- The paper demonstrates that a 4B parameter model can be post-trained via supervised fine-tuning and rubric-based reinforcement learning to rival much larger models in Olympiad-level theorem proving.
- It employs an iterative reasoning cache and test-time scaffolds to refine proofs, significantly enhancing stability and convergence over extensive context windows.
- Empirical results reveal competitive performance against models with 30B to 235B parameters, challenging the notion that only massive LLMs can tackle complex mathematical proofs.
Training Small LLMs for Olympiad-Level Theorem Proving: The QED-Nano Approach
Motivation and Context
The ability of large-scale LLMs to solve complex mathematical proof problems at International Mathematical Olympiad (IMO) gold level has been demonstrated by several proprietary systems. However, these improvements have been opaque, relying on vast “internal” models, costly post-processing, and undisclosed data and reward mechanisms, leaving the open-source community with serious reproducibility and scalability challenges. This paper directly addresses the question: can small, reproducible, open-weight models be pushed, via post-training, to solve nontrivial Olympiad-level proof problems competitively with much larger closed or open models? QED-Nano provides an explicit recipe for achieving this with a 4B parameter model.
Data Curation and Rubric Construction
Central to effective post-training is the creation of high-quality datasets and fine-grained grading incentives, since Olympiad-level proof-writing stresses long-form, globally coherent reasoning. The QED-Nano pipeline begins with extensive curation from high-noise, large-scope community and competition data (AI-MO/aops, AI-MO/olympiads), incorporating automated filtering and human-in-the-loop annotation, explicitly removing trivial and contaminated items. Rubric grading, adapted from [ma2025reliable], gives each problem a detailed, multi-point scheme covering checkpoints, zero-credit items, and deduction heuristics, crucial for inducing non-binary, process-level reward signals for RL.
Multi-Stage Post-Training Recipe
Supervised Fine-Tuning (SFT)
The pipeline first conducts SFT on a curated corpus of Olympiad proofs paired with DeepSeek-Math-V2 completions. This step bestows the model with basic structural proof-writing capacities, exploiting high-quality reasoning traces from a much larger, highly specialized teacher model. The SFT-generated checkpoint, however, tends to overfit on verbosity, frequently yielding length-exploding outputs and spurious long-form completion patterns, which must be subsequently corrected.
Rubric-Based Reinforcement Learning
The core of QED-Nano’s improvement comes from long-context RL using the GRPO algorithm [shao2024deepseekmath] and rubric-based reward functions, with rewards generated from a tuned LLM-judge. The reward protocol is finely optimized for latency and fidelity; using GPT-OSS-20B achieves near-maximal annotator-alignment, making RL feasible at required scales. RL is conducted at extensive context windows (up to 50,000 tokens per response), with parallel rollouts (n=16), ensuring effective exploration and sample efficiency.
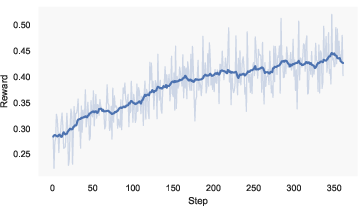
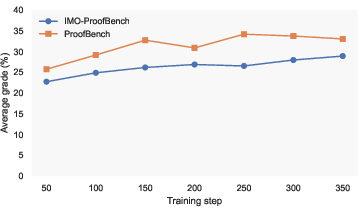
Figure 1: RL training curves with rubric-based rewards (left) and evaluation metrics on Olympiad-level proof benchmarks (right), highlighting rapid improvement and stability.
Iterative RL with Reasoning Cache (RC)
To genuinely benefit from extended test-time compute budgets, QED-Nano incorporates Reasoning Cache (RC) [wu2026reasoningcache]. Instead of simply increasing output length, RC decomposes the proof task into iterative summarize-and-refine cycles, letting the model continually improve and adapt across multiple refinement turns. RL then trains the system to optimize progress over these iterative cycles, significantly increasing stability, convergence speed, and horizon scaling (see performance curves in Figure 1).
Scaffold Integration at Test-Time
Crucially, the final QED-Nano architecture is compatible with a range of inference-time scaffolds, notably RSA [rsa] and variants of DeepSeekMath-style verification pipelines. When these scaffolds are paired with the RL-trained model, the system achieves dramatic improvements by leveraging massive sampling and sequential reasoning passes (token counts in the millions), without architectural changes.
Empirical Results and Claims
QED-Nano demonstrates highly competitive performance. Without scaffolds, it attains 40% on IMO-ProofBench, 45% on ProofBench, and 68% on IMO-AnswerBench in single-turn mode—surpassing every known 4B open model, including those like Nomos-1 (30B) and Qwen3-235B (235B). When executing with RSA scaffold (2M tokens/problem), QED-Nano (Agent) achieves 57% on IMO-ProofBench and 63% on ProofBench, approaching proprietary Gemini 3 Pro and DeepSeek-Math-V2 (685B) at a small fraction of compute and inference cost.
These results provide a clear contradiction to received wisdom that only extremely large, opaque models can compete at the highest levels on open-ended, proof-based reasoning benchmarks. Furthermore, the gains scale with test-time compute and hold across different scaffolding methods, illustrating that the RL-trained policy reliably generalizes to various inference protocols.
Qualitative and Safety Analysis
Manual review of QED-Nano outputs reveals explicit, structured, and rigorously detailed mathematical arguments, with a notable lack of “reward hacking” or adversarial grader exploitation. RL with rubric feedback, rather than answer-only supervision, yields proofs more aligned with human expectations. Notably, while QED-Nano’s default style prefers computation-heavy arguments (especially in geometry), the iterative scaffold primarily corrects fixable but non-trivial logical gaps rather than shifting reasoning styles or compromising rigor.
Implications and Future Directions
Practical Impact: QED-Nano opens a tractable and reproducible path for the mathematical LLM community to achieve near-frontier-level performances without the cost or opacity of massive proprietary systems. The recipe is modular and extensible, generalizing to any reasoning domain with rubric-based reward structures.
Theoretical Insights: This work demonstrates that RL atop small models, when paired with dense, structured reward signals and iterative test-time scaffolds, can reliably scale to tasks far beyond those seen during pretraining. The success of RC and scaffold-based RL may inform the design of future LLM reasoning stacks beyond math, in any domain requiring flexible, adaptive, high-fidelity reasoning over long horizons.
Open Challenges: The primary bottleneck is now the synergy between SFT and RL, specifically controlling for SFT-induced length pathologies and further improving RL’s credit assignment via dynamic curriculum, improved reward shaping, or hybrid oracle planning. There are also open problems in synthesizing models that can perform structural, creative “aha” insights as opposed to computation-heavy exhaustive searches.
Conclusion
QED-Nano provides compelling evidence that small, reproducible, open-source LLMs can approach the reasoning/reproving quality of much larger, closed models when post-trained with sheeted SFT, rubric-shaped RL, and iterative reasoning scaffolds. This overturns assumptions about model size versus reasoning capability and suggests a new tractable regime for high-stakes, cost-sensitive, rigorous mathematical and scientific AI development.
(2604.04898)

