Wolkowicz-Styan Upper Bound on the Hessian Eigenspectrum for Cross-Entropy Loss in Nonlinear Smooth Neural Networks
Published 11 Apr 2026 in cs.LG, cs.AI, and cs.NE | (2604.10202v2)
Abstract: Neural networks (NNs) are central to modern machine learning and achieve state-of-the-art results in many applications. However, the relationship between loss geometry and generalization is still not well understood. The local geometry of the loss function near a critical point is well-approximated by its quadratic form, obtained through a second-order Taylor expansion. The coefficients of the quadratic term correspond to the Hessian matrix, whose eigenspectrum allows us to evaluate the sharpness of the loss at the critical point. Extensive research suggests flat critical points generalize better, while sharp ones lead to higher generalization error. However, sharpness requires the Hessian eigenspectrum, but general matrix characteristic equations have no closed-form solution. Therefore, most existing studies on evaluating loss sharpness rely on numerical approximation methods. Existing closed-form analyses of the eigenspectrum are primarily limited to simplified architectures, such as linear or ReLU-activated networks; consequently, theoretical analysis of smooth nonlinear multilayer neural networks remains limited. Against this background, this study focuses on nonlinear, smooth multilayer neural networks and derives a closed-form upper bound for the maximum eigenvalue of the Hessian with respect to the cross-entropy loss by leveraging the Wolkowicz-Styan bound. Specifically, the derived upper bound is expressed as a function of the affine transformation parameters, hidden layer dimensions, and the degree of orthogonality among the training samples. The primary contribution of this paper is an analytical characterization of loss sharpness in smooth nonlinear multilayer neural networks via a closed-form expression, avoiding explicit numerical eigenspectrum computation. We hope that this work provides a small yet meaningful step toward unraveling the mysteries of deep learning.
The paper provides a closed-form analytical upper bound on the Hessian eigen-spectrum of cross-entropy loss in smooth nonlinear networks.
It derives explicit expressions for Hessian trace and squared trace, revealing the impact of output weight norms and hidden layer width on sharpness.
Empirical results confirm that flatter minima, indicated by lower sharpness bounds, correspond with more stable generalization performance.
Analytical Upper Bounds on Hessian Sharpness in Nonlinear Smooth Neural Networks
Introduction
A major unresolved problem in deep learning theory is the precise analytical characterization of generalization, particularly the connection between loss landscape geometry and out-of-sample performance. It is well-established that the sharpness of a minimum, often quantified by the largest Hessian eigenvalue at a critical point, correlates with generalization: flatter minima typically lead to better generalization, while sharper ones are associated with degraded performance. While previous works have either used numerics or addressed only restrictive network classes (e.g., linear/ReLU models), general closed-form results for nonlinear, smooth multilayer networks remain absent. This work addresses that gap by providing a closed-form analytical upper bound on the maximum Hessian eigenvalue for the cross-entropy loss in smooth, nonlinear multilayer neural networks, leveraging the Wolkowicz-Styan bound.
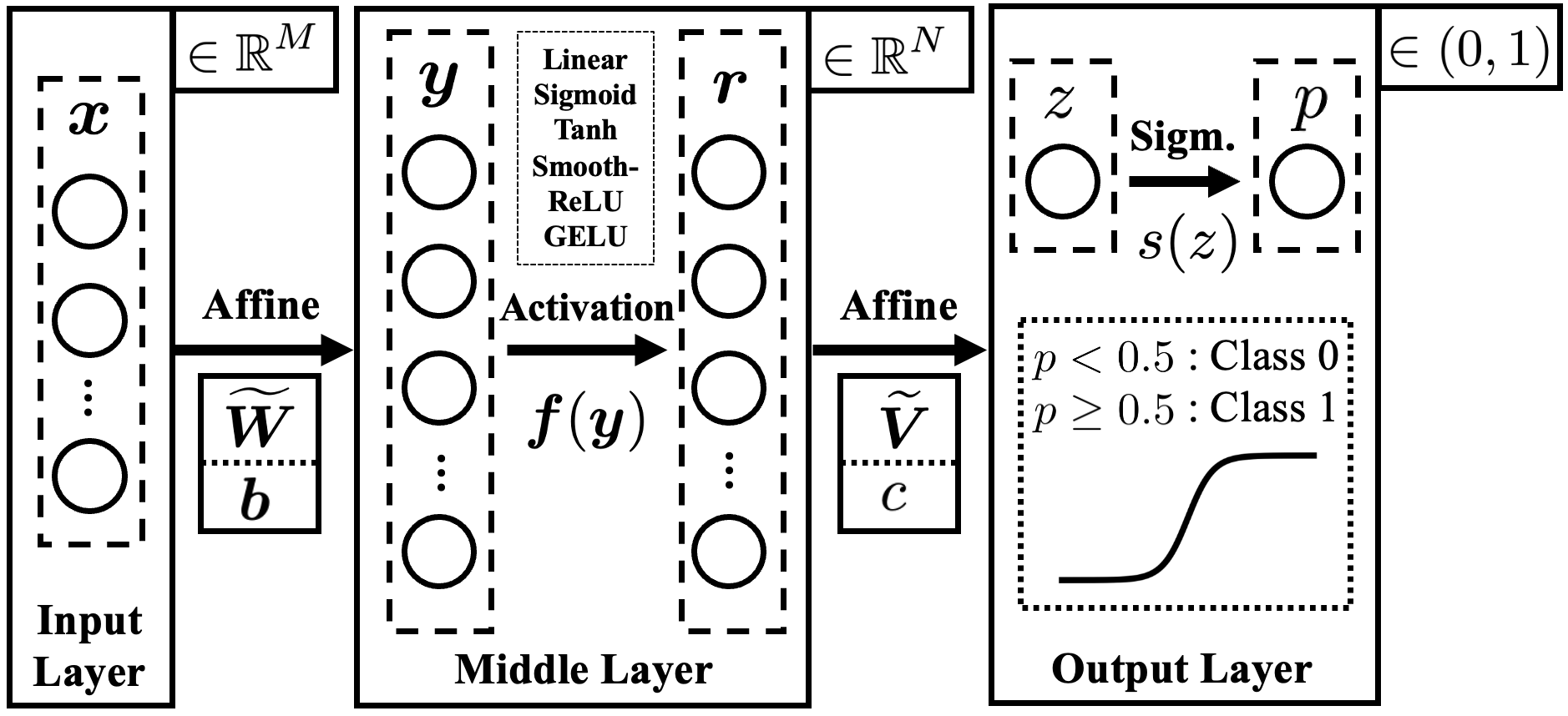
Figure 1: The NN architecture analyzed in this study.
Theoretical Framework and Main Results
The focus is on three-layer feedforward NNs for binary classification, parameterized with affine layers and a rich selection of activation functions (linear, Sigmoid, Tanh, SoftPlus, GELU). The analysis centralizes on the Hessian HL(θ,θ) of the total cross-entropy loss at critical points, whose maximum eigenvalue (λ1) quantifies sharpness.
Given the analytical intractability of eigenvalue computation for high-dimensional Hessians, the Wolkowicz-Styan bound is invoked:
λ1≤λsup(θ)=μ(θ)+D−1σ(θ),
where μ(θ) and σ2(θ) are, respectively, the mean and variance of the Hessian's eigenvalues, calculable as normalized traces of the Hessian and its square. The major technical achievement is providing explicit, closed-form expressions for the trace and squared trace of the Hessian in these networks, as functions of the model parameters, activation derivatives, network dimensions, and sample geometry.
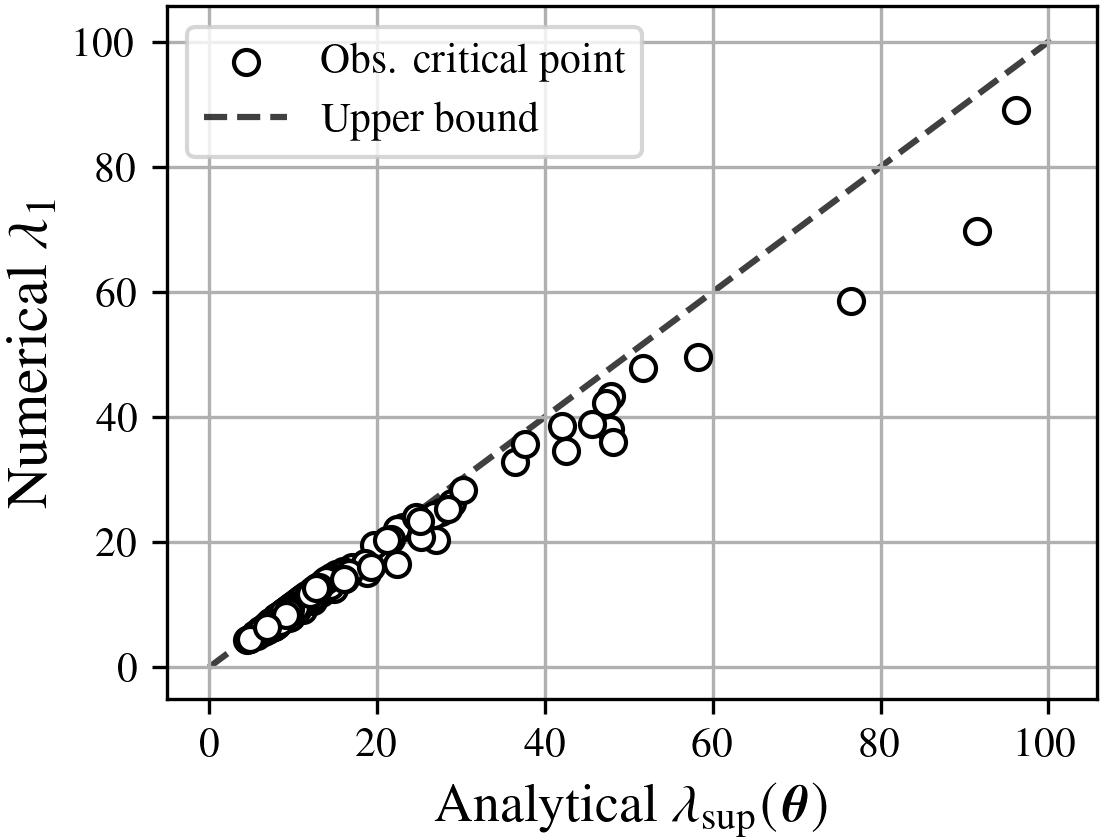
Figure 2: Relationship between the maximum eigenvalues at various critical points and their respective upper bounds. The numerically computed eigenvalues are closely tracked by the analytical upper bounds.
Empirical Evaluation and Spectral Sharpness-Performance Correlation
Empirical analysis confirms that this analytical upper bound is tight in practice (Figure 2). The geometric implications are directly visualized: large values of λsup correspond to highly non-flat loss basins with irregular, distorted decision boundaries, while small values produce smooth boundaries and flatter critical regions.
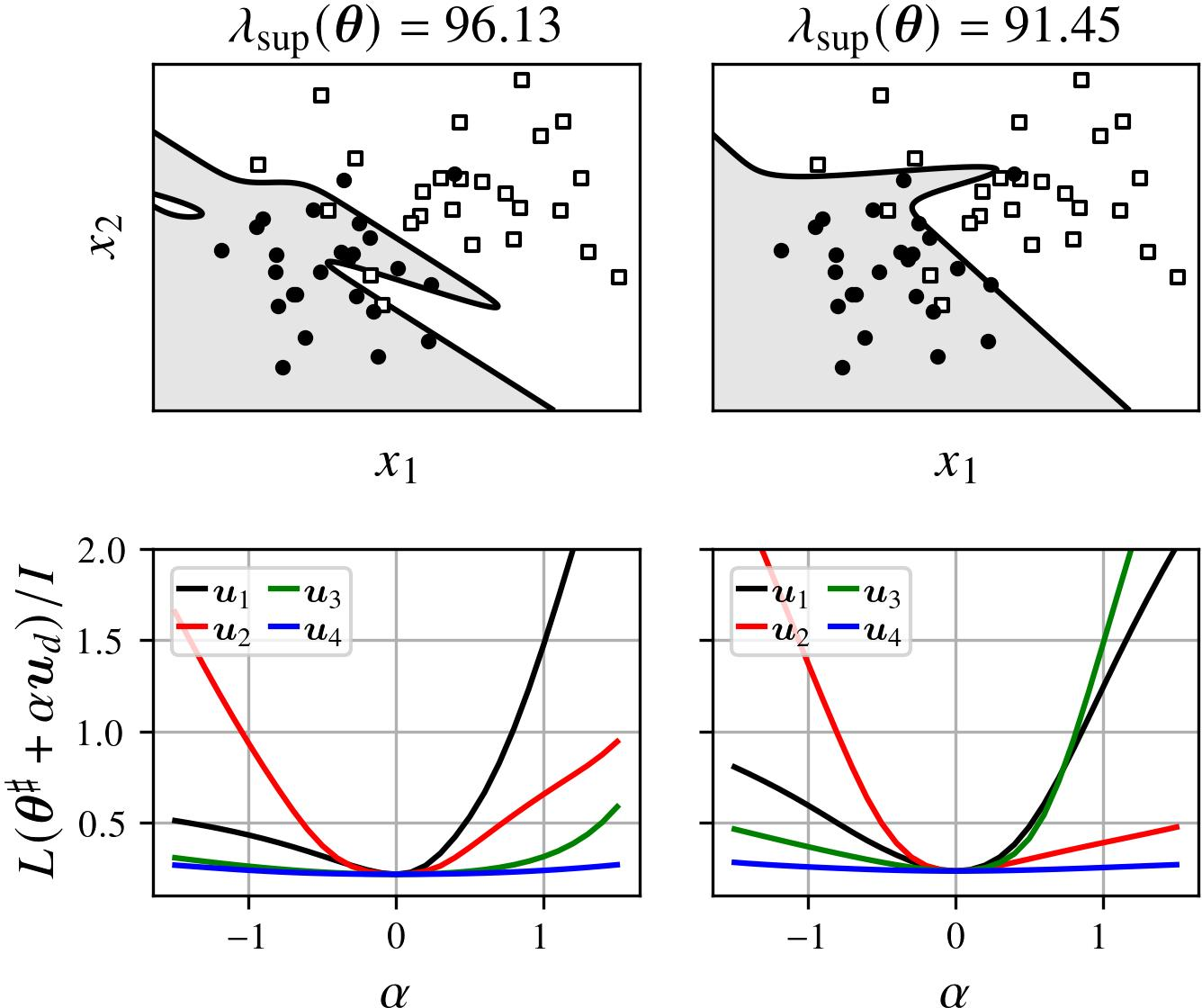
Figure 3: (Top) Decision boundaries for models with the two largest sharpness upper bounds, showing highly irregular boundaries; (Bottom) one-dimensional loss slices along principal Hessian eigenvectors.
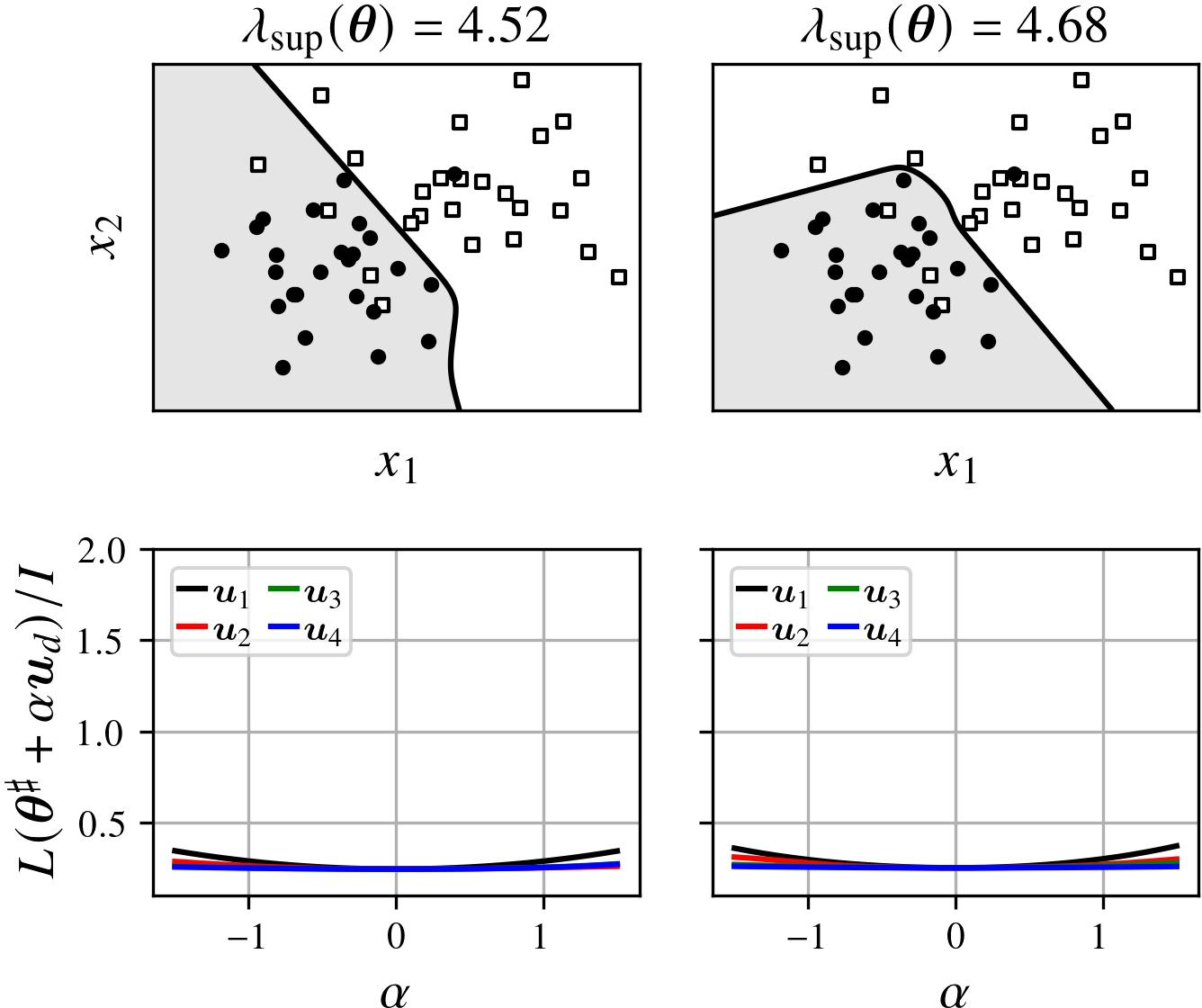
The effects are reversed in minima achieving low λsup, which realize flat basins and stable generalization behavior:
Figure 4: Cases where the sharpness upper bound is smallest. The decision boundaries are less distorted, and the loss varies slowly along principal directions.
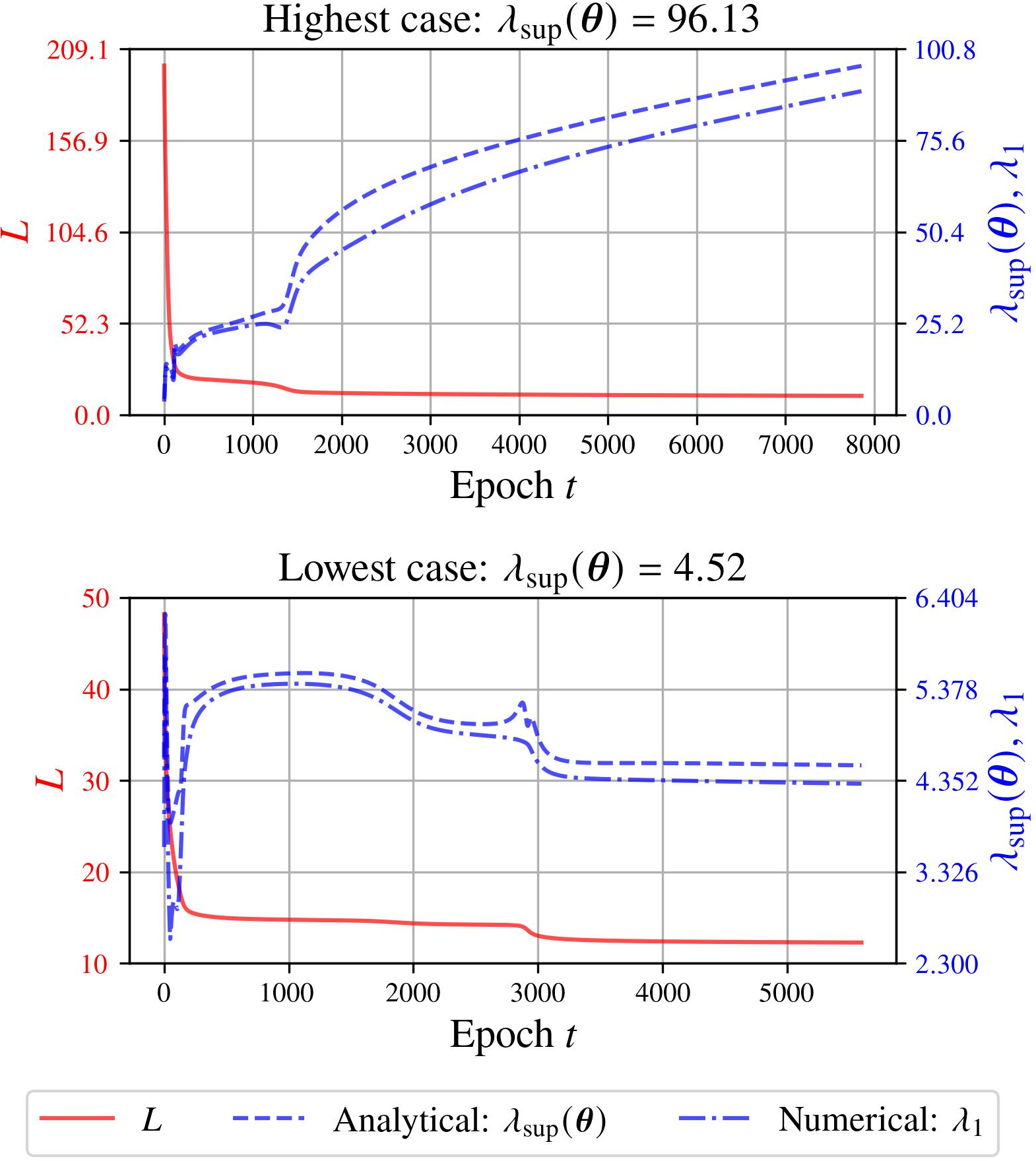
Longitudinal training dynamics further reveal two distinct regimes: some trajectories see the loss decrease without increased sharpness, while others experience divergent sharpness despite successful nominal optimization.
Figure 5: Dynamics of loss, sharpness upper bound, and maximum eigenvalue over training epochs for cases with highest and lowest sharpness.
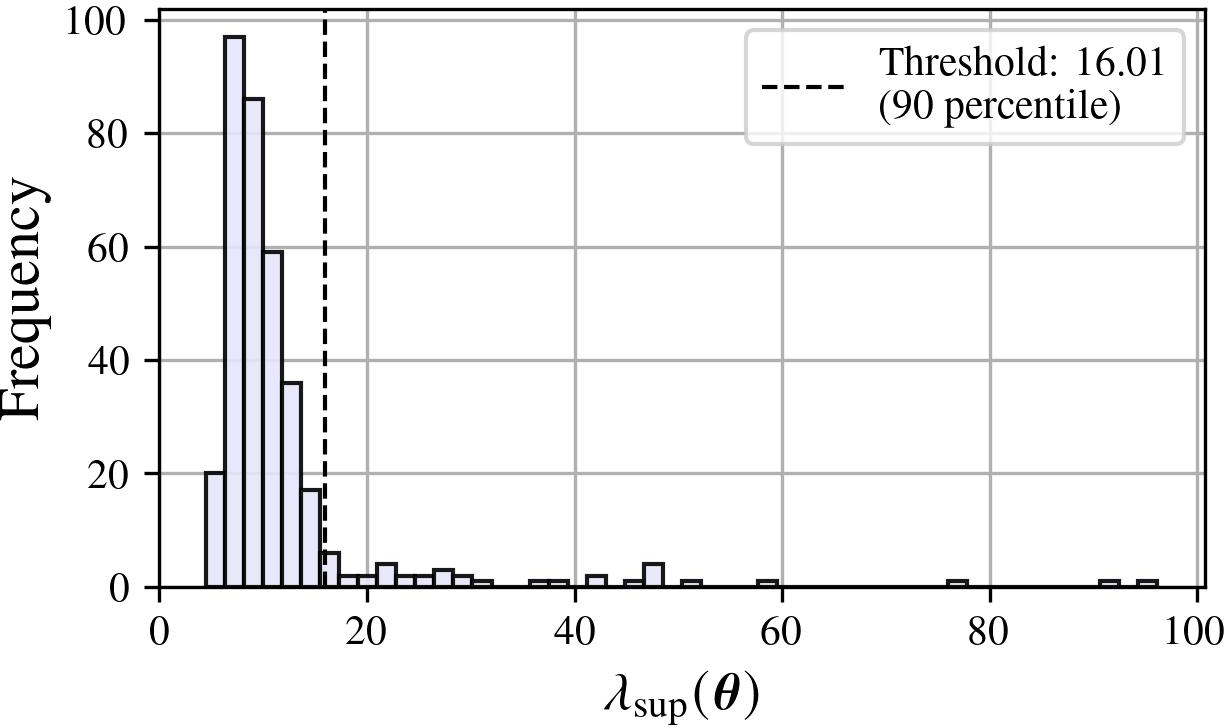
Distributional evidence indicates that, empirically, most critical points reached by gradient descent are relatively flat, but there is a long tail of rare, highly sharp minima.
Figure 6: Distribution of maximum eigenvalue upper bounds across all critical points. The bulk is concentrated at low values, but there exists a significant sharpness outlier tail.
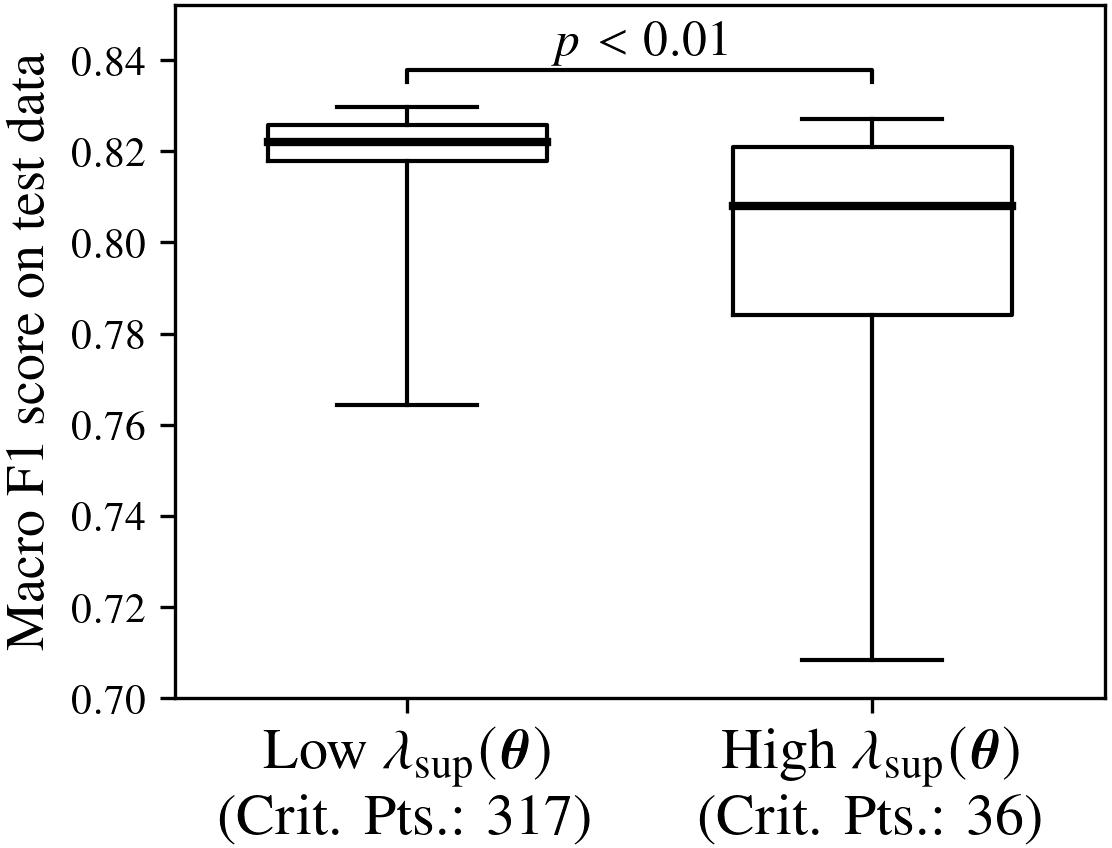
There is a statistically significant correlation between test macro F1-score and λsup: critical points with high sharpness incur notably lower and more variable test performance.
Figure 7: Relationship between the sharpness bound and macro F1-score; sharper minima produce worse and more unstable generalization.
Analytical Structure and Architectural Dependence
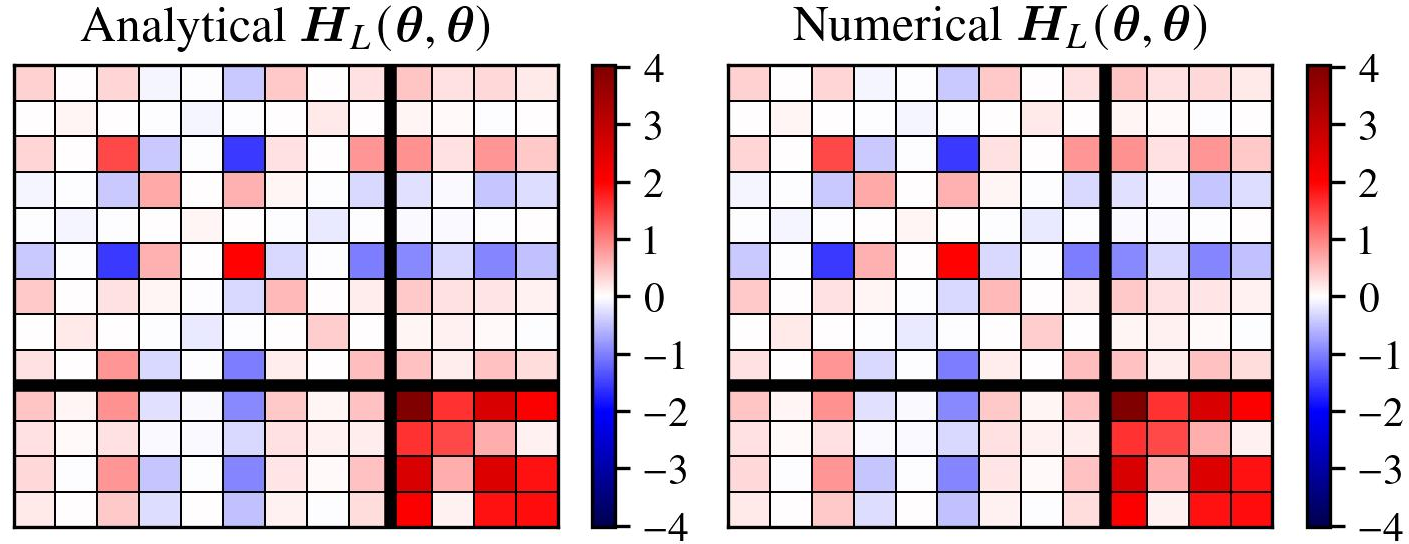
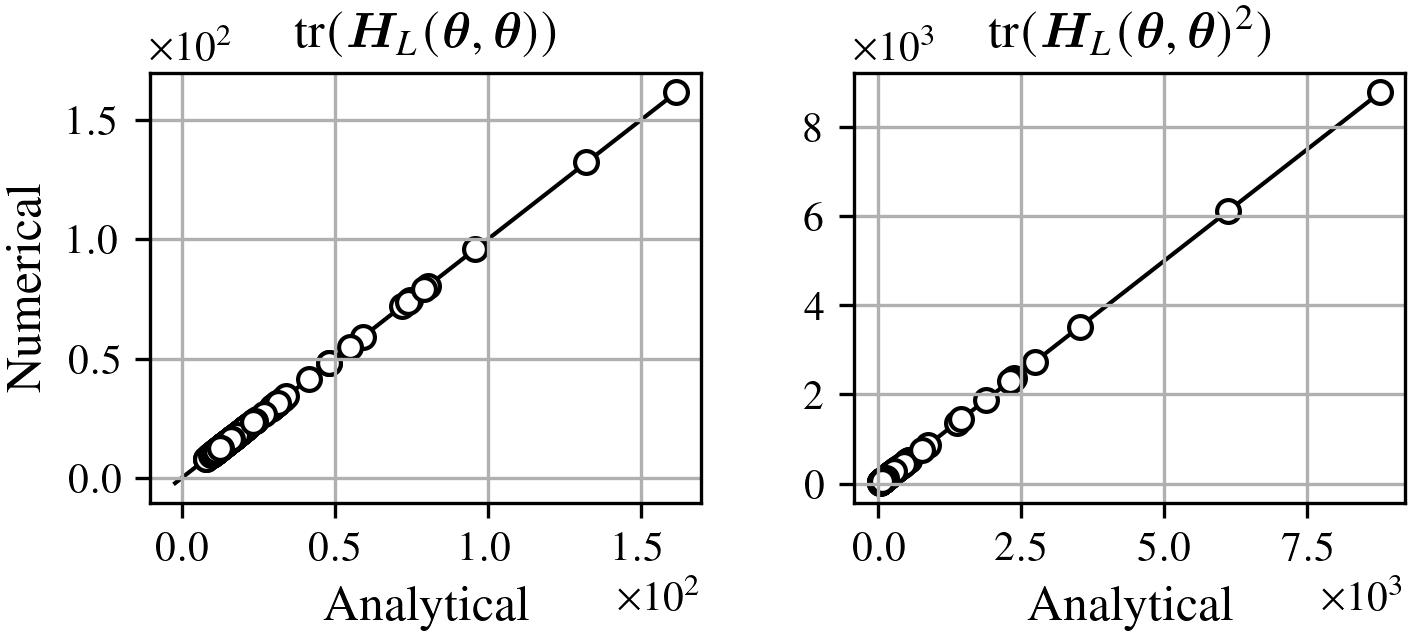
The explicit expressions for the sharpness upper bound decompose into contributions from network parameters (notably the Frobenius norm of output weights) and inner products among input/hidden representations. Visual agreement between analytical and numerical Hessians (Figure 8) and traces (Figure 9) validate these derivations.
Figure 8: Hessian block structure for a critical point; analytical versus numerical comparison.
Figure 9: Analytical and numerical agreement for Hessian trace and squared trace across all observed critical points.
The critical determinants of sharpness, as predicted by the formulas and confirmed by experiment, are:
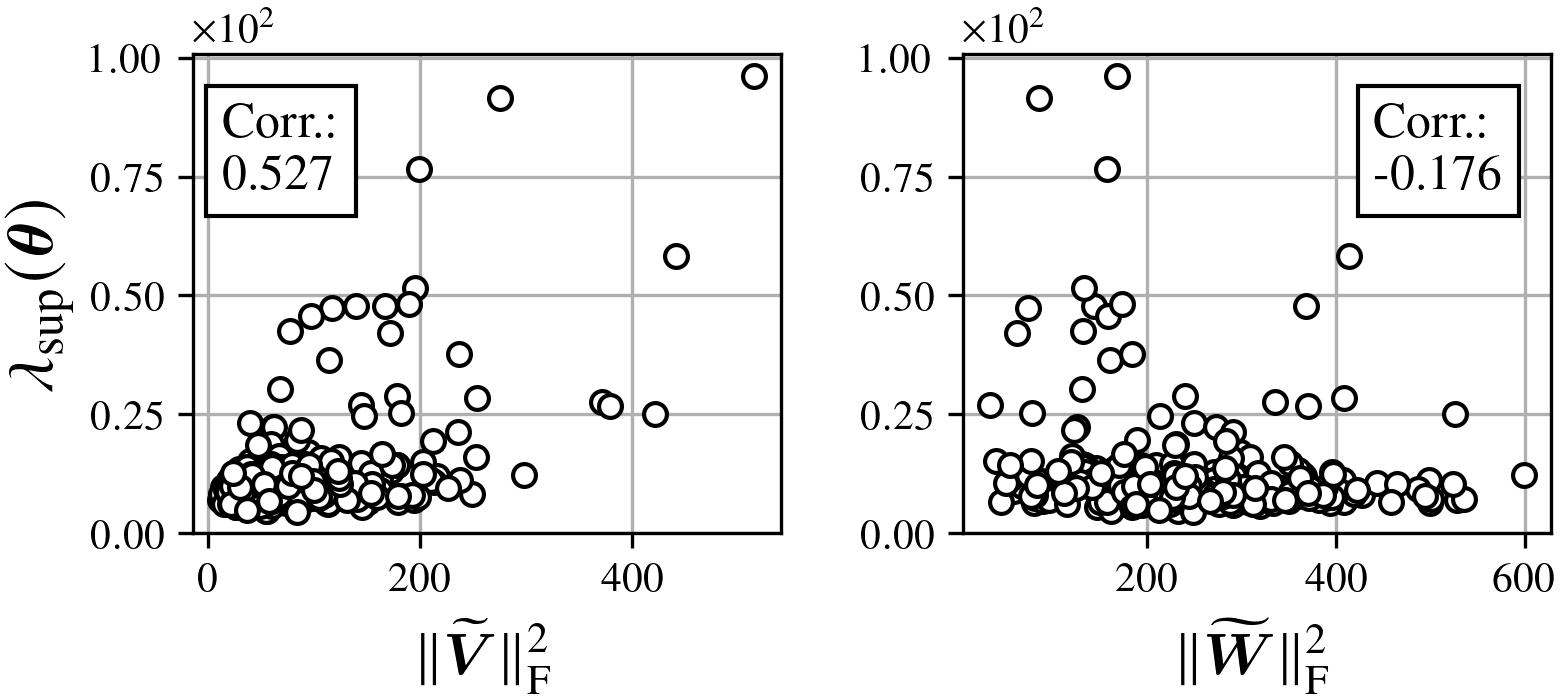
Norm of Output Layer Weights: The upper bound grows with ∥V∥F2, while input layer weights have negligible effect.
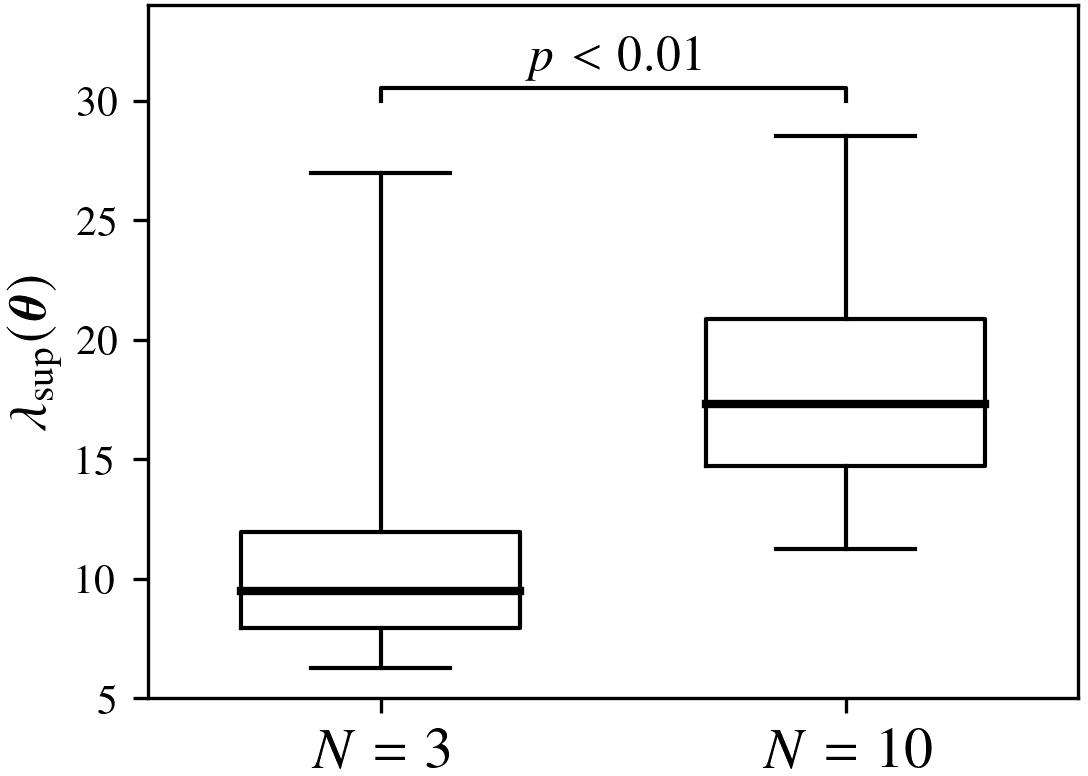
Hidden Layer Width: Increasing the hidden layer dimension N increases sharpness; this is confirmed via statistically significant differences in sharpness at different λ10.
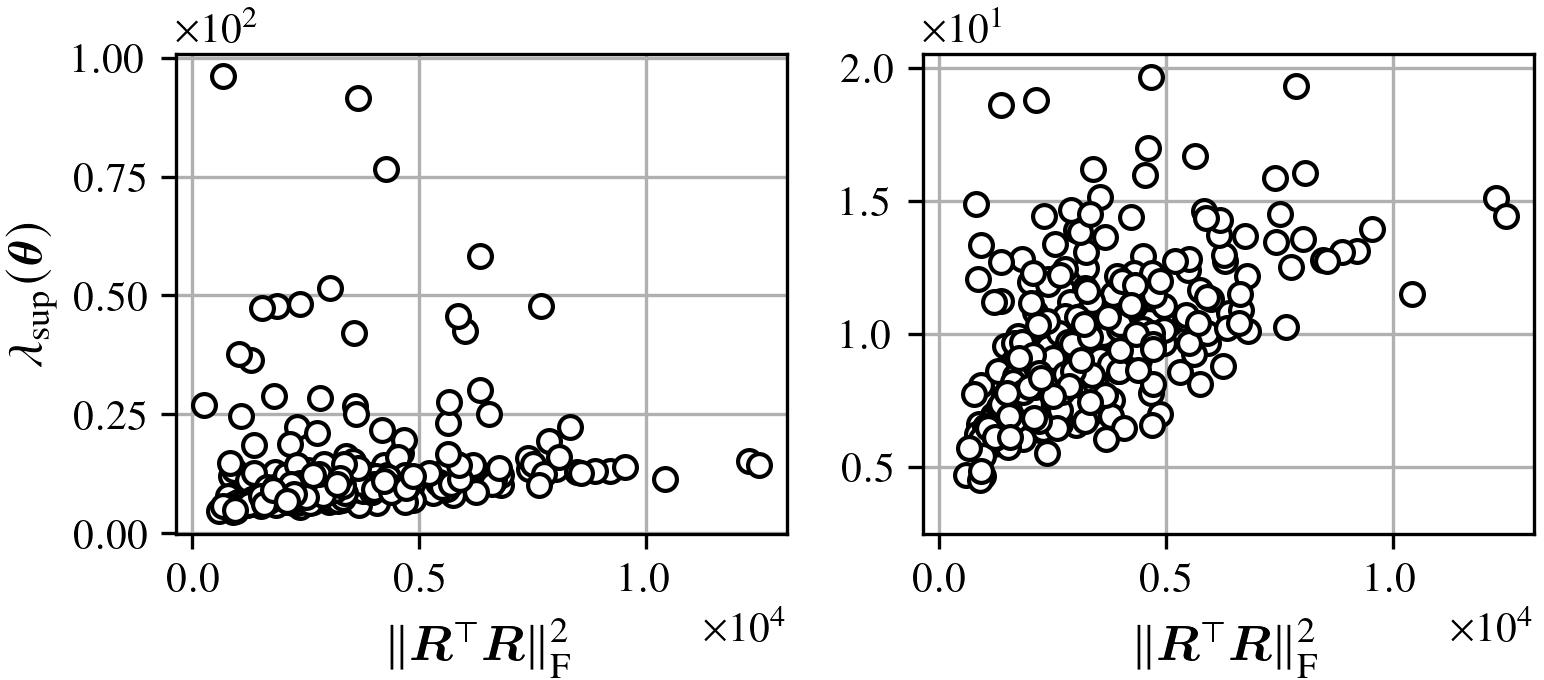
Orthogonality of Representations: The Frobenius norm of the hidden representation Gram matrix, λ11, is positively correlated with the sharpness bound. More correlated representations lead to sharper minima.
Figure 10: Relationship between the Frobenius norms of output (left) and input (right) parameters and the sharpness upper bound; only output-layer-scale is predictive.
Figure 12: Sharpness upper bound versus hidden representation orthogonality; higher correlations (larger norm) yield higher lower bounds for sharpness.
Activation Nonlinearities
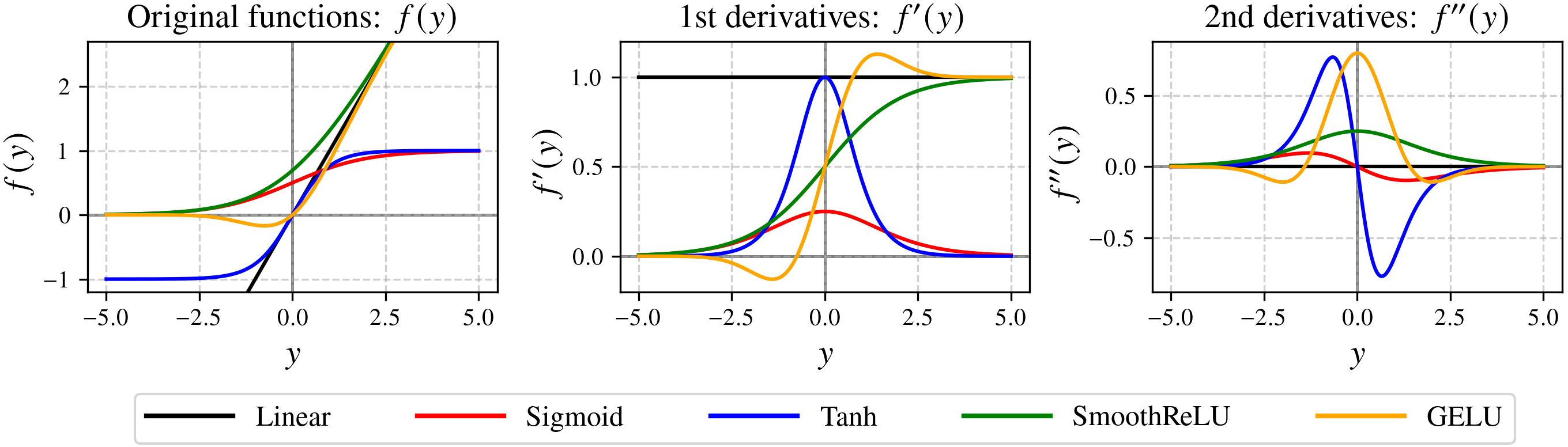
The analysis incorporates a suite of smooth activation functions, providing explicit treatment of their derivative bounds, which feed directly into the sharpness upper bound formulas. Figure 13 collects the activations and their first/second derivatives.
Figure 13: Activation function λ14 and its first and second derivatives for all nonlinearities covered in the analysis.
Discussion and Implications
This work resolves a technical bottleneck in the theory of deep NNs: the derivation of closed-form, data- and parameter-dependent upper bounds on sharpness for smooth nonlinear models. The results establish several quantitative, explicit design guidelines:
Controlling the norm of output-layer weights is critical for flatness and, thus, generalization. Regularization strategies should preferentially penalize these parameters.
Increasing network width without regularization or architectural constraints inherently increases sharpness risk.
Training protocols or architectures promoting more orthogonal representation geometry (e.g., orthogonal regularization, dataset augmentation for diversity) will reduce sharpness and improve generalization reliability.
Overfitting to the absolute training optimum (very small loss) drives the sharpness bound to zero, illustrating that sharpness and generalization are not perfectly aligned in the extreme overfitting regime—this caveat should be considered for interpretability.
These results immediately facilitate sharper, more principled regularization, model selection, and training strategies for deep learning, especially in settings involving smooth nonlinearities.
Conclusion
The presented analysis offers, for the first time, an explicit closed-form upper bound for the largest Hessian eigenvalue—i.e., loss landscape sharpness—in smooth nonlinear multilayer neural networks trained with cross-entropy loss. This advance connects the spectrum of the Hessian to interpretable architectural and data-driven quantities (parameter norms, network width, representation geometry), providing powerful analytical tools for both theoretical understanding and practical NN design. Extensions to deeper architectures and the inclusion of non-smooth activations remain for future investigation, with the expectation that these techniques will further tighten the theoretical–empirical link in deep learning research.
Reference:
"Wolkowicz-Styan Upper Bound on the Hessian Eigenspectrum for Cross-Entropy Loss in Nonlinear Smooth Neural Networks" (2604.10202).