- The paper introduces RecaLLM, which integrates explicit recall spans to mitigate the lost-in-thought issue in long-context reasoning.
- It employs efficient logit masking and fine-grained RL to balance answer quality and retrieval fidelity even over extended context windows.
- Experimental results on benchmarks like RULER and HELMET show significant improvements, achieving state-of-the-art performance up to 128K tokens.
RecaLLM: Explicit In-Context Retrieval for Robust Long-Context Reasoning
Introduction and Motivation
Despite advances in extending the context windows of LLMs, a persistent challenge remains: models rarely utilize long-context information effectively, especially when reasoning chains intermingle relevant and distractor tokens. Empirical evidence demonstrates a pronounced "lost-in-thought" effect, where reasoning—although necessary for task completion—actually degrades subsequent in-context retrieval fidelity (Figure 1). This phenomenon persists across architectures and scales, characterized by models hallucinating values even after the correct retrieval key has been reasoned out (Figure 2).
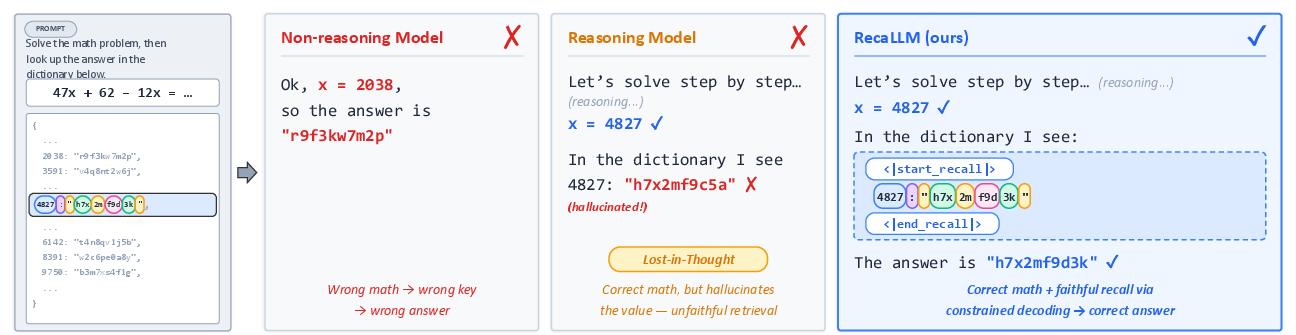
Figure 1: The lost-in-thought problem—after accurate reasoning about a key, models often hallucinate or fail to retrieve the correct value, which RecaLLM mitigates by explicit, faithful recall spans.
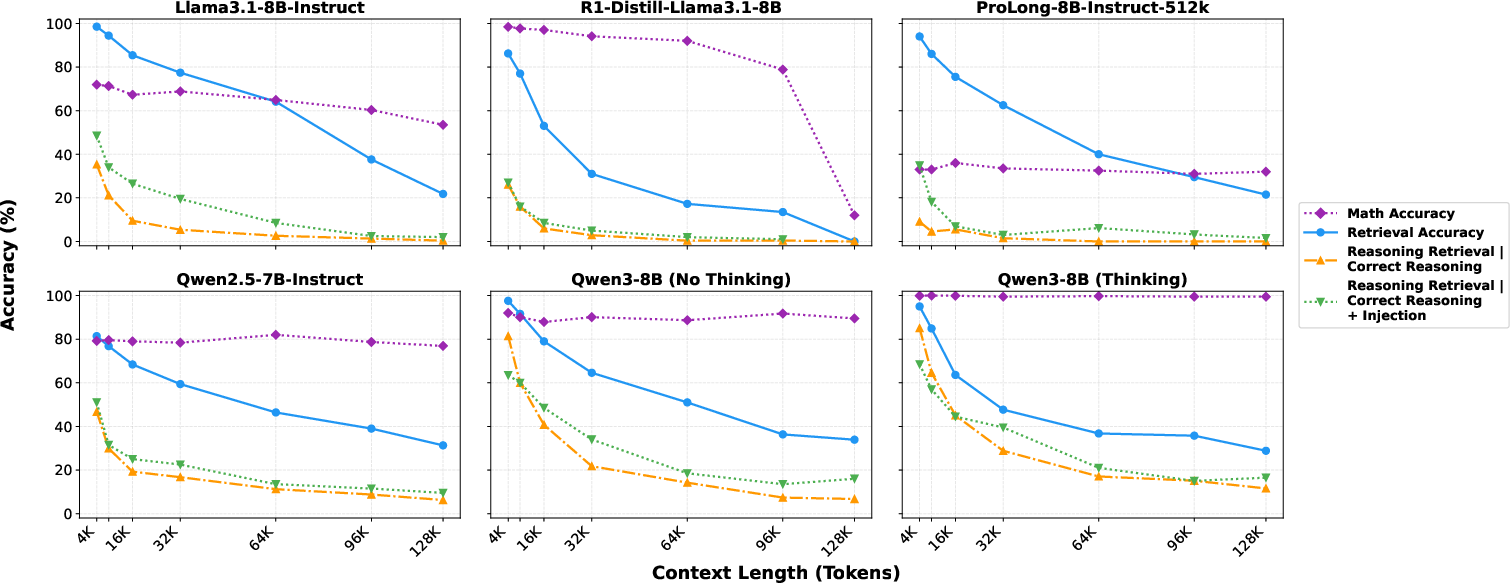
Figure 2: Quantitative evidence of the lost-in-thought gap—retrieval accuracy degrades after reasoning, and even faithful copying is error-prone despite providing the key and context prefix.
Prevailing approaches address long-context capabilities with either context extension (pretraining/continued training on longer sequences) or retrieval-then-reason pipelines. However, they fail to adequately integrate retrieval as a dynamic, interleaved step with reasoning, or to verify retrieval fidelity. This limitation restricts robustness and generalization to real-world, open-ended tasks that demand evidence acquisition during reasoning, not just upfront.
RecaLLM Architecture and Training
RecaLLM targets lost-in-thought by integrating explicit, verifiable in-context retrieval within the reasoning process. The approach rests on three pillars:
- Explicit Recall Spans: Special delimiter tokens segment generations into reasoning and recall (copying) regions. During recall spans, generation is constrained to verbatim substrings from the input or prior outputs, implemented via logit masking and match enumerations in the context.
- Negligible-Overhead Constrained Decoding: Recall spans are enforced through runtime logit masks that are computed efficiently and independently of model activations, adding minimal latency.
- Fine-Grained RL Optimization: RecaLLM leverages supervised cold starts with annotated recall traces, then multi-task RL via GRPO, optimizing a composite reward that balances answer quality and retrieval fidelity, incorporating penalties for overuse or degenerate recall behavior.
This setup makes retrieval verifiable and model-initiated, with supervision not only on final-task accuracy but also on evidentiary grounding.
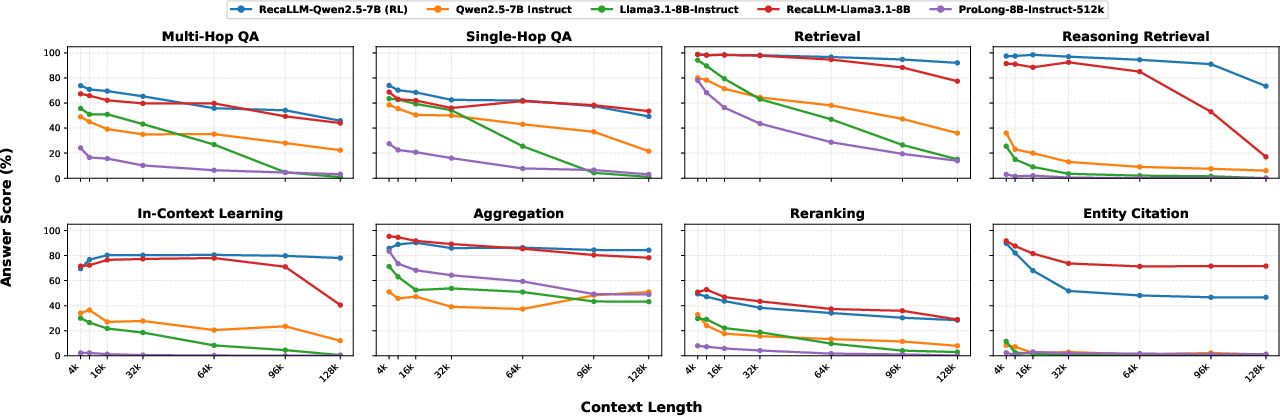
Figure 3: In-domain answer scores across context lengths. RecaLLM’s per-category performance remains robust up to 128K tokens, while baselines degrade after 32K.
Experimental Evaluation
Synthetic and Real-World Benchmarks
The effectiveness of RecaLLM is evaluated with both synthetic (RULER) and application-focused (HELMET) benchmarks. Models are trained with context windows up to 10K tokens, but evaluated up to 128K tokens, showcasing strong out-of-distribution generalization.
Key results include:
- RULER: RecaLLM-Qwen2.5-7B achieves an average score of 92.8, outperforming LoongRL-14B and QwenLong-L1-32B, both larger models trained on longer contexts.
- HELMET: RecaLLM improves its base models by 16.1–17.7 points, achieving state-of-the-art robustness, especially on retrieval-intensive tasks (Recall, ICL, Citation, Re-rank).
Notably, improvement magnifies with increasing context length, e.g., Qwen’s gain grows from +6.8 at 4K to +16.1 at 128K; Llama’s largest improvement is +24.2 at 128K. These improvements are not merely due to memorization or position encoding biases, but to systematic and explicit utilization of context.
Ablation Analysis
Ablations disentangle the impact of reward structure and recall enforcement:
- Without Recall Reward: The model’s recall usage collapses on tasks outside rigid retrieval, reducing average score by 5–6 points and eroding robustness.
- Without Logit Masking: While recall remains frequent, precision on retrieval tasks suffers (i.e., recall is not faithful), highlighting the complementarity of reward and constraint.
- Category Breakdown: Improvements are largest on retrieval + reasoning tasks and entity-centric citation, persisting for in-context demonstration selection and reranking.
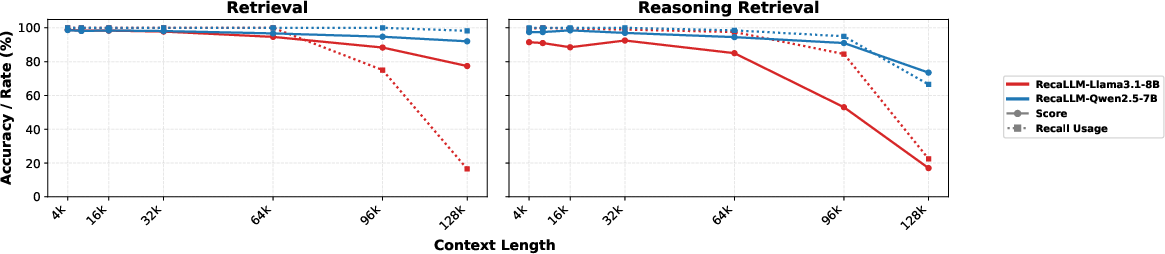
Figure 4: RecaLLM maintains high accuracy and recall span usage across increasing context lengths. Performance drops only when recall usage diminishes.
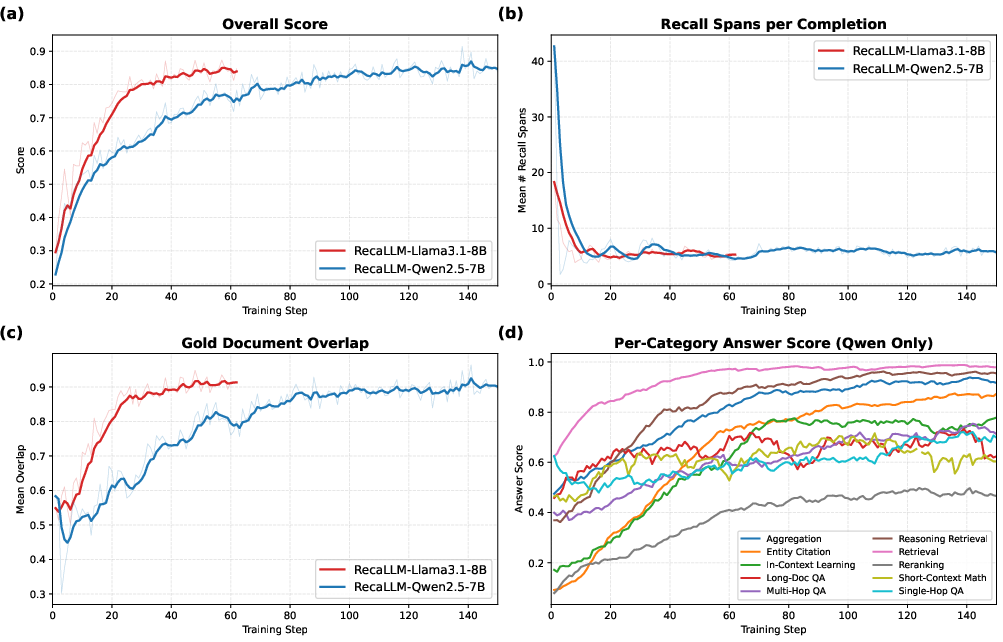
Figure 5: Training dynamics—overall score and gold document recall rates increase, recall spans become more selective, and gains are seen across all task categories.
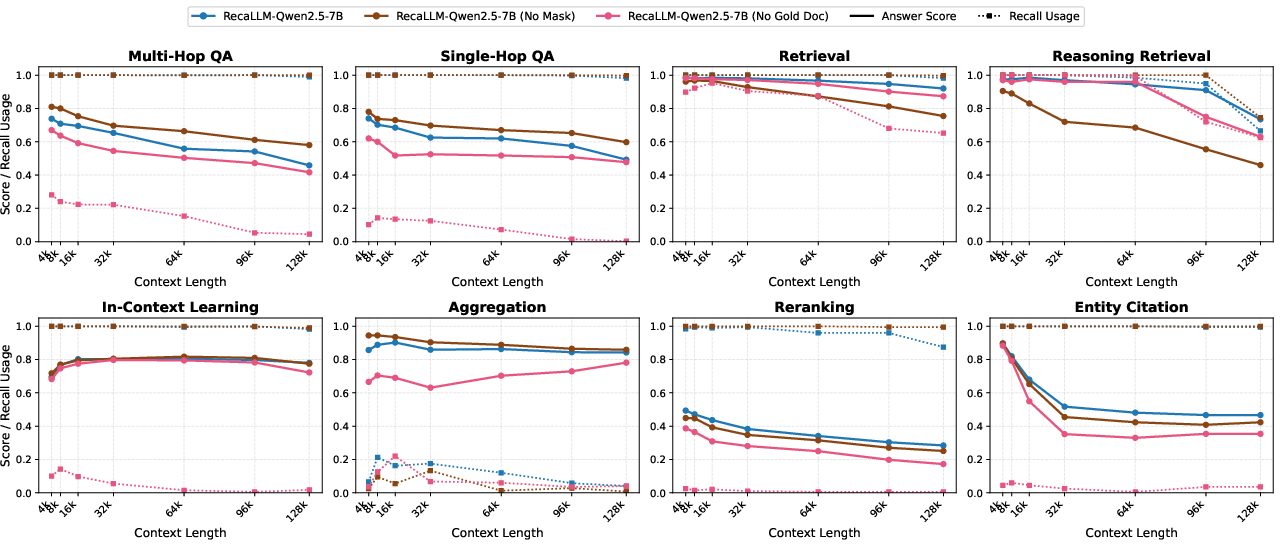
Figure 6: Per-category recall usage rates and answer scores, with and without ablation. Disabling either constrained decoding or explicit reward supervision leads to significant performance drops on target categories.
Implications and Future Directions
RecaLLM’s success demonstrates that explicit, constrained, verifiable in-context retrieval interleaved with reasoning is critical for robust long-context utilization, especially as model context windows continue to expand. It is notable that generalization to 128K contexts is achieved with only 10K-token training data, suggesting that retrieval-centric post-training is more compute/data efficient than brute-force context extension.
Practically, these advances enable more trustable, interpretable systems: retrieval spans serve as evidence-grounded justifications, providing not only accuracy but also transparency in long-context applications. Theoretically, making retrieval explicit unlocks new reward structures for RL, facilitates interpretability, and is compatible with scalable, agentic workflows.
Potential future directions include:
- Relaxing Constraints: Developing more flexible retrieval that balances faithfulness and generative diversity.
- Self-recall over Model Output: Using recall spans not only for input context, but also for long-horizon history consistency.
- Scalability to Larger Models: Investigating how retrieval policies transfer to very large, strongly pretrained LLMs.
- Integration with Agentic RAG Pipelines: Composing retrieval-augmented search agents with explicit in-context grounding.
Conclusion
RecaLLM establishes that lost-in-thought is a widespread failure mode that cannot be overcome by simply scaling context length or compute. Instead, explicit, model-initiated, verifiable in-context retrieval via constrained recall spans—supervised and rewarded through fine-grained RL—enables highly effective long-context reasoning and retrieval. This work provides a foundation for extending the trustworthiness, scalability, and interpretability of LLMs as context windows and application demands continue to increase.
Reference:
"RecaLLM: Addressing the Lost-in-Thought Phenomenon with Explicit In-Context Retrieval" (2604.09494)