- The paper introduces CrashSight, a detailed VQA benchmark that segments crash events into distinct phases with expert-validated annotations for causal reasoning.
- The methodology employs a multi-stage pipeline combining VLM draft captioning, human expert refinement, and LLM-driven QA generation to ensure high annotation quality.
- Experimental results show that domain-specific fine-tuning of VLMs yields significant performance gains while exposing persistent challenges in visual perception and temporal alignment.
CrashSight: Phase-Aware, Infrastructure-Centric Video Benchmark for Traffic Crash Scene VQA
Motivation and Context
Infrastructure-centric perception is essential for Cooperative Autonomous Driving (CDA), offering a holistic understanding of traffic scenarios by integrating vehicle and roadside sensor data. While Vision-LLMs (VLMs) demonstrate general competency in video understanding, their performance in safety-critical, long-tail events such as roadway crashes—especially from infrastructure viewpoints—remains under-characterized. Existing benchmarks predominantly focus on ego-vehicle perspectives and lack the temporal structure, detailed annotation, and reasoning challenges required to robustly assess VLMs in these settings.
CrashSight directly addresses these deficiencies by introducing a large-scale, phase-aware VQA benchmark built from real-world roadside-camera crash footage, with detailed expert-validated annotations and a rich taxonomy of reasoning challenges. The benchmark is specifically tailored to evaluate VLMs' spatio-temporal, causal, and robustness reasoning abilities where the requirements for reliability, explainability, and hallucination resistance are exceptionally stringent.
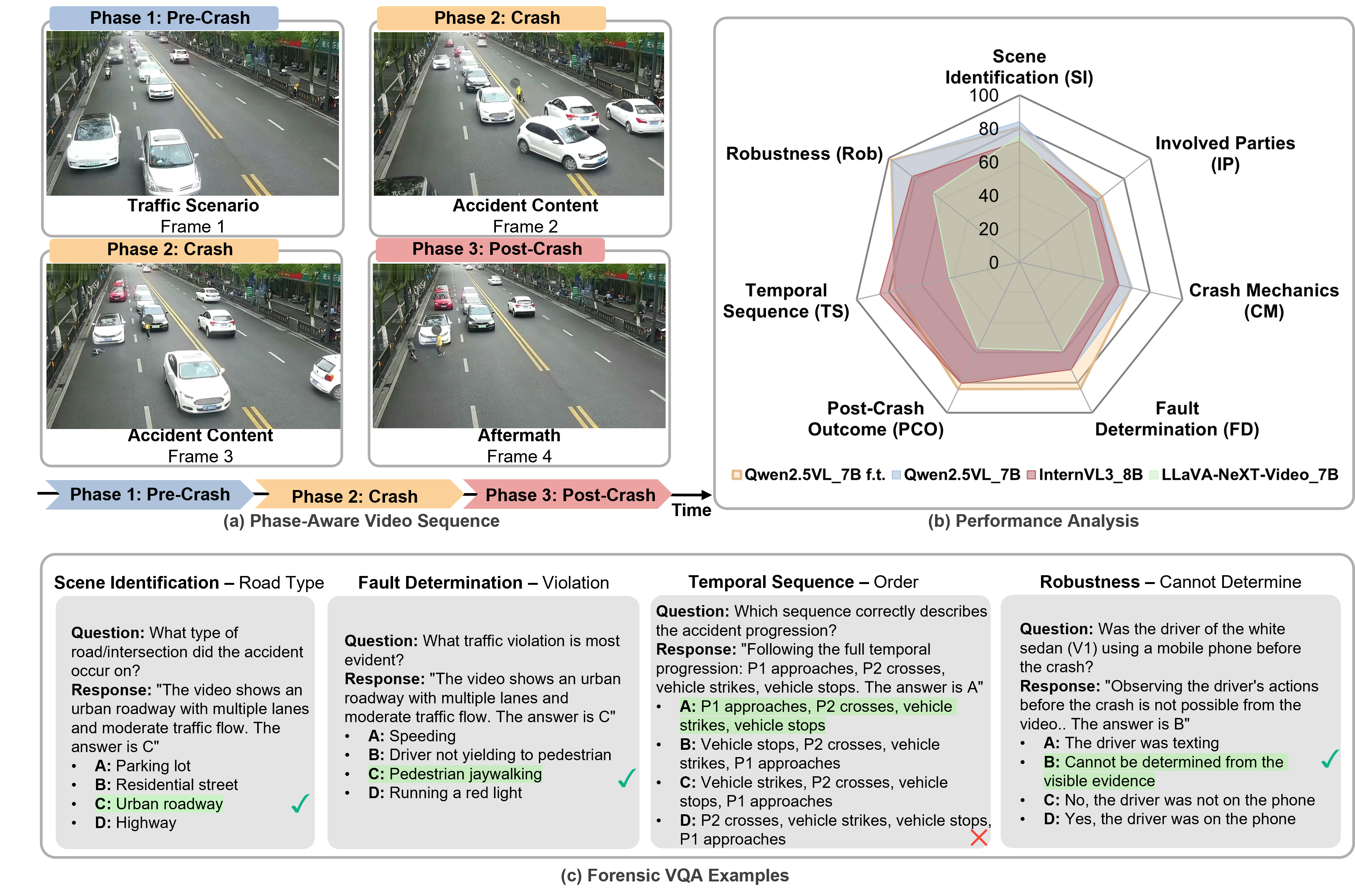
Figure 1: Overview of CrashSight-VQA; illustrates the temporal structure, model performance across QA categories, and representative qualitative QA cases spanning grounding and causality.
Dataset Design and Curation Pipeline
CrashSight comprises 250 surveillance videos, each segmented into four explicitly delineated phases—pre-crash context, collision dynamics, post-crash aftermath, and expert potential-cause assessment. This phase-aware organization underpins phase-grounded dense captioning and QA generation, enabling nuanced, temporally-localized reasoning tasks and accurate evaluation of VLM temporal understanding.
The dataset was generated via a multi-stage pipeline:
- VLM-assisted draft captioning: InternVL3-80B is prompted with structured templates capturing four crash phases; outputs are phase-delimited drafts.
- Human expert refinement: Trained annotators iteratively revise drafts in terms of entity specificity, spatial relations, phase boundaries, and causal attribution; ~90% of drafts require substantial correction.
- LLM-driven VQA generation and verification: QAs are authored and verified in two passes—first by prompt-structured LLMs producing answers and counterfactual distractors grounded in caption evidence, second by augmented LLM verification focused on evidence accuracy and linguistic diversity.
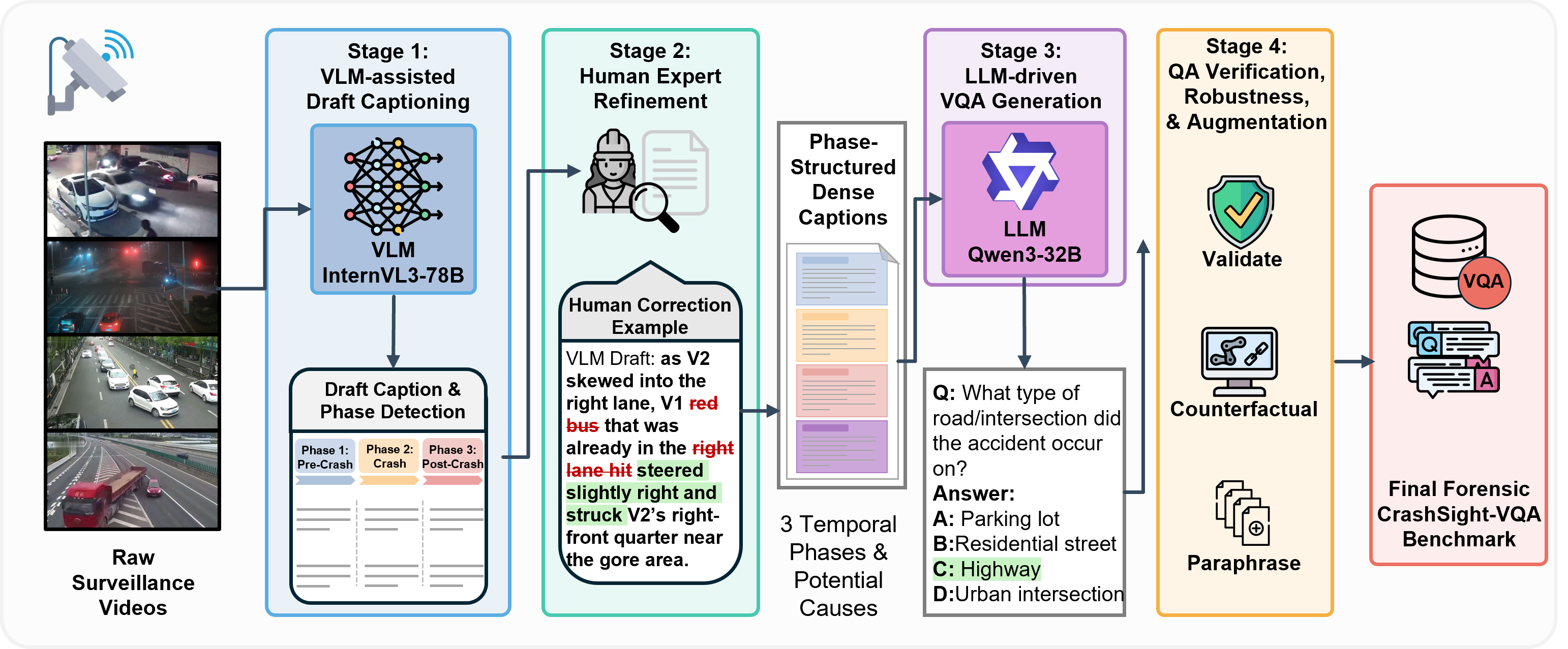
Figure 2: Pipeline schematic for dataset curation, integrating VLMs, expert review, and LLM-based QA/verification, highlighting the scale of human intervention required for quality.
QA Taxonomy
CrashSight comprises 13,016 multiple-choice QA pairs spanning seven categories:
- Tier 1: Crash Understanding (Phase-local, visual grounding)
- Scene Identification (SI): static context—road, lighting, weather
- Involved Parties (IP): entity and role identification, fine discrimination
- Post-Crash Outcome (PCO): aftermath states, emergency response markers
- Tier 2: Crash Reasoning (Cross-phase, causal/temporal integration)
- Crash Mechanics (CM): collision types, kinematics
- Fault Determination (FD): cause inference, violation labeling
- Temporal Sequence (TS): event ordering, cross-phase temporal logic
- Robustness: Four hallucination-probe subclasses requiring "cannot be determined" answers, testing resistance to evidence-less prediction.
Each question presents one gold answer and three category-appropriate counterfactual distractors, with robust shuffling to remove positional bias.
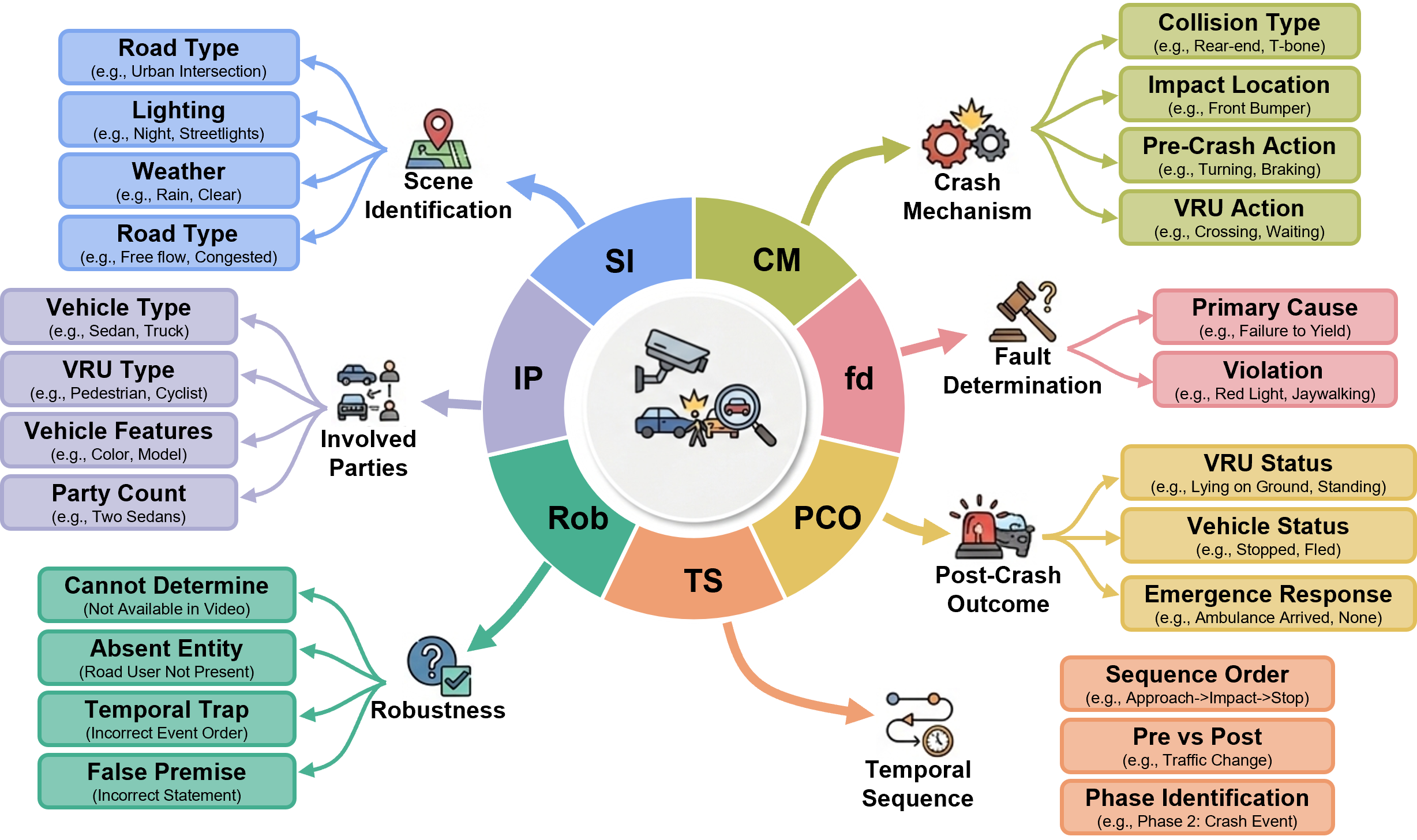
Figure 3: Taxonomy of question categories; crash understanding is phase-grounded, while reasoning requires cross-phase and causal inference. Robustness probes hallucination.
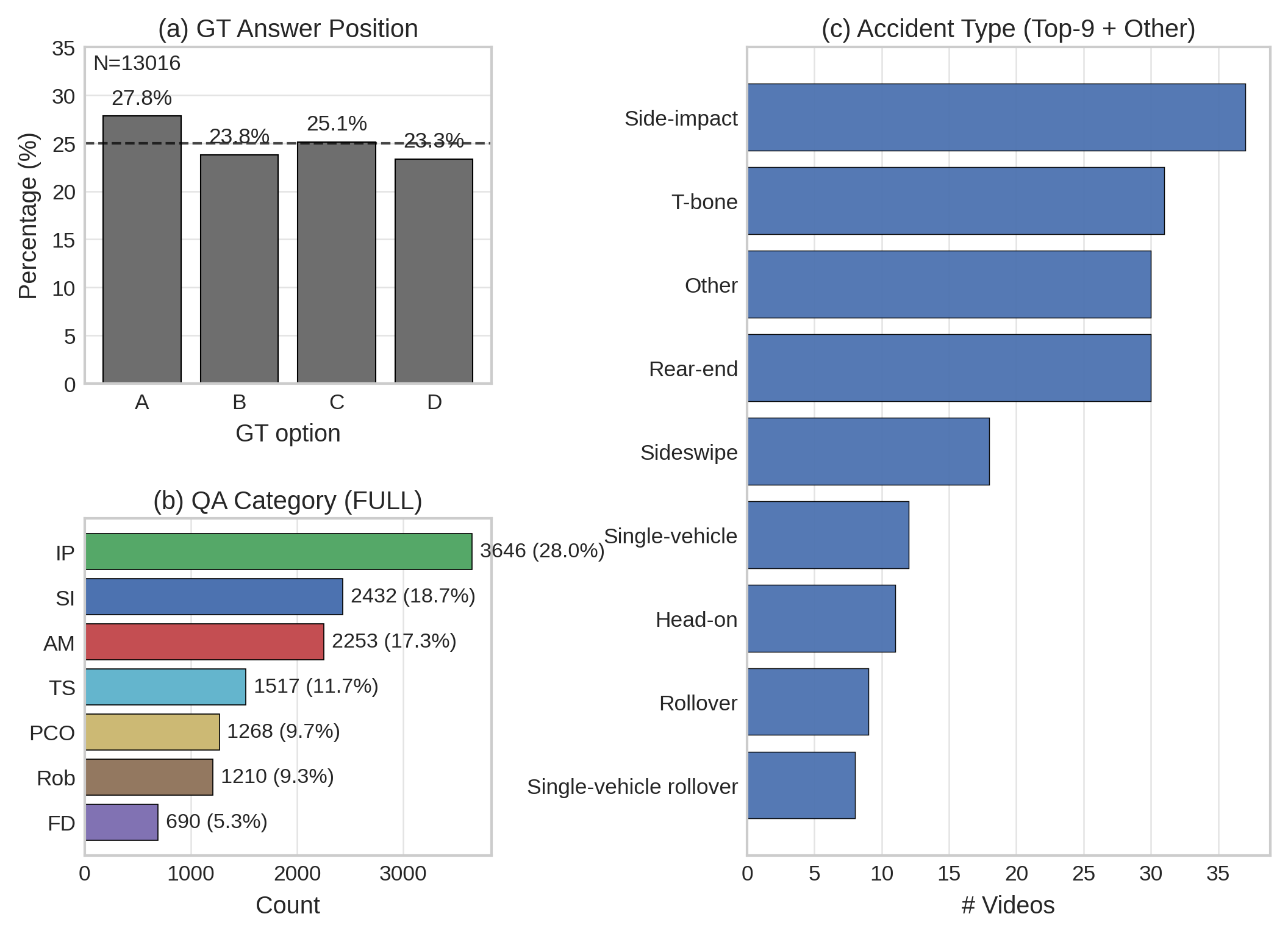
Figure 4: Dataset statistics across categories, answer option shuffling, and incident types.
Experimental Evaluation
Eight state-of-the-art VLMs across four major architectures are benchmarked in zero-shot and domain-finetuned configurations. Key findings include:
- Domain-specific fine-tuning yields substantial accuracy gains (+16.1 points for Qwen2.5-VL-3B, +13.5 for 7B), particularly in Robustness (+26.1) and Crash Mechanics (+17.3). Fine-tuned small models outperform larger zero-shot baselines.
- Architectural design trumps parameter scaling in zero-shot, with InternVL3-2B outperforming Qwen2.5-VL-7B.
- Category-level results show persistent human-AI gaps, especially for Involved Parties (best: 63.2% vs. human 94.7%) and Crash Mechanics, emphasizing the unsolved nature of fine-grained, visually grounded, and causal tasks.
- Systematic error taxonomy reveals that format-level and knowledge-level errors (static-image treatment, hallucination, refusal to answer, answer alignment) are largely solved by fine-tuning. However, core perception failures—spatial discrimination of entities under occlusion, temporal misalignment, and detailed accident reconstruction—persist, attributable to architectural limits (fixed token budget, quantization, frozen visual encoders).
Implications and Theoretical Considerations
CrashSight reveals that while prompt tuning and domain adaptation address instructional and reasoning format deficiencies, VLMs' core limitation in infrastructure-centric crash VQA is visual perception under severe information constraints—infrequent frame sampling, low spatial resolution, and surveillance-specific scene geometry. Scaling parameters alone is insufficient for tasks requiring small-entity discrimination or understanding of rapid, localized collision events common in roadside camera footage.
This benchmark underscores the need for:
- Architecture/data co-design: More adaptive frame sampling, event-driven video parsing, spatio-temporal and 3D-aware representation learning, and object tracking modules bespoke to traffic dynamics.
- Enhanced visual encoders and joint training: Overcoming quantization bottlenecks and exploring (partial) vision encoder fine-tuning or unlocked adapters targeted for surveillance configurations.
- More demanding evaluation formats: Beyond multiple-choice QA, including structured multi-turn interaction, explicit explanation, and evidence consistency verification to advance the state of explainable and reliable infrastructure perception.
CrashSight also highlights annotation challenges: expert review remains non-trivial to scale, especially for fine-grained phase and causality delineation, limiting the expansion of such benchmarks. Greater automation will demand more robust VLMs and agentic LLM workflows that can reliably align with domain expert standards.
Future Directions
Research enabled by CrashSight may facilitate the design of VLMs with improved crash cognition and causal reasoning critical for CDA and post-incident assessment. Expanding datasets to wider camera conditions and rare edge-cases, integrating auxiliary sensor modalities, and exploring richer QA and scene captioning schemas are all promising trajectories. Ultimately, the infrastructure-centric VQA paradigm will be crucial for safer, fully realized cooperative autonomy and for improved forensic, regulatory, and management use-cases in intelligent transportation.
Conclusion
CrashSight introduces rigorous standards for phase-aware, infrastructure-vantage crash understanding, exposing core limitations in current VLM architectures. While model adaptation, fine-tuning, and advanced prompt engineering yield tangible improvements in reasoning task alignment and hallucination resistance, fundamental visual perception and temporal alignment deficiencies remain unresolved. Progress in surveillance-based crash understanding will depend on bridging this gap through architectural innovation, high-fidelity data regimes, and the development of robust, scalable annotation and evaluation workflows.
(2604.08457)