- The paper introduces SFGS, a pipeline that integrates structural priors with fine-grained Gaussian splatting to enhance expressive avatar reconstruction.
- The paper leverages a hierarchical approach combining SMPL-X and MANO refinements to address reconstruction errors in non-rigid regions like hands and faces.
- The paper demonstrates improved temporal coherence and photorealism with real-time performance, validated by superior SSIM, PSNR, and Chamfer Distance metrics.
Structure-Aware Fine-Grained Gaussian Splatting for Expressive Avatar Reconstruction
Introduction
Monocular video-based reconstruction of expressive, animatable human avatars continues to challenge the limits of current computer vision and graphics algorithms, especially when targeting photorealism, anatomical correctness, and rich fidelity in dynamic regions including hands and facial details. The paper "Structure-Aware Fine-Grained Gaussian Splatting for Expressive Avatar Reconstruction" (2604.09324) presents Structure-aware Fine-grained Gaussian Splatting (SFGS), an enhanced 3DGS-based pipeline that integrates structural priors, pose-conditioned geometric and appearance modeling, and fine-grained modules for hand rectification. SFGS is specifically engineered to deliver temporally coherent, per-frame free-viewpoint renderings of expressive avatars from unconstrained monocular input.
Limitations of Classical Human Gaussian Splatting
Former human Gaussian splatting approaches have demonstrated utility for body-scale geometry but characteristically fail to resolve excess error in articulated, non-rigid regions, most notably the hands and facial features, due to the lack of local pose-conditioned modeling and constrained mesh topology.

Figure 1: Classical human Gaussian splatting produces noticeable errors in highly non-rigid regions, with maximal reconstruction errors concentrated in the hands.
These deficiencies significantly limit the capacity for fine motion capture and the realism required in AR/VR telepresence or animation editing.
SFGS Pipeline Architecture
SFGS employs a canonical-to-posed approach. It initializes 3D Gaussian distributions over an upsampled canonical mesh—parameterized with SMPL-X—and fuses information from both triplane (static spatial) and hexplane (temporally aware) encodings for each point. An MLP-based modulation computes object-specific offset, scale, and color. Critically, a structure-aware offset module introduces pose dependency by weighting offsets according to dominant joints, and a hand-specific MANO refinement module is added for detailed hand geometry capture.
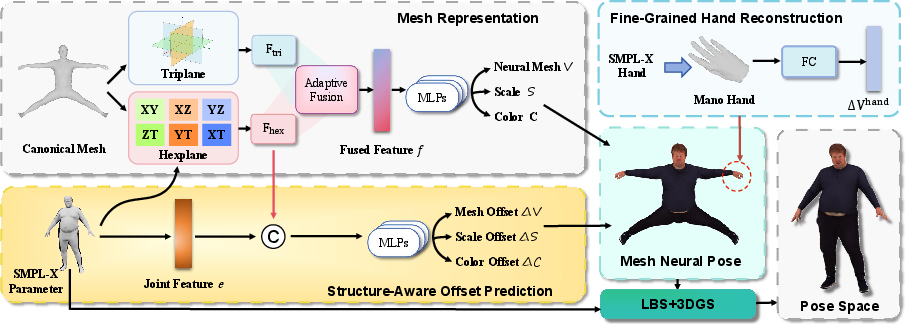
Figure 2: SFGS system overview: mesh sampling, HexPlane/Triplane-encoded feature extraction, pose-aware and part-aware correction, and rendering with Gaussian Splatting.
The HexPlane embedding, by including temporal context, substantially ameliorates temporal coherency and corrects motion-induced flicker. The structure-aware offset module, leveraging the SMPL-X kinematic hierarchy, provides per-Gaussian correction guided by local pose and joint association, replacing global linear models with fine-grained, anatomically plausible deformations.
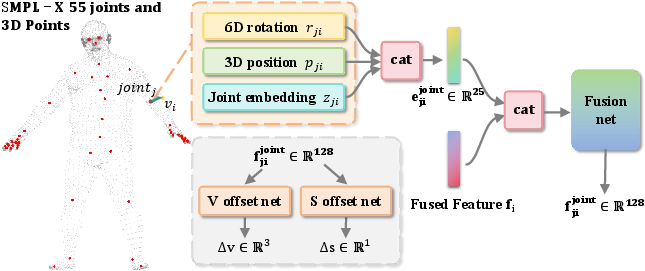
Figure 3: Each Gaussian’s offset and scaling are controlled via a joint-aware feature derived from SMPL-X, facilitating region-specific pose-driven deformations.
Advances in Fine-Grained Modeling
Unlike mesh-driven or voxel-based representations, SFGS assigns each Gaussian a principal influencing joint (from SMPL-X) according to the skinning weight. For hand regions, the pipeline transitions to MANO topology, allowing MANO-derived mesh residuals to be applied to SMPL-X hand vertices and further refined with a hand-pose-conditioned MLP. This hierarchical design is necessary to resolve inconsistencies and artifacts prevalent in the hands when only generic body models are used.
Representation Fusion and Temporal Consistency
The adaptive fusion of Triplane and HexPlane features is key to balancing spatial and temporal information. The temporal HexPlane embedding, when ablated, is shown to induce flicker and degrade perceptual metrics such as PSNR and LPIPS, whereas the combined embedding enables temporally consistent outputs.
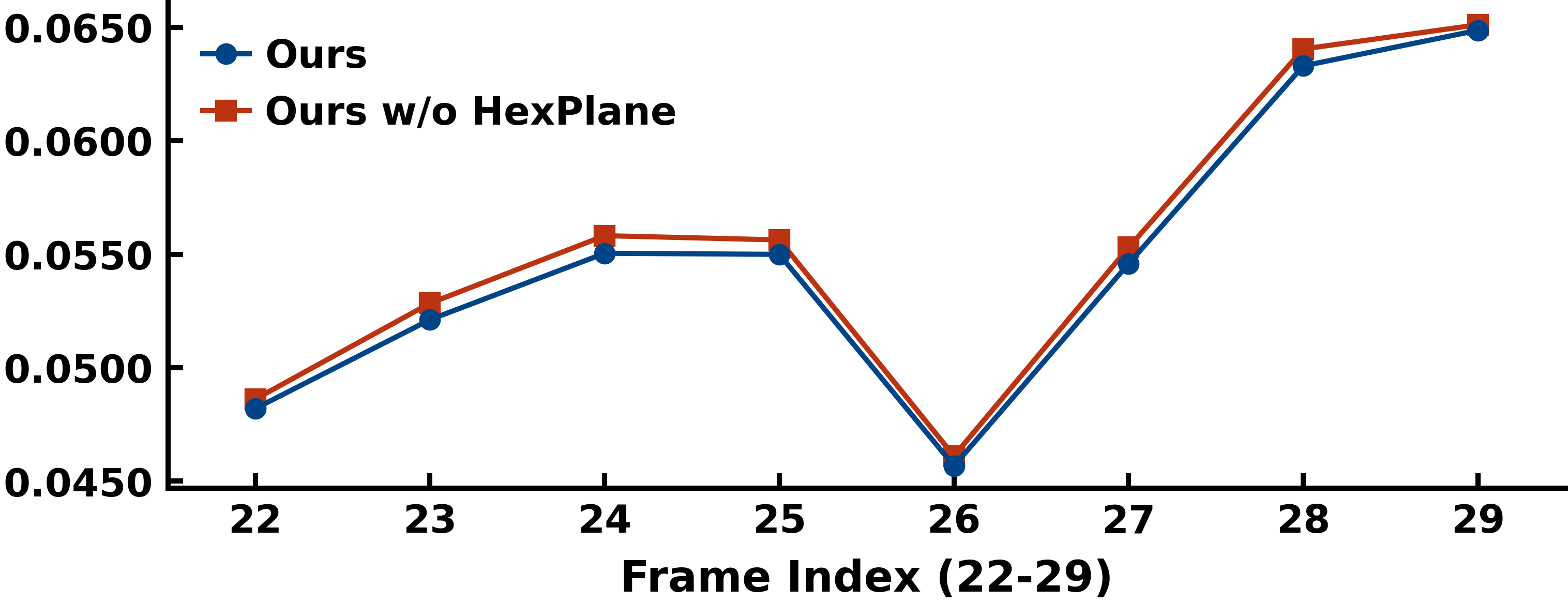
Figure 4: HexPlane dramatically reduces temporal LPIPS, indicating improved visual stability across frames.
Empirical Results
SFGS demonstrates consistently improved photorealism, geometric accuracy, and fine-feature reconstruction across public benchmarks, outperforming ExAvatar, HUGS, and other 3DGS-driven baselines. On the Neuman and X-Humans datasets, SFGS yields improvements in SSIM, PSNR, and Chamfer Distance for hands and faces, with ablation showing distinct contributions from each architectural component.

Figure 5: On Neuman, SFGS surpasses other methods, especially in the visual clarity of the hands and face, closely matching the ground truth.
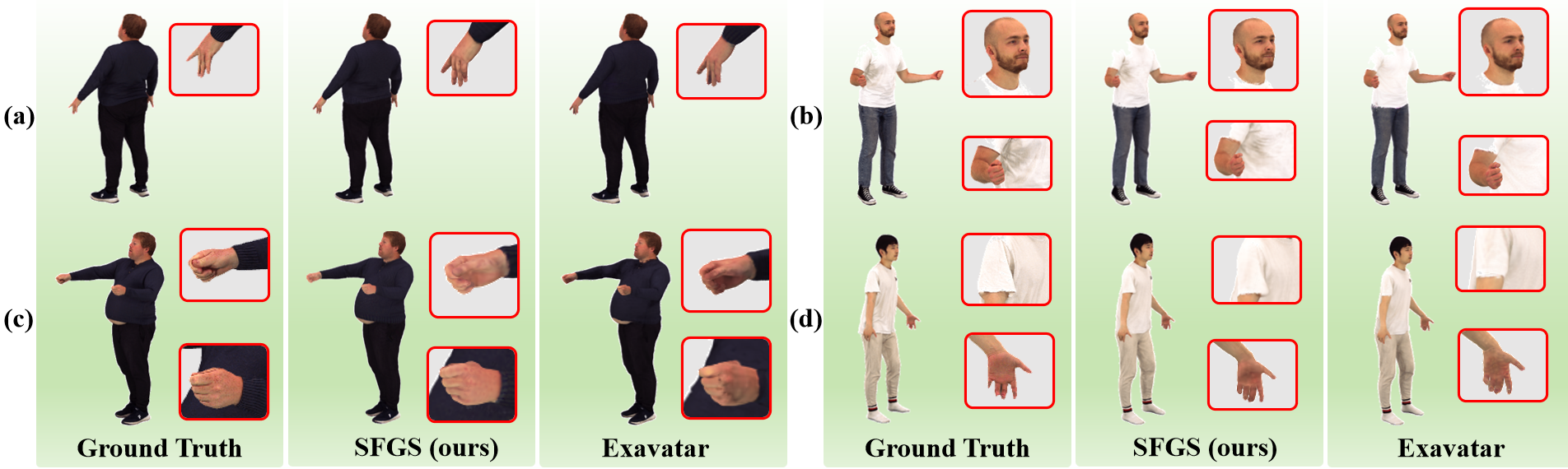
Figure 6: For X-Humans data, SFGS consistently surpasses ExAvatar on nuanced details, shadow reproduction, and preservation of small parts.
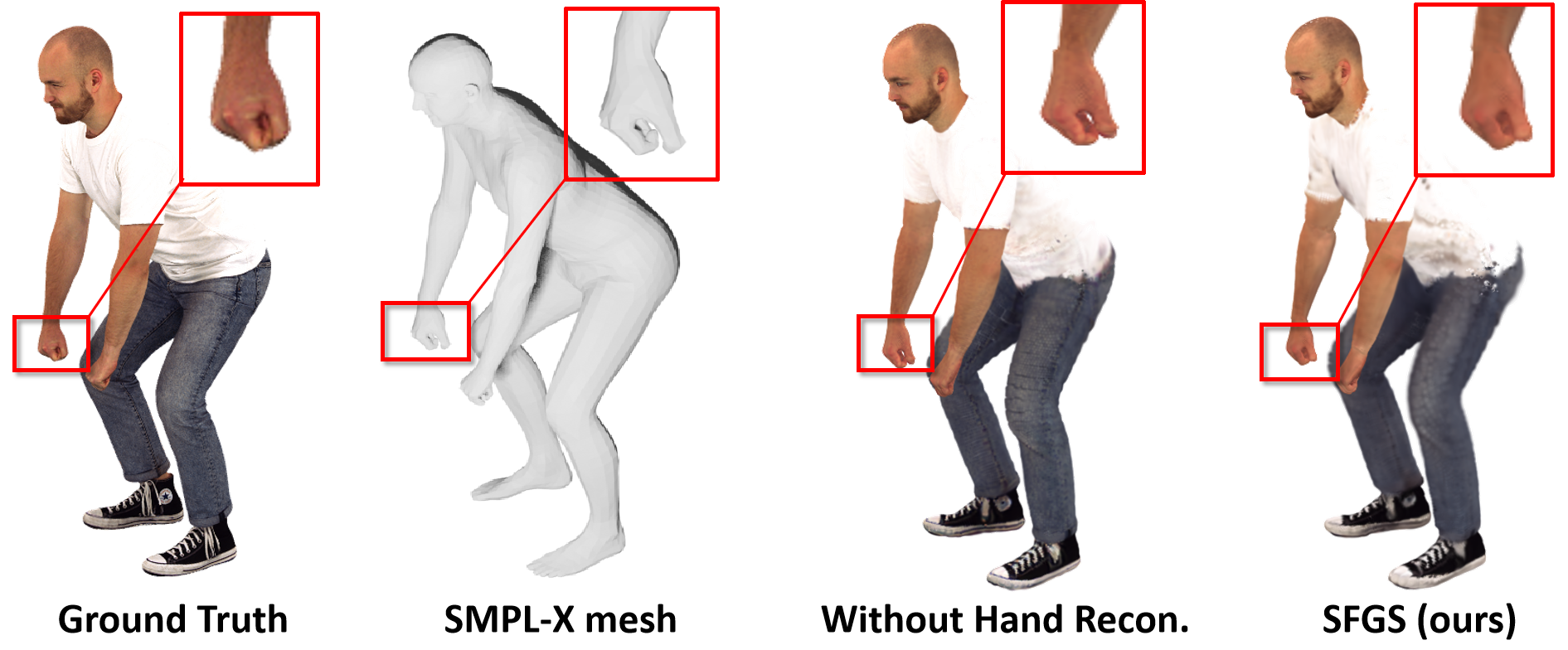
Figure 7: With fine-grained hand refinement, SFGS corrects SMPL-X-induced hand artifacts, achieving anatomically realistic hand renderings.

Figure 8: Structure-aware color offset aligns fine tone and texture, accurately reproducing skin detail and surface variation in the rendered avatar.

Figure 9: Structure offset improves the reconstruction of the mouth, with better fine-feature alignment than baseline structure-agnostic approaches.
SFGS also achieves real-time rendering speeds (30 FPS at 800×1200, RTX 4090), surpassing previous 3DGS methods and supporting practical deployment.
Implications and Future Directions
The SFGS methodology marks a notable advance in high-fidelity, expressive human avatar rendering from monocular signals. The direct association of Gaussians to anatomical joints and the part-specific MANO refinement set the stage for scalable, edit-friendly avatar systems that maintain high anatomical accuracy across varying articulations and challenging motion scenarios.
The singularization of fine-grained, part-aware corrections (especially for the hands) addresses a persistent deficiency in human digitization systems, directly impacting applications in telepresence, motion analysis, animation blending, and digital actor creation. The ability to render avatars with both anatomical consistency and temporal coherence facilitates downstream tasks such as retargeting, interactive editing, and real-time interaction with plausible expressiveness.
Future research may expand the point density or adaptive upsampling to better address topologically challenging regions (such as elaborate garments or body types with broad geometry) and leverage sketch, text, or multimodal input for motion control or conditional generation, integrating with developments in generative and diffusion models.
Conclusion
SFGS presents a comprehensive, anatomically and structurally grounded approach to monocular human avatar reconstruction. By leveraging pose-aware deformation, HexPlane temporal conditioning, and specialized hand refinement, it establishes a pipeline for the production of photorealistic, expressive, and temporally coherent avatars with real-time performance. Its improvements in fine-detail recovery and per-part accuracy have clear implications for interactive applications and further study in controllable, generalizable avatar modeling (2604.09324).

