- The paper demonstrates that DACS, a deterministic and agent-triggered protocol, increases steering accuracy up to 98.4% while reducing context pollution significantly.
- It utilizes a dual-mode architecture—Registry and Focus—to maintain lightweight per-agent registries and isolate complete context as needed, ensuring efficient orchestration.
- Empirical analyses across diverse and high-density scenarios validate DACS's robust performance improvements and sub-linear context scaling for multi-agent LLM environments.
Dynamic Attentional Context Scoping for Multi-Agent LLM Orchestration: Mechanism and Empirical Analysis
Motivation and Problem Statement
The orchestration of multiple concurrent LLM agents—where an orchestrator LLM coordinates, steers, and integrates the activity of numerous specialized agents—poses acute scaling challenges due to "context pollution." As the number of agents (N) increases, each agent's intermediate state, task-specific outputs, and pending queries compete for space in the orchestrator's context window. In flat-context architectures, this mutual contamination erodes per-agent steering accuracy, decreases context efficiency, and induces cross-agent leakage (i.e., the orchestrator's responses to one agent are semantically or lexically polluted by the states of others). Prior context management research addresses single-agent memory overflow, tool/retrieval bloat, or system-level memory compression but does not implement per-agent dynamic isolation for concurrent, steerable agents.
DACS: Mechanism Design and Theoretical Properties
Dynamic Attentional Context Scoping (DACS) is introduced as a deterministic, agent-triggered protocol for context isolation in multi-agent orchestration. The orchestrator LLM switches between two primary asymmetric operational modes:
- Registry Mode: The orchestrator holds a lightweight per-agent registry (≤200 tokens/entry), updated in real-time with status, minimal task summaries, and progress. This mode supports system responsiveness and efficient agent monitoring.
- Focus(ai) Mode: Upon receipt of a
SteeringRequest from agent ai, the orchestrator loads ai’s complete context (task details, steering history, current output) and compresses all other agent contexts to their respective registry entries. The context window thus contains F(ai)+R−i, ensuring all other agent state is minimized.
Context isolation is agent-triggered, respecting agent urgency (with preemption for high-priority requests), and ensures focus context scales sub-linearly with N and decision density D. The focus mode context size grows as ∣F∣+(N−1)∣r∣, and the context efficiency ratio (flat baseline/DACS) increases monotonically with N and ≤2000.
Experimental Design
Empirical analysis spans four experimental phases using an open-source orchestration harness, with all agent-orchestrator interactions fully observable at the token level:
- Phase 1 (Agent Count Scaling): ≤2001 agents; canonical mix of code, research, and data agents. Measures how context pollution and accuracy scale with ≤2002.
- Phase 2 (Agent Diversity): Homogeneous (shared vocabulary), maximally diverse (disjoint domains), and adversarial cascade (pipeline dependency) scenarios test the protocol under various agent interaction structures.
- Phase 3 (Decision Density): Fix ≤2003, scale up decisions-per-agent ≤2004 to probe context and accuracy degradation under long interaction sequences.
- Phase 4 (Ecological Validity): All scripted agent stubs are replaced with autonomous LLM agents (Claude Haiku 4.5), emitting free-form steering requests, evaluated with LLM-as-judge protocols (Claude Haiku and GPT-4o-mini).
Three metrics are core: steering accuracy (keyword/LLM-judged correctness per agent decision-point), wrong-agent contamination (keyword leakage from non-target agents), and actual orchestrator context size at each steering point.
Principal Findings
Context Pollution and Accuracy Dynamics
In all synthetic scenarios, DACS yields a steering accuracy of 90.0–98.4% versus 21.0–60.0% for a flat-context baseline (p < 0.0001). The advantage grows with agent count—accuracy delta increases from +36.7 pp (≤2005) to +69.0 pp (≤2006). DACS also suppresses contamination rates, achieving 0-14% (vs 28–57% baseline). Critically, the context efficiency ratio grows with scale, reaching up to 3.53× at ≤2007.
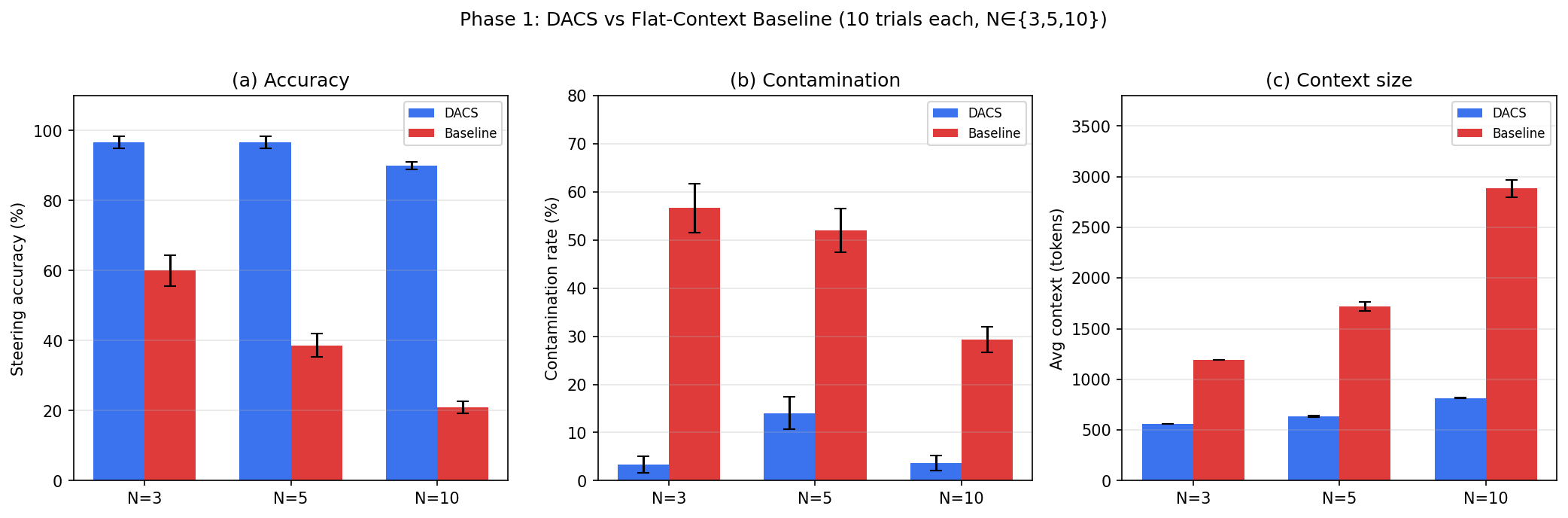
Figure 1: DACS vs. flat-context baseline across ≤2008, highlighting sharp improvements in steering accuracy, substantial reductions in cross-agent contamination, and aggressive context compression under DACS.
Agent Diversity and Pipeline Dependency
DACS maintains its advantage across both homogeneous and heterogeneous agent sets. For maximally diverse agents, steering accuracy remains at 96.0% with zero contamination, while the baseline collapses to 37.0% accuracy with >50% cross-agent leakage. In the pipeline (cascade) scenario—where theoretical advantages for the flat baseline may exist—DACS still outperforms by +37.3 pp.
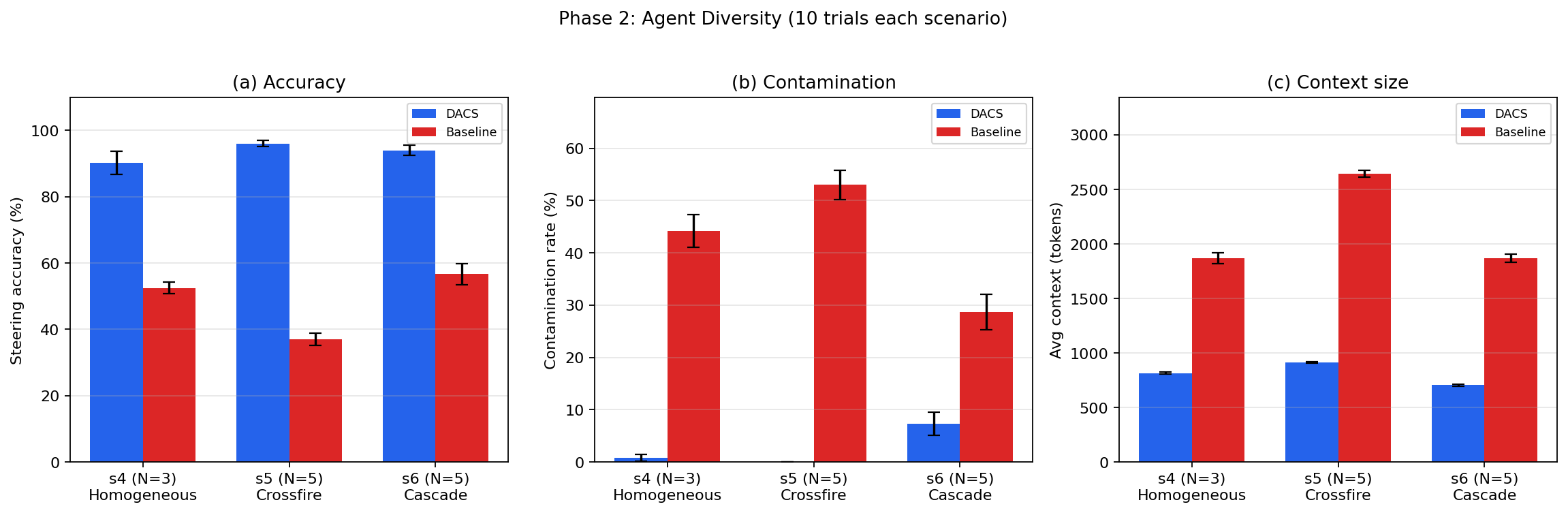
Figure 2: Phase 2 (agent diversity): DACS maintains accuracy and eliminates contamination across homogeneous, crossfire, and cascade settings, with context stability tied to enforced isolation.
Decision Density Amplification
As decision density ≤2009 increases (e.g., (ai0 for (ai1), the baseline accuracy degrades sharply, falling from 60.0% to 44.2%, whereas DACS shows stable or even improved performance (up to 98.4%). This underpins the compounding effect of interaction history length on context pollution—highlighting DACS’s sub-linear context growth and resilience.
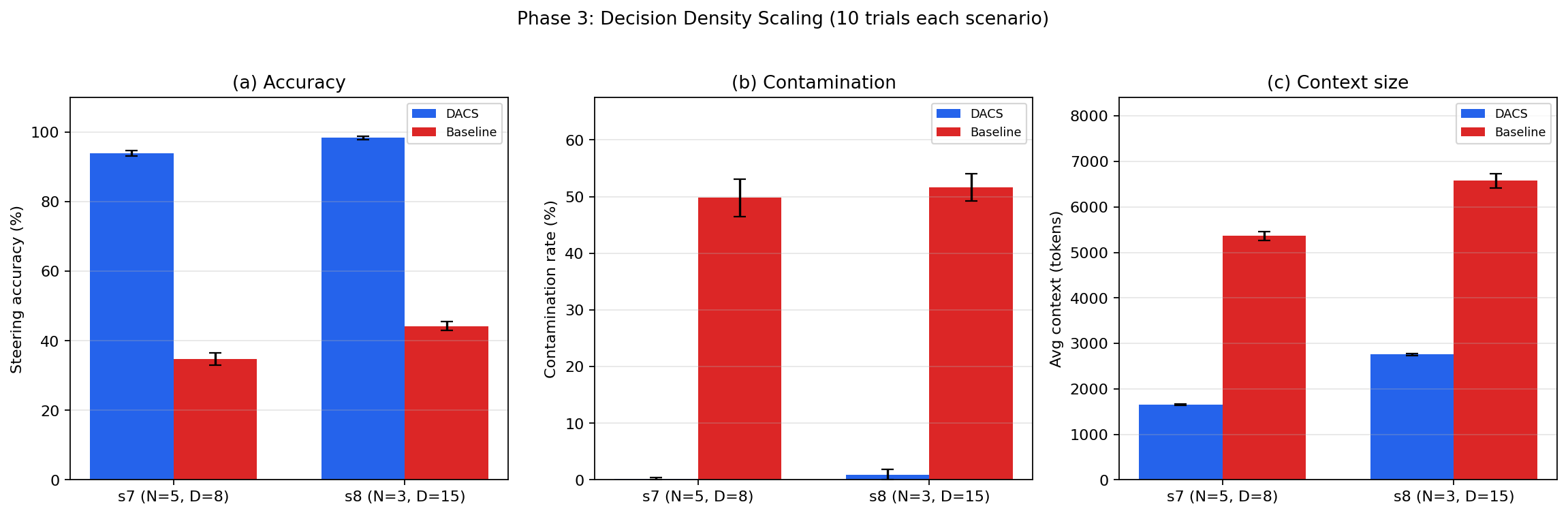
Figure 3: Decision density scaling (Phase 3) demonstrates the compounding degradation of the baseline as steering history lengthens, while DACS preserves both accuracy and context compactness.
Autonomous LLM Agents Validation
In fully autonomous agent settings (Phase 4), DACS yields a +17.2 pp accuracy delta vs baseline at (ai2 and +20.4 pp at (ai3, corroborated by both Claude Haiku and GPT-4o-mini judges. The advantage persists, though absolute accuracy decreases under the more demanding, free-form query regime (reflecting increased ambiguity and evaluation stringency). The context efficiency effect is mirrored.
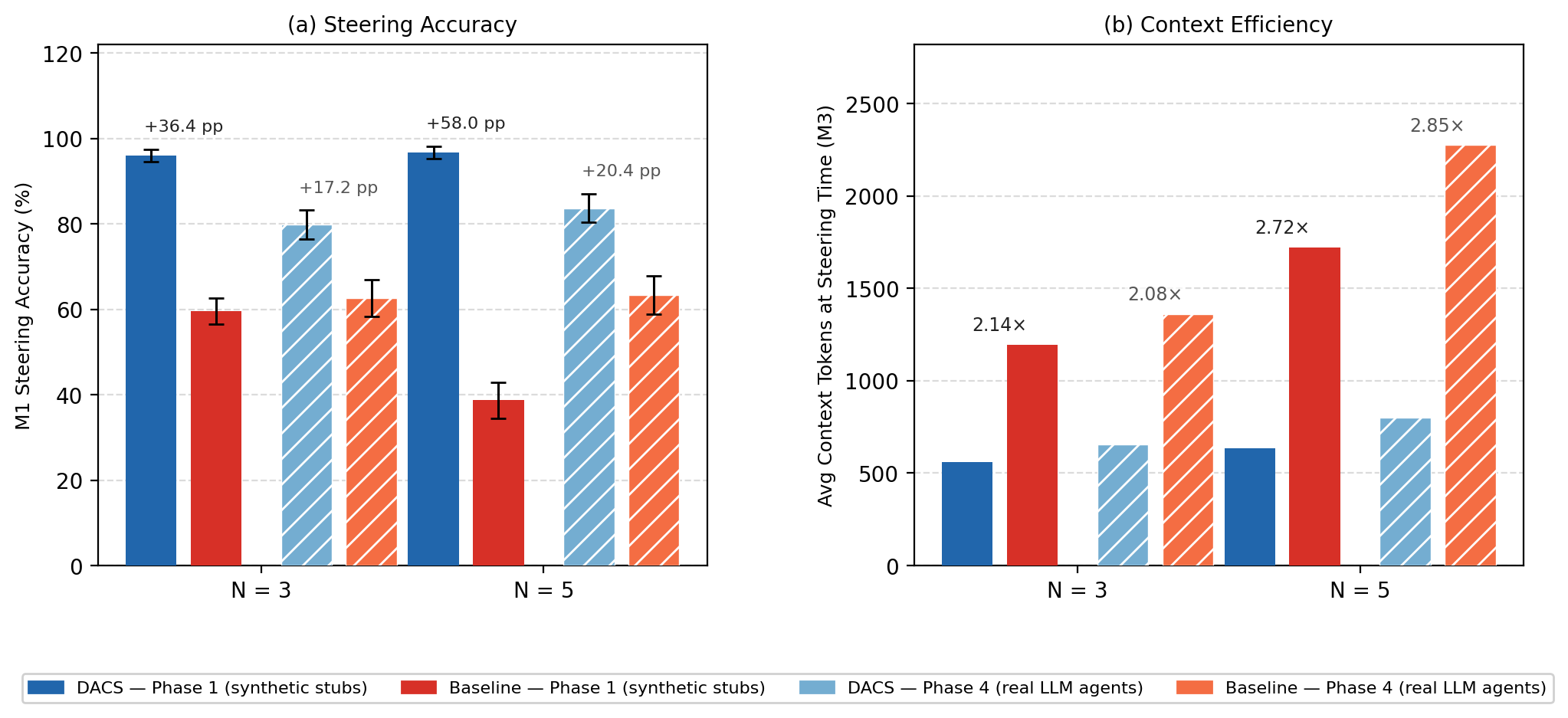
Figure 4: Real-agent validation: DACS sustains its accuracy/context advantage against the baseline in a live LLM-agent regime (Phase 4), consistent with findings in synthetic, scripted settings.
Theoretical and Practical Implications
The empirical evidence supports several theoretical claims:
- Context isolation is the principal causal variable in multi-agent steering accuracy. Unlike prior work focused on hierarchical routing or message fidelity tiering, DACS’s deterministic isolation directly targets cross-agent contamination at its moment of impact.
- Sub-linear context scaling is not a byproduct of architectural decomposition but an enforceable protocol-level guarantee. This ensures that as systems scale to large (ai4 and high (ai5, context windows remain within model limitations without sacrificing agent steering fidelity.
- Design orthogonality: DACS is fully compatible with hierarchical agent architectures and can be composed with approaches like AgentOrchestra’s planning delegation (Zhang et al., 14 Jun 2025) or context tiering.
For practical deployment, these findings indicate that orchestrator-centric LLM systems operating in tool-rich, high-parallelism environments should privilege deterministic, agent-triggered context isolation over opportunistic or reactive compression/eviction heuristics. Further, measuring and controlling actual context content at steering time supersedes aggregate memory or cache metrics for correctness and alignment.
Future Directions
Several axes require further exploration: extension to (ai6 and higher interaction densities, generalization across model families (including low-context or instruction-tuned architectures), refinement of contamination metrics (from binary cross-agent keyword detection to clause-specific leakage analysis), and integration with production user-facing responsiveness evaluations.
Conclusion
Dynamic Attentional Context Scoping deterministically eliminates context pollution by agent-triggered, asymmetric context window isolation at multi-agent orchestration steering points. Across a battery of synthetic and real-agent trials, the protocol produces substantial, robust increases in steering accuracy, strong suppression of contamination, and highly efficient context growth. Its formalization and open-source availability offer a direct path to scalable, interpretable, and accurate multi-agent LLM systems, with broad applicability to tool orchestration, workflow management, and agent collaboration in large-scale environments.
References

