- The paper introduces an anchor-based decoding strategy that detects token stability via historical predictive distributions, significantly reducing block-boundary delays.
- It employs an exponentially-weighted KL divergence across a historical buffer to robustly differentiate stable tokens from transient oscillations.
- Empirical results demonstrate up to 80% reduction in decoding steps and multimodal performance gains, establishing AHD as a scalable, model-agnostic efficiency enhancer.
Anchor-based History-Stable Decoding for Diffusion LLMs: Breaking Block Boundaries
Introduction and Motivation
Diffusion LLMs (dLLMs) have become a major alternative to autoregressive models, offering high-quality text generation through iterative denoising with bidirectional attention mechanisms. However, despite significant acceleration strategies, semi-autoregressive (Semi-AR) decoding remains the dominant inference paradigm and exhibits a pronounced bottleneck: block-boundary-induced delays. Blockwise sequential decoding precludes immediate decoding of tokens that have already reached stable states, especially those spanning block boundaries, leading to redundant computation, elevated latency, and impaired performance coherence.
The paper "Breaking Block Boundaries: Anchor-based History-stable Decoding for Diffusion LLMs" (2604.08964) addresses this inefficiency by analyzing token stability and introducing a novel Anchor-based History-stable Decoding (AHD) strategy. AHD leverages the historical trajectory of token predictions to robustly detect when tokens reach an absolute stability trend, enabling early cross-block decoding and optimizing both efficiency and output quality.
Analysis of Semi-AR Decoding Bottlenecks
Comprehensive empirical analysis reveals two central issues. First, many tokens stabilize well before their designated block is eligible for decoding, resulting in a block-boundary delay that wastes numerous decoding steps. Second, the onset of token stability often exhibits radiative effects—stable tokens tend to accelerate stabilization in their neighborhoods, which, if not decoded promptly, can suppress local inference and degrade overall performance.
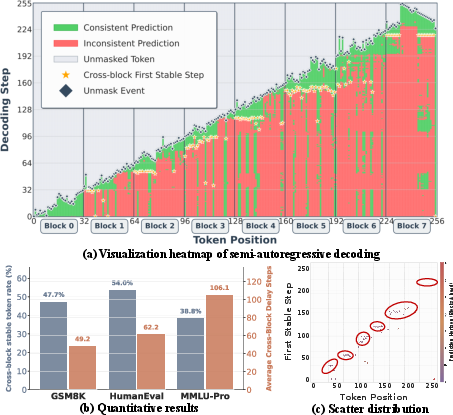
Figure 1: Systematic analysis of Semi-AR decoding on dLLMs, including temporal visualization of stability onset and quantification of unnecessary decoding delays across benchmarks.
Moreover, token stability, as tracked via per-step confidence metrics or entropy, is frequently obfuscated by local fluctuations even after the token has effectively converged (Figure 2). Thus, naive lookahead or single-step confidence-based acceleration strategies are insufficient, as they either misjudge early stability or artificially delay unlock decisions to avoid potential errors.
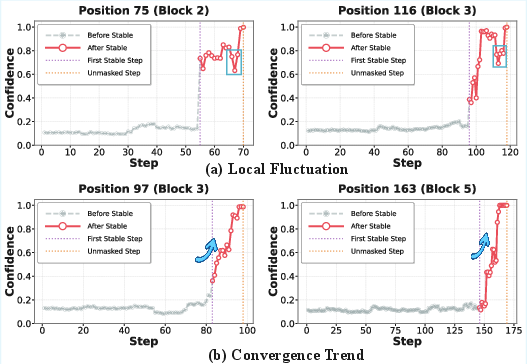
Figure 2: Token confidence dynamics during decoding; local fluctuations persist beyond the genuine stability point, challenging naive decoding acceleration approaches.
Standard iterative decoding in dLLMs further exacerbates the issue by isolating each step’s predictions—history is discarded, and only the last prediction dictates the output. This prevents the model from robustly exploiting global stability signals observable in historical prediction trajectories.
The Anchor-based History-stable Decoding (AHD) Algorithm
AHD directly addresses these challenges with a historical consistency framework. At each decoding step, for every token in the future (yet-to-be-decoded) block, AHD constructs a historical buffer of recent predictive distributions and designates the present step as a dynamic anchor. It then calculates an exponentially-weighted, anchor-based KL divergence across this history window to quantify consistency:
Djt(acs)=τ=1∑H−1wτDKL(Pj,anchort∣∣Pjt−τ)
where H is the buffer length and λ controls the decay of weights wτ. A token is deemed stable and eligible for cross-block decoding if this aggregate score drops below a tunable threshold ϵ. This approach sharply distinguishes consistent convergence (absolute stability) from transient local oscillations and mitigates both delayed unlocking and premature commitment errors.
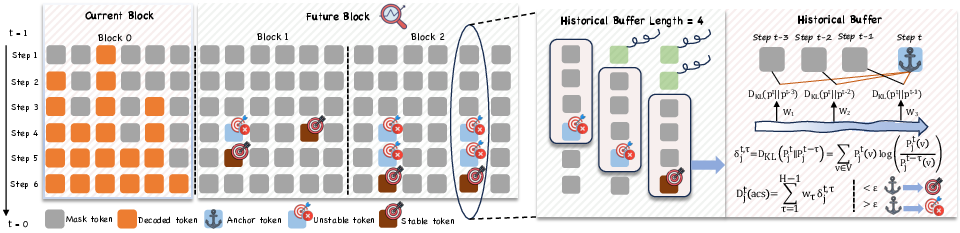
Figure 3: AHD architecture highlighting the retrospective tracking of token trajectories from dynamic anchor points, enabling early and robust cross-block unlocking via stability trend monitoring.
Unlike single-step or stepwise-anchored methods (e.g., KLASS), AHD’s anchor mechanism grounds stability in global recent history, providing both higher sensitivity to convergence trends and robustness against long-range fluctuations.
Empirical Results
Extensive experiments were conducted on state-of-the-art dLLMs (LLaDA-8B-Instruct, LLaDA-1.5) in language, vision-language, and audio-language settings across a comprehensive suite of benchmarks. Key findings include:
- Performance-efficiency dominance: AHD consistently achieves simultaneous improvements in decoding step reduction (up to 80% on BBH) and benchmark scores (up to +3.67 points), outperforming all prior advanced decoding strategies, which typically incurred performance trade-offs.
- Multimodal robustness: AHD preserved or improved performance across multimodal datasets (e.g., MathVista, ScienceQA) and yielded significant speedups (up to 16.4× on GQA).
- Scalability to long sequences: Unlike previous methods, AHD maintains its advantages with long output sequences (up to 1024 tokens or more), with step reductions and performance gains becoming even more pronounced as sequence length grows.
Notably, ablation studies substantiate the impact of historical window length and the threshold parameter ϵ, demonstrating that AHD provides a tunable trade-off between aggressiveness and reliability. The additional computational overhead is negligible relative to dLLM inference, as the required logits are already computed for all positions per step.

Figure 4: (a) Computational complexity analysis highlighting minimal overhead of AHD; (b) tradeoff study varying ϵ; (c) impact of history buffer length.
Case studies illustrate that AHD not only accelerates inference but also prevents errors incumbent to delayed or misaligned blockwise decoding, thus enhancing both accuracy and sample quality.
Theoretical Properties
The authors provide a theoretical analysis showing that the anchor-based KL consistency score tightly controls the deviation of the current probability distribution and its semantic embedding from the recent historical mean. This formalizes the anchoring mechanism’s ability to capture trajectory-level convergence and filter out single-step noise, filling a crucial gap left by prevailing per-step heuristics.
Implications and Future Directions
AHD sets a new standard for inference in dLLMs, showing that block boundaries are not an inherent limitation but an addressable artifact of current decoding protocols. By systematically integrating historical prediction trends and introducing anchor-based retrospective monitoring, AHD offers a training-free, model-agnostic mechanism for both efficiency and quality enhancement.
Practically, this positions dLLMs as highly competitive, even at large scale and in diverse modalities, for deployment scenarios where latency, throughput, and output coherence are all critical. Theoretically, the anchor-based approach may stimulate further research into trajectory-level dynamics in iterative generative models, potentially influencing design across modalities.
Open challenges remain in optimal hyperparameter adaptation (e.g., per-task tuning of ϵ and H) and verification on even larger models (≫8B), as well as enhanced vectorization and integration with advanced caching paradigms.
Conclusion
Anchor-based History-stable Decoding (AHD) for dLLMs redefines fast, high-quality text and multimodal generation by breaking artificial block boundaries through global, trajectory-based stability assessment. Combining theoretical rigor and robust empirical validation, AHD demonstrates substantial step reductions and performance improvements across benchmarks, providing a clear blueprint for next-generation decoding strategies. This work crystallizes the importance of historical consistency and trend-aware inference in diffusion generative modeling.

