- The paper demonstrates that frustration in sample-label coupling drives a gradual collapse in embedding separations.
- It uses spectral and dynamical mean-field analysis to reveal two distinct timescales: a fast alignment followed by a slow, collective collapse.
- The study shows that employing stop-gradient operations in projection heads preserves class separation, preventing complete geometric collapse.
A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics
Introduction and Motivation
Representation collapse is a prominent failure mode in self-supervised representation learning, where the learned embeddings lose discriminative power and different data points become indistinguishable. This paper, "A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics" (2604.09979), presents a rigorous, infrared-level (embedding-space) analysis of collapse, directly dissecting the fundamental mechanisms and their prevention strategies outside the specifics of large network architectures. The work is motivated by the observation that, despite empirical advances, a coherent theoretical account of collapse dynamics and mitigation in nonlinear, high-dimensional learning systems is lacking.
The authors construct a minimal but expressive representation learning framework where both sample and label embeddings are directly optimized under mean squared error (MSE) objectives. Unlike conventional supervised settings with fixed one-hot labels, this structure allows explicit tracking of representation collapse as a geometric contraction of learned label-embedding separations. The approach isolates the intrinsic factors leading to collapse and formalizes the effect of preventions like projection heads and stop-gradient operations via spectral and dynamical mean-field analysis.
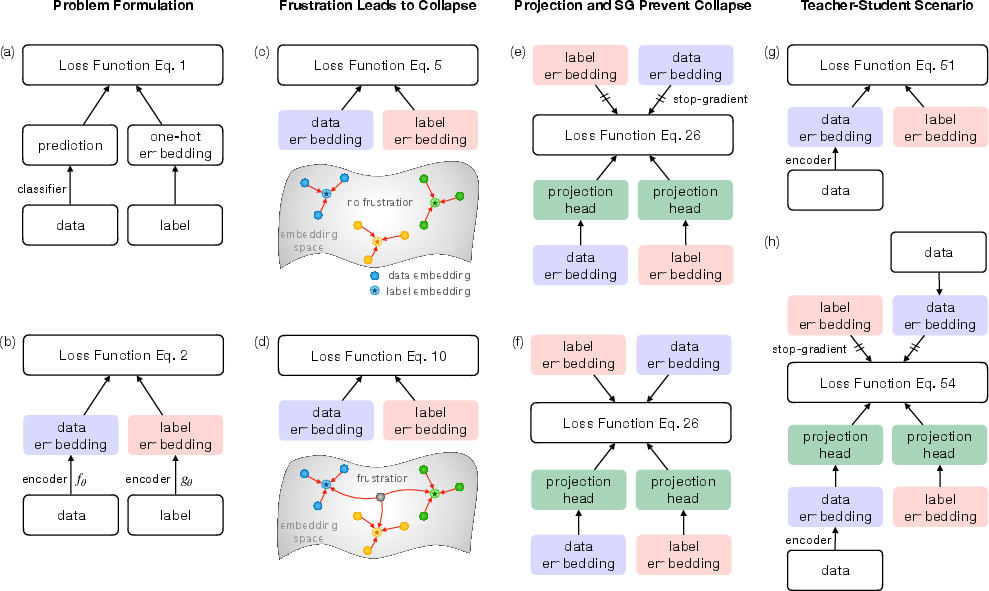
Figure 1: Schematic overview of model collapse in standard contrastive (a) vs. generative embedding spaces (b–h), and the effect of frustration and architectural choices.
Collapse Dynamics: The Role of Frustration
In the unfrustrated regime—where all samples can be perfectly classified—the mutual dynamics of sample and label embeddings guarantee persistent class separation at convergence. The fixed-point analysis demonstrates that label embeddings relax to class-wise means determined by initialization, preserving nonzero inter-class deviations.
However, the introduction of "frustration"—a fraction r of samples that cannot be unambiguously classified—induces global collapse. In the embedding-level minimal model, frustrated samples are implemented as data points coupled to multiple class labels, generating competing geometric constraints. The resulting dynamics decompose into fast sample-wise alignment (with time scale ∼(γN)−1) and a slow, collective collapse of class structure (with time scale ∼(γr)−1), as supported both by analytic spectrum calculation and empirical simulations.
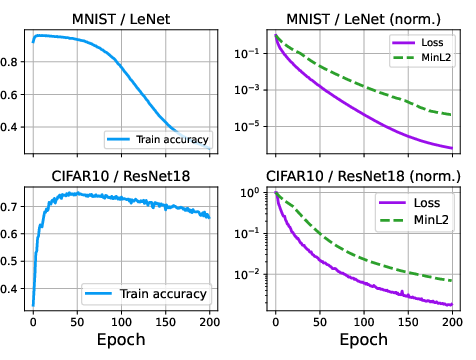
Figure 2: Training dynamics for MNIST and CIFAR-10: initial rapid accuracy improvement followed by late-time collapse-induced degradation. MinL2 captures shrinking label-embedding separation, revealing two distinct timescales.
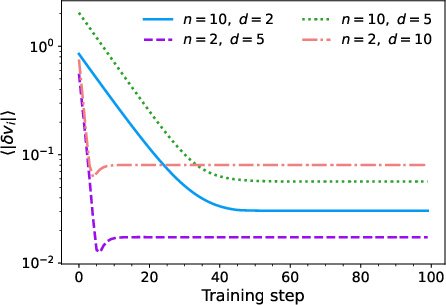
Figure 3: Unfrustrated runs exhibit exponential decay of inter-class deviation to stable, nonzero plateaus—no geometric collapse.

Figure 4: In the frustrated model, sample-level deviations quickly relax, and class-level structure degrades slowly, signifying separation of time scales.
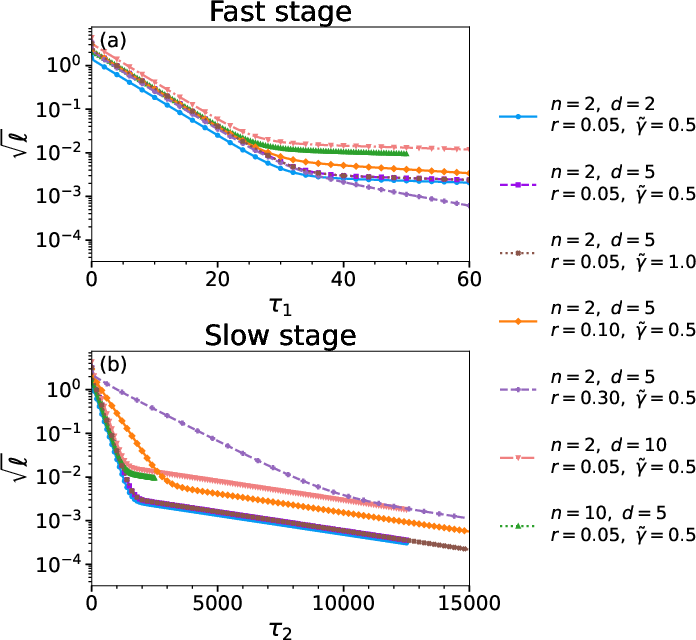
Figure 5: Two distinct relaxation regimes in the training loss: fast alignment and slow, frustration-driven collapse.
The slow regime, driven by the frustration-induced coupling, mirrors empirical findings in overparametrized real networks: rapid initial generalization yields to slow performance deterioration as embedding geometry collapses.
Preventing Collapse: Projection Heads and Stop-Gradient
A major theoretical result is that a projection head alone does not prevent representation collapse, as the attraction induced by frustration remains. The introduction of the stop-gradient operation—a critical nuance in implicit approaches like BYOL and SimSiam—qualitatively alters the dynamical system by breaking reciprocal feedback between twin embedding branches. Analytical fixed-point characterization using spectral decomposition of W2 (for projection matrix W) reveals that with stop-gradient, the system admits a non-collapsed sector: class separation is maintained in the eigenspace associated with eigenvalue (1−r), while collapse only occurs in the (1)-eigenspace.
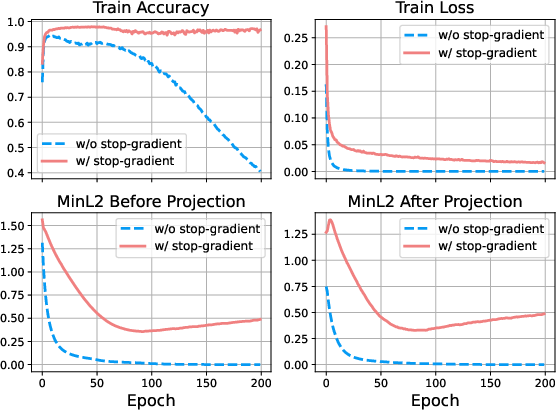
Figure 6: Stop-gradient preserves early-stage accuracy gains and halts late-stage decay of inter-label separations, stabilizing embedding geometry.
Empirical results confirm that, in the presence of stop-gradient, label embeddings resist collapse and maintain finite separation regardless of frustration ratio r, whereas omitting stop-gradient invariably yields full geometric collapse.
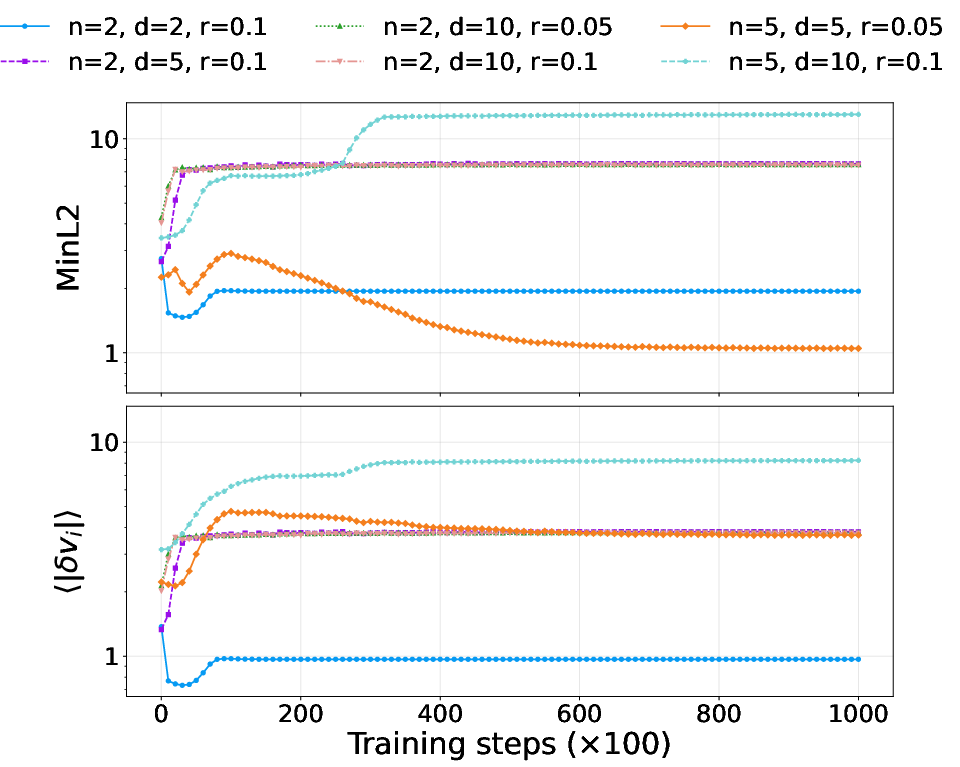
Figure 7: Minimum pairwise class-label distances and deviation magnitudes stabilize at nonzero values when stop-gradient is used, across varying n, d, and ∼(γN)−10.
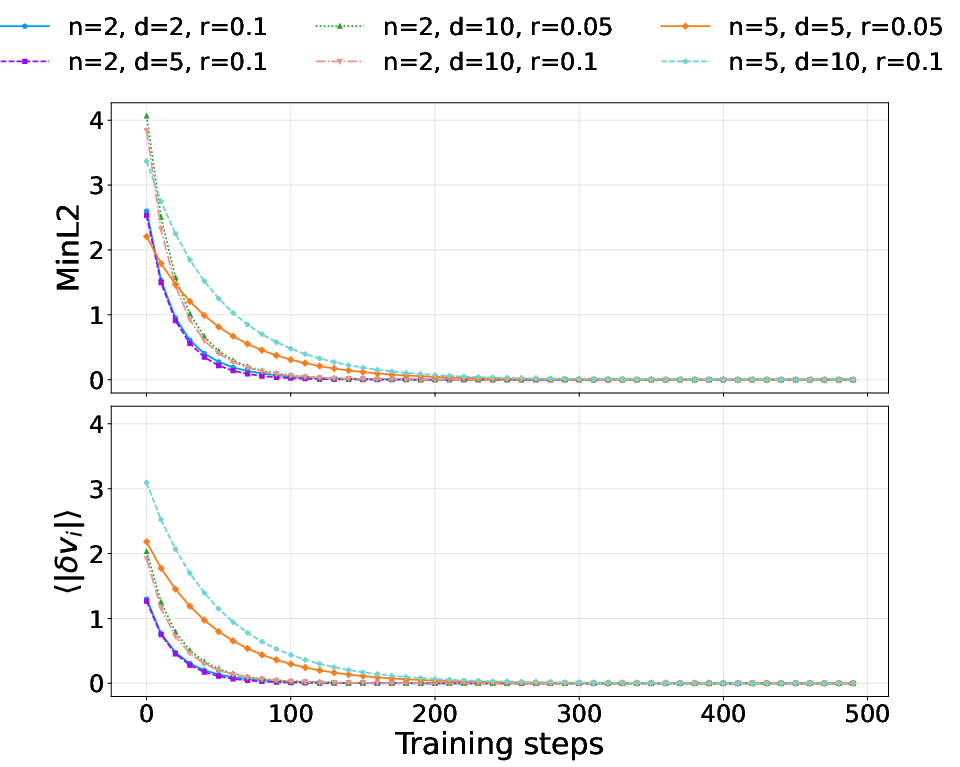
Figure 8: Without stop-gradient, both measures decay rapidly toward zero, indicating universal collapse.
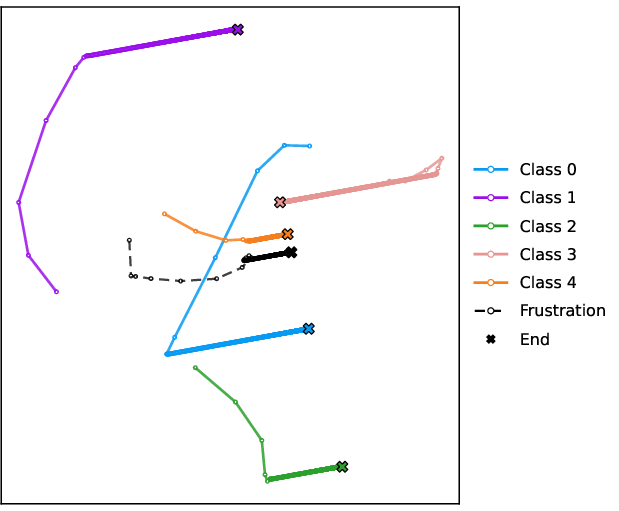
Figure 9: 2D trajectories of label embeddings with a single frustrated sample demonstrate contraction and partial, not total, collapse in the presence of stop-gradient.

Figure 10: Eigenvalue spectrum of ∼(γN)−11 at convergence shows clustering near ∼(γN)−12 (collapsed) and ∼(γN)−13 (non-collapsed sectors), consistent with theoretical predictions.
Extension: Parametric Teacher-Student Models
The generality of the mechanisms is validated in a teacher-student paradigm with a linear student network mapping inputs to embeddings. The synthetic setting allows precise frustration control by label corruption and exposes additional scale symmetry in the loss dynamics.
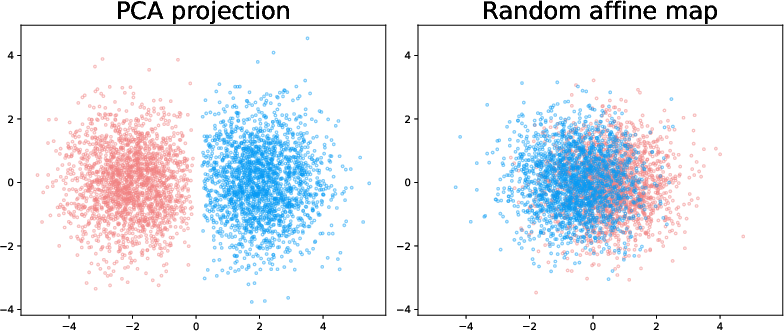
Figure 11: Synthetic teacher-student dataset visualizations. Classes are clearly linearly separable under PCA; random projections do not highlight structure.
Frustration again induces two-stage relaxation in training loss, with the late decay rate precisely set by the effective frustration fraction. The geometric mechanism for collapse and its mitigation by projection heads with stop-gradient are qualitatively identical, even in the presence of a parametric encoder.
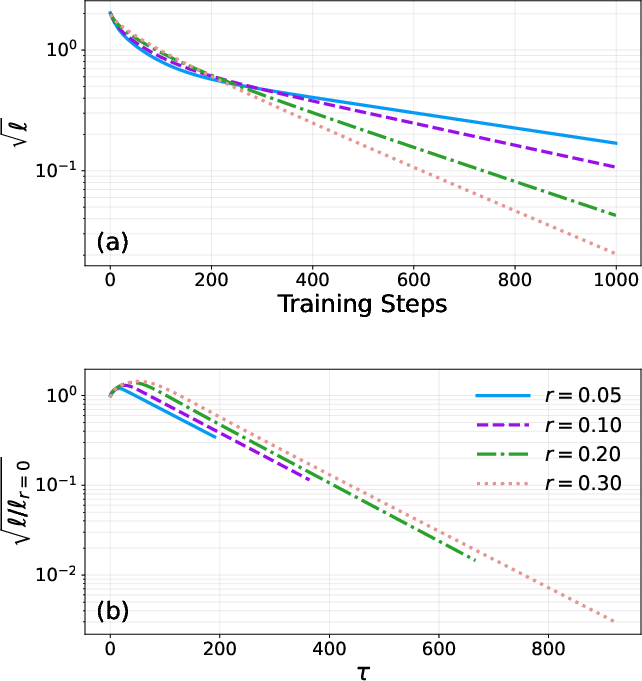
Figure 12: Linear model training with increasing frustration ratios ∼(γN)−14: late-time (normalized) loss decay exhibits exponential scaling with ∼(γN)−15.
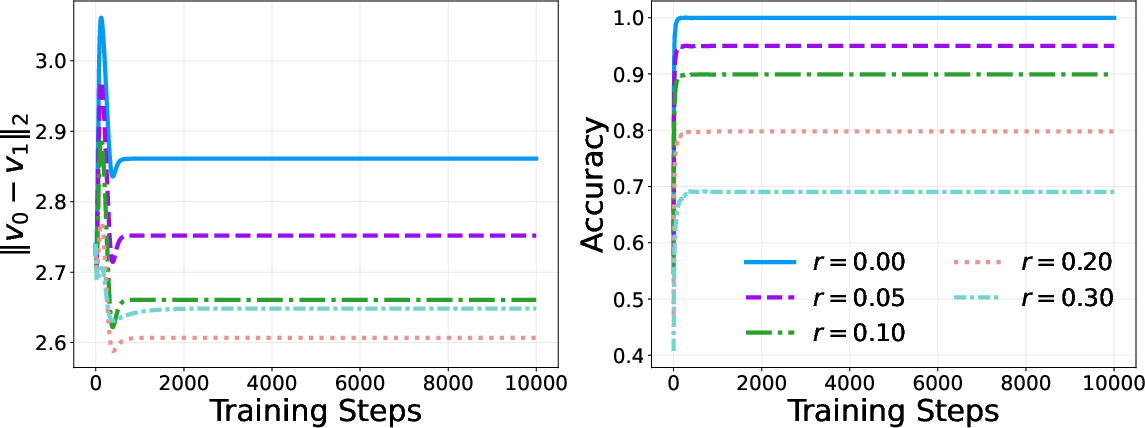
Figure 13: Linear teacher-student with projection head and stop-gradient avoids geometric collapse; label embedding separation quickly reaches a nonzero plateau for all ∼(γN)−16, and accuracy remains optimal up to irreducible frustrated errors.
Practical and Theoretical Implications
The minimal model's findings have direct implications for self-supervised learning protocol design:
- Explicit identification of frustration as the driver of collapse allows for better regularization, data design, and diagnostic strategies in both supervised and unsupervised settings.
- Quantitative clarification of timescales in training dynamics explains transient improvements and late-stage failures, relevant for setting early stopping or tailoring curriculum.
- Rigorous demonstration that stop-gradient is essential for collapse avoidance in projection-based architectures underlines the need for architectural/dynamical asymmetry in SimSiam/BYOL-style methods.
- Spectral decomposition of collapse- and non-collapse directions provides a foundation for further analytical study of larger or nonlinear systems, as well as connections to DMFT and many-body physics.
The empirical persistence of these mechanisms in high-dimensional, linear teacher-student constructions, beyond unstructured embedding settings, suggests the minimal model captures a universal aspect of representation collapse.
Future Directions
Key open directions include:
- Incorporation of intra-class repulsion or sample-level repulsive interactions to more realistically model finite cluster width as observed in real data.
- Investigation of stochasticity (SGD), explicit regularization, and dynamics in non-convex or nonlinear embedding maps, especially using field-theoretical tools (e.g., MSRJD formalism).
- Study of the effect of collapse prevention on downstream transfer and robustness, particularly in high-noise or class-imbalanced regimes.
Conclusion
This paper offers a precise embedding-space theoretical framework for analyzing representation collapse, identifying frustration as its cause, and establishing that collapse can be dynamically prevented only by breaking embedding-branch symmetry via stop-gradient. The minimal model not only aligns with empirical observations in deep learning but also introduces spectral and dynamical mean-field machinery that holds promise for more general, large-scale analyses in machine learning and statistical physics.