Envisioning the Future, One Step at a Time
Abstract: Accurately anticipating how complex, diverse scenes will evolve requires models that represent uncertainty, simulate along extended interaction chains, and efficiently explore many plausible futures. Yet most existing approaches rely on dense video or latent-space prediction, expending substantial capacity on dense appearance rather than on the underlying sparse trajectories of points in the scene. This makes large-scale exploration of future hypotheses costly and limits performance when long-horizon, multi-modal motion is essential. We address this by formulating the prediction of open-set future scene dynamics as step-wise inference over sparse point trajectories. Our autoregressive diffusion model advances these trajectories through short, locally predictable transitions, explicitly modeling the growth of uncertainty over time. This dynamics-centric representation enables fast rollout of thousands of diverse futures from a single image, optionally guided by initial constraints on motion, while maintaining physical plausibility and long-range coherence. We further introduce OWM, a benchmark for open-set motion prediction based on diverse in-the-wild videos, to evaluate accuracy and variability of predicted trajectory distributions under real-world uncertainty. Our method matches or surpasses dense simulators in predictive accuracy while achieving orders-of-magnitude higher sampling speed, making open-set future prediction both scalable and practical. Project page: http://compvis.github.io/myriad.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Envisioning the Future, One Step at a Time — Explained Simply
What is this paper about?
This paper is about teaching a computer to “imagine” how things might move in the future by looking at just one picture. Instead of drawing full future videos (which is slow and expensive), the computer focuses on tracking only a few important points in the image—like sticking small dots on key parts of objects—and predicts how those dots move over time. This makes it fast to explore many possible futures and choose a good one.
What questions are the researchers asking?
The authors set out to find out:
- Can a model predict realistic future motion from a single image, even in messy, real-world scenes where anything might happen?
- If we predict motion step by step (instead of in one big leap), can we handle long, complicated chains of events better?
- If we only track a few important points (instead of every pixel), can we be much faster without losing accuracy?
- Can this fast “imagination” help with planning actions—like choosing how to hit a billiard ball?
- How can we fairly test such models in the open world? (They propose a new benchmark called OWM.)
How does the method work (in everyday terms)?
Think of giving the model a single photo and placing a handful of dots on parts of objects you care about (like a ball, a door handle, or a person’s hand). The job is to predict where each dot will move in the next moment, then the moment after that, and so on.
Here’s the big idea in simple steps:
- Focus on motion, not appearance: Instead of painting every pixel of future frames, the model predicts the paths of just these dots. That’s far less work and much faster.
- Step-by-step prediction: The model doesn’t try to guess the whole future at once. It predicts small, short steps (like “where will the dot move in the next instant?”), then continues from there. This mirrors how we mentally unfold events (like a billiard ball bouncing from wall to wall).
- Embrace uncertainty: The world is unpredictable. The model treats each next step like rolling a “smart dice,” producing many possible future motions and keeping track of how unsure it is.
- A quick note on the tech (in plain English):
- “Autoregressive” means “one step depends on the previous step,” like writing a story sentence by sentence.
- “Diffusion with flow matching” is a training trick that helps the model learn realistic variations in how things could move, from small nudges to big jumps.
- “Motion tokens” bundle three kinds of information for each dot: what object it belongs to, where it is, and how it has been moving.
- “Fast reasoning blocks” are efficiency tweaks so the model can simulate thousands of futures quickly.
- Optional hints: You can give the model a tiny “poke” (an initial direction/speed) to guide how things start moving.
Training and evaluation:
- The model is trained on millions of short real-world video clips. It uses tracking tools to learn where points actually moved in those videos.
- To test it fairly, the authors created OWM, a new benchmark with 95 real-world videos where the camera stays still (so we can focus on object motion, not camera motion). They also test on simple physics videos to check if the model respects basic physical rules.
What did they find, and why does it matter?
Main results:
- Faster and accurate: Predicting just the motion of a few points (instead of full video frames) makes the model orders of magnitude faster. In their tests, their model could generate thousands of future rollouts per minute, while typical video models often manage fewer than one per minute.
- High quality: Even though it’s much faster, the model matches or beats state-of-the-art video generators at predicting where things will move in real scenes.
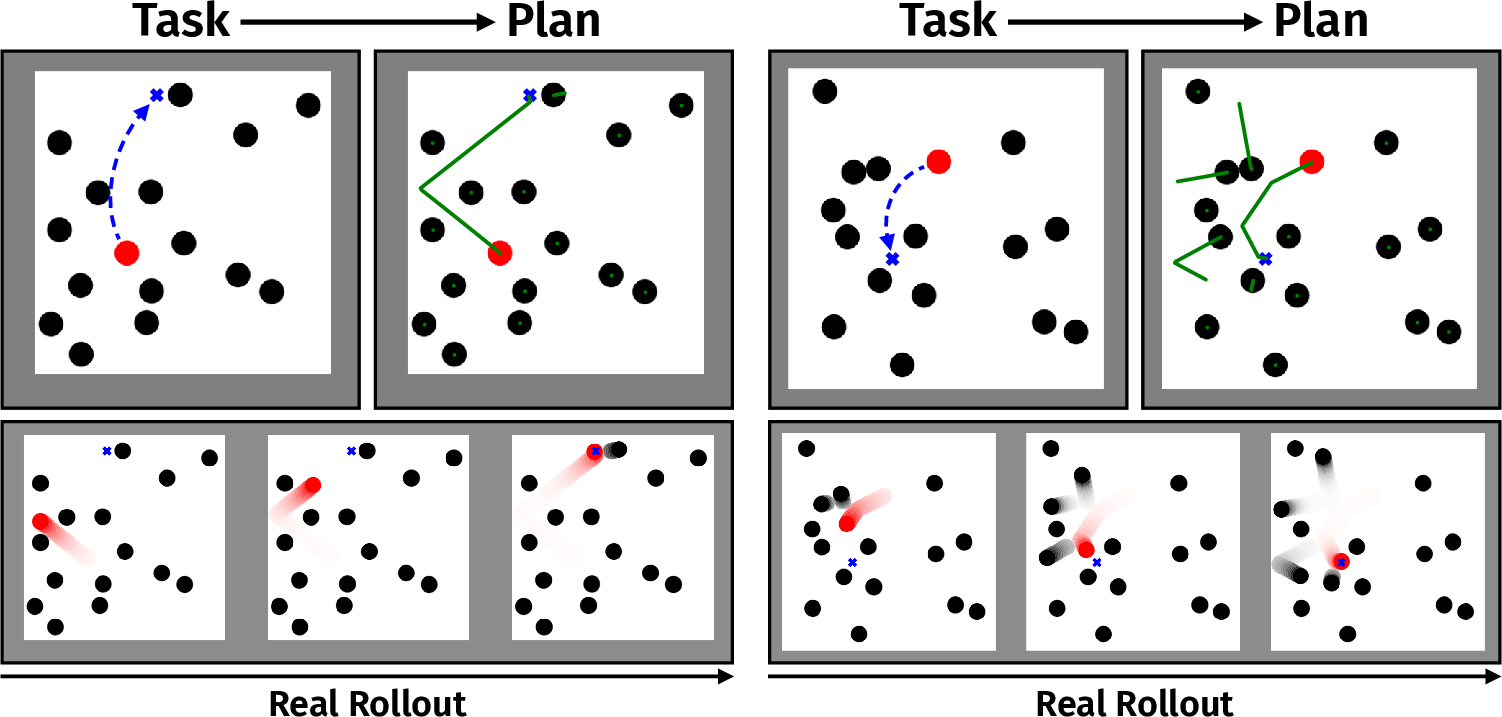
- Great for planning: In a billiards task, the model used its fast “imagination” to try many different shots (initial pushes) and pick the one most likely to succeed. Because it can roll out thousands of possibilities quickly, it chooses better actions.
- Calibrated uncertainty: When the model says it’s uncertain, that usually reflects how hard the prediction actually is. That’s useful for knowing when to trust it.
Why this matters:
- Being able to imagine many futures quickly is useful for robotics, sports analysis, games, and interactive systems. Instead of burning time and compute drawing heavy videos, you can focus on the key motions that drive decisions.
- It’s scalable: Because the method avoids the “visual tax” (rendering every pixel), it can explore many “what if?” scenarios in the same time and budget.
What could this change in the future?
- Smarter decision-making: Systems (like robots or assistants) can test many possible actions in their head before choosing one, saving time and avoiding mistakes.
- Wider use in the real world: Because the model learns from in-the-wild videos and handles many kinds of scenes, it can help in open-ended, unpredictable environments.
- Better benchmarks: Their OWM benchmark offers a way to measure not just one prediction, but a whole distribution of possible futures—more realistic for messy real-world situations.
A few limitations:
- The current setup assumes the camera doesn’t move, which simplifies things. Handling moving cameras (like headcams or drones) is a next step.
- The model learns from point tracks produced by existing trackers, so it can inherit their errors.
In short
This paper shows a new way to predict the future from a single image by focusing on how a few important points move, step by step. It’s fast, accurate, and good at exploring many “what if?” futures—making it practical for planning and decision-making in complex, real-world scenes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Joint ego-motion and scene dynamics: Extend the model beyond the static-camera assumption to jointly infer and predict camera motion and scene motion, including disentangling 3D ego motion from object motion in unconstrained videos.
- From 2D image-plane to 3D world trajectories: Develop a consistent 3D formulation that predicts trajectories in world coordinates (with depth and camera intrinsics/extrinsics), including training from monocular video and handling perspective effects.
- Occlusions, visibility changes, and FOV exits: Incorporate mechanisms for point visibility toggling, occlusion handling, and re-entry, including uncertainty-aware predictions when points leave the frame or become untrackable.
- Dynamic, variable-cardinality point sets: Support creation, deletion, and re-identification of trajectories over time (variable K), rather than assuming a fixed set of user-provided points persisting throughout.
- Automatic selection of “decision-centric” points: Learn to propose or adaptively refine query points that maximize predictive/decision utility (e.g., object keypoints, contact points), instead of requiring user-specified points at inference.
- Rigid/non-rigid coherence constraints across points: Enforce or learn structured constraints (rigid body, articulated joints, non-rigid deformation) to maintain physically consistent motion among multiple points on the same object.
- Long-horizon stability and error compounding: Quantify and mitigate error accumulation over substantially longer horizons than those used for training (e.g., scheduled sampling, closed-loop fine-tuning, or consistency regularizers).
- Exposure bias from teacher forcing: Assess and reduce train–test mismatch (e.g., via professor forcing, data as demonstrator, or online rollouts during training) to improve robustness during autoregressive inference.
- Posterior calibration and uncertainty quantification: Go beyond qualitative correlation to measure and improve calibration (e.g., reliability diagrams, ECE, CRPS), and provide well-calibrated predictive intervals for downstream decision-making.
- Diversity and coverage of multi-modal futures: Complement minADE_N with metrics that assess coverage and diversity (e.g., pairwise trajectory diversity, precision/recall in motion space, human plausibility ratings), given only a single realized future.
- Physical plausibility beyond trajectory error: Introduce diagnostics that test conservation laws, collision coherence, frictional behavior, and contact timing, not merely pointwise distance to observed trajectories.
- Sensitivity to tracker-derived supervision: Quantify how biases and failures in pseudo ground-truth tracks (TAPNext/V-DPM) affect learning; investigate robust training under label noise and alternatives (e.g., self-supervision, partial human annotation).
- Benchmark scale and scope: Expand OWM beyond 95 static-camera clips to include dynamic viewpoints, larger scale, diverse domains (fluids, deformables, cloth, articulated agents), and multi-agent interactions to validate open-set claims.
- Action conditioning beyond single-step “poke”: Generalize conditioning to multi-step action sequences and closed-loop control, enabling interactive rollouts conditioned on planned control inputs over time.
- Planning efficiency and differentiability: Explore differentiable planning through the model (e.g., gradient-based or implicit planning via the flow ODE), in addition to sampling-and-selecting counterfactuals.
- Scalability with K and T: Characterize performance and resource scaling for larger numbers of trajectories (K » 16) and longer horizons (T » 16), including memory/compute limits and architectural changes to maintain efficiency.
- Permutation invariance and ordering bias: Replace trajectory-by-trajectory factorization with set-equivariant architectures to remove dependence on arbitrary ordering and investigate alternatives to random trajectory IDs.
- Out-of-frame boundary conditions: Define principled boundary handling and extrapolation when motion takes points beyond the image, including predictive uncertainty escalation and re-entry logic.
- Robustness to domain shifts: Evaluate and improve robustness under challenging conditions (camera shake, rolling shutter, motion blur, low light, fast non-rigid motion) and across domains unseen during training.
- Heavy-tailed motion modeling theory: Provide theoretical and empirical guidelines for the flow-matching head and scale cascade under heavy-tailed motion distributions (e.g., choice of priors, step-size schedules, solver stability).
- Sampling efficiency vs. fidelity trade-offs: Systematically benchmark ODE/SDE solvers, step counts, and caching strategies for the flow-matching head to optimize speed without degrading posterior fidelity.
- Integration with semantics and goals: Investigate conditioning on semantic inputs (e.g., object categories, affordances) or language goals to guide rollouts toward task-relevant futures.
- Automatic point tracking at inference: Provide an end-to-end pipeline that includes automatic detection/initialization of query points for deployment scenarios where user input is unavailable.
- Data efficiency and ablations: Quantify how performance scales with training set size (10M clips vs. smaller subsets) and pretraining choices (e.g., alternative image encoders), identifying minimal data regimes.
- Real-world deployment constraints: Validate throughput and latency on commodity/edge hardware (e.g., mobile GPUs), and study speed–accuracy trade-offs in time-critical applications.
- Fairness and comparability of baselines: Establish standardized, compute-matched protocols for dense video model baselines (including fast trackers and sampling budgets) to ensure apples-to-apples comparisons under time limits.
Practical Applications
Immediate Applications
The paper introduces a fast, dynamics-centric model that predicts and explores diverse future point trajectories from a single image without generating video. Below are concrete, deployable use cases that rely on the current formulation (static camera, sparse point trajectories, uncertainty-aware step-wise rollouts).
- Traffic and crowd flow forecasting from fixed cameras – sectors: public policy, smart cities, transportation, safety
- What: Predict plausible pedestrian/vehicle paths a few seconds ahead to warn of near-term conflicts (e.g., jaywalking into traffic, cyclists entering blind spots) and optimize signal timing or crowd routing.
- Tools/products/workflows:
- Edge/cloud service that ingests a reference frame + short warm-up motion (from trackers), then rolls out thousands of futures and surfaces high-risk trajectories in a control dashboard.
- Plugin for existing traffic management platforms that consumes CCTV feeds and outputs per-object trajectory distributions and risk scores.
- Assumptions/dependencies: Static cameras; accurate point tracking to initialize query points; domain adaptation to the deployment scene; governance for privacy and alerting thresholds; human-in-the-loop for interventions.
- Industrial cell and warehouse safety forecasting – sectors: robotics, manufacturing, logistics, EHS
- What: From a fixed overhead camera, anticipate paths of pallets, AGVs, forklifts, and people to prevent near-term collisions. Use uncertainty estimates to prioritize interventions.
- Tools/products/workflows:
- ROS-compatible module that subscribes to a video frame and recent motion hints, then publishes predicted trajectories with confidence for downstream safety monitors.
- “What-if” tool for safety engineers to probe outcomes by “poking” objects (initial motion hints) and exploring counterfactuals quickly.
- Assumptions/dependencies: Static camera coverage of the cell/aisle; reliable trackers; calibrated thresholds for safety-critical use; model monitoring for domain shift (new layouts, lighting).
- Sports broadcast and coaching overlays – sectors: media, sports analytics
- What: Predict ball/player trajectories from a televised frame to create live AR overlays (possible shots, runs, passes). The billiards planning demo generalizes to other ball sports in fixed-camera settings (e.g., snooker tables).
- Tools/products/workflows:
- Broadcast graphics plugin that samples many futures per “poke” (coach input or auto-detected intents) and selects top-k physically consistent trajectories for on-screen visualization.
- Coaching tool for scenario exploration (e.g., “if kicked with X direction/magnitude…”).
- Assumptions/dependencies: Static or calibrated broadcast cameras; integration with player/ball trackers; sports-specific priors may improve accuracy but are not strictly required.
- Video analytics without dense generation – sectors: software, VFX, creative tools
- What: Rapidly explore motion “beats” from a concept frame without rendering video. Useful for previz, storyboard validation, and interactive ideation.
- Tools/products/workflows:
- Design tool where users drop sparse points and “poke” to branch and compare thousands of futures in seconds, exporting selected trajectories as guides for animators.
- Assumptions/dependencies: Users provide or auto-select salient points; static-frame assumption is fine for previz; optional domain finetuning for stylized content.
- Model-based planning in simple environments – sectors: robotics R&D, RL research, gaming
- What: Use the model as a fast world model to evaluate candidate actions via thousands of counterfactual rollouts (e.g., selecting a billiard shot).
- Tools/products/workflows:
- Planning loop that samples action seeds, rolls out trajectory distributions, evaluates a reward, and picks the best action (best-within-time-limit).
- Research baselines replacing dense video world models with sparse trajectory rollouts for Monte Carlo planning.
- Assumptions/dependencies: Known action-to-poke mapping; static camera; environment within training distribution; not safety-critical without closed-loop safeguards.
- Academic benchmarking and methods reuse – sectors: academia, ML tooling
- What: Evaluate motion prediction models with OWM (open-world, static-camera benchmark) and reuse architectural components (motion tokens, fused attention blocks, FM head with scale cascade).
- Tools/products/workflows:
- OWM benchmark suite for distributional trajectory evaluation; reference implementations of KV-cached AR decoding + FM sampling; ablation-friendly training scripts.
- Assumptions/dependencies: Access to OWM and similar evaluation data; reproducible training on large-scale internet videos with tracker-derived supervision.
- Human–computer interaction for “what-if” previews – sectors: product design, UX, AR prototyping
- What: In design tools or AR protos with fixed viewpoints (e.g., tabletop setups), users “poke” objects on a still image to preview plausible motions and constraints (collisions, sliding).
- Tools/products/workflows:
- Lightweight web API backing a canvas widget: click-to-place points, drag to hint initial motion, show multiple sampled futures with uncertainty bands.
- Assumptions/dependencies: Static camera or pre-registered scene; non-safety-critical setting; user guidance to choose meaningful points.
Long-Term Applications
These require extending the approach (e.g., dynamic/ego cameras, 3D reasoning, tighter control–action coupling, safety certification) or scaling to more complex domains.
- On-vehicle forecasting for autonomous systems – sectors: autonomous driving, mobile robotics
- What: Predict multi-agent trajectories from moving cameras (ego-motion), integrate with perception, and use rollouts for risk-aware planning.
- Tools/products/workflows:
- 3D trajectory head with joint ego-motion estimation; fusion with LiDAR/radar; closed-loop planners using uncertainty-weighted rollouts.
- Assumptions/dependencies: Joint ego+scene motion modeling; multi-sensor calibration; extensive validation; regulatory compliance; robust online calibration to changing conditions.
- City-scale multi-camera forecasting and policy simulation – sectors: urban planning, public safety
- What: Stitch predictions across a network of cameras to forecast flows at intersections, test “what-if” infrastructure changes, and evaluate near-term interventions.
- Tools/products/workflows:
- Multi-view association + trajectory fusion; simulation dashboards for planners; APIs to query counterfactuals (e.g., signal timing changes).
- Assumptions/dependencies: Cross-camera re-identification; privacy-preserving deployment; bias audits; governance for automated interventions.
- Clinical and assistive applications (fall risk, rehab) – sectors: healthcare, elder care
- What: From room-mounted cameras, anticipate short-horizon motions (e.g., potential stumble paths) and alert caregivers; visualize rehab motion trajectories.
- Tools/products/workflows:
- HIPAA-compliant edge devices inferring distributions and uncertainty; clinician dashboards for trajectory summaries and trend tracking.
- Assumptions/dependencies: Medical-grade validation; privacy and consent; specialized training on clinical domains; minimized false alarms; robust in varied lighting/occlusion.
- Household robots and AR glasses – sectors: consumer robotics, AR/VR
- What: Predict how objects and people will move to enable safe, anticipatory behaviors (e.g., placing items, avoiding pets), and render likely futures in AR to guide users.
- Tools/products/workflows:
- On-device or near-edge inference with dynamic-view support; interaction loops that combine “poke”-like user hints with closed-loop replanning.
- Assumptions/dependencies: Efficient on-device or low-latency edge compute; continuous re-estimation under ego-motion; strong human factors testing.
- Digital twins and predictive maintenance – sectors: manufacturing, energy, infrastructure
- What: Integrate trajectory rollouts into digital twins to anticipate motion of components/material flows and test “what-if” operational changes without pixel-level simulation.
- Tools/products/workflows:
- Coupling with CAD/SCADA data; constraint-aware trajectory sampling conditioned on machine states; dashboards showing predicted flows and rare-event tails.
- Assumptions/dependencies: High-fidelity domain adaptation; mapping between control inputs and motion hints; integration with physics constraints for out-of-distribution edge cases.
- Generalist world models for RL and agents – sectors: AI research, software
- What: Use sparse, uncertainty-aware rollouts as a planning substrate for agents to reason over multi-step futures without paying the “visual tax.”
- Tools/products/workflows:
- Hybrid latent+trajectory planners; model-predictive control with uncertainty penalties; training curricula that bridge 2D trajectories to 3D dynamics.
- Assumptions/dependencies: Learnable interfaces between actions and trajectory conditions; benchmarks that reward long-horizon, multi-modal predictions; stability under distribution shifts.
- Regulatory tooling for safety analytics – sectors: policy, insurance, compliance
- What: Regulators and insurers assess near-term risk in public spaces/industrial sites by stress-testing scenes with counterfactual rollouts.
- Tools/products/workflows:
- Compliance dashboards providing explainable trajectory distributions, calibrated uncertainty, and auditable logs of rollouts used in decisions.
- Assumptions/dependencies: Clear standards for interpretability and uncertainty calibration; safeguards against misuse; oversight processes.
- Mobile/on-device “future preview” features – sectors: consumer software, cameras
- What: Smartphone camera apps that show likely motion of fast-moving subjects (e.g., kids, pets, sports) for better framing or action shots.
- Tools/products/workflows:
- Compressed variants (distillation/quantization) and partial offload to edge; UI affordances to place points and “poke” to fine-tune predictions.
- Assumptions/dependencies: Significant model compression; battery/latency constraints; handling of rolling shutter and device motion.
Cross-cutting assumptions and dependencies
- Camera and viewpoint: Current method assumes a static camera; dynamic/ego cameras need additional modeling (ego-motion compensation, 3D geometry).
- Supervision quality: Training uses tracker-derived pseudo ground truth; performance depends on tracker reliability and coverage of edge cases.
- Query point selection: Systems must select or solicit salient points; auto-selection may need task-specific heuristics or detectors.
- Safety and calibration: For safety-critical uses, calibrated uncertainty, fail-safes, and human oversight are required.
- Compute and integration: Although orders-of-magnitude faster than video models, real-time deployment still needs GPU/edge acceleration and integration with perception/actuation stacks.
- Domain adaptation: Performance improves with finetuning on target domains (sports type, factory layout, city scene); monitoring for distribution shift is recommended.
- Ethics and privacy: Deployments in public/clinical spaces require privacy-preserving design, consent, and compliance with local regulations.
These applications leverage the paper’s core innovations: step-wise autoregressive prediction over sparse trajectories, fast KV-cached decoding, a flow-matching posterior with a scale cascade for heavy-tailed motion, and the OWM benchmark for distributional evaluation under real-world uncertainty.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates to improve training stability. "We train using bfloat16 mixed precision with AdamW~\cite{loshchilov2018decoupled,kingma_adam_2017} with a peak learning rate of 3e-5, betas (0.9, 0.99), and weight decay $0.01$."
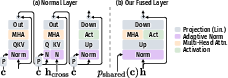
- adaptive norms: A conditioning mechanism that adapts normalization parameters to inject control signals into a network. "conditioning implemented via adaptive norms~\cite{huang2017arbitrary} with a shared~\cite{chen2024pixartalpha} control vector "
- autoregressive diffusion model: A generative approach that unrolls future states step-by-step while modeling uncertainty via diffusion. "Our autoregressive diffusion model advances these trajectories through short, locally predictable transitions, explicitly modeling the growth of uncertainty over time."
- autoregressive transformer: A transformer that models sequences with causal factorization over time and elements. "We parametrize the joint with an autoregressive transformer~\cite{vaswani2017attention}~"
- axial RoPE: Rotary positional embeddings applied along axes to encode positions for attention. "We base our positional encoding on axial RoPE~\cite{su2021roformer,crowson2024hourglass}."
- bfloat16 mixed precision: A reduced-precision floating-point format used to speed up training and reduce memory without large accuracy loss. "We train using bfloat16 mixed precision with AdamW~\cite{loshchilov2018decoupled,kingma_adam_2017}..."
- bilinear sampling: An interpolation method for retrieving feature values at non-integer coordinates. "First, we retrieve appearance (``what'') from the spatial image features at the trajectory's origin $x_0\supi$ using bilinear sampling."
- counterfactual rollouts: Simulated trajectories exploring hypothetical futures under alternative actions. "it can rapidly perform thousands of counterfactual rollouts -- here to select a candidate billiard shot (bottom)."
- ELBO (augmented ELBO): The evidence lower bound; here augmented by a flow-matching loss to train probabilistic models. "We train with teacher forcing~\cite{baumann2025whatif} and maximize the likelihood in \cref{eq:full_factorization} through the augmented ELBO defined by the flow matching loss"
- excess kurtosis: A statistic measuring heavy-tailedness compared to a normal distribution. "with excess kurtosis in the hundreds instead of around 0."
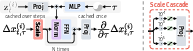
- flow matching: A technique that learns a velocity field to transport a noise distribution to data via an ODE. "A flow matching~\cite{lipman2022flow} head~\cite[cf.] []{li2024autoregressive} predicts the ODE velocity of a noisy motion $\Delta x_{t, \tau}\supi$ as it evolves from (Gaussian prior) to (data)"
- flow matching head: A network head that predicts the flow (velocity) for diffusion-style generation. "A flow matching~\cite{lipman2022flow} head~\cite[cf.] []{li2024autoregressive} predicts the ODE velocity of a noisy motion $\Delta x_{t, \tau}\supi$..."
- Fourier embedding: A sinusoidal feature mapping that represents inputs (e.g., motion) across multiple frequencies. "Second, we encode current motion $\Delta x_t\supi$ as a Fourier embedding~\cite{mildenhall2020nerf,tancik2020fourfeat} when observed"
- Gaussian Mixture Model (GMM): A probabilistic model that represents a distribution as a mixture of Gaussian components. "Alternatively, the distribution over future motion could be modeled with a Gaussian Mixture (GMM) Distribution head~\cite{tschannen2024givt} similar to the single-step Flow Poke Transformer~\cite{baumann2025whatif}."
- Gaussian prior: An initial normal distribution used as the starting noise in diffusion or flow-based models. "as it evolves from (Gaussian prior) to (data)"
- heavy tail-like behavior: Distributional property with frequent extreme values compared to normal data. "Motion shows significant heavy tail-like behavior, unlike typical image distributions for which similar heads were previously applied"
- KV caching: Storing transformer key/value tensors to accelerate autoregressive decoding. "Importantly, this formulation enables fast decoding with KV caching."
- minADE_N: Minimum Average Displacement Error over N hypotheses; evaluates the closest predicted trajectory to ground truth. "minADE_N = \min_k \Bigl[\frac{1}{KT}\sum_{i=1}K\sum_{t=1}T\bigl|\hat{\mathbf{x}_{n,t}\supi - \mathbf{x}_t\supi\bigr|_22\Bigr],"
- ODE velocity: The time derivative in an ordinary differential equation describing the flow from noise to data. "predicts the ODE velocity of a noisy motion $\Delta x_{t, \tau}\supi$"
- open-set motion prediction: Predicting motion in unconstrained settings with potentially unseen dynamics or categories. "We further introduce OWM, a benchmark for open-set motion prediction based on diverse in-the-wild videos"
- OWM: A curated benchmark for evaluating open-world motion prediction under uncertainty. "We further introduce OWM, a benchmark for open-set motion prediction based on diverse in-the-wild videos"
- positional encoding: Embeddings that encode spatial and temporal positions for attention mechanisms. "Motion and image tokens share one reference coordinate frame, so we apply a single positional encoding scheme to both."
- prefix layout: An attention pattern that concatenates streams to emulate cross-attention efficiently. "Further, we combine self- and cross-attention in a prefix layout, concatenating "
- teacher forcing: Training method feeding ground-truth previous outputs into an autoregressive model. "We train with teacher forcing~\cite{baumann2025whatif}"
- visual tax: The computational burden of generating dense pixels before reasoning about dynamics. "A model that requires video generation as a prerequisite for motion prediction is considered dense and incurs the visual tax"
- Wasserstein distance: A transport-based metric between distributions; here used to interpret trajectory error. "akin to a one-sided Wasserstein distance over motion space."
Collections
Sign up for free to add this paper to one or more collections.