- The paper introduces a theoretical framework connecting model capacity (2-bits-per-parameter) with factual memorization using mutual information.
- It presents loss-based pruning strategies (LossH and LossHF) to adaptively control data redundancy and flatten fact frequency distributions.
- Empirical results on synthetic and Wikipedia datasets demonstrate that optimal pruning enables small models to achieve factual accuracy comparable to much larger models.
Cram Less to Fit More: The Impact of Training Data Pruning on Factual Memorization in LLMs
Introduction and Motivation
The memorization of factual knowledge within the parametric weights of LLMs is crucial for their performance on closed-book question answering and knowledge-intensive tasks. Despite the scale of contemporary LLMs, empirical results show that models often underperform in memorizing rare or long-tail facts, presenting limitations in factual accuracy even with substantial increases in model size. This suboptimality raises a fundamental question: is the bottleneck in fact accuracy an inherent consequence of model capacity, or does it result from a mismatch between data distributions and model architecture during training?
This work formalizes fact memorization from an information-theoretic perspective, deriving new connections between the model's capacity (as measured in bits/parameter) and its ability to memorize independent facts. It demonstrates that in scenarios where the entropy of the training data's factual content exceeds the model's memorization capacity, factual accuracy falls significantly below the theoretical optimum, especially under non-uniform, power-law fact frequency distributions.
Capacity Limits and Fact Memorization
The authors introduce a principled notion of “fact memorization” by framing knowledge as deterministic mappings over world parameters and quantifying the mutual information between the model parameters and these mappings. By establishing the connection between memorization and capacity—specifically, the 2-bits-per-parameter limit for Transformer models—an upper bound on the expected number of memorized independent facts of entropy b is derived:
E[Acc-Cnt]≤bln∣W∣+Nln2
where ∣W∣ is the effective parameter space of the model, and N is the number of facts.
Experimental results on synthetic datasets constructed to precisely control the fact entropy and distribution validate this theoretical upper bound. When the number of distinct facts presented exceeds the effective encoding capacity of the model, observed factual accuracy collapses, even if the model is sufficiently trained to minimize the overall loss (Figure 1).
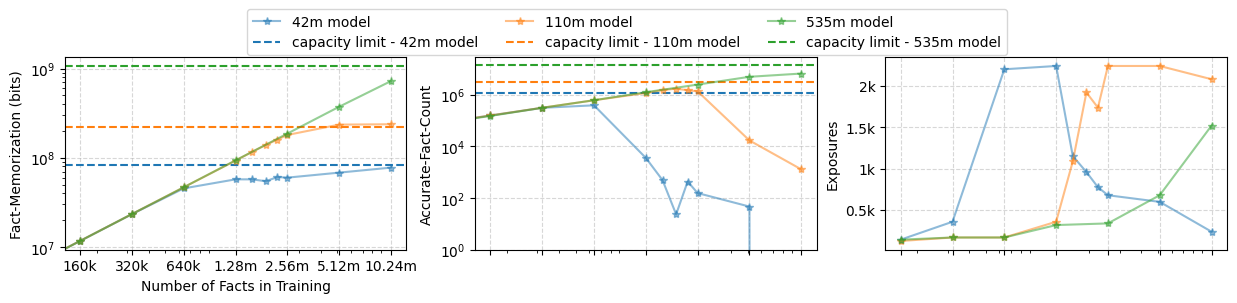
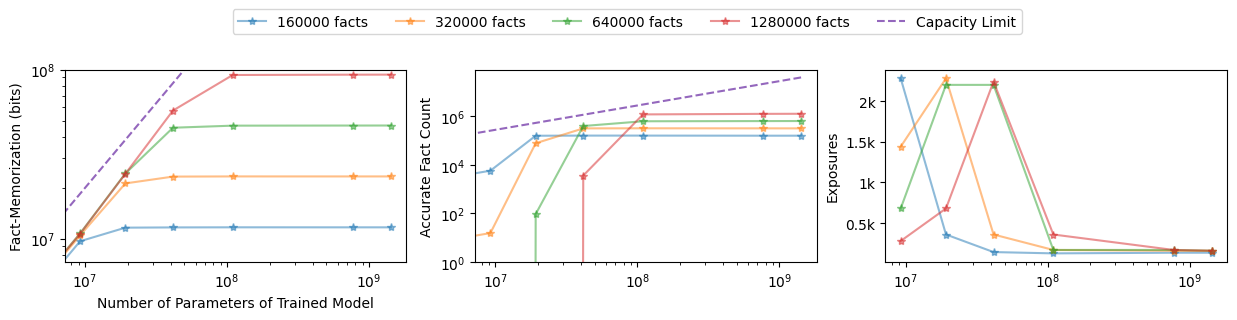
Figure 2: Fact memorization (bits), fact accuracy (accurate fact count), and exposures to convergence, showcasing the strict capacity boundary where accuracy collapses as fact count exceeds capacity.
Long-tail, power-law distributions further exacerbate this phenomenon: as the skew in fact frequency increases, factual accuracy achievable by models of fixed size declines sharply, demonstrating a direct empirical correlation between data distribution entropy and memorization outcomes.
Loss-Based Data Selection: From Principle to Practice
Building upon these insights, the paper proposes data selection mechanisms that adaptively prune the training data to both control the number of distinct facts and flatten their frequency distribution, thus aligning the dataset entropy with available capacity. The innovation lies in leveraging the training loss of individual data samples—as a proxy for redundancy and rarity—to dynamically subselect records at the fact level.
Two selection variants are developed:
- LossH (Head): Selects the lowest-loss (most “memorized” or redundant) facts up to the model's theoretical memorization capacity.
- LossHF (Head-Flattened): Adds an explicit step to down-weight or sub-sample facts with excessive frequency, aiming for a more uniform exposure distribution.
Empirical evaluation on synthetic datasets demonstrates that these loss-based selections are nearly optimal, achieving factual accuracy closely matching the theoretical capacity, even under adversarial (long-tailed) distributions.
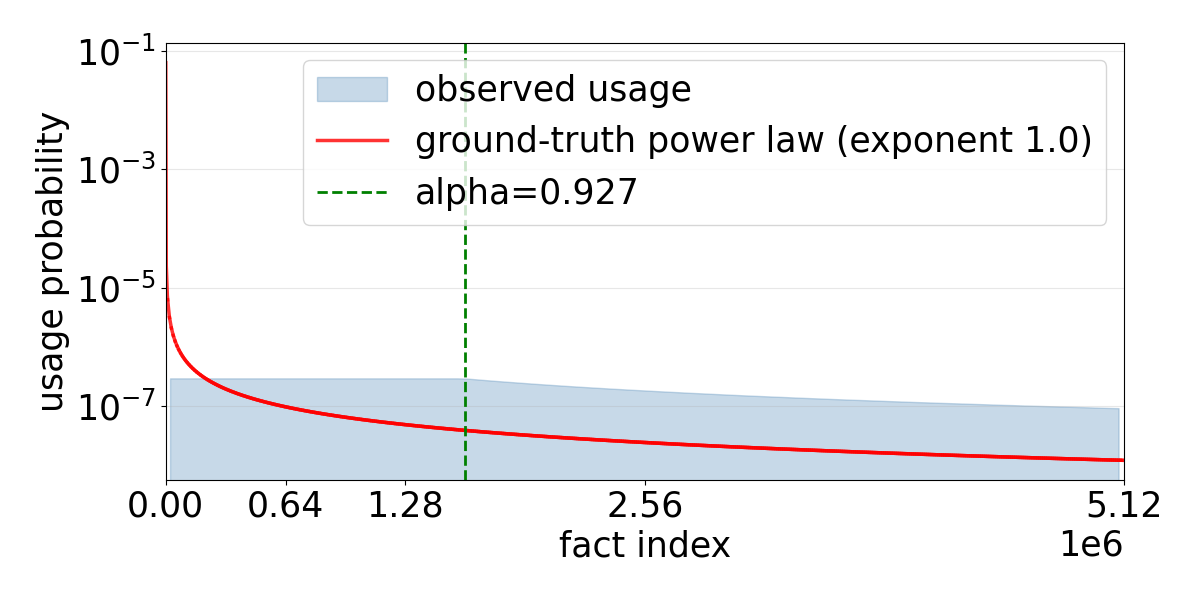
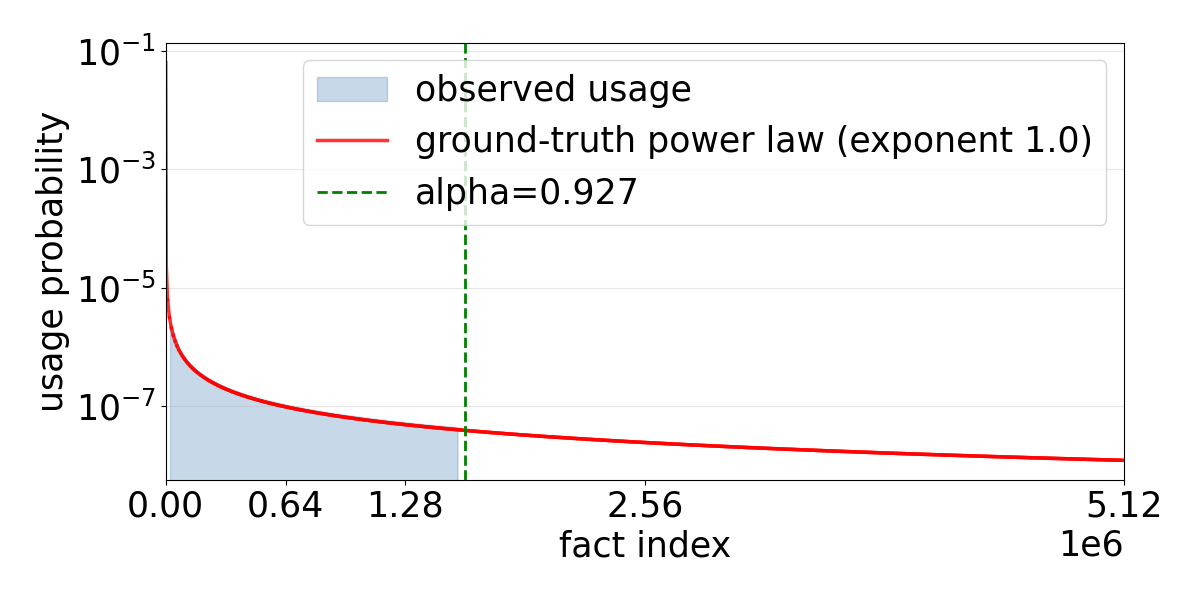
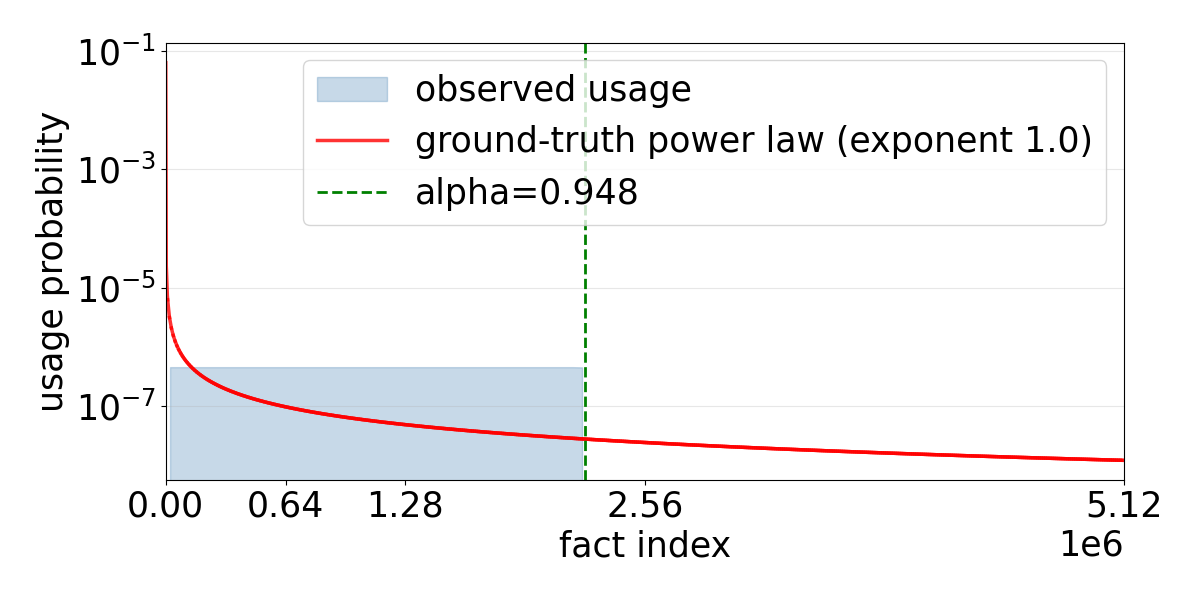
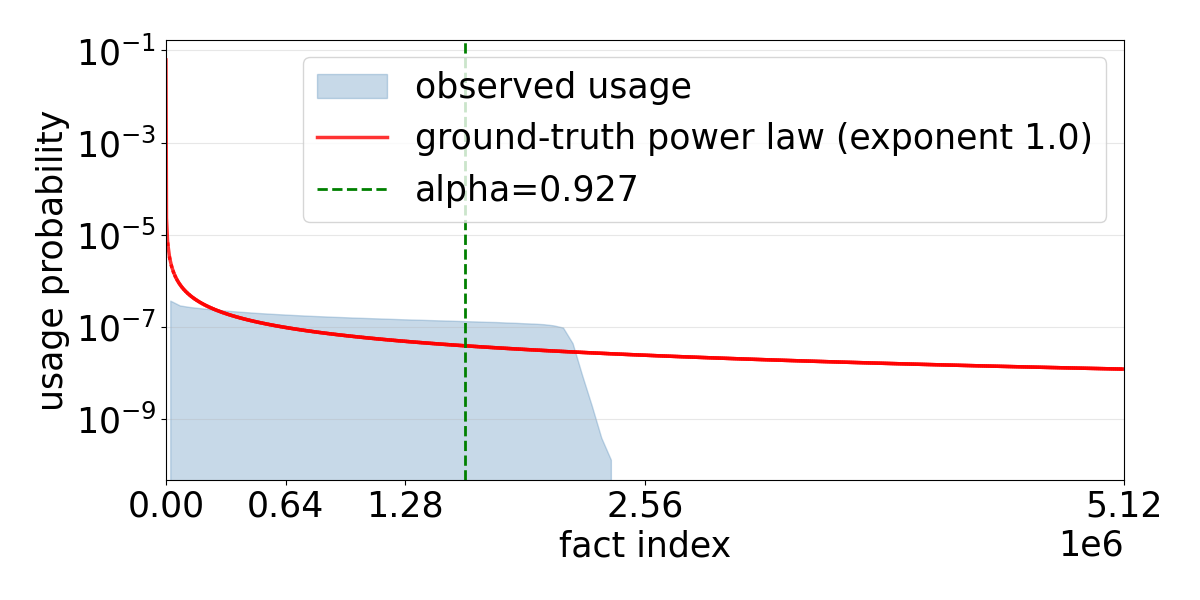
Figure 4: Comparison of data usage histograms under different selection algorithms, emphasizing how head-flattened selection achieves a near-uniform fact distribution.
Scaling to Real-World Corpora: Wikipedia Pretraining
To assess applicability beyond synthetic settings, the methodology is applied to pretraining on a fact-annotated Wikipedia corpus. By segmenting facts within naturally occurring documents and applying the loss-based selection strategy at the fact level, dramatic improvements are demonstrated.
Key findings include:
- For a GPT2-Small model (110M parameters), pruning the training corpus to an optimal 20% selection ratio yields a 1.3x increase in factual accuracy on out-of-distribution test facts compared to full-dataset training, closely matching the performance of a 10x larger (1.3B parameter) model trained on the complete dataset.
- Downstream knowledge-intensive benchmarks show corroborating gains, while general NLU capabilities remain unaffected across a range of selection ratios, evidencing that factual accuracy can be decoupled from broad language competence under these schemes.
Contrasts and Implications
One contradictory claim challenged by these results is the assertion that only exponential increases in model scale (e.g., 1020 parameters for full Wikipedia memorization) can suffice for human-level fact accuracy. The work shows that judicious data pruning enables small models to match or exceed the factual accuracy of much larger baselines, shifting the limiting factor to data curation rather than mere scale.
This rebalancing of priorities has substantial implications:
- Model Efficiency: Training smaller models to optimal factual accuracy reduces computational costs and environmental impact, providing a path toward sustainable scaling.
- Practices in Corpora Design: Data deduplication and random pruning are insufficient; loss-guided, capacity-aware fact pruning is essential for small model performance.
- Theoretical Foundations: The mutual information perspective provides a rigorous handle for relating data curation, model architecture, and factual generalization in LLMs.
Future Directions
Several open problems are highlighted, including:
- Addressing catastrophic forgetting when memorizing new facts sequentially (e.g., in transfer or continual learning).
- Extending fact-level selection to data without explicit annotation or clear fact boundaries, possibly through lightweight automatic annotation pipelines.
- Integrating data selection with architectural advances (MoE, sparse memories) or in conjunction with retrieval-augmented models to improve the joint efficiency of parametric and non-parametric memory systems.
Conclusion
This work provides a firm theoretical and empirical case that suboptimal factual accuracy in LLMs arises not from fundamental capacity limitations alone but from mismatched data-to-capacity ratios—particularly where redundant and rare facts are intermixed. Training data pruning, grounded in loss-based fact selection and judicious frequency flattening, achieves near-capacity factual accuracy for small models and eliminates the previously observed shortfalls under power-law fact distributions. This perspective realigns future progress in high-fidelity factual language modeling toward principled data curation and opens several promising directions for both efficient model development and deeper understanding of memorization phenomena in neural architectures.