- The paper presents two explicit uncertainty interfaces—a global verbal confidence score and a local <uncertain> token emission—to directly quantify model uncertainty.
- It employs calibration-aware reinforcement learning to sharply reduce overconfident errors while modestly improving overall accuracy.
- Mechanistic analysis reveals that while the global interface refines output confidence without altering core computations, the local interface triggers actionable intervention points during reasoning.
Explicit Interfaces for Uncertainty Expression in LLMs
Deployment of LLMs in applications requiring fine-grained control necessitates actionable and explicit uncertainty quantification. Traditional approaches typically treat uncertainty as a post-hoc latent variable, inferred after completion of generation, decoupled from the model's causal outputs. Such paradigms are fundamentally limited: downstream systems (e.g., abstention, retrieval, or verification modules) are forced to rely on heuristic, often unreliable, extractions of uncertainty from surface features, logit entropy, or external calibration statistics. The lack of legible and explicit model-side uncertainty impedes optimal downstream decision-making and makes failures difficult to diagnose and intercept.
"LLMs Should Express Uncertainty Explicitly" (2604.05306) reconceptualizes model uncertainty not as an after-the-fact diagnostic but as a design choice in interface construction. The paper's central innovation is the operationalization and experimental comparison of two explicit uncertainty interfaces:
- Global verbal confidence, in which the LLM generates a scalar, calibrated measure of final-answer reliability at the end of its output;
- Local process-level signaling, via a special <uncertain> token emitted during reasoning to indicate high-risk, epistemically fragile states.
By dissecting the effects and mechanisms of these interfaces, the authors establish that actionable, legible uncertainty is a multi-scale construct, best realized through explicit, trainable outputs rather than indirect statistical estimators.
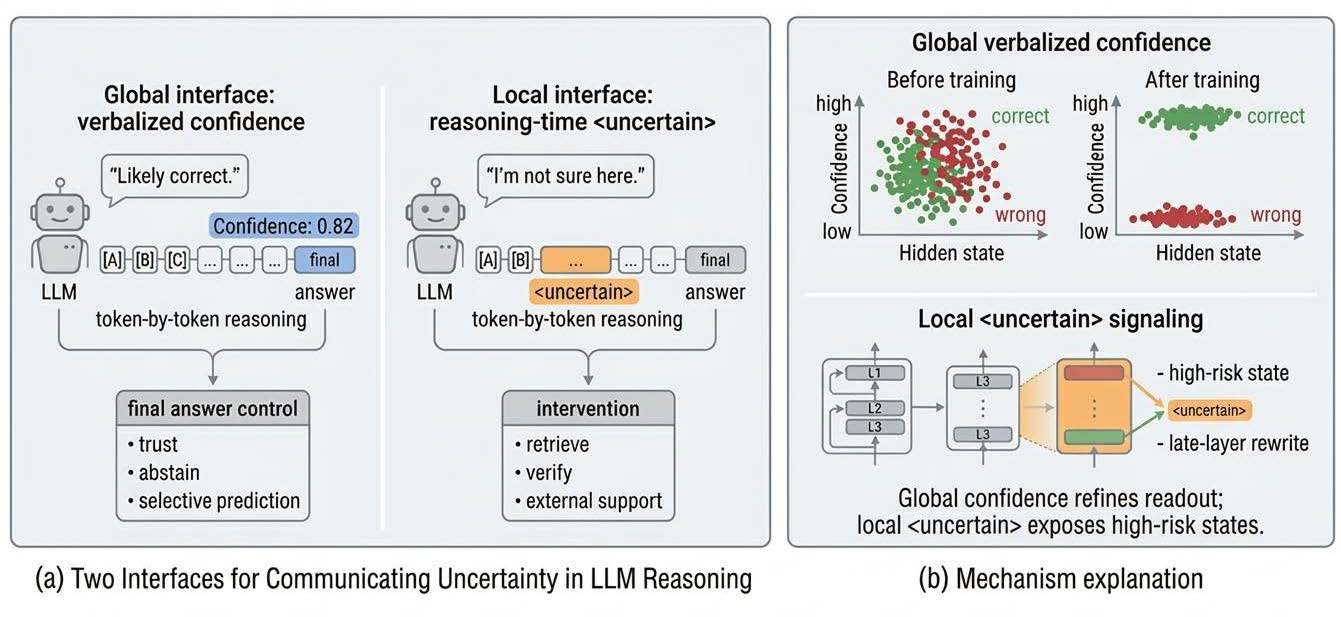
Figure 1: Overview of the two uncertainty interfaces.
Methodology: Interface Construction and Optimization
Verbal Confidence Interface
The global interface is instantiated as a trajectory-level mapping from final hidden states to a confidence value c∈[0,1], intended to approximate the posterior correctness probability of the answer generated. Crucially, training is based on a calibration-aware reward: for a completed answer with confidence p, the model is rewarded with +p if the answer is correct and −p otherwise. This reward structure directly penalizes overconfident errors and incentivizes only justified high confidence.
The theoretical analysis is anchored in generalized reinforcement learning via policy reweighting (GRPO). The post-update policy shifts probability mass away from overconfident error trajectories and toward justified trajectories, but never creates new trajectories not already supported by pretraining. Thus, calibration mainly reorders latent reasoning paths by their empirical reliability, rather than generating new solutions ab initio.
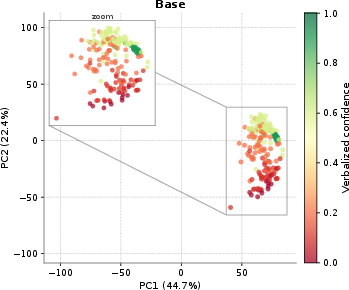
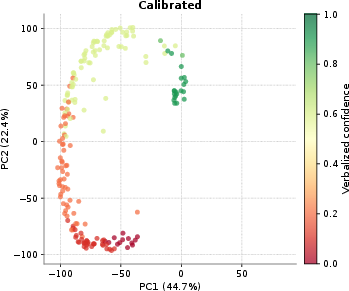
Figure 2: Base model.
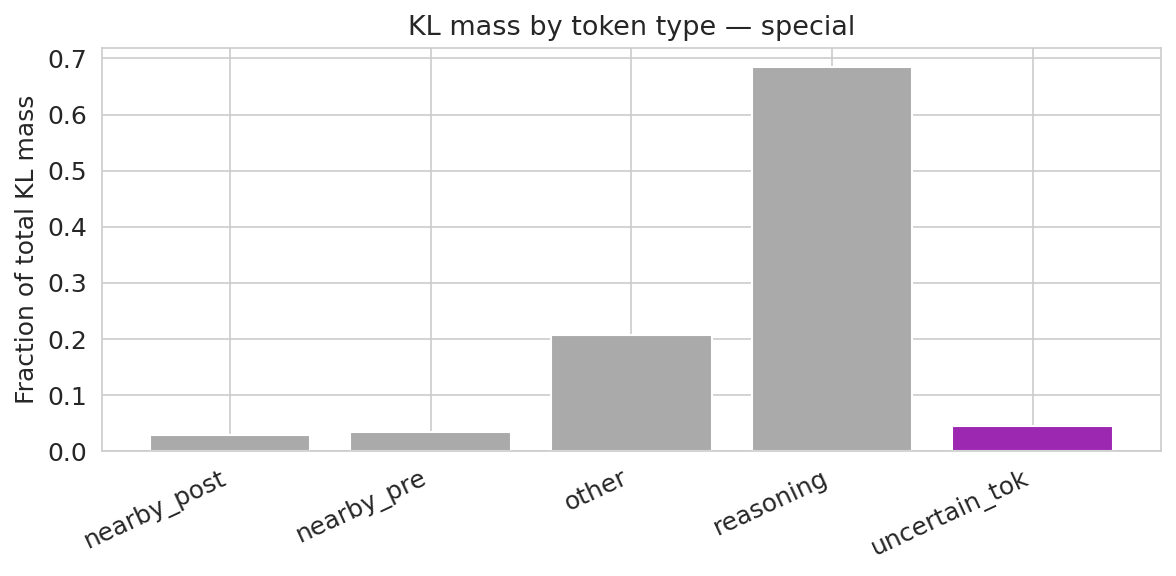
Figure 3: Verbal model. Most total KL mass lies in reasoning tokens, even though confidence digits are strongly enriched on a per-token basis.
Local Reasoning-Time Interface
The local interface is realized as the emission of a literal <uncertain> marker at any point in reasoning where the model enters a high-risk or knowledge-gap state. The objective during training imposes an asymmetry: silent (unemitted) failures are penalized more heavily than explicit uncertainty emission, pushing the model to surface its epistemic boundaries. The emission points are then used as triggers for system-level interventions (evidence retrieval, tool invocation, etc).
Probe-based hidden-state analysis determines where in the model’s representation the signal for uncertainty resides, and when it is most reliably detectable for control purposes.
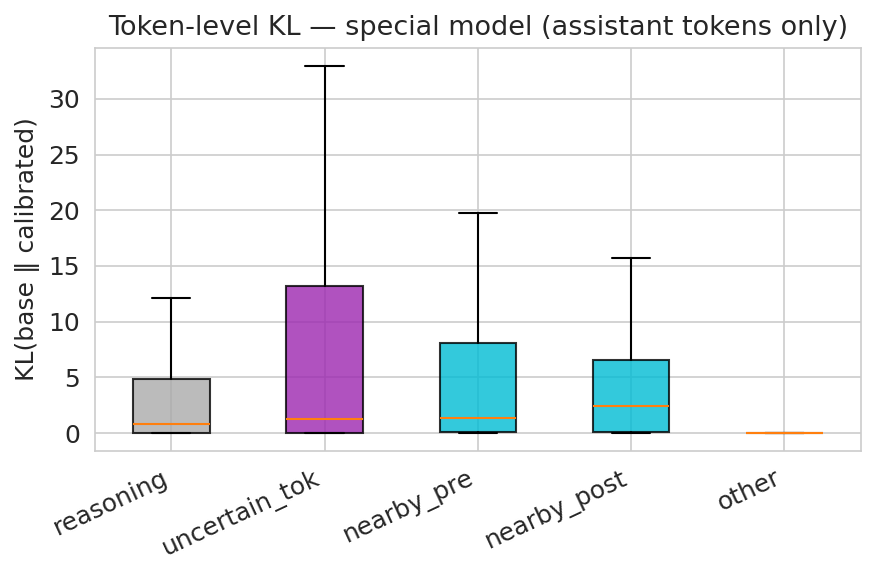
Figure 4: Verbal interface.
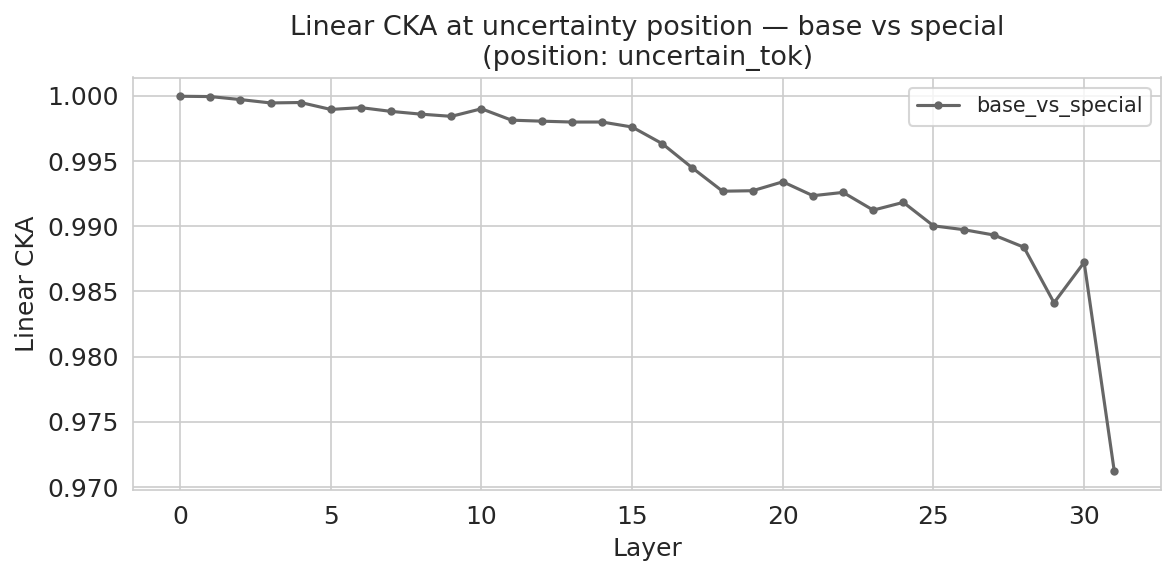
Figure 5: Verbal interface.
Empirical Results
Calibration Improvements and Behavioral Shifts
The global verbal confidence model achieves a strong empirical calibration: accuracy modestly improves (0.345 → 0.358), but expected calibration error (ECE) and overconfidence are dramatically reduced (ECE: 0.383 → 0.049; overconfident errors: 88.6% → 3.9%). The recalibrated model suppresses overconfident hallucinations, redistributing them as low-confidence errors—effectively shifting epistemic failure modes to aleatoric, lower-risk ones.
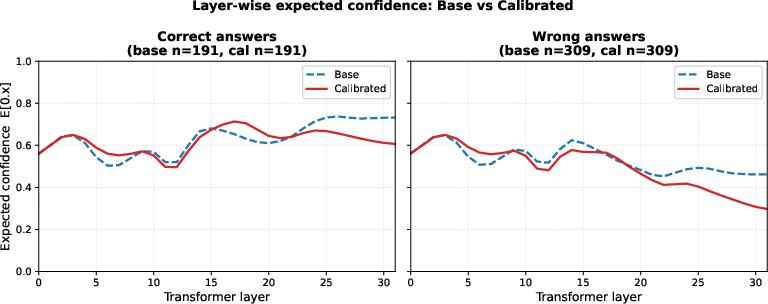
Figure 6: Detailed binned routing view for verbalized confidence calibration. In the base model, correct answers and many wrong answers both terminate with dominant mass in the High confidence bin. After calibration, low-confidence errors are redirected away from High and into Low, while correct answers remain more conservative. This makes the main mechanism visually explicit: calibration sharpens the late-stage mapping from hidden states to confidence outputs rather than uniformly lowering confidence everywhere.
Reasoning-Time Emission and Downstream Control
For the local interface, the trained model emits <uncertain> at a broad range of positions along the reasoning trace, not only at endpoints. This emission converts previously silent, undetected errors into explicit, system-interpretable intervention points. The fraction of wrong answers flagged for intervention rises from 15.1% (base) to 88.2% (calibrated), with substantial increases in overall answer-line completion, accuracy, and detector recall (79.9% on emitted cases).
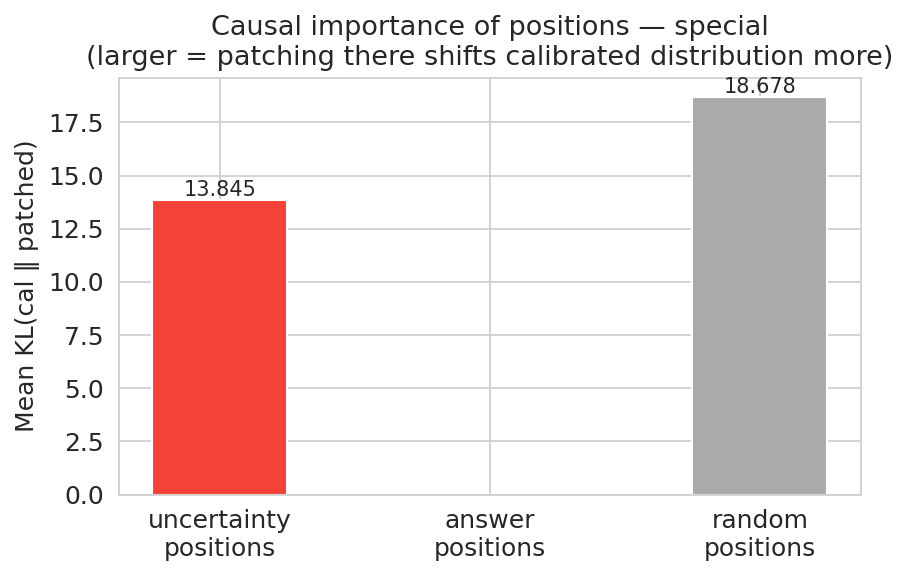
Figure 7: Verbal interface.
Mechanistic Analysis
Mechanistic interpretability probes show that the two interfaces alter the model's computation in distinct ways:
- Verbal confidence calibration leads to sharp alterations at output (confidence token) positions only. The KL-divergence footprint is tightly localized (Figure 3), and representation geometry is almost perfectly preserved relative to the base model (CKA ≈ 1.0 throughout). Thus, the model learns to extract and express latent uncertainty without disrupting the broader computation, operating as a geometric refinement at readout rather than an architectural rewrite.
- <uncertain> emission induces broader late-layer representational change (diverging CKA), and the signal spreads spatially across both the emission token and neighboring reasoning tokens. This reflects an explicit construction of an uncertainty state during reasoning, as required for timely intervention.
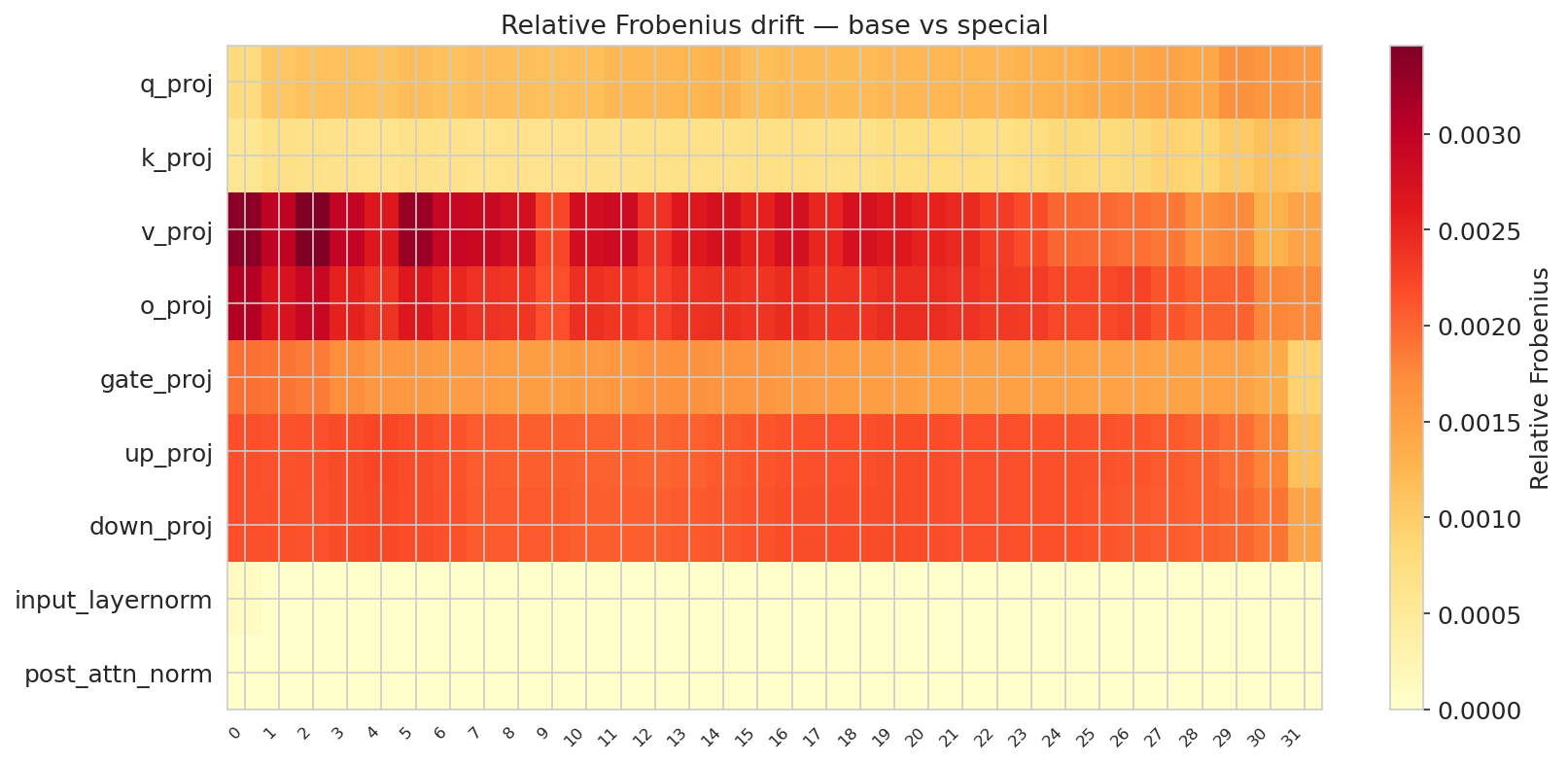
Figure 8: Verbal model. Drift is concentrated in value/output projections and MLP projections, with minimal change in normalization layers.

Figure 9: Mechanism-to-behavior linkage for the verbal model. Localization-related features predict per-example confidence shifts with cross-validated R2=0.51, indicating that the strength of the learned confidence mechanism varies meaningfully across examples rather than appearing only as a population-level average.
Downstream Task Evaluation and Interface Comparison
On Adaptive RAG (retrieval-augmented generation) benchmarks, both interfaces decisively outperform prior approaches—whether post-hoc signal extraction, output-format supervision, or heuristic emission detection. Notably:
- Verbal-Calibrate delivers the best overall F1/EM, triggering retrieval more selectively but with higher precision.
- Uncertain-Calibrate achieves high-recall intervention but triggers retrieval more frequently, making it well-suited to recall-focused controllers.
Neither effect is reducible to simple template formatting or post-hoc rescaling: control performance is only realized with explicit, interface-matched training.
Implications and Future Directions
This study robustly demonstrates that explicitly trained uncertainty interfaces are indispensable for actionable, legible, and reliable control in LLMs. The global-verbal interface is optimal for final-answer trust assessment, supporting abstention, gating, and selective retrieval. The local emission interface is maximally useful for exposing failures during reasoning, enabling high-recall interventions pre-commitment.
The mechanistic separation—readout sharpening versus architectural rewrite—suggests that future models may optimally combine both, deploying global, calibrated trust signals at the macro (response) level, and local uncertainty emissions at micro (process) granularity. In a retrieval or tool-augmented setting, this implies a compositional interface, where LLMs alternately propose, verify, and revise their hypotheses by introspecting and signaling epistemic boundaries in real time.
Further theoretical development on interface learning objectives, interpretability of uncertainty states, and extension to tool-integrated or RL-fine-tuned models is warranted. Explicit uncertainty communication will likely become a primary axis of differentiability in safety-critical, high-stakes LLM deployment.
Conclusion
This work reconceptualizes uncertainty not as a post-hoc artifact but as a multi-scale, trainable interface. Effective LLM control and trust hinge on explicit, interface-matched uncertainty expression: verbalized global scores for answer trustworthiness, and process-local emission for intervention signals. The findings set a new standard for uncertainty-aware LLM system design, with theoretical and practical ramifications for high-reliability AI.