- The paper introduces Alloc-MoE, a two-stage framework that optimizes expert activations to balance speed and accuracy under strict computational budgets.
- It employs Alloc-L for sensitivity-aware layer allocation using dynamic programming and Alloc-T for adaptive token-level routing based on routing entropy.
- Empirical results demonstrate up to 2.15% improvement on math tasks and notable inference speedups, validating its efficiency in constrained environments.
Budget-Aware Expert Activation for Efficient MoE Inference: The Alloc-MoE Framework
Introduction
Mixture-of-Experts (MoE) architectures have become central to efficient scaling of LLMs by leveraging sparse routing of token representation through specialized expert subnetworks. However, the projection of tokens to multiple experts per layer introduces a non-negligible inference latency bottleneck, especially in edge and resource-constrained scenarios. Attempts to reduce the number of active experts per token are known to affect model performance adversely, underpinning a critical speed–accuracy trade-off. The Alloc-MoE framework addresses this bottleneck by introducing a formal activation budget and optimizing expert selection both at the layer and token level to minimize accuracy degradation under tight computational constraints.
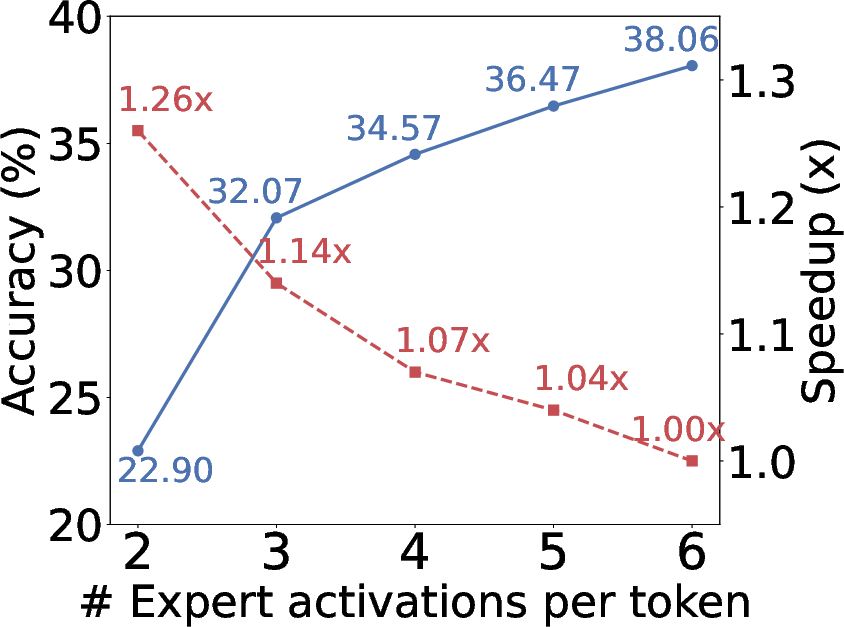
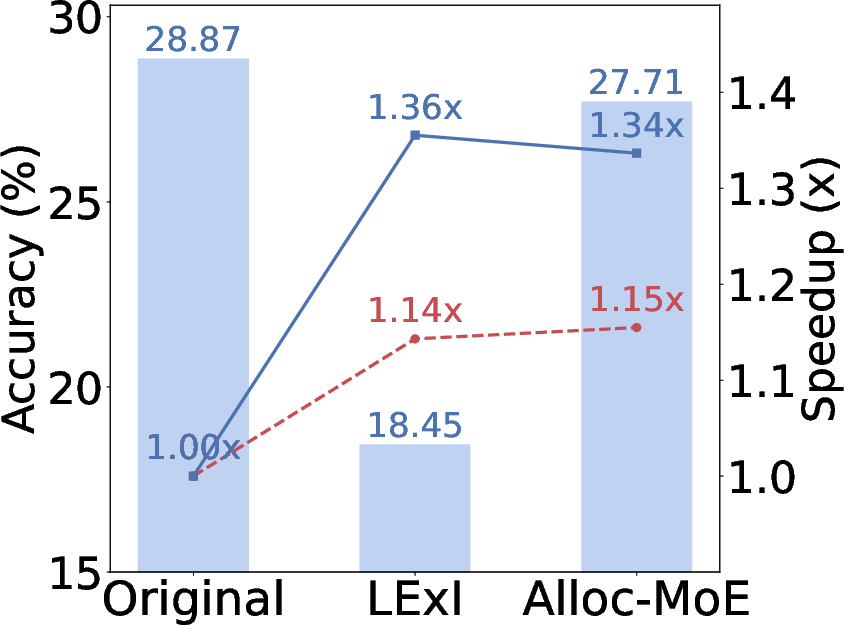
Figure 1: (a) Reducing expert activations per token yields speedup but degrades accuracy. (b) Alloc-MoE achieves comparable latency and near-original performance at half activation.
Alloc-MoE reframes the problem of MoE inference efficiency as a discrete constrained optimization task. It defines a global activation budget (aggregate expert activations per token across all MoE layers) and per-layer activation budgets (average number of expert activations assigned within each layer). The framework manipulates these quantities to minimize performance loss given a fixed allowance of activations, enabling consistent enforcement of latency/resource constraints.
The Alloc-MoE Framework
Alloc-MoE is structured as a two-stage allocation process, harnessed by Alloc-L (layer-level) and Alloc-T (token-level):
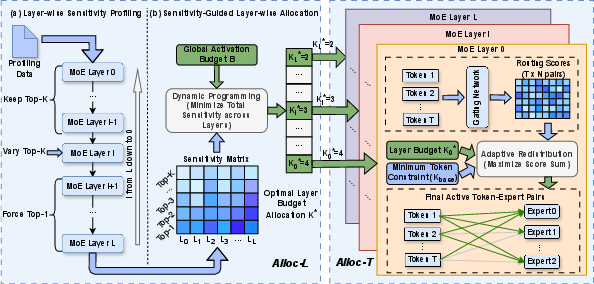
Figure 2: Alloc-MoE pipeline with sensitivity profiling via Alloc-L (left) and dynamic token-wise expert assignment via Alloc-T (right).
Alloc-L: Sensitivity-Aware Layer-Level Allocation
Alloc-L first conducts a model calibration phase to empirically profile the sensitivity of each MoE layer by measuring end-to-end perplexity changes when the number of activated experts is varied. It isolates each layer in turn, holding preceding layers fixed and subsequent layers at their minimal setting. The relative perplexity increments form a global sensitivity matrix, yielding a layer budget allocation problem analogous to a grouped knapsack. Dynamic programming is employed to obtain the optimal assignment of activation budgets across layers for a given global constraint.
Alloc-T: Token-Level Adaptive Routing
Within each MoE layer, Alloc-T further optimizes the allocation by leveraging routing scores. It adaptively redistributes a fixed activation pool across tokens, prioritizing ambiguous tokens—those with diffuse routing score entropy—so that more experts are assigned to tokens most likely to benefit from greater representational diversity. A per-token lower bound ensures robust routing, and the remaining activations are globally pooled and greedily allocated to maximize the sum of routing weights, incurring negligible computational overhead.
Experimental Evaluation
Alloc-MoE is evaluated on DeepSeek-V2-Lite, Qwen1.5-MoE-A2.7B, and OLMoE-1B-7B-0924 across three groups of benchmarks: NLU, reasoning, and math. For each model, a variety of increasingly restrictive budgets are tested to expose model robustness to aggressive sparsification. On DeepSeek-V2-Lite, Alloc-MoE outperforms layer- and token-reduction baselines in the majority of budget–task configurations, especially under the harshest constraints, showing improvements of up to 2.15% on aggregate math tasks.
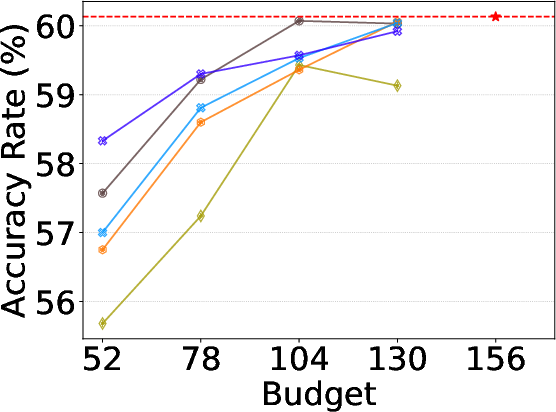
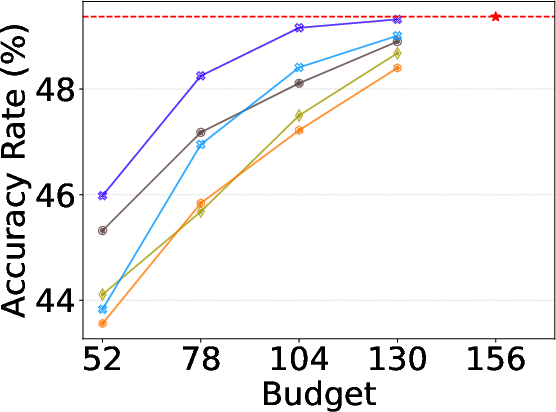
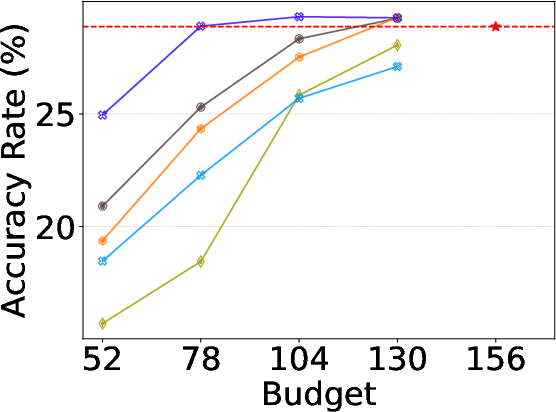
Figure 3: Task-specific performance under varying activation budgets on DeepSeek-V2-Lite. Alloc-MoE shows clear advantage as computational pressure increases.
Comparison ablations confirm that Alloc-L yields stronger accuracy than static layer reductions and that Alloc-T produces larger gains when token-level routing ambiguity is high, with their combination providing orthogonal, additive improvement.

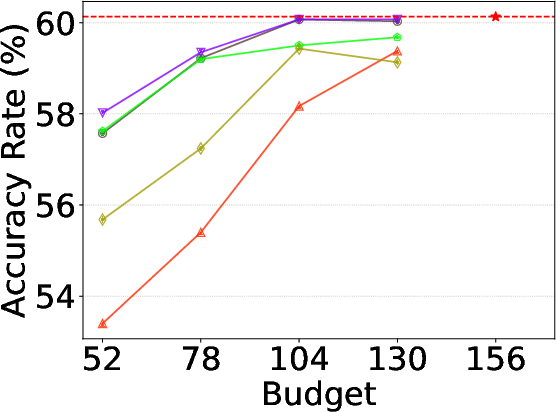
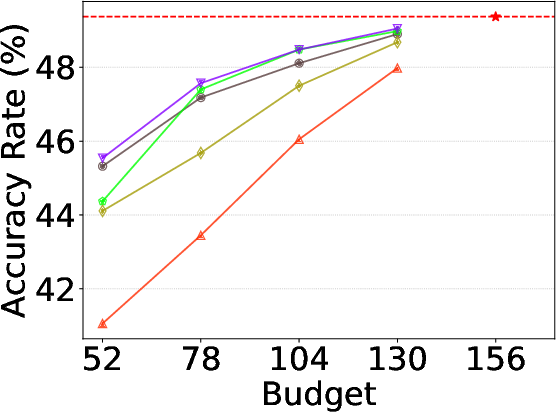
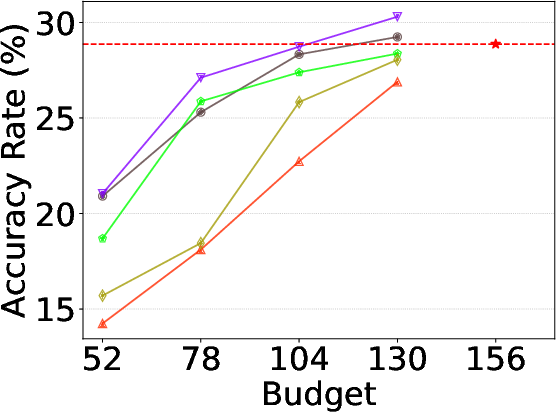
Figure 4: Alloc-L ablation on NLU, Reasoning, and Math—demonstrating superior accuracy across shrinking budgets.
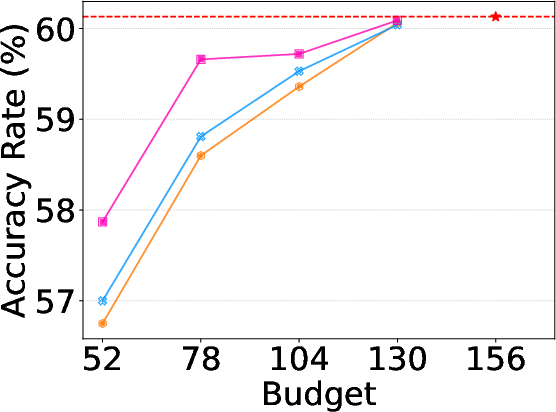
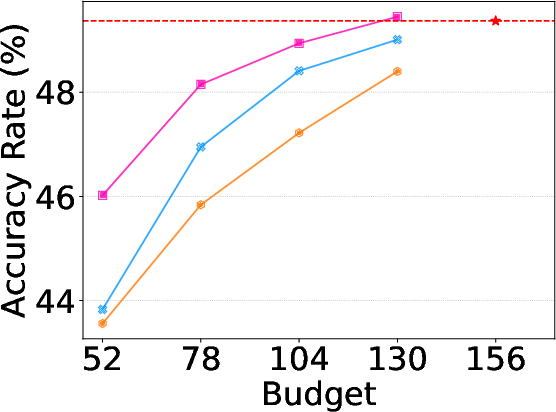
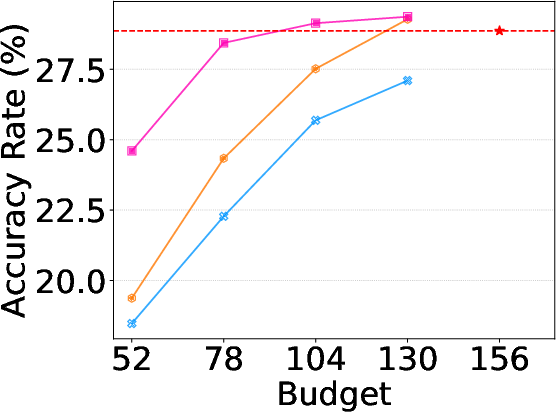
Figure 5: Alloc-T ablation highlights progressively stronger advantages as activation budgets are constrained, especially for more complex tasks.
Latency and Inference Speedup
Alloc-MoE introduces no runtime overhead compared to specialized reduction baselines. In aggressive sparsification scenarios (half-budget), Alloc-MoE achieves up to 1.34× speedup in typical decode regimes and 1.15× in prefill, attributed solely to the reduction of expensive expert feed-forward operations.
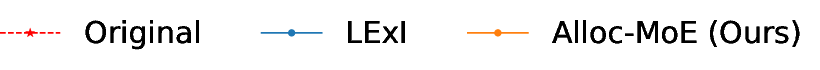
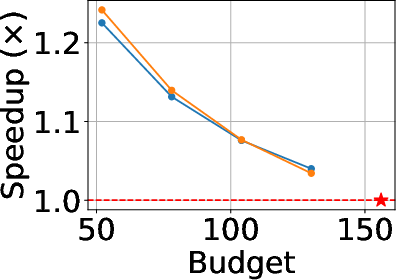
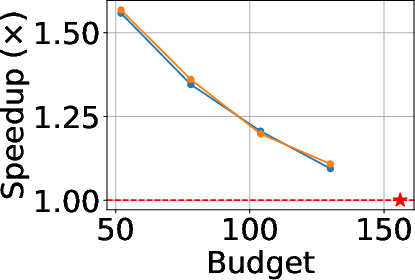
Figure 6: Inference speedup during prefill and decode for various global activation budgets.
Analysis of Expert Load Balance
Maintaining expert load balance across workers and devices is critical for distributed deployment. Alloc-MoE preserves the load rank (Spearman ρ > 0.93), exhibits minimal entropy and JS divergence shifts, and reduces individual expert load, which can lower communication and queuing penalties at scale.
Figure 7: Distribution of per-expert load confirms Alloc-MoE does not disrupt specialist assignment or induce imbalance.
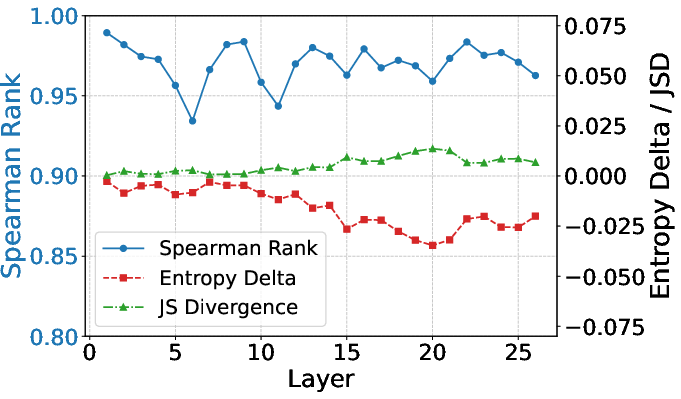
Figure 8: Metrics for load stability (Spearman, entropy difference, JS divergence) remain stable with Alloc-MoE.
Layer and Token-Level Allocation Patterns
Alloc-L generates non-uniform, data-driven layer allocations with earlier layers typically assigned higher budgets. Alloc-T exhibits a monotonic allocation increase with routing entropy; ambiguous tokens are preferentially upweighted in terms of expert count, confirming the utility of entropy as a proxy for representational need.
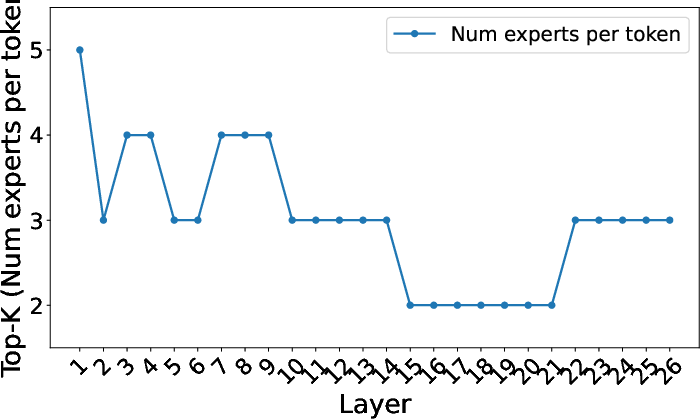
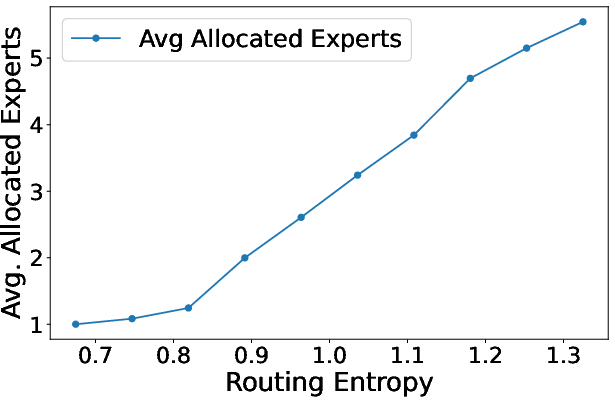
Figure 9: (a) Alloc-MoE’s non-uniform layer allocation at half-budget. (b) Token-wise expert allocation correlates with routing entropy.
Ablations and Robustness
Ablation studies on Qwen and OLMoE confirm the generality of the method: Alloc-L always outperforms static and heuristic layer assignments, and Alloc-T consistently outperforms token-level baselines under aggressive conditions. The framework’s calibration is robust to dataset choice, and token-level base allocations are best when minimal (Kbase=1).
Implications and Future Directions
Alloc-MoE formally unifies global, layer, and token-level sparsity mechanisms under a single budget-aware constrained optimization paradigm. The robustness of Alloc-MoE underpins its suitability for real-time and mobile deployment of large MoE models without retraining. Its layer- and token-agnostic allocation is amenable to further extensions involving multi-objective optimization, e.g., incorporating hardware topology, communication cost, or capacity constraints. Integrating Alloc-MoE into the training pipeline to enforce sparsity-aware routing could induce new regularities in expert utilization and robustness, meriting investigation.
Conclusion
Alloc-MoE delivers a principled, practical approach to efficient MoE inference by coordinating expert activation allocation at both layer and token granularity under an explicit activation budget. Experimental results across multiple MoE model families and diverse evaluation suites highlight its advantage in preserving model accuracy while enabling substantial cost savings and latency reduction in constrained environments.

