- The paper presents A-MBER, a novel benchmark that evaluates history-grounded affective interpretation in extended conversational settings.
- It employs a staged construction pipeline with persona definition, multi-session synthesis, and explicit annotation to ensure selective and context-sensitive memory usage.
- Experimental results reveal that structured memory significantly boosts affect inference performance compared to local-context baselines, underscoring the importance of memory organization.
A-MBER: Towards Benchmarking Affective Memory in Long-Horizon Emotion Recognition (2604.07017)
A-MBER addresses a critical evaluation gap in current AI research: while long-term memory datasets concentrate on factual recall and temporal consistency, and emotion recognition datasets focus on local instantaneous affect, there is a lack of systematic benchmarking for models’ ability to leverage remembered multi-session interaction history to interpret users' present affective states. This capability is indispensable for memory-centered conversational systems, which function in settings where the significance of a user’s emotional presentation is determined not only by the current utterance, but by historical events, recurring triggers, prior attempts at support, and emotional trajectories across sessions.
A-MBER departs from conventional benchmarks by formulating affective memory evaluation as the intersection of emotion recognition and long-horizon memory, foregrounding the need for history-grounded present-state affect interpretation. The central hypothesis is that models require not only extensive memory windows, but also selective and context-sensitive utilization of interaction history for accurate present-state affective inference.
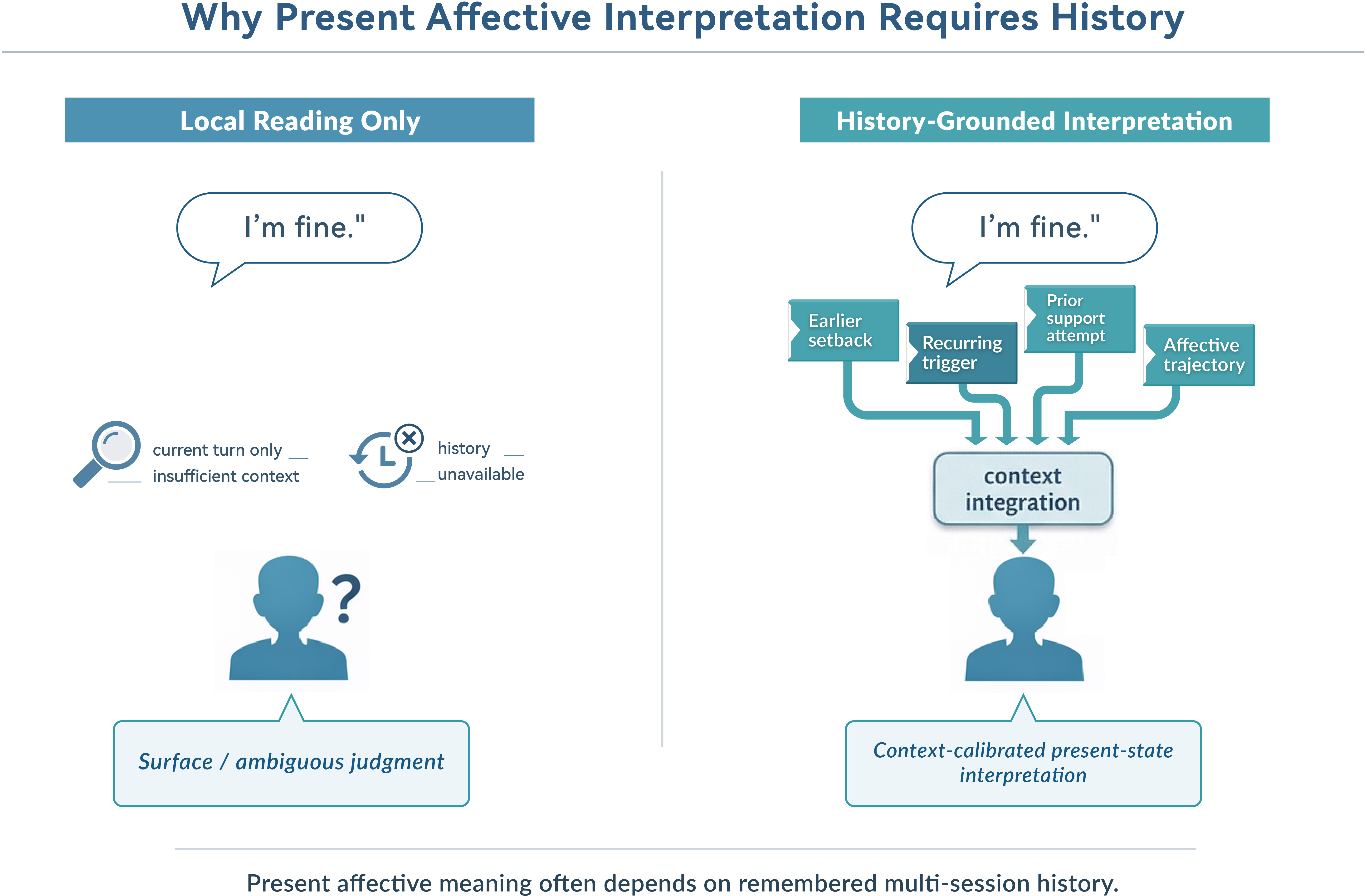
Figure 1: Motivation for history-grounded affect interpretation; identical anchor turns yield divergent emotional readings when evaluated with their preceding context.
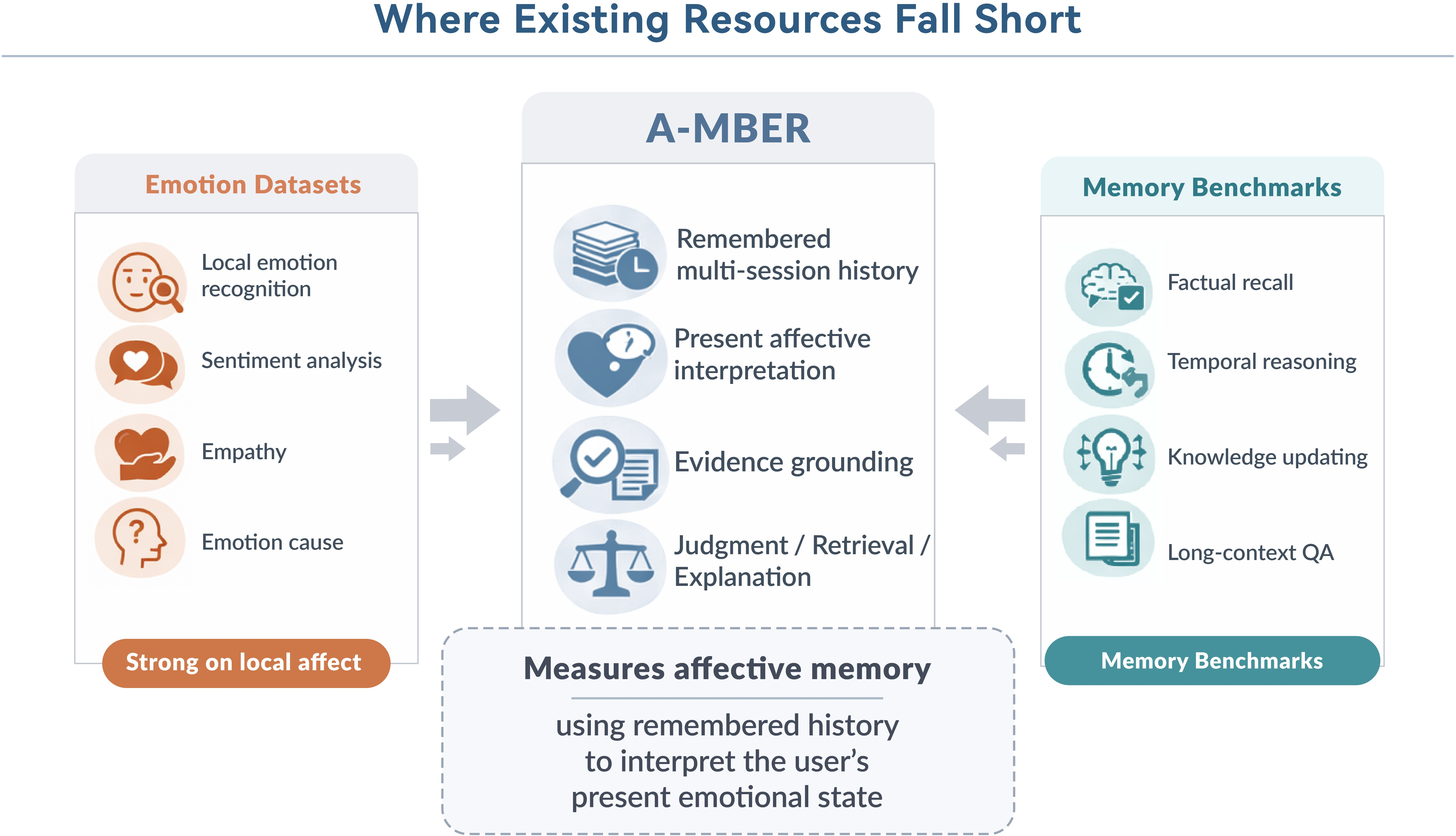
Figure 2: A-MBER's position at the intersection between local emotion evaluation and factual temporal reasoning benchmarks.
Benchmark Construction Framework
A-MBER employs a staged construction pipeline anchored by explicit intermediate representations: persona definition, long-horizon planning, multi-session conversation synthesis, annotation, question creation, and controlled benchmark packaging. The primary scenario involves teacher/counselor–student roles in repeated session dialogues, with student-side affect as the interpretation target. Instead of flat data generation, each benchmark unit centers on a designated anchor turn, contextualized with the relevant historical trajectory, task query, and evidence specification.
The construction pipeline ensures that long-horizon emotional dependencies are explicitly built into interaction data, separating scenario design, observable dialogue, and turn-level supervision. The anchor-turn schema encourages evaluation mechanisms to focus on the momentary state while demanding evidence from prior turns, thus enforcing historical grounding.
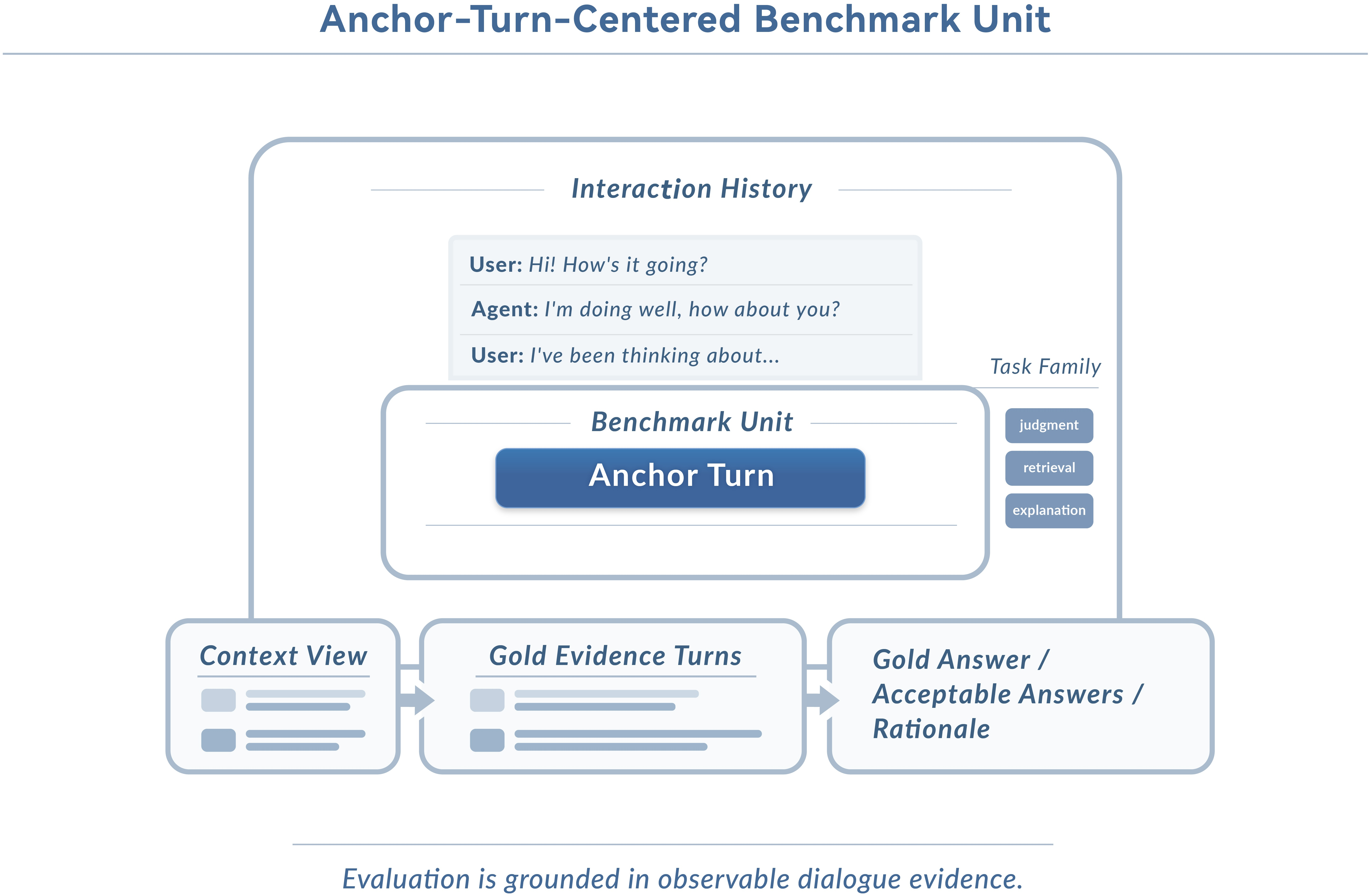
Figure 3: Benchmark unit schema centers on an anchor turn, associated history, task specification, evidence, and expected output.
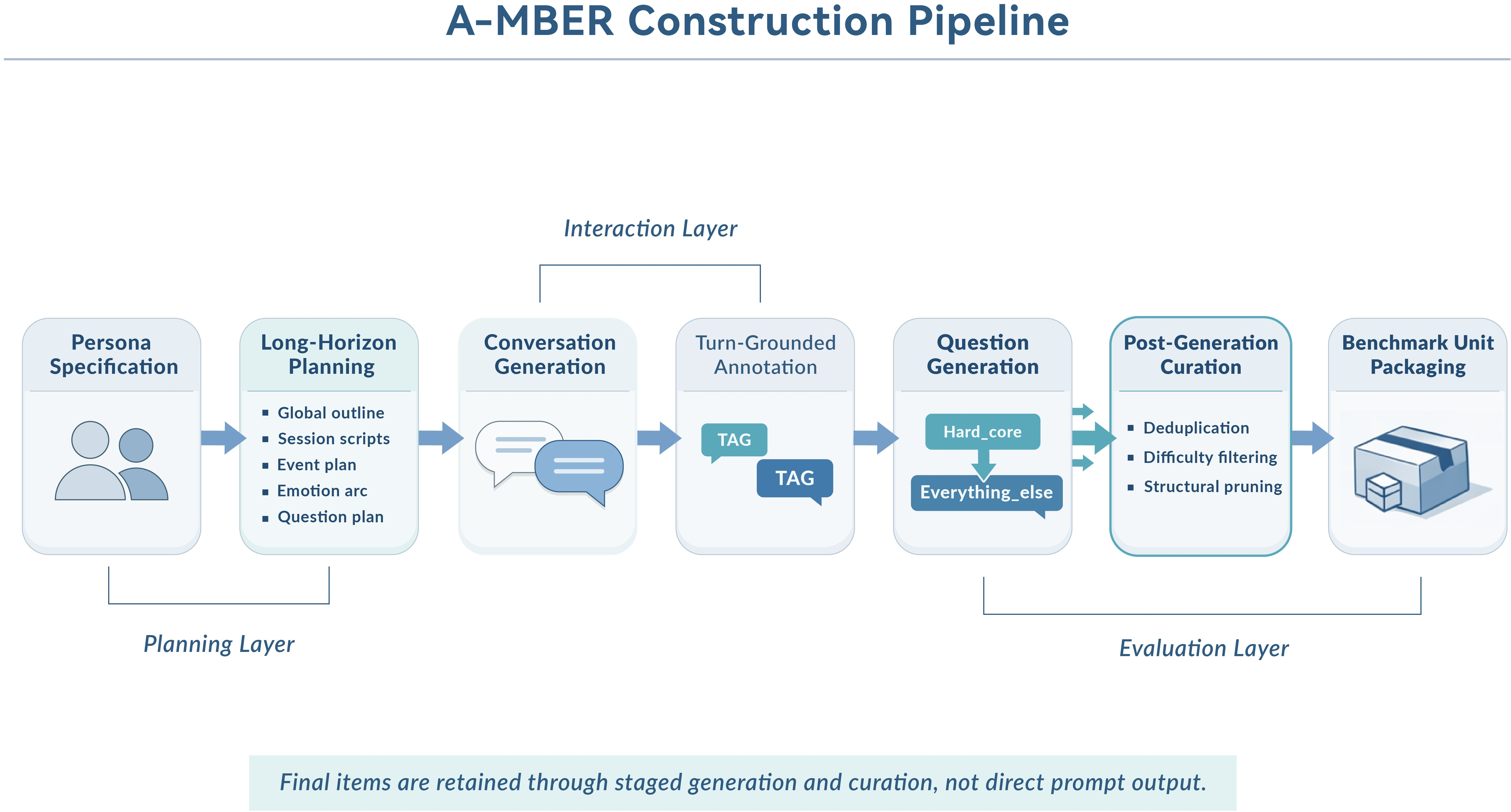
Figure 4: Staged pipeline for benchmark creation, including planning, generation, annotation, and curation.
Task Families and Evaluation Design
A-MBER decomposes evaluation into three primary task families:
- Judgment: Present-state affect inference at the anchor turn.
- Retrieval: Identification of historically relevant evidence turns supporting interpretation.
- Explanation: Justification of the interpretation in a grounded, evidence-driven manner.
Robustness-oriented and adversarial settings (modality degradation, insufficient evidence) are integrated to decouple genuine long-horizon affective understanding from superficial local performance. The benchmark instantiation uses layered composition: core affect-memory items, diagnostic probes (trajectory, relation, multi-hop reasoning), and stress-tests (modality-missing, ambiguous input).
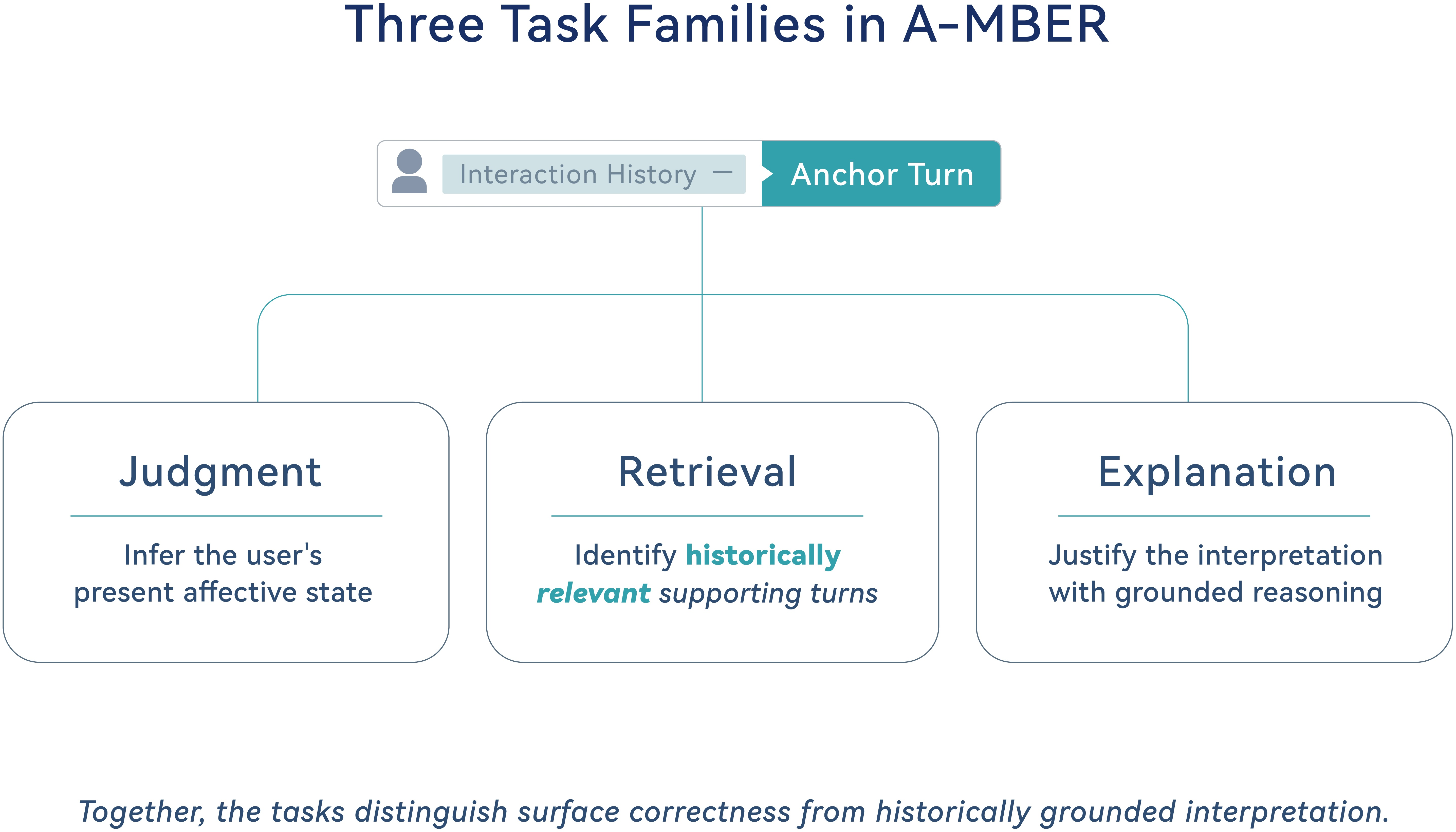
Figure 5: Task family organization capturing judgment, retrieval, and explanation.
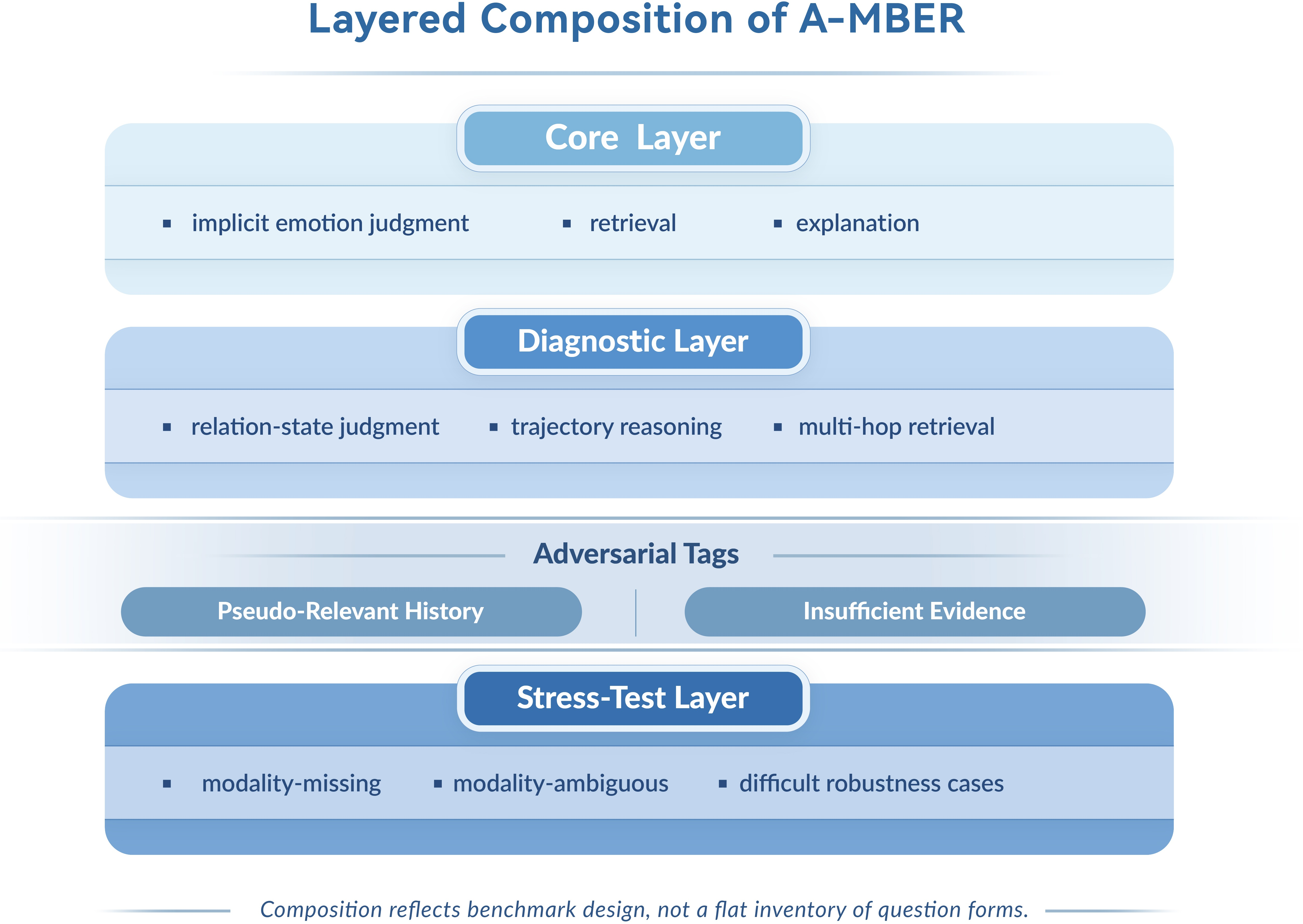
Figure 6: Layered benchmark structure, distinguishing primary evaluation targets and robustness/diagnostic subcomponents.
Memory Levels, Reasoning, and Evaluation Protocol
A-MBER annotates each item with memory dependency (degree of historical reliance) and reasoning structure (local vs. multi-hop, trajectory-based). This allows for stratified reporting and calibrated analysis of where memory most impacts affective interpretation. System comparison is organized via explicit context policies: session-local (current session only), full-history (all prior sessions), retrieved-memory (selective historical access), structured-memory (advanced memory architecture), and gold-evidence (providing annotated supporting turns).
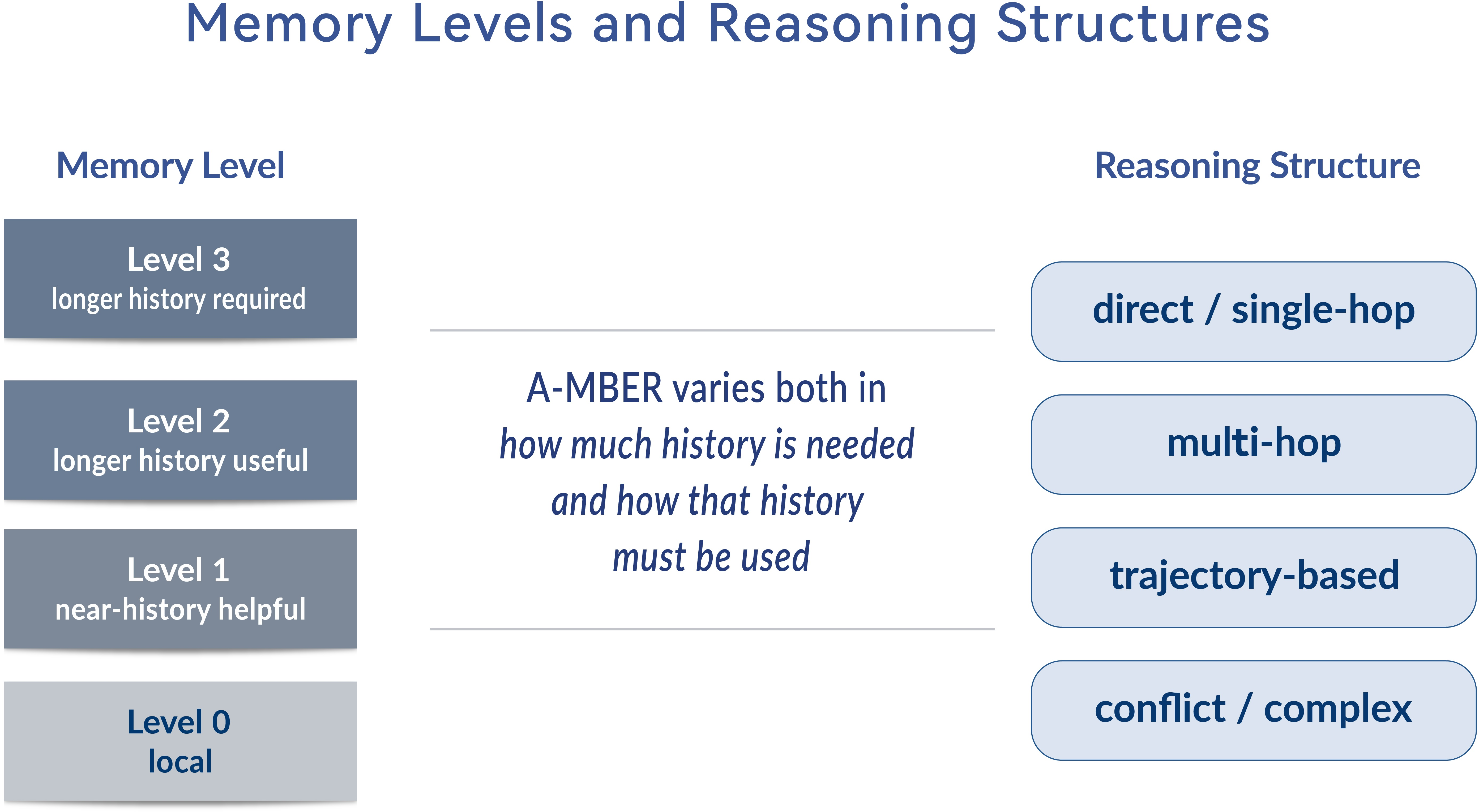
Figure 7: Overview of how items vary by memory-dependency and reasoning complexity.
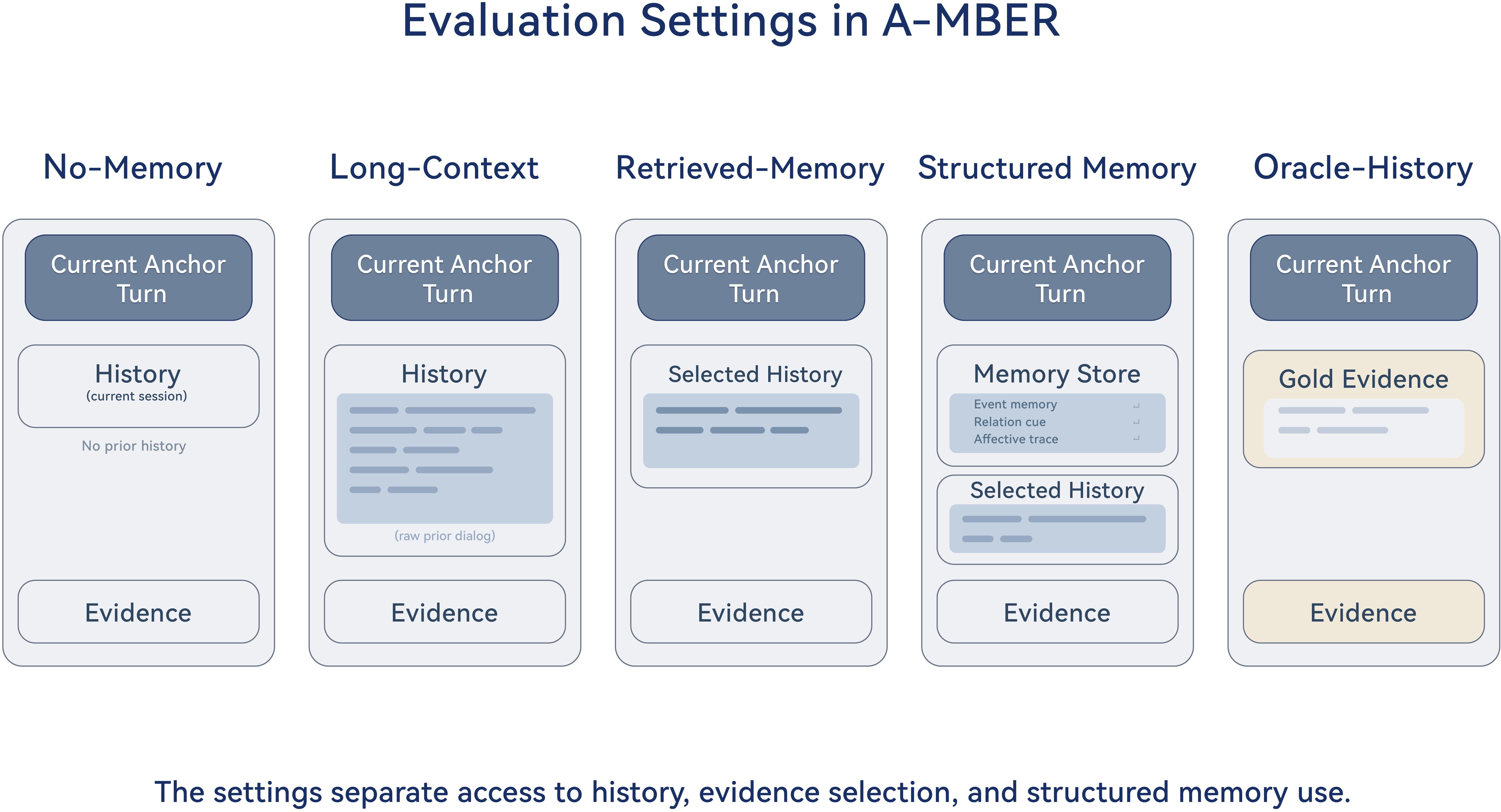
Figure 8: Evaluation settings contrasting memory access paradigms; fixed benchmark units allow attribution of performance gains to memory structure.
Experimental Results
Empirical evaluation demonstrates consistent improvements as models are equipped with broader and increasingly structured access to history. Results show:
- Substantial performance increase from minimal local context (judgment: 0.34) to structured memory (judgment: 0.69), with gold-evidence as an upper bound (judgment: 0.81).
- Memory-mediated gains are most pronounced in long-range implicit affect, high memory dependency, trajectory-sensitive queries, and robustness/adversarial settings.
- Structured memory outperforms both raw-context and retrieval-based access, indicating benefits from memory organization beyond simple exposure or retrieval.
- Even with gold supporting evidence provided, the benchmark retains substantial interpretation difficulty, mitigating concerns of evidence-access saturation.
Strong numerical results confirm the benchmark’s discriminative power on the targeted dimensions; e.g., for long-range implicit affect, structured memory systems yield 0.65 accuracy vs. 0.18 for local-only baselines, and memory level 3 items display the largest performance delta.
Implications, Limitations, and Future Directions
A-MBER supplies a formal infrastructure for quantifying affective memory capabilities in conversational systems, advancing evaluation beyond factual memory or local affect recognition. Practically, this supports the development of AI assistants capable of sustained, contextually appropriate behavior, critical for domains like tutoring, counseling, and care. The benchmark explicitly distinguishes between improvements from mere history access vs. selective, grounded use, enabling principled comparison across memory architectures.
Theoretical implications include redefinition of long-range difficulty as event density and cross-session interpretive burden, rather than text length, and foundational justification for memory-centered evaluation paradigms in affective intelligence. A-MBER exposes limitations in existing approaches, showing that access to history is not sufficient—organization, selection, and context-sensitive reasoning are indispensable.
Limitations include synthetic data and scenario constrainment; broader domain generality, multimodal evidence integration, human-written data, and more realistic interaction settings remain as avenues for future extension. Open-form explanation evaluation mandates continued exploration of rubric-guided and human oversight scoring mechanisms.
Conclusion
A-MBER inaugurates a benchmark suite specifically for history-grounded affective interpretation, systematically evaluating the integration of long-horizon memory in emotion recognition. Rigorous construction, stratified analysis, and robust empirical validation substantiate A-MBER’s utility in distinguishing memory architectures and advancing system-level affective intelligence. By targeting the intersection of memory use and affect interpretation, A-MBER establishes new methodology for both theoretical study and practical deployment of memory-centered AI systems in extended conversational settings.