- The paper introduces DARE, a unified framework that integrates diverse diffusion LLM families with a common post-training and evaluation pipeline.
- It decouples training and rollout optimizations, achieving up to 4x acceleration in RL pipelines and over 14x speedup in block-diffusion models.
- Empirical results reveal trade-offs among RL algorithms, promoting modularity and fair benchmarking across tasks like mathematics, reasoning, and code generation.
DARE: A Unified Framework for Diffusion LLM Post-Training and Evaluation
Motivation and Context
The emergence of diffusion LLMs (dLLMs) has catalyzed substantial research interest due to their parallel generation capabilities and flexible, bidirectional, or block-structured generation regimes. However, progress in dLLM training and evaluation is impeded by fragmented codebases, pipeline divergence between different dLLM families, and incompatibility with established LLM post-training frameworks predicated on autoregressive (AR) next-token prediction. These issues hinder reproducibility, slow experimental iteration, and complicate fair algorithmic comparison.
"DARE: Diffusion LLMs Alignment and Reinforcement Executor" (2604.04215) introduces DARE, an extensible, unified post-training and evaluation stack for dLLMs, addressing this infrastructure gap at both the systems and algorithmic levels.
Architectural Overview
DARE is constructed as a systems layer integrating a broad set of dLLM families with unified training, rollout, and evaluation pipelines. It supports both masked diffusion and block-diffusion generative paradigms, covering models such as LLaDA, Dream, SDAR, LLaDA2.0, and LLaDA2.1. The framework is built atop verl for distributed training and OpenCompass for evaluation, augmented with dLLM-specific modules for actor updates, rollout orchestration, reward modeling, and inference acceleration.
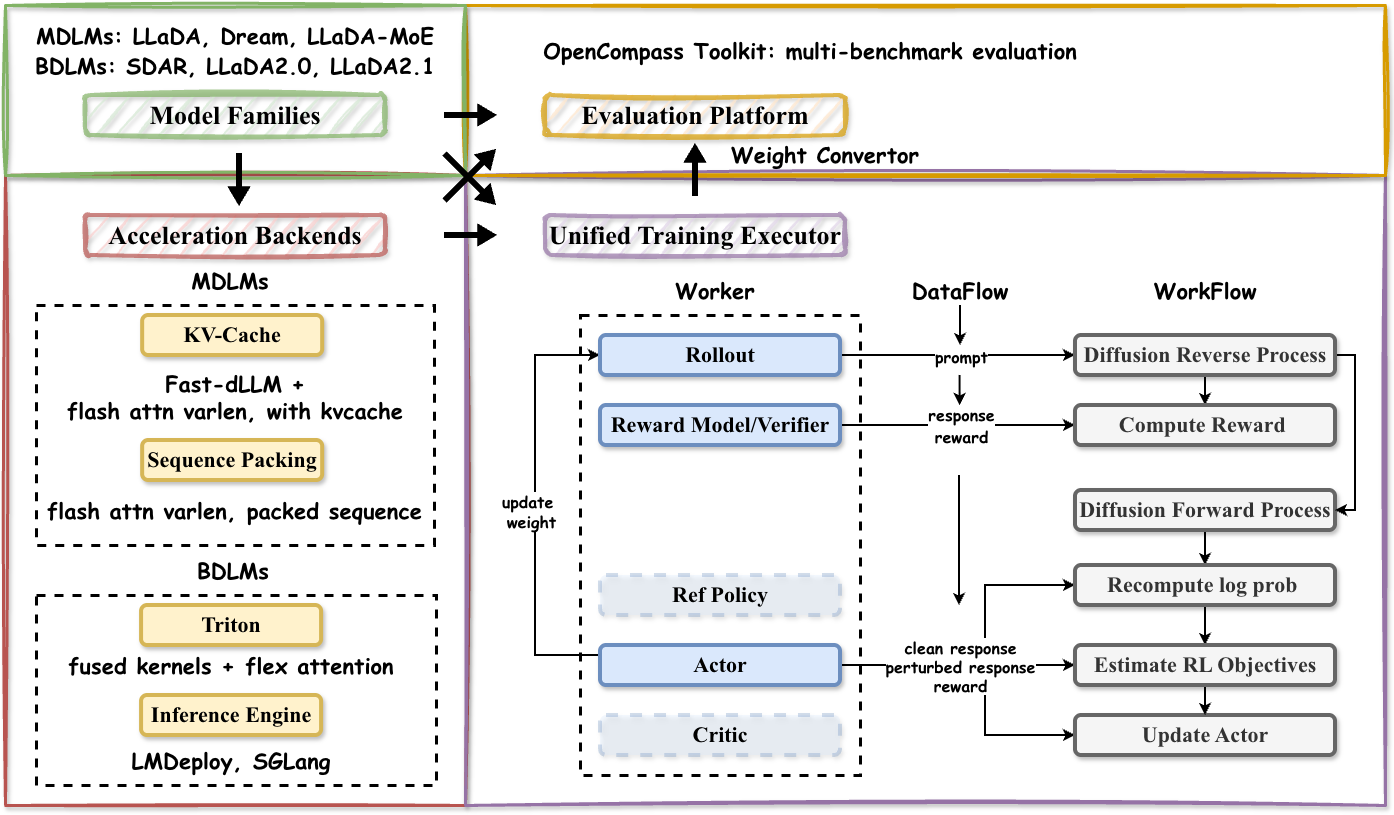
Figure 1: High-level architectural composition of DARE, connecting multiple dLLM families, model-aware acceleration modules, unified post-training execution logic, and the OpenCompass evaluation platform.
The modular design decouples model- and algorithm-specific logic from the shared post-training pipeline, thereby reducing the engineering burden for integrating new dLLM variants and facilitating direct, controlled comparisons of RL and alignment approaches. Workers, dataflows, and workflows abstract the core functional units, allowing diverse algorithms to leverage a consistent outer optimization structure with only limited algorithm-specific hooks for forward corruption, likelihood estimation, or policy loss specification.
Decoupled Systems Optimization
A distinguishing principle of DARE is the treatment of training and rollout as orthogonal acceleration targets. Masked and block dLLMs exhibit highly divergent demands on attention mechanisms, memory layout, and input length handling. DARE optimizes these independently, targeting lowered iteration latency and maximal throughput for both SFT and RL regimes.
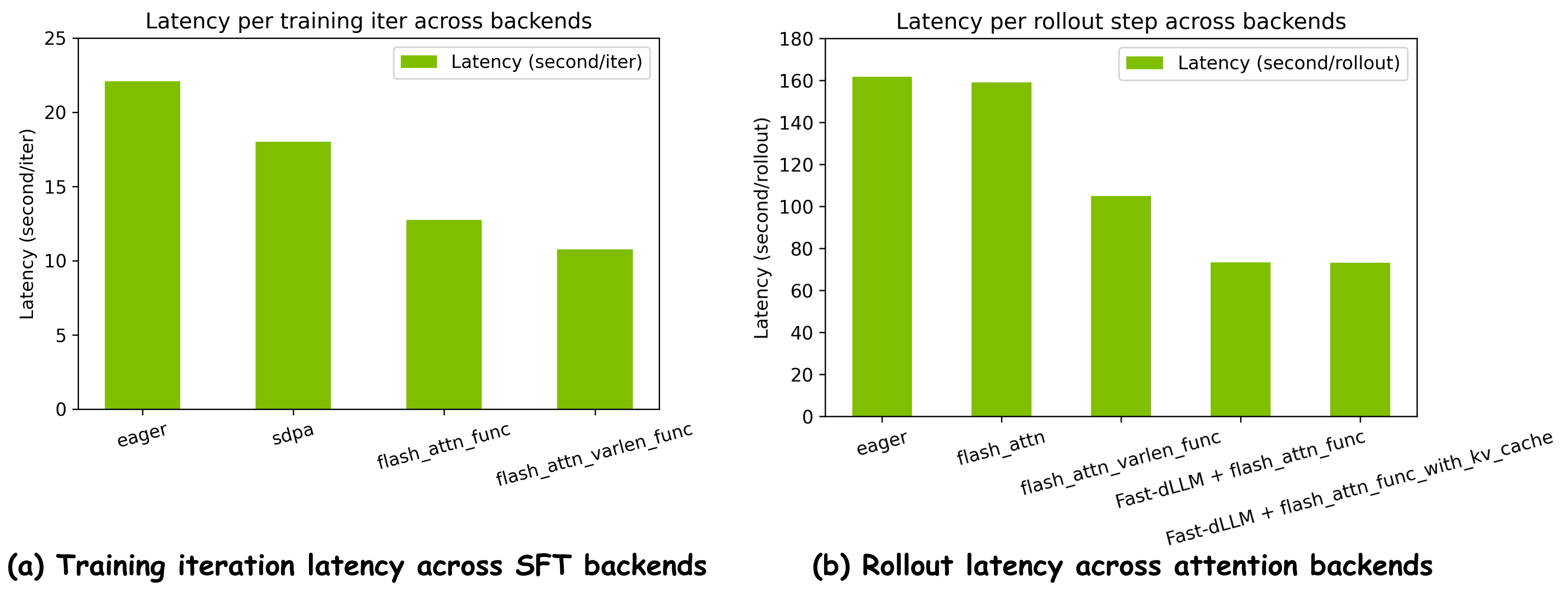
Figure 2: Comparative latency for various attention backends during SFT and rollout on masked diffusion LLMs; Fast-dLLM and FlashAttention integration yield significant speedups by disaggregating optimal backend choices for training versus inference paths.
On the training side, attention kernel selection (e.g., flash_attn_varlen_func for variable-length batches) minimizes padding overhead and reduces SFT latency by up to 2x compared to eager execution. Rollout paths, especially for MDLMs, benefit from decoupled accelerated attention (e.g., Fast-dLLM with KV-cache compatible FlashAttention), resulting in a further 2.2x speedup. End-to-end, this yields up to a 4x combined RL pipeline acceleration for masked paradigms. For block-diffusion models, LMDeploy, SGLang, and block-aware fused operators produce >14x pipeline speedups, essential for competitive iteration on variable-length or semi-autoregressive paths.
Integrated Post-Training Algorithms
DARE integrates a diverse spectrum of post-training objectives—SFT, PEFT, preference optimization, and an array of dLLM-tailored RL methods (VRPO, d1, (Coupled-)GRPO, MDPO, CJ-GRPO, BGPO, SPG, EBPO). Unlike previous approaches with repository-specific, non-portable pipelines, all algorithms are implemented as plug-ins with matched dataflows, rollout strategies, and reward dispatching logic.
Empirical comparisons within DARE reveal no universally dominant post-training algorithm. For instance, in mathematics tasks (GSM8K, MATH), trajectory-level RL methods such as CJ-GRPO and Coupled-GRPO yield best results on LLaDA and Dream backbones, while on code tasks (HumanEval, MBPP), VRPO or Coupled-GRPO can lead, with ELBO-based and MC-surrogate methods demonstrating task-dependent stability and variance.
Empirical Stability and Algorithm Analysis
Figure 3: Representative training curves illustrating convergence stability and reward profiles across different dLLM backbones and RL algorithms in the DARE pipeline.
Training curve analysis in DARE uncovers strong empirical claims: ELBO-based RL algorithms (BGPO, SPG) often exhibit high variance and late-stage collapse when the Monte Carlo sample count for estimator computation is insufficient. By contrast, d1, Coupled-GRPO, and CJ-GRPO deliver more stable convergence, with lower likelihood of abrupt reward degradation. This exposes the practical trade-offs between estimator accuracy, pipeline stability, and computational efficiency that are difficult to observe in fragmented codebases, and highlights that robust dLLM RL requires specialized objective design and sufficient estimator resources.
Benchmark Results and Algorithmic Differentiation
DARE's unified platform enables robust, reproducible comparison across both model families and tasks. Benchmarking covers QA, reasoning, mathematics, and code generation datasets, with optimal algorithm/model settings on each. Strong numerical results include:
- LLaDA2.1-mini achieving 84.56 on MATH, 81.10 on HumanEval, and 26.67 on AIME24, demonstrating the competitiveness of large-scale block-diffusion architectures.
- SDAR-30B-A3B reaching 92.81 on HellaSwag and 92.49 on GSM8K.
- LLaDA-8B-Instruct and Dream-7B-Instruct displaying high code generation accuracy (with VRPO and Coupled-GRPO baselines), but exhibiting task-dependent ranking shifts under RL algorithm variations.
There is an explicit emphasis in the paper that no single RL or alignment algorithm provides state-of-the-art gains across all tasks or model families; DARE exposes these mismatches, preventing misleading conclusions enabled by non-unified, paper-specific experimental setups.
Theoretical and Practical Implications
DARE establishes a new template for research infrastructure in the dLLM domain. The system's modularity and extensibility reduce redundant engineering work and accelerate the lifecycle from algorithmic proposal to benchmarked results. The empirical analysis, especially around ELBO estimator instability and RL pipeline decoupling, suggests multiple avenues for advancing dLLM post-training—specifically in estimator innovation, robust and sample-efficient policy optimization, and scalable inference backends. DARE's open and unified evaluation approach facilitates generalization assessment and underpins fair ablations for future methods. As diffusion-based models expand into vision, multimodality, or more complex semi-autoregressive tasks, DARE's design principles are likely to be further validated and adopted.
Conclusion
DARE provides a unified, extensible executor and evaluation framework for diffusion LLM post-training and alignment, spanning both masked and block-diffusion families, a heterogeneous portfolio of RL and SFT algorithms, and acceleration backends tailored for the unique requirements of dLLMs. The framework brings clarity and control to empirical evaluation, demonstrates robust speedups via decoupled systems optimization, and reveals key stability-efficiency trade-offs in current RL algorithm design. DARE positions itself as a sustainable substrate for rapid method innovation and fair benchmarking throughout the growing dLLM research landscape.