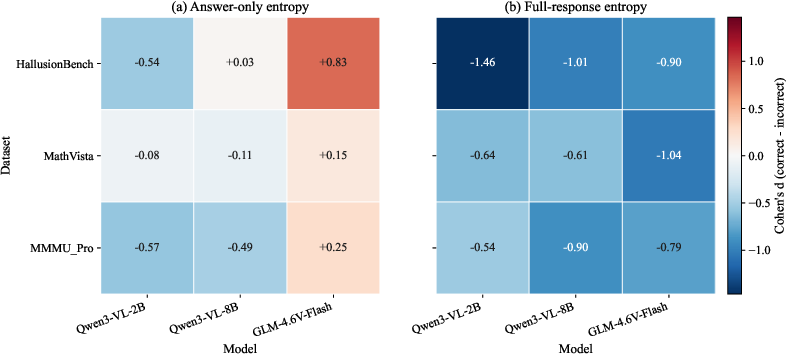
- The findings reveal that text-only uncertainty measures fail to capture visually ungrounded errors, emphasizing the need for task-aware and architecture-specific calibration.
Evidence Collapse in Multimodal Reasoning: A Task-Conditional Failure Mode in Reinforcement-Learned VLMs
Introduction
The paper "Don't Blink: Evidence Collapse during Multimodal Reasoning" (2604.04207) investigates the calibration and failure dynamics of reasoning Vision-LLMs (RVLMs) with an explicit focus on the decay of visual grounding—termed evidence collapse—during the course of extended generation. The authors demonstrate that as RVLMs produce more detailed reasoning traces, they risk becoming overconfident in predictions that have lost grounding in visual evidence, resulting in “confident-but-blind” errors. This failure mode is invisible to text-only monitoring approaches based on predictive entropy, which dominate current multimodal uncertainty quantification protocols.
The central thesis is that the occurrence and risk profile of evidence collapse are not uniform but task-conditional: the implications of visual disengagement differ substantially depending on whether the task demands sustained visual reference or can be solved through early visual extraction and symbolic processing. The paper performs an in-depth empirical and statistical analysis across multiple benchmarks and model architectures, providing insights that have substantial theoretical and operational implications for AI safety, deployment policy, and future RVLM design.
Evidence Collapse: Quantification and Dynamics
The study operationalizes visual grounding by aggregating self-attention weights over visual tokens within bounding-box annotated evidence regions throughout the entire reasoning and answer generation trajectory. The authors systematically evaluate total visual attention mass and evidence-region-specific attention (Abbox) at multiple canonical positions, summarizing with area-under-the-curve metrics (Vthinking_auc) to capture sustained vs. declining visual engagement.
Across all combinations of model and dataset, a universal pattern emerges: both overall and evidence-specific visual attention decay significantly from the start of reasoning to the production of the final answer, defying the expectation that RVLMs maintain attention to critical visual context as reasoning unfolds.
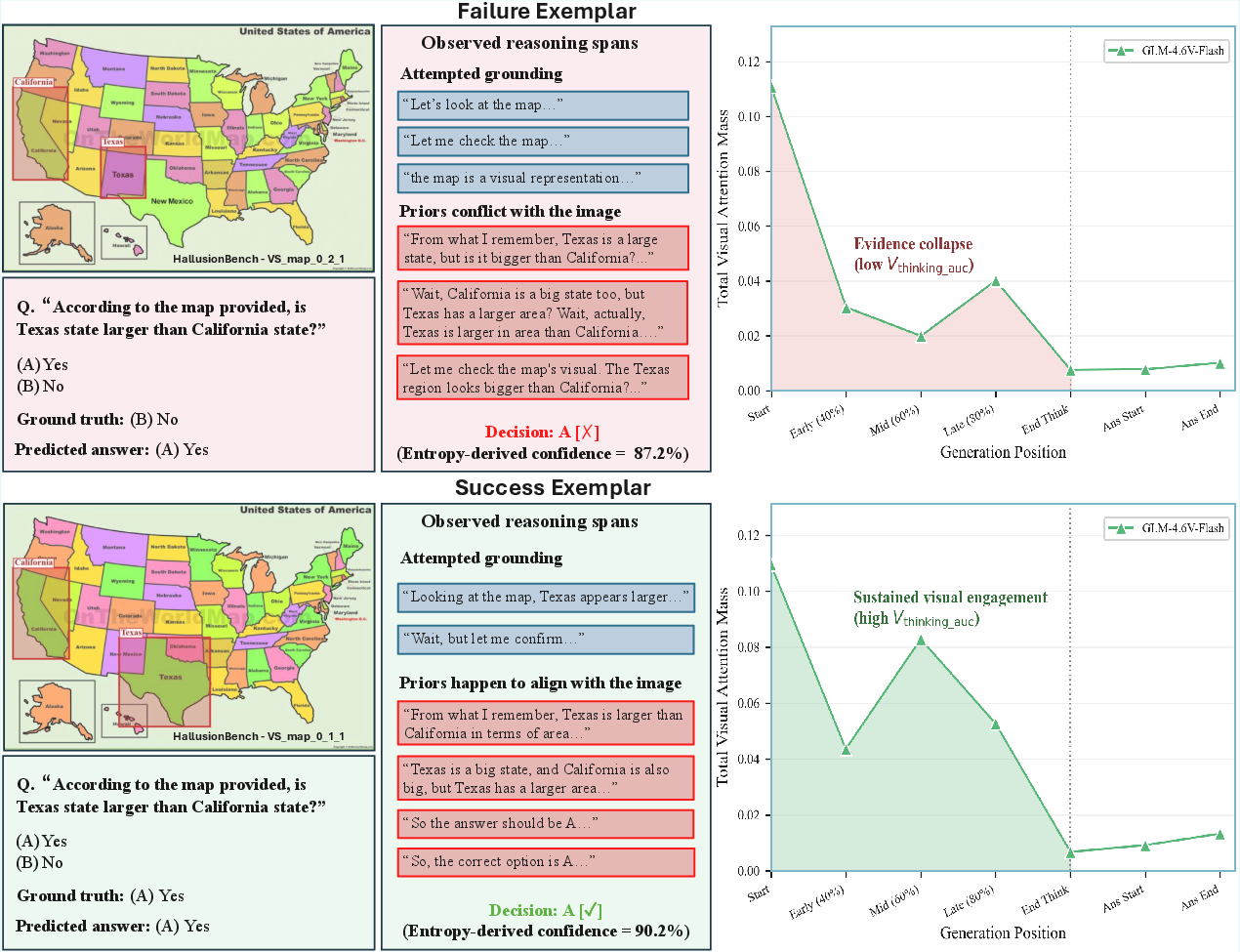
Figure 1: Qualitative contrast of evidence collapse and its downstream error implications: equivalent entropy-derived confidence despite divergent visual engagement trajectories.
The analysis rules out benign redistribution of attention, documenting that absolute evidence-region attention declines in 83--100% of samples, with loss rates often exceeding 50%. Critically, endpoint-only monitoring (e.g., answer-time attention) underestimates collapse frequency; degradation is usually progressive, peaking mid-reasoning.
Architectural Factors in Visual Grounding
Through per-layer AUROC analysis for evidence localization, the authors reveal architecture-dependent loci of visual grounding: Qwen (DeepStack) models achieve peak evidence localization in early layers (0–5), while GLM (single-stream early fusion) models localize evidence in later layers (15–20). This dictates that probing or intervention for visual grounding behavior must be architecture-aware, invalidating heuristic layer-averaging typical in prior interpretability work.
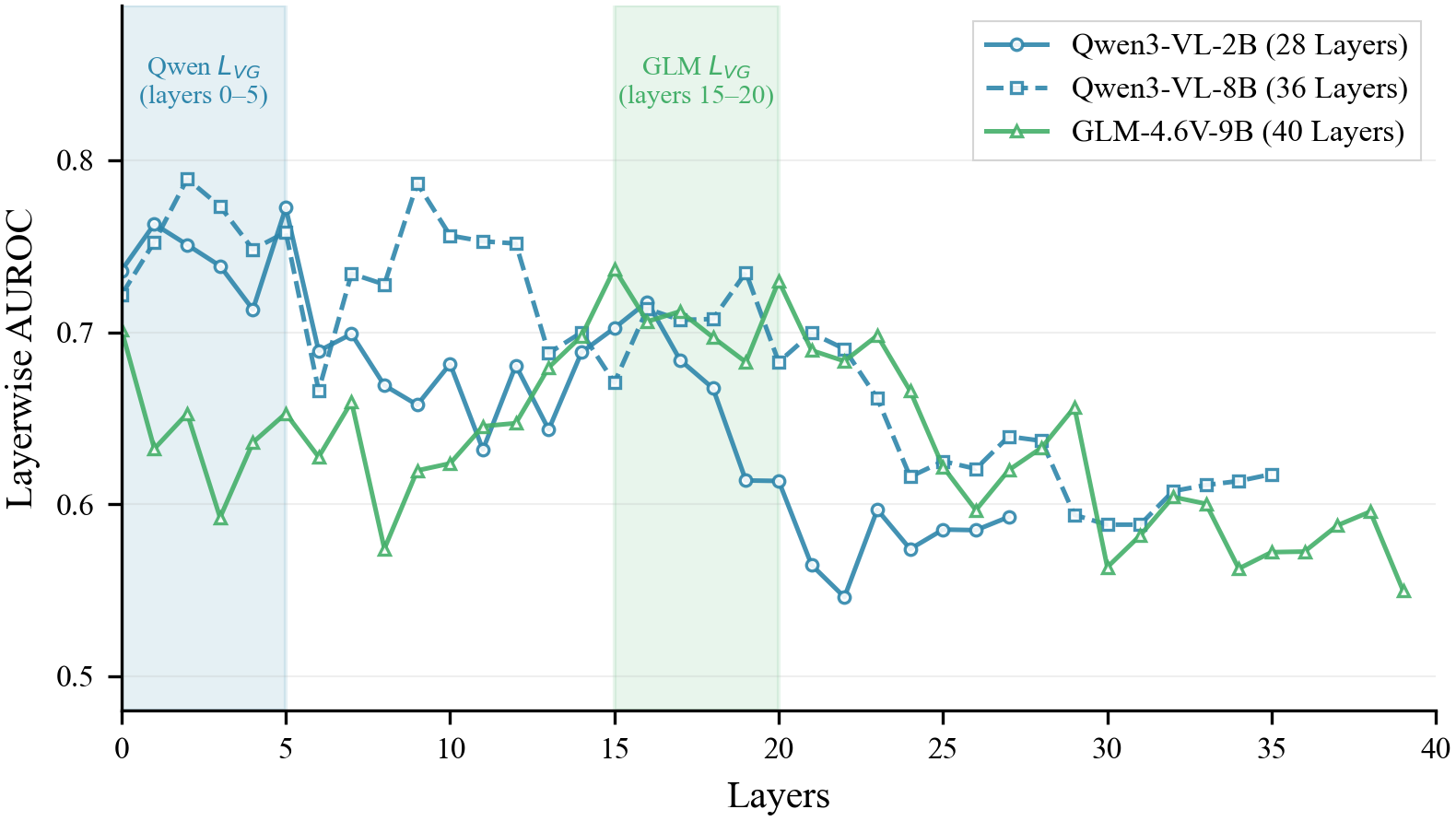
Figure 2: Layerwise AUROC for evidence localization reveals architecture-dependent grounding: early for Qwen, late for GLM.
Calibration and Monitoring: Limitations of Text-Only Entropy
An extensive analysis of standard text-only entropy-based confidence measures demonstrates that:
Task-Conditional Error Regimes and Interaction Models
A principal contribution is the delineation of task-conditional risk regimes through an entropy--vision interaction model. Logistic regression with an interaction term between (z-normalized) entropy and visual engagement reveals that:
- On tasks requiring sustained visual reference (e.g., expert-level STEM, highly entangled visual-symbolic reasoning), confident-but-blind generations incur a significant risk penalty (negative interaction coefficients, up to βEV≈−0.61).
- On tasks amenable to early extraction + symbolic reasoning (math diagrams, unperturbed contexts), the same regime is comparatively benign, and inefficient re-engagement of visual evidence may even be detrimental.
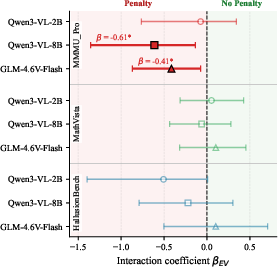
Figure 4: Distribution of interaction coefficients (βEV) across tasks/models: sign flip illustrates task-conditionality of the confident-but-blind penalty.
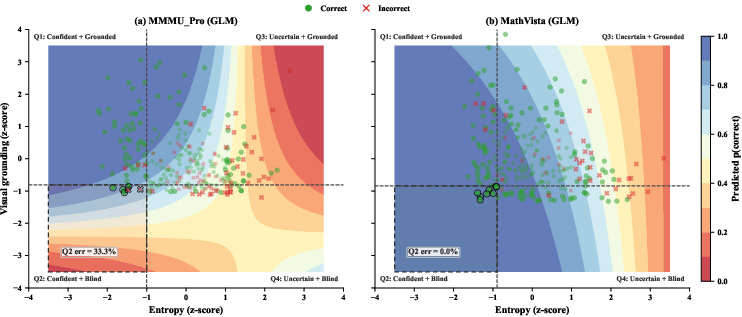
Figure 5: Regime map over entropy and visual engagement for GLM: the Q2 (confident+blind) quadrant is high-risk on MMMU_Pro but benign on MathVista.
Selective Monitoring and Deployment Implications
Attempting to naively linearly fuse vision features and entropy degrades cross-task calibration: global fusion fails because it cannot account for the interaction sign flip between task families. By contrast, a conditional vision veto—which selectively overrides entropy-based acceptance when visual engagement is extremely low—improves selective risk only on tasks with negative βEV, fully aligning empirical outcomes with the task-conditionality signals of the interaction model.
Discussion and Broader Implications
The observed evidence collapse phenomenon implies that extended generated reasoning, while generally beneficial for transparency, can create new avenues for misalignment and overconfidence through progressive loss of grounding. This demands that multimodal uncertainty monitors be:
- Task-aware: automatically or semi-automatically determining whether a given input requires monitoring for sustained visual grounding.
- Architecture-specific: appropriately locating and interpreting grounding layers and attention maps.
- Trajectory-level: capturing sustained rather than endpoint-only grounding, since most failures are gradual.
This study sharply delineates the theoretical boundary of text-only calibration protocols for multimodal models and provides an actionable framework for integrating vision-based monitoring as a conditional augmentation rather than a global supplement.
Limitations and Future Directions
The evaluation is currently circumscribed by:
- Reliance on attention as a correlational proxy for grounding; causal intervention (e.g., activation patching) is required for mechanistic validation.
- Model scale (2B–8B), which may not capture extreme behaviors in frontier LLMs/RVLMs.
- Manual task-typing; production deployment will require robust zero-shot task-type inference to automate selection of appropriate monitoring regimes.
Scaling the empirical protocol to 72B+ models, more diverse architectures, and direct causal testing of grounding (potentially via counterfactual intervention) are critical next steps.
Conclusion
This work rigorously demonstrates that evidence collapse—the loss of visual grounding during extended generation—is a universal but task-conditional phenomenon in contemporary RVLMs. While full-generation entropy offers the strongest universal monitor, it is blind to visually ungrounded confabulation. The error profile associated with confident-but-blind generations flips with task nature, forcing multimodal system designers to adopt task-aware, conditional monitoring policies. The study offers a methodologically robust empirical basis for a paradigm shift in uncertainty quantification and safe deployment of reasoning VLMs.