- The paper identifies that supervised fine-tuning fails to internalize 15.3% ± 2.1% of training signals, a phenomenon termed Incomplete Learning.
- It introduces a diagnostic framework that attributes unlearned samples to five causal categories, including knowledge deficits and data conflicts.
- Targeted interventions such as continued pre-training and dynamic resampling lead to measurable accuracy gains across diverse benchmarks.
Systematic Diagnosis and Mitigation of Incomplete Learning in Supervised Fine-Tuning of LLMs
Introduction
Supervised Fine-Tuning (SFT) is the prevailing protocol for adapting LLMs to downstream domains. However, a persistent failure mode exists wherein models, after apparent convergence, consistently mispredict a nontrivial subset of the training data—termed the Incomplete Learning Phenomenon (ILP). This behavior is orthogonal to traditional catastrophic forgetting: rather than losing previously acquired abilities, the model fails to assimilate certain supervised signals, even when those signals are repeatedly presented during SFT.
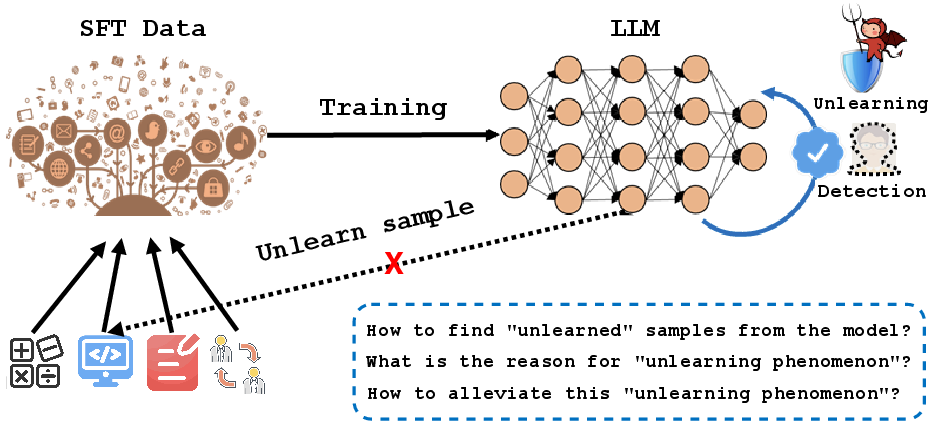
Figure 1: Schematic illustration of ILP, showing that after SFT, some training samples remain unlearned despite being part of the supervision.
This paper systematically characterizes ILP in SFT for LLMs, formalizing it as the model's inability to internalize portions of the supervision signal. The study demonstrates the prevalence of ILP across model architectures (e.g., Qwen, LLaMA, OLMo2), data domains, and benchmarks. It then introduces a diagnostic framework for attributing unlearned samples to causal mechanisms, offering a taxonomy of five distinct categories, and empirically verifies targeted interventions for each.
Framework for Diagnosing and Attributing ILP
The core methodology is a diagnostic-first framework, which decomposes ILP attribution into three phases: (1) supervised fine-tuning, (2) post-SFT detection of unlearned samples, and (3) assignment of unlearned instances to underlying causes based on training/inference signal analysis.

Figure 2: General pipeline: SFT on data, re-evaluate to detect unlearned samples, and process/calibrate for fine-grained diagnosis and remediation.
Unlearned samples are detected by converting free-form outputs to structured multiple-choice (MC) questions, allowing for discrete, stable measurement of training-set performance. An instance is marked as unlearned based on its pass@N or best-of-N (BoN) score under repeated sampling, with robust stability checks to avoid artifacts of stochastic decoding.
Comprehensive empirical surveys across ten SFT datasets show 15.3%±2.1% of supervised instances remain unlearned after SFT convergence—a phenomenon independent of model family or domain.
Taxonomy and Empirical Analysis of Incomplete Learning
The diagnostic pipeline assigns unlearned samples to five causal categories:
- Base Model Knowledge Limitations: The SFT signal presupposes prerequisite knowledge not present in the pre-trained model.
- SFT–Pretraining Conflicts: SFT supervision contradicts high-confidence prior knowledge from pre-training.
- Internal SFT Data Conflicts: Annotation inconsistencies or label contradictions exist within SFT data.
- Left-side Forgetting: Sequential processing of SFT data induces an order bias, with earlier samples being systematically forgotten.
- Insufficient Optimization: Rare or compositional supervision patterns receive inadequate training signal under default SFT regimes.
Attribution relies on knowledge state probing (pre-/post-SFT accuracy, Jensen–Shannon divergence over predictive distributions) and targeted causal interventions.
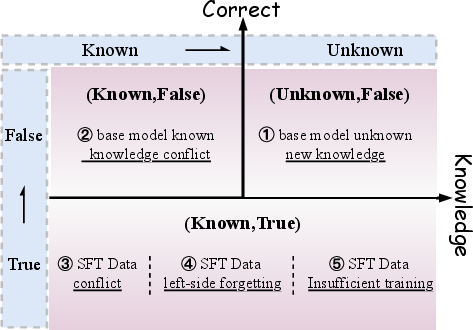
Figure 3: Unlearned sample attribution pipeline: identification, attribute partitioning, and hypothesis testing via targeted interventions.
Targeted Intervention Strategies
1. Knowledge Deficits and Continued Pre-training (CPT)
Instances unlearned due to missing base knowledge are addressed via CPT on an augmented corpus. Blind spots are identified via OpenIE extraction from unlearned samples; external domain knowledge is retrieved and merged ($0.8$ general corpus, $0.2$ domain-augmented) for continued pre-training. Reapplication of SFT over the updated backbone significantly lifts pass@N on in-domain tasks.

Figure 4: CPT-driven accuracy improvements on MedQA, LegalBench, and FinanceBench—highlighting the step-change in domain mastery when missing knowledge is injected pre-SFT.
Quantitatively, CPT yields accuracy gains of 9.4%–14.1%, contrasting with marginal (≤1.5%) benefits of increased SFT epochs.
2. Mitigating SFT–Pretraining Conflicts
When SFT and pretraining are in tension (strong incorrect priors), knowledge conflict detection is performed via confidence thresholding. Targeted CPT on authoritative external sources realigns strong priors—reducing SFT conflict rates by $2.5$–$4.0$ points across all models and benchmarks. Comparative experiments show CPT outperforms naive data deletion and grouping for conflict resolution.
3. Resolving Internal SFT Data Conflicts
Annotation inconsistencies are identified by semantic similarity and judged for correctness by an expert LLM. Conflicting samples are either deleted or bucketed (batched separately during SFT), with dynamic reassignment. Dynamic bucketing improves accuracy by $1.4$–2.8% over baselines, outperforming hard deletion.
4. Addressing Left-side Forgetting
Dynamic resampling and global shuffling counteract recency bias in SFT. For CNN/DailyMail summarization, the ROUGE-L score on early-presented training data is improved by $0.8$0 (from $0.8$1 to $0.8$2), with minimal negative effect on later segments. Periodic performance monitoring further upweights affected batch slices.
5. Adapting to Rare/Complex Patterns
Adaptive epoch strategies with early stopping are used to accommodate dataset heterogeneity. Progressive epoch increments optimize validation performance for challenging subsets, yielding $0.8$3–$0.8$4 accuracy improvements across all model variants.
Implications and Theoretical Considerations
This study underscores the inadequacy of global SFT loss or held-out set accuracy as a surrogate for true knowledge internalization in LLMs. The presence of robust, reproducible unlearned subsets post-convergence exposes fundamental limitations in standard SFT protocols and emphasizes the criticality of knowledge diagnosis at the per-sample level.
The results highlight a nontrivial interplay between pretraining data coverage, fine-tuning expressivity, sequential optimization dynamics, and rare-sample optimization in high-parameter regimes. CPT emerges as a necessary, but not sufficient, tool—especially as domain specialization and continual adaptation become standard operational requirements for LLM deployments.
Experiments on OLMo2-7B reinforce this perspective: targeted CPT can introduce constructive bias where SFT data is in direct conflict or absent from pretraining, but may also cause transient degradation in generalization benchmarks due to representational recalibration. This complexity underlines the need for context-aware, fine-grained adaptation frameworks.
Conclusion
The paper delivers a comprehensive taxonomy, diagnostic protocol, and intervention toolkit for understanding and mitigating ILP in supervised fine-tuning of LLMs (2604.10079). Theoretical and empirical evidence converges on the necessity of moving from performance-centric to learning-centric SFT evaluation, with rigorous sample-level diagnostics. Advanced adaptation strategies—including targeted knowledge injection, dynamic resampling, and conflict-aware data organization—demonstrate substantial efficacy in closing persistent learning gaps.
Future research should explore scalable diagnostic automation, curriculum-driven interventions that leverage ILP signals, and robust evaluation frameworks for tracking internalization of supervision in increasingly large and specialized LLMs.
References
For full references, see the original paper (2604.10079).