- The paper introduces GeoSkill, a training-free framework that leverages an evolving Skill-Graph to enable interpretable visual geo-localization.
- It employs a four-stage pipeline combining expert-distilled skills, online inference, and autonomous evolution to enhance spatial accuracy and reasoning traceability.
- Empirical results demonstrate state-of-the-art performance with high F1 scores and robust, auditable inference without any parametric model updates.
Skill-Conditioned Visual Geolocation for Vision-LLMs: An Expert Analysis
Introduction and Motivation
The visual geo-localization task—predicting precise Earth coordinates from images—demands not only high performance, but explicit, auditable geographic reasoning under complex, ambiguous scenarios. Traditional neural paradigms, from feature-based retrieval to LVLM-based inference and recent agentic web-augmented methods, exhibit insufficient interpretability, suffer from semantic hallucinations, and lack mechanisms for autonomous self-improvement. The paper "Skill-Conditioned Visual Geolocation for Vision-LLMs" (2604.09025) introduces GeoSkill, a training-free geo-localization framework that leverages an evolving Skill-Graph composed of atomic, interpretable skills distilled from human expertise, with a closed-loop autonomous evolution mechanism for continual, verifiable augmentation (Figure 1).
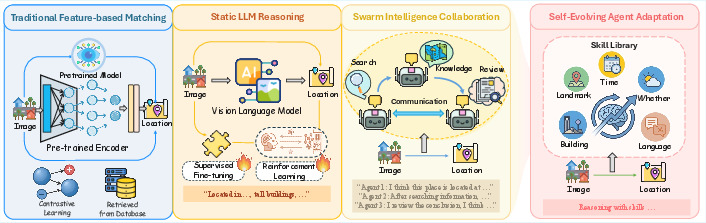
Figure 1: The evolution of geo-localization approaches culminating in GeoSkill, which uniquely features an evolving Skill-Graph enabling self-improving geographic reasoning via feedback loops.
GeoSkill Framework Architecture
GeoSkill is instantiated through a four-stage pipeline (Figure 2):
- Offline Skill Library Initialization: Structured trajectories from domain experts are decomposed into atomic, natural-language skills, each capturing a minimal geospatial heuristic with reliability metadata, forming an initial Skill-Graph.
- Online Inference and Rollout: Given a query image, visual cues are parsed, relevant skills retrieved using hybrid retrieval (BM25 + dense embeddings), and dynamically composed into an instance-specific reasoning graph. The model reasons via a coarse-to-fine process, with all claims both visually and skill-grounded, yielding traceable localization outputs.
- Offline Logging and Validation: Reasoning traces and outcomes are logged, externally validated, and stored for subsequent feedback-driven refinement.
- Offline Skill-Graph Updating: Using high-capacity models, failed and successful inference records are mined; new skills are synthesized, existing ones merged or pruned, and relational structure refined—without any parametric model updates.
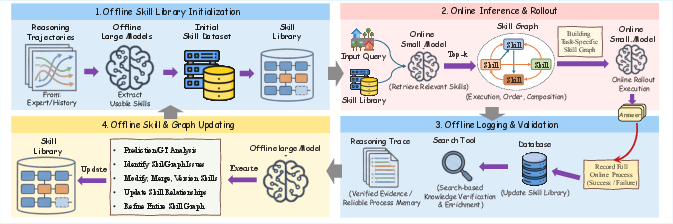
Figure 2: Workflow of GeoSkill, from expert trajectory distillation to online inference, validation, and autonomous Skill-Graph evolution.
This architecture enforces dual evidentiary constraints on all inferences, promotes logical faithfulness, and encourages the emergence of verifiable novel skills through symbolic memory optimization.
Hallucination-Resistant Skill Initialization
One critical innovation of GeoSkill is its bootstrapping phase: skills are distilled from human expert trajectories rather than LVLM generations, circumventing known initialization-stage hallucination cascades. Expert traces (e.g., GeoGuessr champion playbooks) are parsed and mapped to atomic, auditable skill triplets (⟨K,H,v⟩). All skills are tagged with linguistic certainty-derived reliability scores and mapped to geographical applicability, ensuring both initial asset quality and coverage diversity. Failed or brittle expert traces are also documented for negative evidence initialization, improving error signal diversity during early evolution.
Online Skill-Conditioned Inference
GeoSkill’s inference relies on strategic composition of retrieved skills. Scene parsing translates raw visual evidence into attribute representations, dramatically improving retrieval relevance. Skills are assembled into a directed reasoning graph that mirrors expert deduction, enforcing hierarchical logic and precise visual-claim alignments. Inference outputs include a full, evidence-grounded chain supporting each spatial prediction—a robust mechanism for damping nonsense speculation and supporting real-time auditing.
Autonomous Knowledge Evolution
GeoSkill’s self-improving loop fundamentally redefines geo-localization agent learning. Rather than gradient-based RL, logical evolution is achieved by symbolic synthesis, merging, and pruning of skills and relations. Systematic diagnosis of failed rollouts, inspiration from RL’s pass@k, and algorithmic repair of the Skill-Graph demonstrably increase reasoning coverage and logical precision, while filtering hallucination-prone patterns. Crucially, this process is decoupled from model scale: new skills are type-checked, externally validated, and remain reusable across multiple backbones.
Empirical Results and Analysis
Geolocation Accuracy and Robustness
On three challenging benchmarks (Im2GPS 3k, EarthWhere, GeoRC), GeoSkill achieves superior or competitive accuracy versus SOTA LVLMs and agentic systems, particularly excelling on benchmarks requiring transparent, multi-stage reasoning and deep world knowledge (strong results at regional and country-level thresholds). Notably, inference is achieved entirely without parameter updates, underscoring the effectiveness of its knowledge-centric design.
Reasoning Faithfulness
GeoSkill routinely leads in reasoning faithfulness, achieving the highest F1 (60.31) on GeoRC, substantially outperforming models prone to “right-answer-wrong-logic” hallucinations. The explicit skill-claim traceability enforced by the Skill-Graph architecture underpins these gains.
Evolution Dynamics
Autonomous evolution iteratively translates outcome feedback into higher-quality skill repositories. Initial expansion (from 1,080 to 1,500+ skills) drives steep gains in both spatial accuracy and faithfulness; subsequent consolidation through merging/pruning maintains or raises overall metrics while reducing redundancy. This non-monotonic graph growth empirically parallels RL’s logical trajectory optimization, but with symbolically auditable updates.
Ablation and Parameter Sensitivity
Ablations confirm the criticality of skill conditioning and hierarchical planning: removing or shuffling skills sharply degrades both accuracy and interpretability. Multi-step rollout analysis reveals that increased rollouts improve both metrics, at a runtime cost—highlighting practical trade-offs for real-time applications.
Interpretability: Case Study
A detailed Andorra case (Figure 3) illustrates how GeoSkill integrates highly specific cues—including terrain, signage, linguistic markers—traverses multiple logical hypotheses, and is robust to misleading cues via graph consensus, disambiguating locale precisely and verifiably.
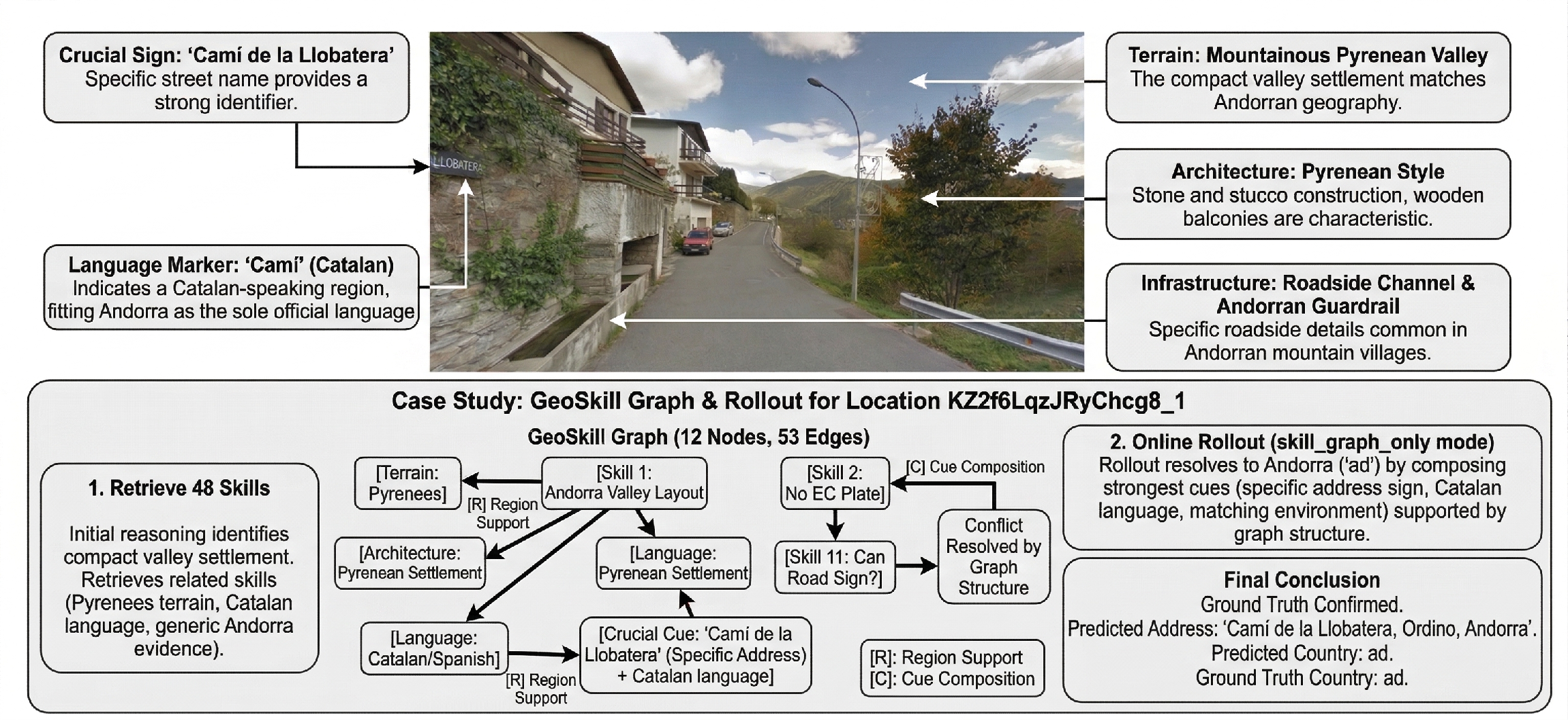
Figure 3: Case study showing GeoSkill's reasoning process from visual cues through Skill-Graph traversal to final, auditable prediction.
Sensitivity and Efficiency Analysis
Experiments on the rollout parameter reveal a consistent monotonic improvement in both geolocation precision and logical faithfulness with more rollouts, with execution time scaling linearly. In practical deployments, a moderate rollout count offers an efficient balance between accuracy and computational budget.
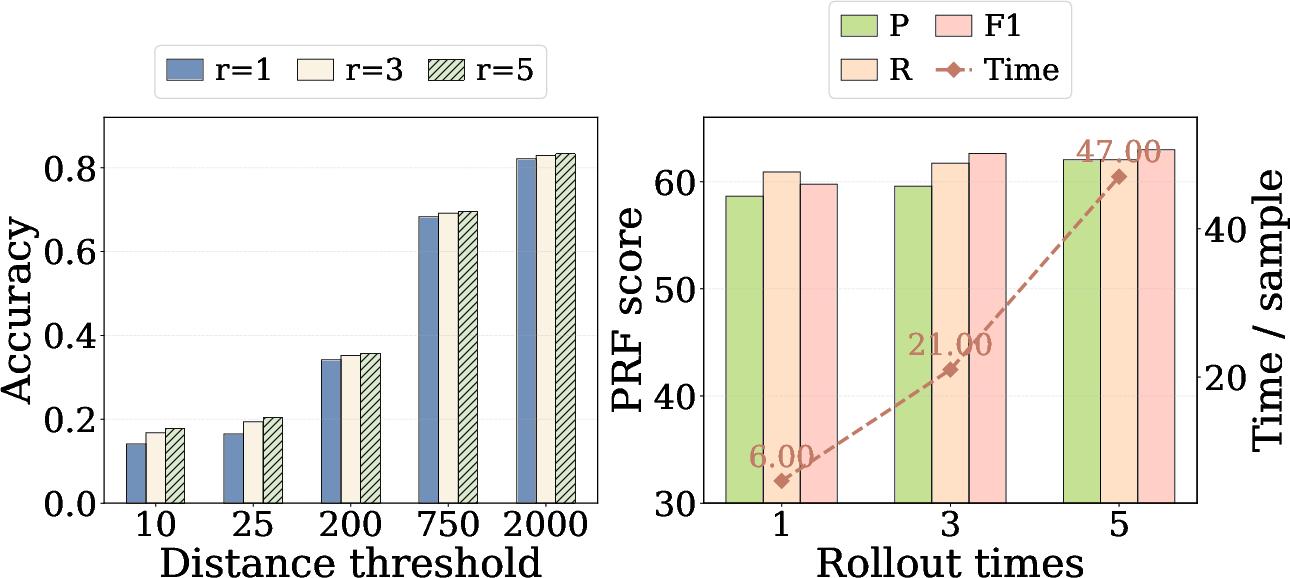
Figure 4: Multi-step rollout sensitivity: increasing inference steps boosts accuracy and faithfulness but increases runtime.
Implications and Future Directions
GeoSkill’s architecture advances geo-localization in two principal directions: moving from static parametric or agentic models to explicitly structured, evolving knowledge graphs; and from task-specific, monolithic reasoning to modular, auditable, transferable skill-driven pipelines. Practically, this enables robust, interpretable geographic inference at scale, with a straightforward path to customizing or transferring skill libraries across domains or agent backbones. Theoretically, GeoSkill offers a concrete instantiation of symbolic RL concepts in a high-dimensional perception domain.
Areas poised for further exploration include finer disentanglement of skills and knowledge for transfer learning, multimodal and cross-lingual retrieval mechanisms for more granular cue fusion, and interactive human-in-the-loop evolution protocols.
Conclusion
GeoSkill demonstrates that self-evolving, explicitly skill-conditioned reasoning frameworks can not only match but surpass traditional parametric and agentic models in both accuracy and interpretability for visual geo-localization. By formalizing geographic knowledge as a dynamic, auditable Skill-Graph, and employing rigorous autonomous evolution with outcome-grounded updates, the framework eliminates persistent reliability gaps and unlocks new avenues for scalable, trustworthy vision-language agents.