- The paper demonstrates that E-VLA integrates asynchronous event signals with RGB imagery to overcome severe low-light and motion blur challenges.
- It introduces two effective fusion strategies—overlay fusion and hierarchical adapter—achieving up to 90% success in manipulation tasks where image-only methods fail.
- The study provides a synchronized RGB-event dataset and establishes a scalable framework for robust robotic manipulation in adverse perceptual environments.
E-VLA: Event-Augmented Vision-Language-Action Model for Robust Robotic Manipulation
Introduction and Motivation
Vision-Language-Action (VLA) models have shown considerable success in vision-conditioned manipulation tasks by leveraging pretrained visual encoders and LLMs. However, robustness degradation under low-light, motion blur, and black clipping conditions exposes a fundamental limitation of frame-based image sensing—information loss at the capture stage is not recoverable through downstream image enhancement or data augmentations. The work "E-VLA: Event-Augmented Vision-Language-Action Model for Dark and Blurred Scenes" (2604.04834) introduces a scalable event-augmented VLA framework, E-VLA, that systematically integrates asynchronous, high-dynamic-range visual signals provided by event cameras into state-of-the-art language-conditioned manipulation pipelines. The E-VLA system demonstrates strong improvements in task success rates under severe visual degradations where image-only VLA systems predictably fail.
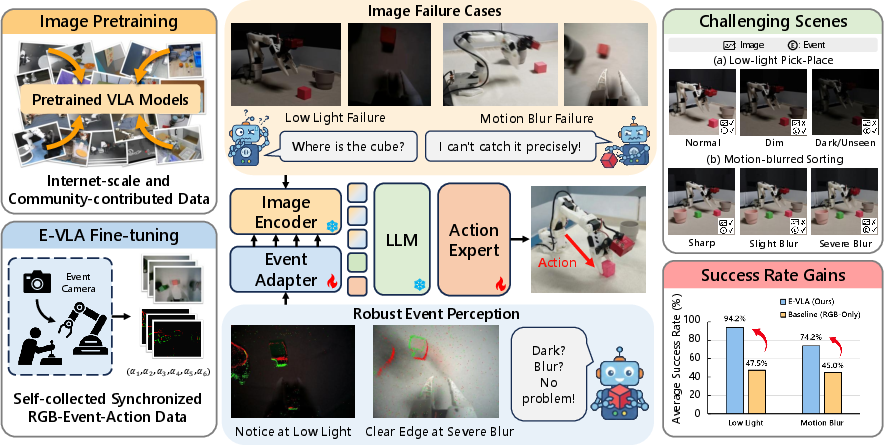
Figure 1: Event cues stably augment VLA models to preserve performance under low-light and motion-blurred conditions, superseding the collapse observed in image-based models; the E-VLA setup, data collection, and evaluation is depicted.
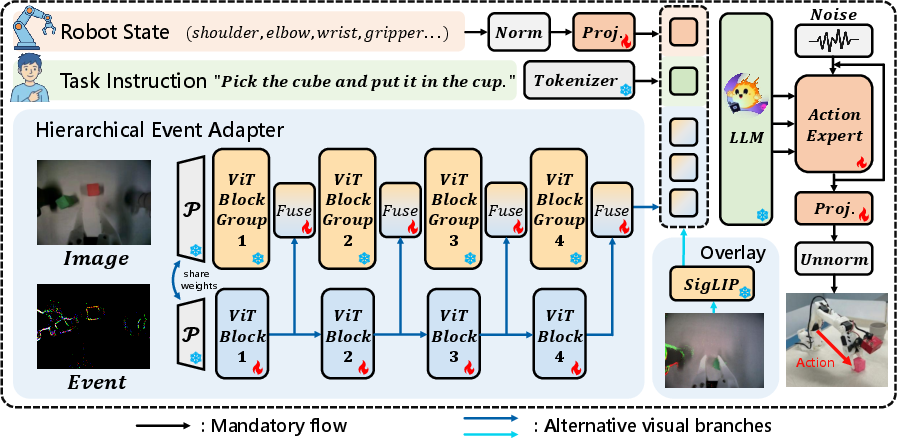
E-VLA Architecture
E-VLA establishes a systematic framework for fusing event stream cues with classical RGB imagery and language inputs. The platform is based on SmolVLA, using an efficient ViT-style visual encoder (SigLIP) and a transformer-based action expert, augmented with two event fusion variants:
Recognizing the lack of event-augmented embodied datasets, the authors construct a synchronized RGB-event-action dataset using a LeRobot SO100 manipulator with a wrist-mounted DAVIS346 event camera. The platform is calibrated for precise spatiotemporal alignment of event streams and images. Data is collected across representative manipulation tasks (Pick-Place, Sorting, Stacking) under controlled illuminations (200 to 20 lux, normal to extremely low-light) and varying exposure times to elicit motion blur.

Figure 3: Visualization of the E-VLA dataset; event maps augment RGB frames, and dataset statistics show event rate stability under severe illumination collapse.
Methodological Insights
Event windowing is identified as a crucial design axis. The authors show that "recent-N events" (fixed-count) windows yield more temporally stable representations than fixed-duration windows, especially under highly non-stationary arm speed/rate regimes of real manipulation. Accumulated polarity-agnostic event counts, when demosaiced to RGB format, exploit the expected input distribution of the pretrained SigLIP backbone.
In ablation, aggressive image dropout regularization during event-adapter training optimizes robustness by forcing reliance on event cues, but excessive regularization can hinder performance in well-lit conditions due to failure to retain color discrimination capacities.
Empirical Results
The robustness of E-VLA is exhaustively benchmarked against image-only baselines and popular enhancement pipelines (RetinexNet, Retinexformer, EvLight), as well as reconstruction-based event image methods (E2VID).
Key findings:
- At 20 lux (practically black RGB frames), image-only achieves 0% pick-place task success; overlay fusion achieves 60% and the event adapter 90%.
- Under severe motion blur (1000ms exposure), image-only collapses (Pick-Place: 0%), but overlay and adapter variants achieve 20–25% and up to 32.5% (Sorting).
- The hierarchical adapter outperforms overlay fusion by 10–30% across illuminations <40 lux.
- Out-of-distribution generalization to unseen low-light conditions is markedly superior for the event-adapted VLA, with the event branch retaining 45% success at 20 lux vs. 0% for image-only.
- Event representations using accumulated count-based frames yield the highest robustness; voxel grid and time surface baselines perform significantly worse.

Figure 4: Qualitative comparison of visual inputs under illumination collapse—frame-based perception fails, while event representations preserve scene structure and actionable cues.

Figure 5: Grayscale distribution analysis confirms practical black clipping at low lux; events remain information-rich.

Figure 6: Visualizations of E-VLA performance under severe motion blur—event frames maintain geometric structure lost to image blur.
Limitations
E-VLA's strong resilience is not without task-specific bottlenecks. In color-dependent tasks (Sorting), the absence of intensity information in event frames limits correct color classification post-grasp, as event signals are derived from changes, not static appearances. Monocular, wrist-mounted setups are vulnerable to occlusions during stacking, which cannot be compensated by event-based cues alone.
Practical and Theoretical Implications
E-VLA substantiates that event-based sensing can be scalably and efficiently integrated into VLA manipulation models with negligible computational overhead and without violating pretrained distributional assumptions. This paradigm shift extends VLA robustness into the sub-niche of persistent perceptual degradations, critical for edge-deployed embodied agents in unstructured environments. The architecture is inherently compatible with any ViT-based VLA model family, facilitating plug-and-play adoption.
Practical deployments in warehouses, autonomous labs, or planetary robotics can directly benefit where illumination or motion speed is not controllable. Theoretical implications include robustifying perception-action loops by assimilating asynchronous, high-dynamic-range signals, prompting reconsideration of event domain pretraining and transfer learning strategies.
Future Research Directions
Potential advances include:
- Event-based demosaicing and colorization methods to mitigate the current event-insensitivity to chromatic semantics.
- Multi-view or actively modulated sensor placements to overcome viewpoint occlusion.
- Larger, more diverse event-augmented datasets enabling contrastive, multi-task event-LM pretraining.
- The exploration of time-adaptive fusion and event-triggered perception-action coupling.
Conclusion
E-VLA presents a practical and efficient blueprint for integrating neuromorphic event cues into the vision-language-action paradigm, yielding large gains in manipulation robustness under challenging perceptual conditions while maintaining strong computational efficiency and pretrained model compatibility. This establishes a new direction for scalable, robust embodied intelligence anchored in event-based perception (2604.04834).