- The paper demonstrates that no single LLM excels across all healthcare tasks, highlighting significant trade-offs between factual retrieval and semantic accuracy.
- It employs standardized medical tasks—including MCQ answering, evidence reasoning, and clinical note summarization with BLEU, ROUGE-L, and BERTScore—to compare performance.
- Findings advocate a hybrid task-routing approach, suggesting domain-specific models like ChatDoctor for safety-critical applications while using general models for administrative tasks.
Comparative Evaluation of LLMs in Healthcare
Introduction and Motivation
The expansion of LLMs into the healthcare sector introduces advanced support for clinical decision-making, patient interaction, and medical documentation due to their capabilities in text comprehension, summarization, and generative tasks. However, deployment within high-stakes clinical settings exposes inherent risks of inaccuracy, unreliability, and data hallucination, underscoring the necessity for rigorous, task-specific benchmarking. Existing literature has inadequately addressed systematic comparative evaluation of LLMs for healthcare, often focusing on proprietary datasets, single domains, or coarse-grained metrics.
The study systematically benchmarks five LLMs—ChatGPT, LLaMA, Grok, Gemini, and ChatDoctor—across representative medical NLP tasks to delineate their respective strengths, limitations, and suitability for clinical integration.
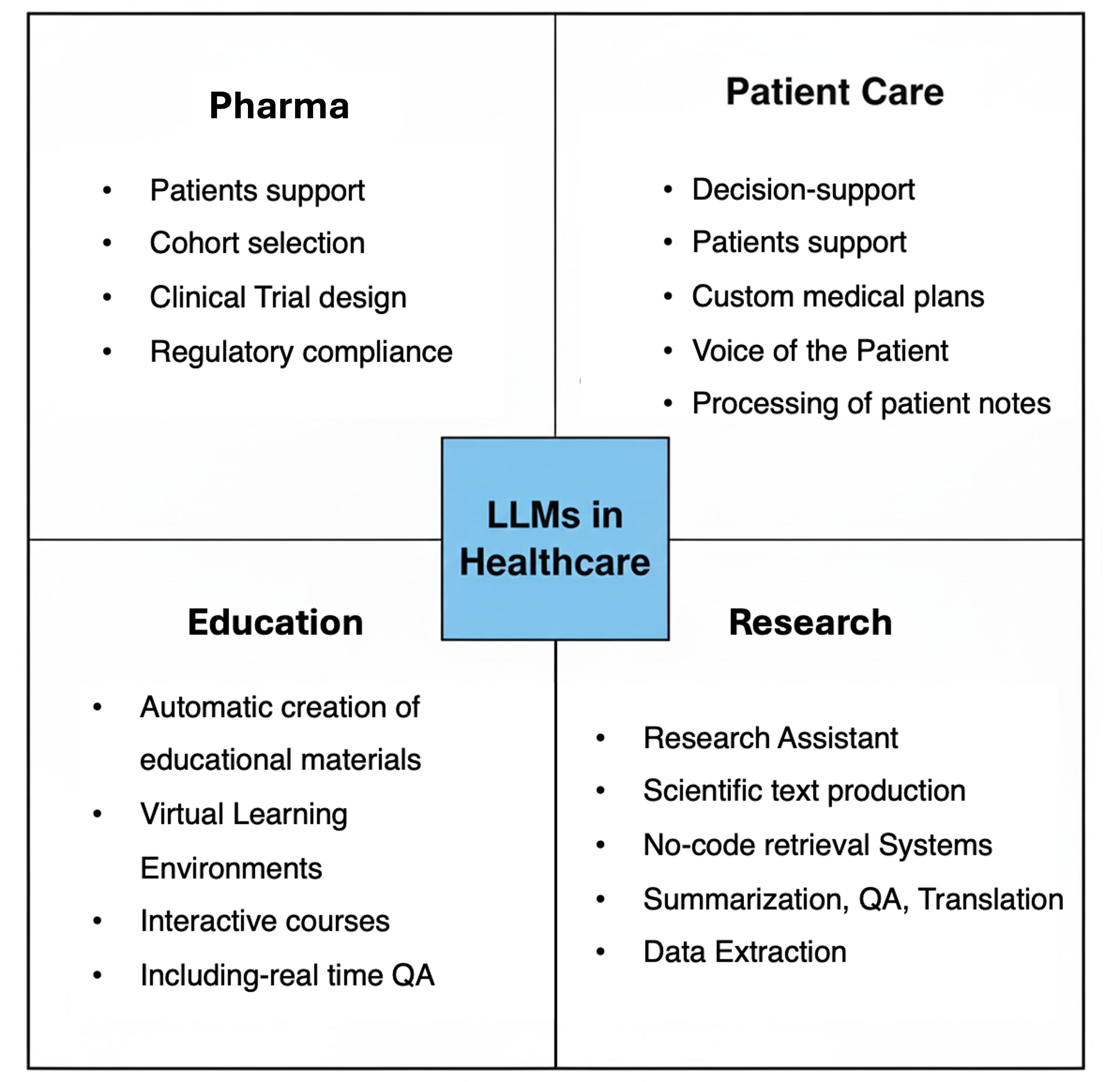
Figure 1: LLMs supporting tasks such as clinical documentation, patient triage, literature search, summarization, and patient-facing chatbots in healthcare.
Task Domains, Hallucinations, and Evaluation Protocol
The selected tasks span: (1) medical multiple-choice question answering (MedMCQA), (2) research evidence-based yes/no/maybe reasoning (PubMedQA), and (3) clinical note summarization (Asclepius). This design assesses both discriminative and generative capabilities for factual recall, nuanced reasoning, and semantic text generation. Standardized prompt templates and evaluation metrics were applied across all models to ensure comparability. Medical hallucinations are categorized in the study as factual, logical, or random, aligning with known risk modes for LLMs in clinical settings.
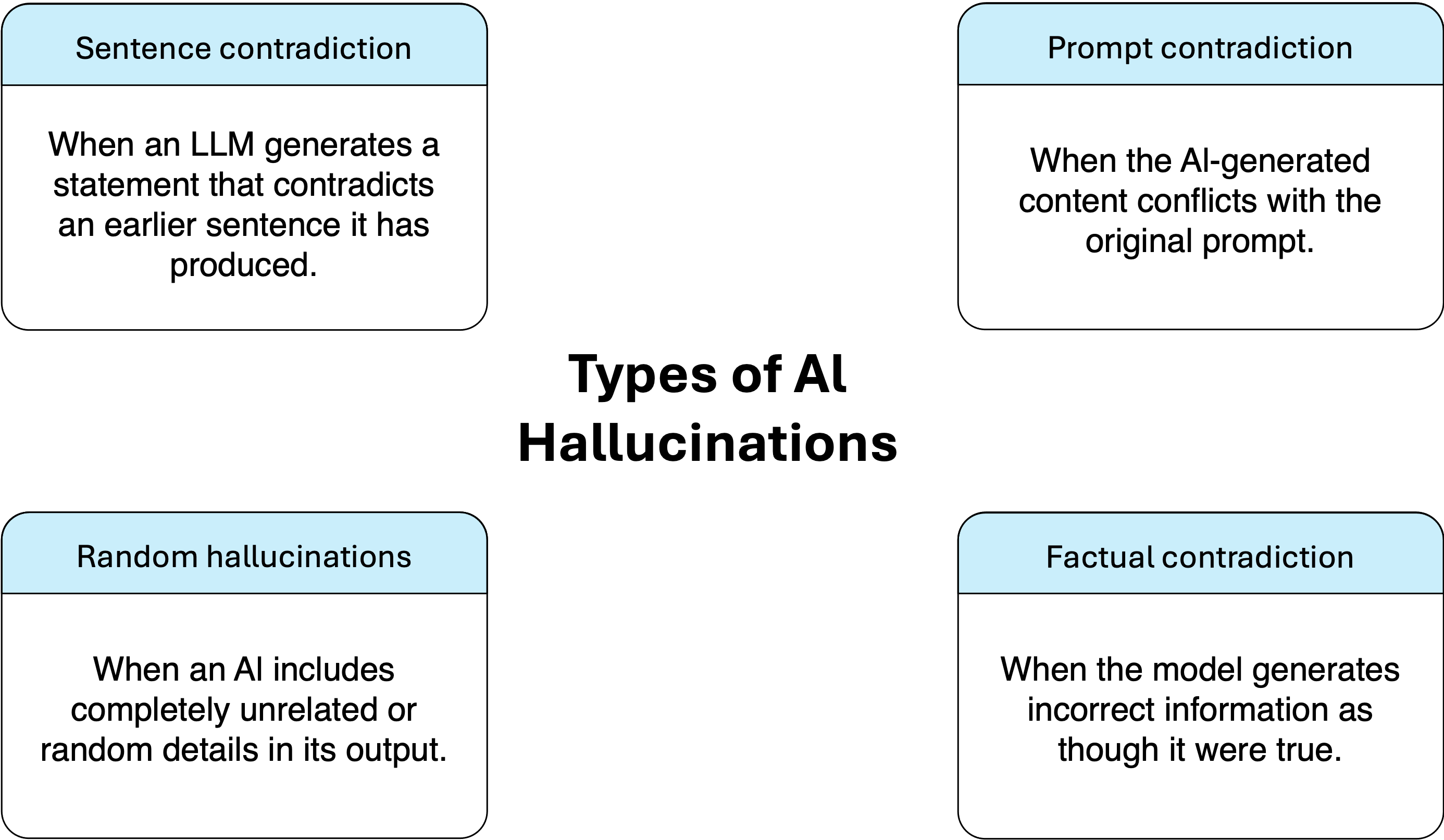
Figure 2: Factual, logical, and random hallucination types with clinical ramifications for model-generated outputs.
Model Selection and Dataset Curation
The study incorporates both domain-specific and general-purpose LLMs:
- ChatDoctor: LLaMA-derivative, fine-tuned with medical corpora and enforced safety alignment
- Grok 3 Mini, Gemini 2.5 Flash Lite, GPT-4o-Mini: Modern, general-purpose architectures of varying parameter efficiency and inference latency
- LLaMA-3.1-8B: Representative, open-source baseline for reproducibility
Tasks are evaluated on robust, open datasets—MedMCQA (183k MCQs), PubMedQA (1k annotated questions), and Asclepius (2k synthetic clinical notes)—subjected to normalization and metadata stripping for consistent downstream analysis.
Medical Question Answering (MedMCQA, PubMedQA)
In MCQ answering, all models achieved accuracy in the 0.711–0.833 range, with high Macro-F1, reflecting reliable knowledge retrieval across broad medical subdomains. For PubMedQA, which demands interpretation of biomedical research and uncertainty reasoning, accuracy ranged from 0.592–0.794, with lower Macro-F1 (0.283–0.379), pinpointing a limitation in class-balancing and uncertainty detection.
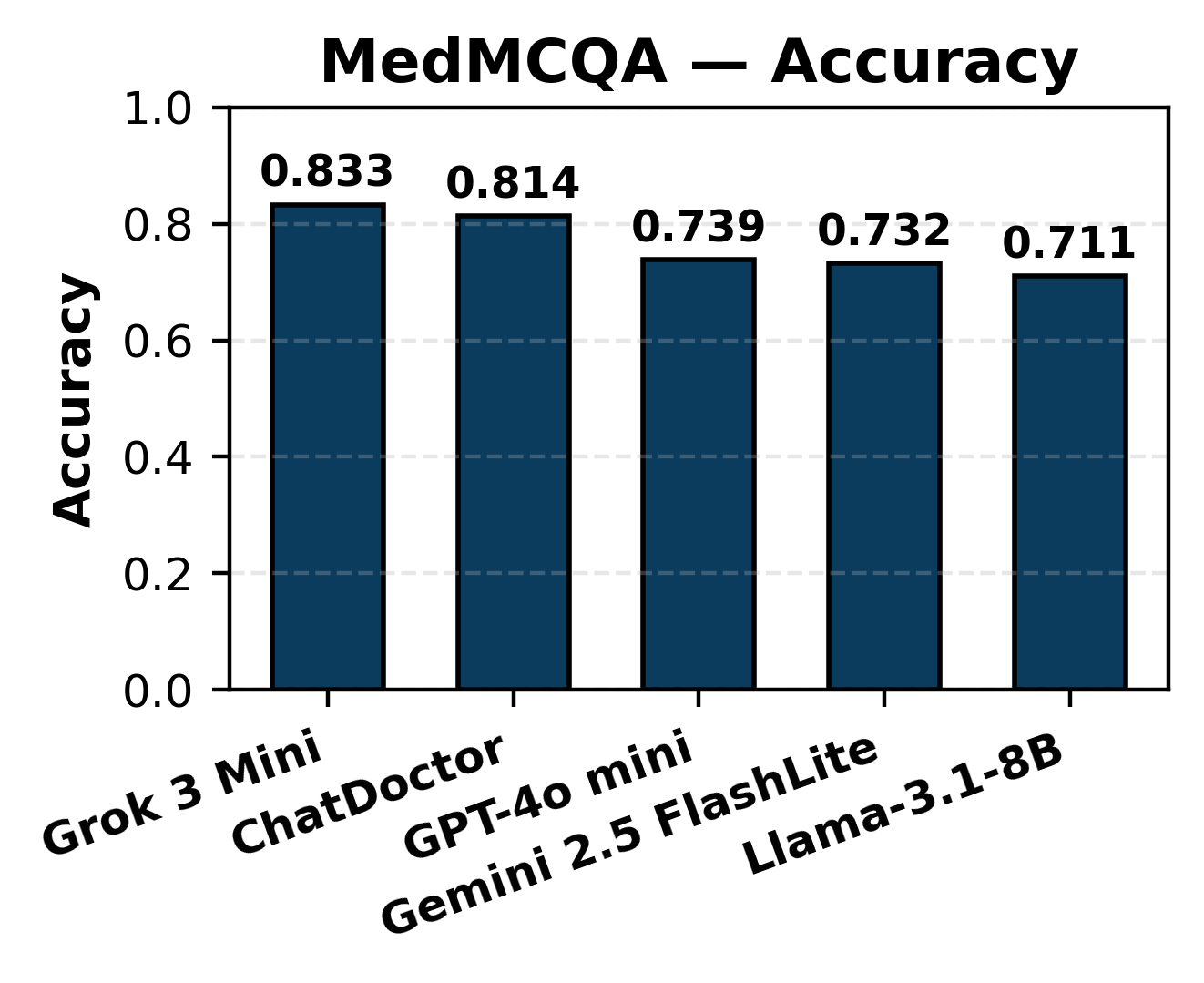
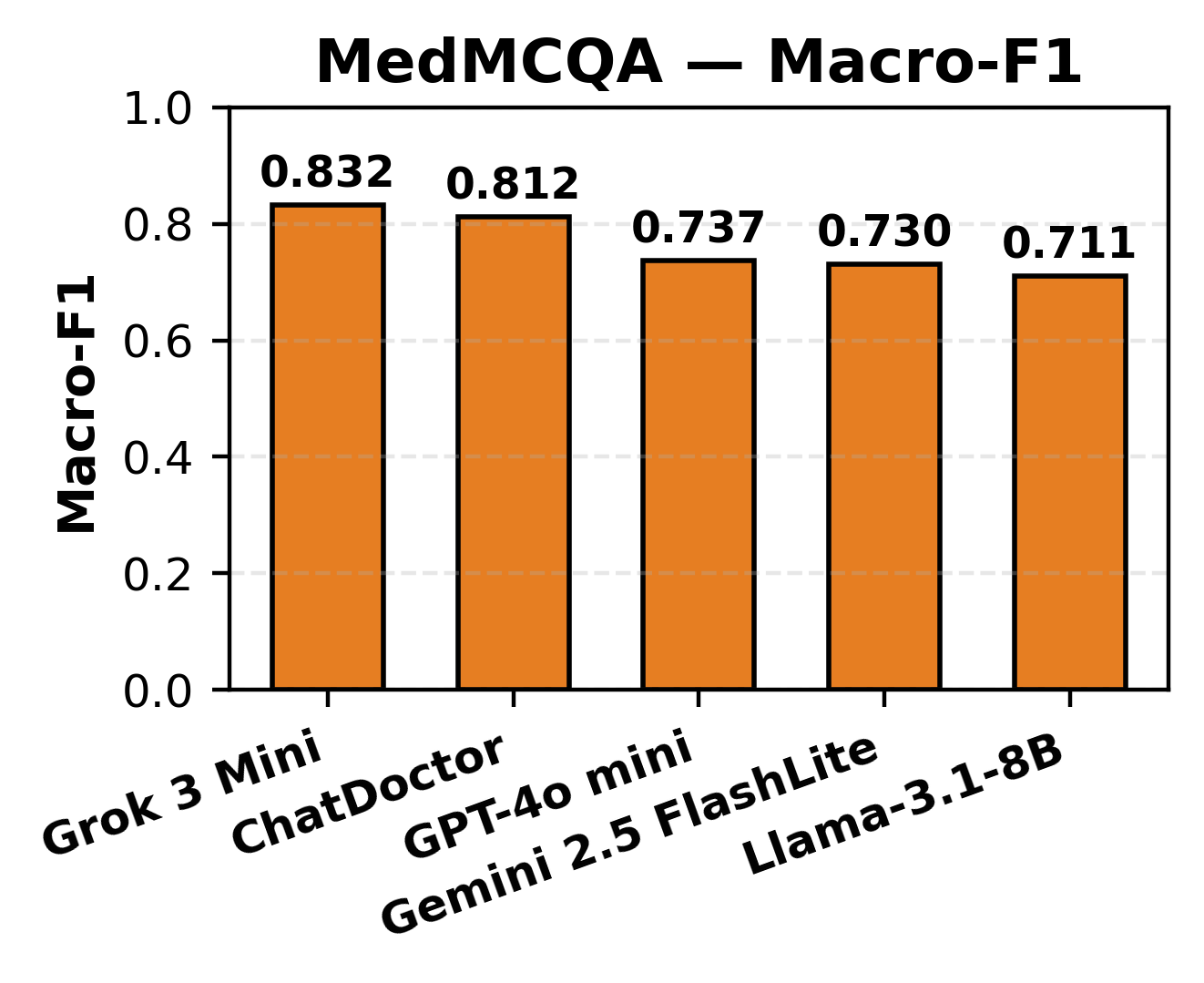
Figure 3: MCQ accuracy distribution across LLMs highlighting uniformity in baseline recall on MedMCQA.
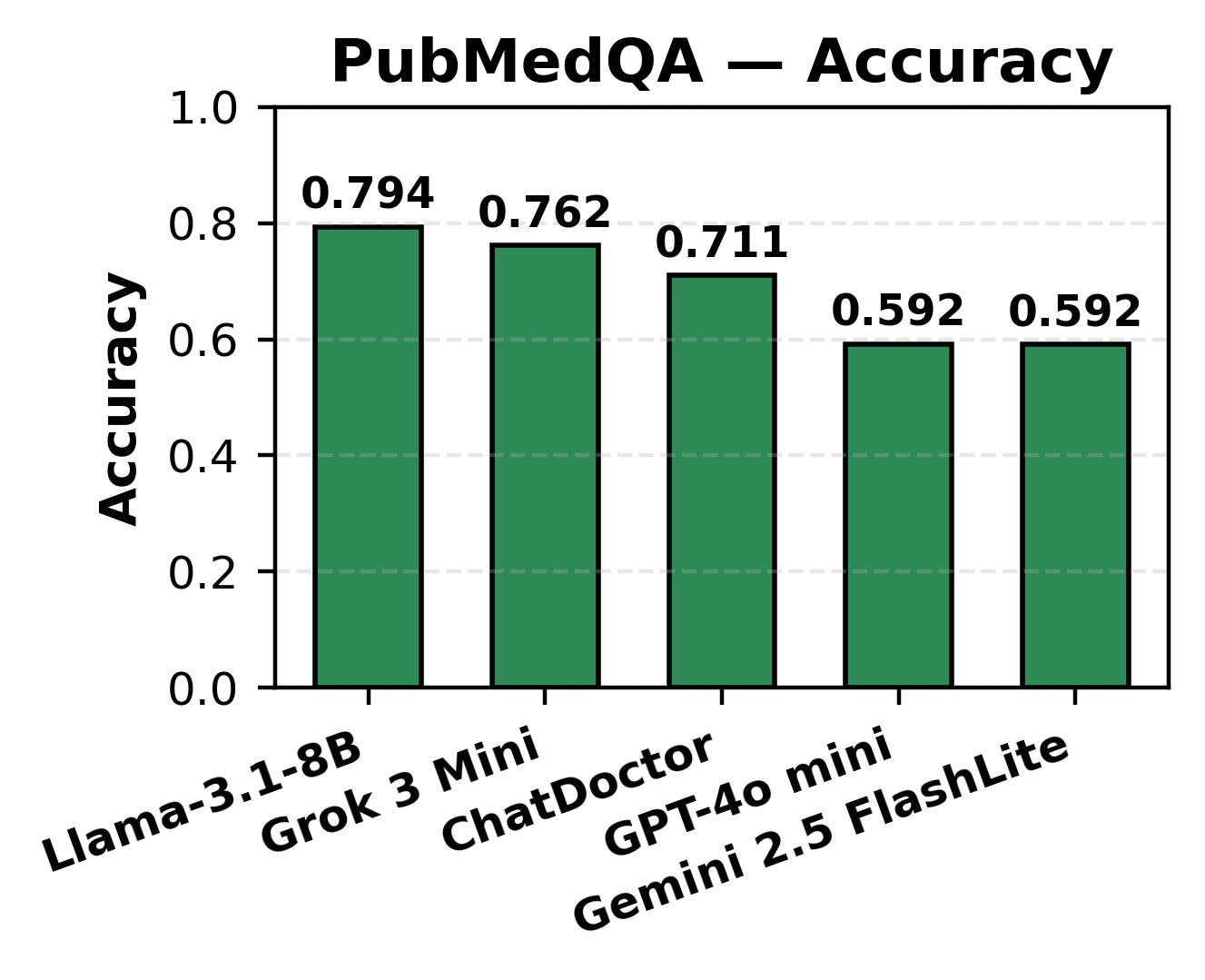
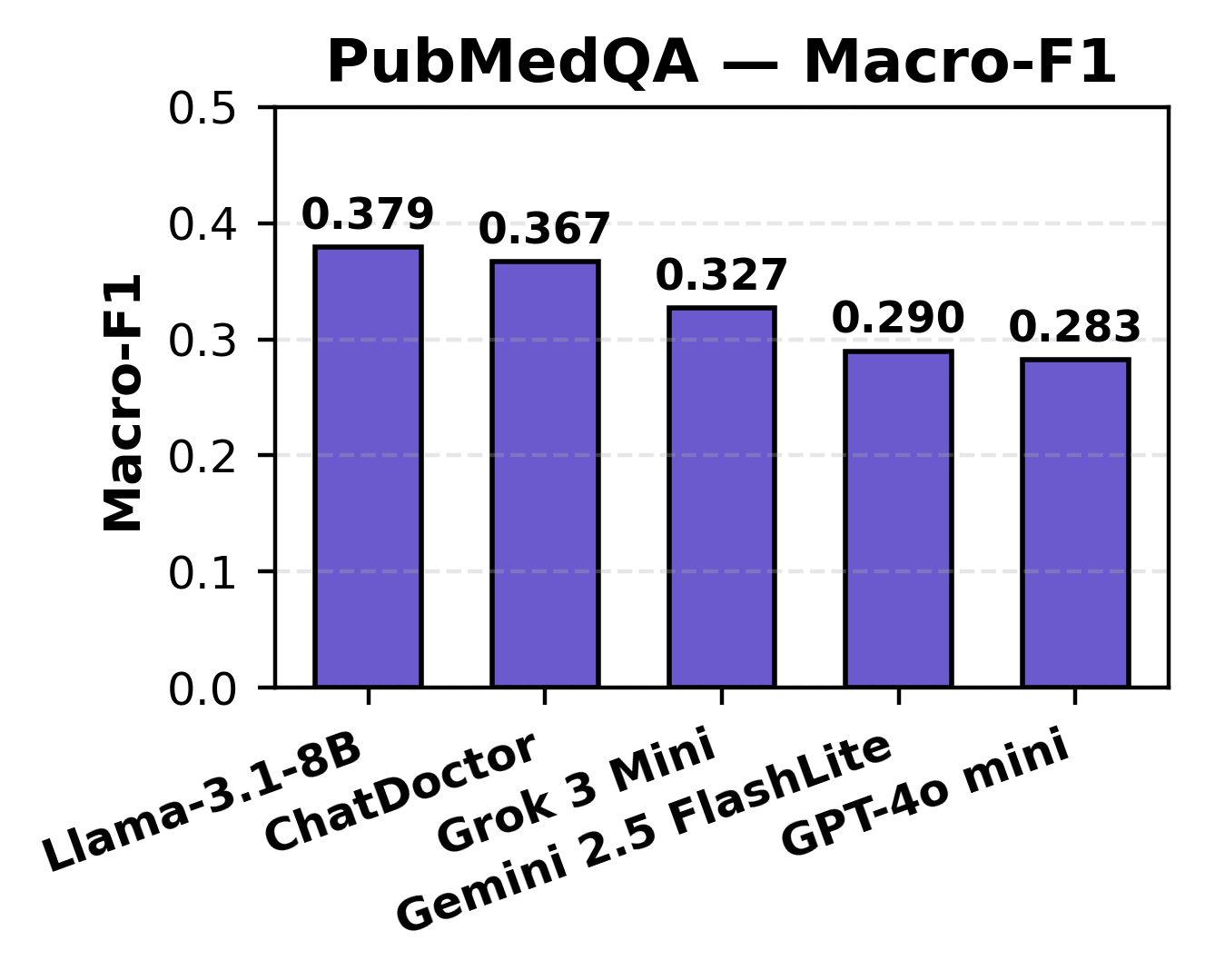
Figure 4: PubMedQA accuracy, illustrating impaired model balance and sensitivity for nuanced yes/no/maybe responses.
Notably, general-purpose models (Grok, LLaMA) excelled in structured fact retrieval, while domain-specific models (ChatDoctor) exhibited enhanced semantic and contextual caution.
Clinical Note Summarization (Asclepius)
Summary generation was evaluated using BLEU, ROUGE-L, and BERTScore metrics, with BLEU scores spanning 6.89–12.57, ROUGE-L ranging 0.195–0.271, and BERTScore F1 between 0.125–0.222. ChatDoctor and Gemini prioritized semantic fidelity, natively avoiding unsupported hallucinations, in contrast to Grok, which favored lexical overlap at the expense of deeper clinical correctness.
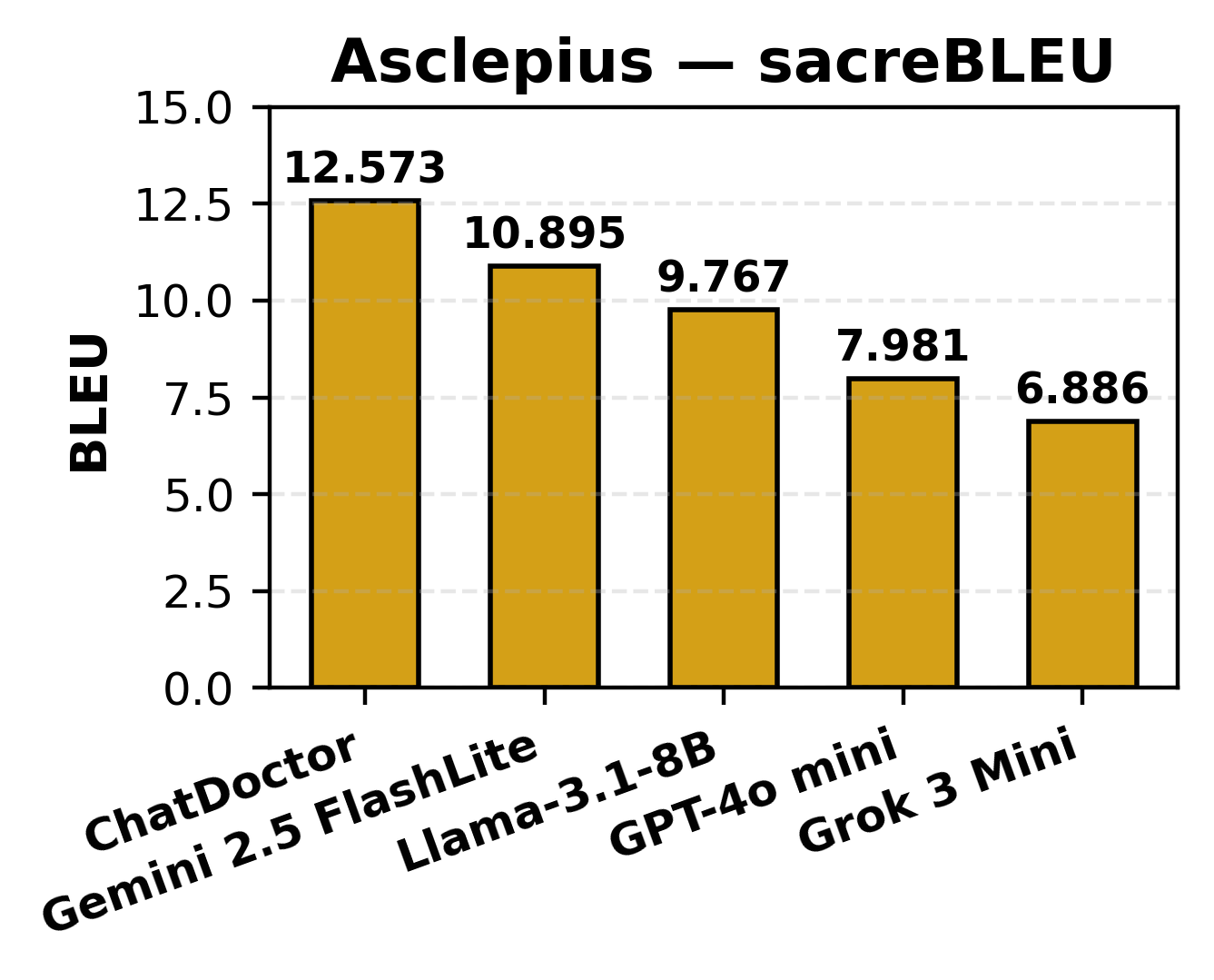
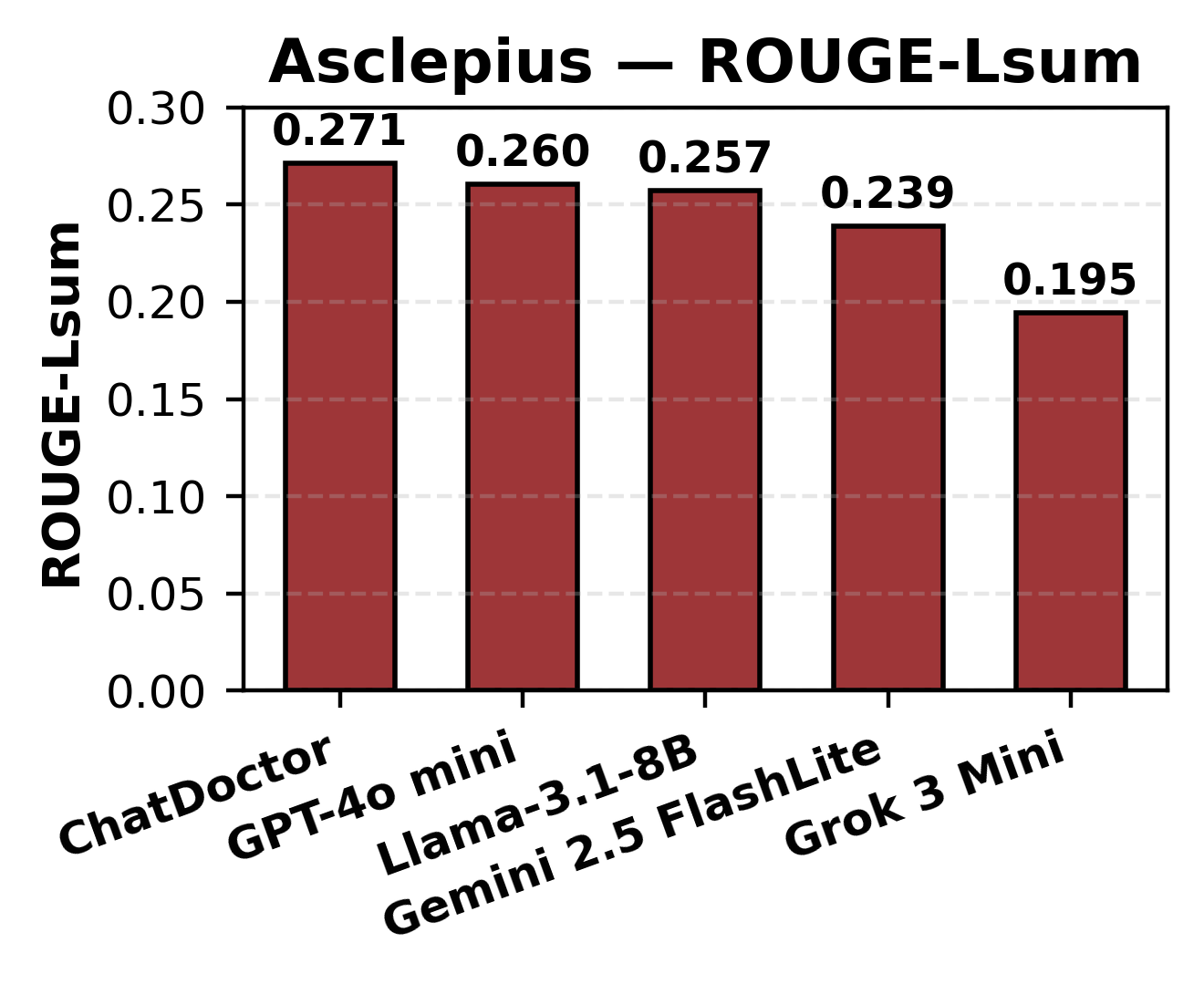
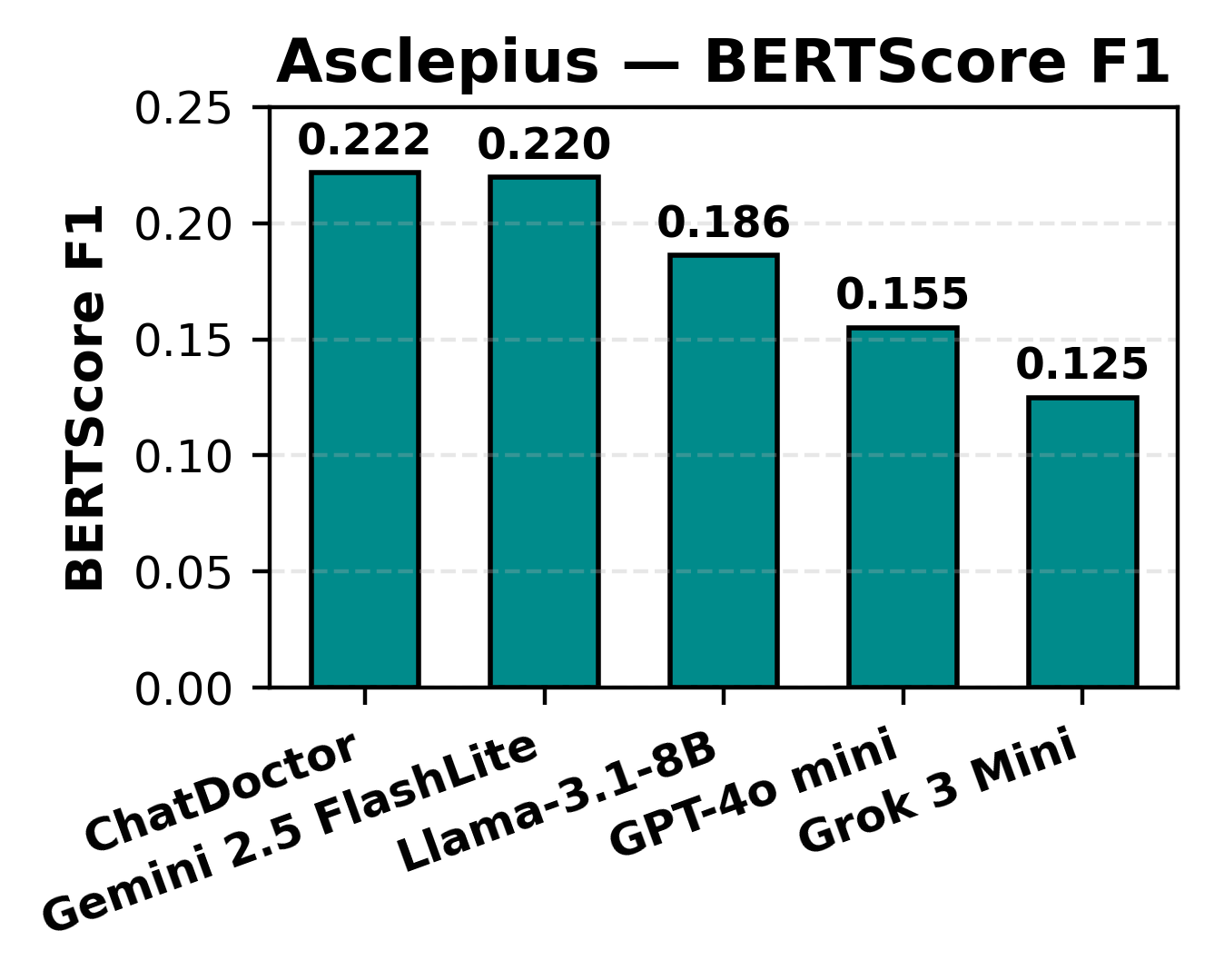
Figure 5: BLEU score performance for Asclepius clinical summarization, sorted by model.
A multi-dimensional radar/heatmap analysis consolidated results and emphasized task-dependent performance divergence. Grok led factual structured recall, while ChatDoctor dominated clinical summarization and semantic preservation. LLaMA-3.1-8B unexpectedly performed best in PubMedQA’s uncertainty class.
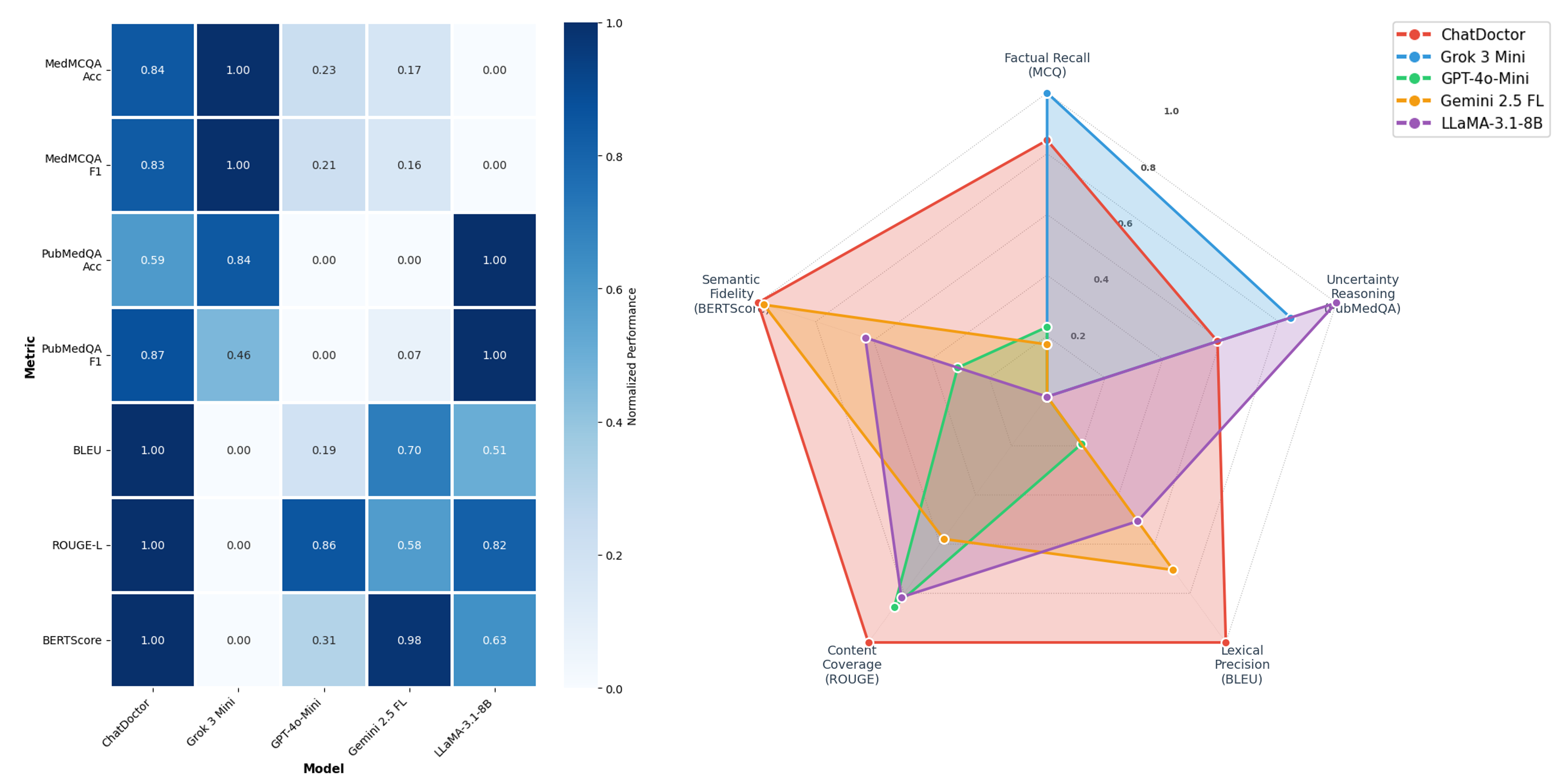
Figure 6: Left: task-normalized heatmap of per-model scores. Right: radar plot indicating distinct LLM capabilities per dimension.
The bold claim that emerges is the rejection of the "universal model" hypothesis; no single LLM outperforms across all healthcare-relevant axes. Instead, pronounced trade-offs exist between generative semantic precision (ChatDoctor) and fluency in factual Q&A (Grok, LLaMA).
Implications, Limitations, and Future Directions
The results indicate a necessary transition toward hybrid or “task-routing” paradigms—allocating queries to appropriate LLMs by required medical skill or safety threshold rather than defaulting to a one-size-fits-all generalist. Evaluation shows BLEU/ROUGE are insufficient for capturing clinical appropriateness; semantic and context-aware metrics (e.g., BERTScore) are essential for evaluating systems intended for high-stakes settings.
From a practical perspective, the cautious language and explicit uncertainty adopted by domain-specific models bolster arguments for their use in decision-support rather than automation. Conversely, generalist models' efficiency and broad coverage suit non-critical documentation and administrative applications. Adopting LLMs as augmentative rather than replacement technology is necessary to safeguard patient safety and compliance with ethical and legal standards.
This work also exposes substantial limitations, such as prompt sensitivity effects, fixed vs. adaptive prompt risks, and reliance on synthetic or curated datasets that neglect real-world linguistic noise and institutional heterogeneity. There is an unmistakable need for expert-in-the-loop clinical validation, adaptive ensemble methods, and meta-evaluation frameworks tailored to safety-critical medicine.
Conclusion
The comparative study robustly demonstrates the non-universality of LLM effectiveness in healthcare, documenting clear, task-specific trade-offs between domain-tuned and general-purpose models. Domain-adapted models, exemplified by ChatDoctor, provide superior semantic reliability and safety for critical medical documentation, while general-purpose LLMs like Grok and LLaMA perform optimally in knowledge-driven Q&A. Comprehensive clinical deployment will require interactive, multi-dimensional evaluation metrics, hybrid inference strategies, and continuous human oversight to support the nuanced requirements of medical practice and patient care.
Further advancements are necessary in dataset realism, prompt engineering, and robust, semantically-aligned benchmarking to ensure future LLMs meet the stringent standards demanded by the healthcare domain.