- The paper introduces a direct conversion method from autoregressive to block-diffusion VLM, considerably reducing training complexity.
- It employs innovations like block-size annealing and causal context attention to maintain near-lossless accuracy while boosting inference speed.
- Experimental results show high throughput and robust performance on 11 multimodal benchmarks, ideal for real-time applications.
Fast-dVLM: Efficient Block-Diffusion VLM via Direct Conversion from Autoregressive VLM
Introduction and Motivation
Fast-dVLM introduces an efficient block-diffusion paradigm for vision-LLMs (VLMs) aimed at resolving the inherent throughput limitations of autoregressive (AR) decoding, particularly in physical AI applications such as robotics and autonomous driving. AR-based VLMs generate tokens sequentially, which is a bottleneck for inference under tight batch-size-one constraints, as seen in edge deployments. Block-wise discrete diffusion, with speculative block decoding methodologies, offers a solution by generating multiple tokens in parallel, effectively utilizing hardware parallelism.
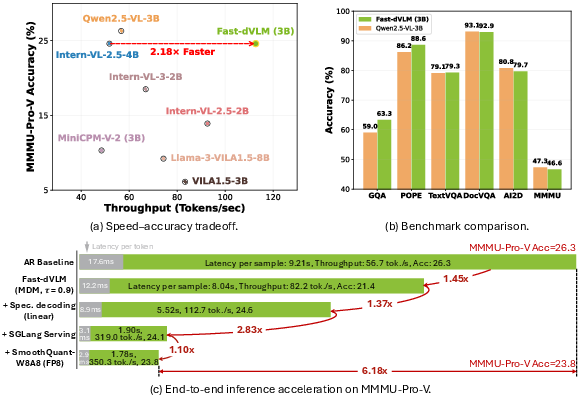
Figure 1: Fast-dVLM offers near-lossless accuracy compared to AR VLMs on MMMU-Pro-V and up to 6.18× end-to-end inference speedup on a single H100 GPU.
Methodological Advances
AR-to-Diffusion Conversion: Direct vs. Two-Stage
The paper systematically compares two strategies for converting a pretrained AR VLM into a block-diffusion VLM: (a) a two-stage process that adapts the LLM backbone via text-only diffusion fine-tuning before multimodal training, and (b) direct conversion that fine-tunes the full VLM in a single multimodal stage.
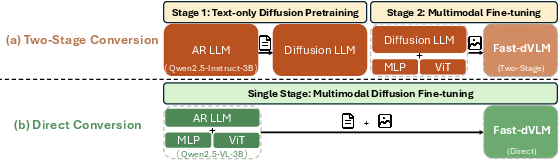
Figure 2: The two-stage strategy (a) applies text-only diffusion before multimodal fine-tuning; the direct path (b) converts the entire VLM in a single multimodal stage.
Empirical results demonstrate that the direct path is substantially more data- and compute-efficient, leveraging the pretrained multimodal alignment without repetitive adaptation. The direct approach outperforms the two-stage method across all benchmarks, with particularly pronounced gains on reasoning-intensive tasks.
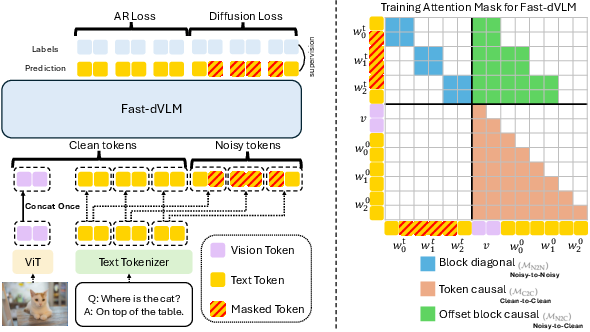
Figure 3: Training architecture and attention mask for block size B^=2, illustrating vision-efficient concatenation and block-diagonal attention.
Training Innovations
Fast-dVLM employs several architectural and training adaptations to support block diffusion in the multimodal setting:
- Block-size Annealing: Progressive curriculum for increasing block corruption spans, improving denoising stability.
- Causal Context Attention: Preserves the pretrained AR sequential structure and compatibility for self-speculative verification.
- Auto-Truncation Masking: Prevents future prompt leakage in multi-turn settings via response boundary truncation.
- Vision-Efficient Concatenation: Minimizes compute and memory overhead by avoiding unnecessary vision embedding duplication in the noisy stream.
The dual-loss objective combines diffusion branch for parallel denoising with a causal LM branch to retain AR capabilities.
Inference Algorithms
Fast-dVLM enables KV-cache-compatible block-wise parallel decoding. The inference pipeline includes:
Integration with SGLang and further FP8 quantization produces system-level speedups, reaching up to 6.18× wall-clock improvement over AR decoding.
Experimental Results
Accuracy and Efficiency
Fast-dVLM, initialized from Qwen2.5-VL-3B via direct conversion, was evaluated on 11 multimodal benchmarks. With masked diffusion model (MDM) decoding, it achieved an average score of 73.3, nearly matching the AR baseline (74.0), and 1.95× tokens per forward evaluation (NFE). Speculative decoding reached 2.63× tokens/NFE and exact baseline performance on short-answer tasks. For the long-answer MMMU-Pro-V benchmark, Fast-dVLM with speculative decoding scored only 1.7 points below AR baseline, confirming near-lossless quality in extended reasoning.

Figure 5: Qualitative math reasoning: Fast-dVLM achieves correct results with 1.6× faster decoding than AR baseline.
Ablation and Speed Analysis
Ablation studies highlight the critical impact of causal context attention (−22.5% average accuracy if removed), block-size annealing (−4.4%), and auto-truncation masking (−3.7%). The confidence threshold τ=0.9 yields the optimal speed-quality tradeoff for MDM decoding. Speculative decoding with SGLang and FP8 quantization further boosts throughput to 350.3 tokens/sec (6.18× speedup) without significant quality loss.
Qualitative Examples
Fast-dVLM maintains high decoding throughput and accurate reasoning in art recognition, chart QA, and physical AI tasks such as autonomous driving and robotic manipulation, with tokens/step ratios above 1.68 for long-form outputs.

Figure 6: Fast-dVLM demonstrates accurate responses with high throughput for diverse categories including art style, celebrity identification, and chart QA.

Figure 7: Fast-dVLM enables efficient, stepwise reasoning in embodied and physical AI tasks, maintaining high throughput and detailed output.
Practical and Theoretical Implications
The direct conversion methodology substantially reduces training complexity and increases adaptability of AR VLMs to block-diffusion paradigms, with negligible performance regression. The block-diffusion and self-speculative mechanisms dramatically improve inference efficiency under edge constraints. This enables practical deployment of VLMs in real-time robotics, autonomous vehicles, and other latency-critical multimodal environments. Theoretical advances in dual-mode attention, block-wise denoising, and adaptive masking strengthen the foundation for future multimodal diffusion modeling.
Future Directions
Potential research directions include further scaling to larger block sizes, optimizing quadratic speculative decoding kernels, integrating reinforcement learning for improved chain-of-thought coherence (see (Zhao et al., 16 Apr 2025)), and exploring hybrid AR-diffusion architectures for even finer quality-speed tradeoffs. The paradigm is generalizable to broader multimodality and structured output scenarios, positioning block-diffusion models as a robust alternative to conventional AR inference.
Conclusion
Fast-dVLM establishes a systematic, efficient recipe for block-diffusion vision-language modeling, demonstrating near-lossless generation quality with substantial inference speedup over AR baselines. The direct conversion process leverages pretrained multimodal alignment, outperforming two-stage approaches in quality and training efficiency. Key architectural innovations and dual-mode speculative decoding deliver practical acceleration for edge deployment, while extensive experiments affirm generalization across diverse benchmarks and tasks. Fast-dVLM marks a significant advancement in scalable, parallel multimodal reasoning.