- The paper introduces a novel adversarial search framework using dual-agent MCTS to robustly counter pseudo-correctness in code generation.
- It demonstrates that divergence-driven test synthesis significantly improves logical error detection and boosts pass@1 accuracy by over 5% on challenging benchmarks.
- Ablation studies confirm that removing components like the Attacker or global filter sharply degrades performance, underscoring the method’s efficiency and cost-effectiveness.
AdverMCTS: An Adversarial Search Paradigm for Robust Code Generation
Motivation and Problem Definition
LLMs have demonstrated substantial capability in code generation, particularly when augmented with search-based inference protocols. However, standard evaluation pipelines, which depend on sparse, static public test cases to filter candidate solutions, are highly susceptible to pseudo-correctness. This phenomenon occurs when generated code is tuned to pass the visible public tests yet generalizes poorly and fails on withheld, semantically challenging hidden cases. The limited adversarial coverage in static test suites allows overfitted, fragile solutions to survive, undermining both search-based and sampling-based methods.
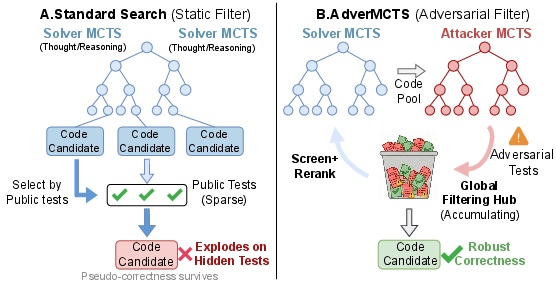
Figure 1: Standard search using sparse tests allows pseudo-correct code to survive, while AdverMCTS leverages a co-evolving adversarial Attacker to iteratively expose and penalize logical errors.
The paper "AdverMCTS: Combating Pseudo-Correctness in Code Generation via Adversarial Monte Carlo Tree Search" (2604.10449) formalizes this verification bottleneck and shifts the focus towards dynamic, hostile verification. The authors argue that rigorous code generation should be recast as a two-player minimax interaction between a code-generating Solver and an adversarial Attacker, with the latter explicitly co-evolving new constraints to expose and eliminate pseudo-correct solutions.
AdverMCTS Framework
AdverMCTS instantiates a dual-agent adversarial protocol, operationalized via parallel Monte Carlo Tree Search (MCTS) instances. The framework operates as a minimax loop: the Solver expands partial-chain-of-thought (CoT) trajectories and synthesizes code candidates, while the Attacker maintains a persistent search tree conditioned on the evolving code pool to discover discriminative, failure-triggering corner test cases. Valid test cases identified by the Attacker are globally accumulated as hard constraints, actively filtering fragile solutions during the search and serving as additional tie-breakers in final reranking.
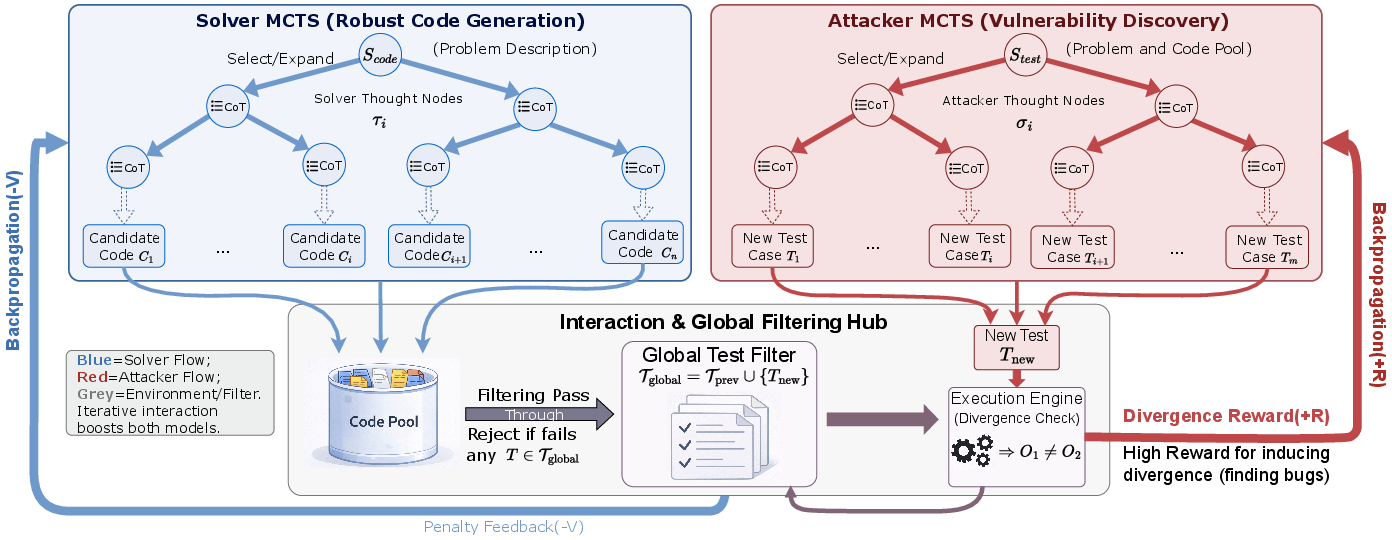
Figure 2: Solver (blue) proposes candidate code; Attacker (red) synthesizes adversarial tests by inducing output divergence; the Global Hub adjudicates, adds new constraints, and triggers penalty signals for fragile code.
The core sequential protocol comprises:
- Solver MCTS: Expands reasoning steps, synthesizes executable code at simulation nodes, and updates values via a hybrid signal—intrinsic public test pass rates and extrinsic penalties from the adversarial constraint set.
- Attacker MCTS: Grows a context-aware search tree, leveraging divergence-driven multi-sample test synthesis (DMTS) over the current code pool to maximize inter-candidate output disagreements, which proxy logical fragility.
- Arbiter: For each divergent test, an LLM-based judge infers the correct output, formally labeling the new test for constraint enforcement.
- Global Test Filter: Aggregates all validated adversarial tests, acts as a monotonic gate for code pool entry, and anchors reranking for final solution selection.
Empirical Results
Extensive experiments on APPS and TACO benchmarks reveal several strong claims and performance improvements:
- AdverMCTS consistently outperforms state-of-the-art search methods (PG-TD, MCTS-Thought, LATS, ToT, and RethinkMCTS), with mean Pass@1 accuracy gains exceeding +5% on the most challenging APPS-Competition and TACO-Hard subsets and robust improvements spanning smaller (Qwen3-4B) and larger (DeepSeek-V3.2, 671B) backbones.
- The framework demonstrates scalability and agnosticism to model scale, maintaining or increasing its relative advantage on both open and frontier models.
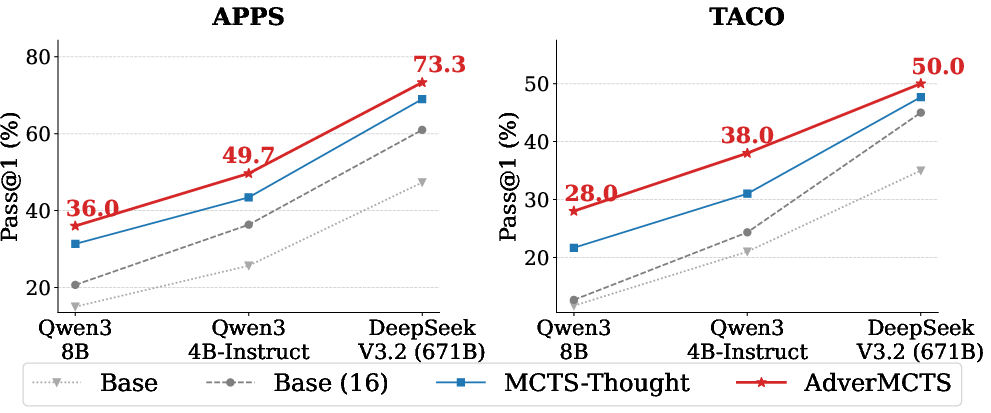
Figure 3: AdverMCTS delivers monotonic performance gains across LLMs of differing capabilities, remaining effective for both base and very large models.
- Ablation studies highlight that removing either the Attacker, divergence-based test synthesis, or global filter substantially degrades Pass@1, quantifying each component’s necessity.
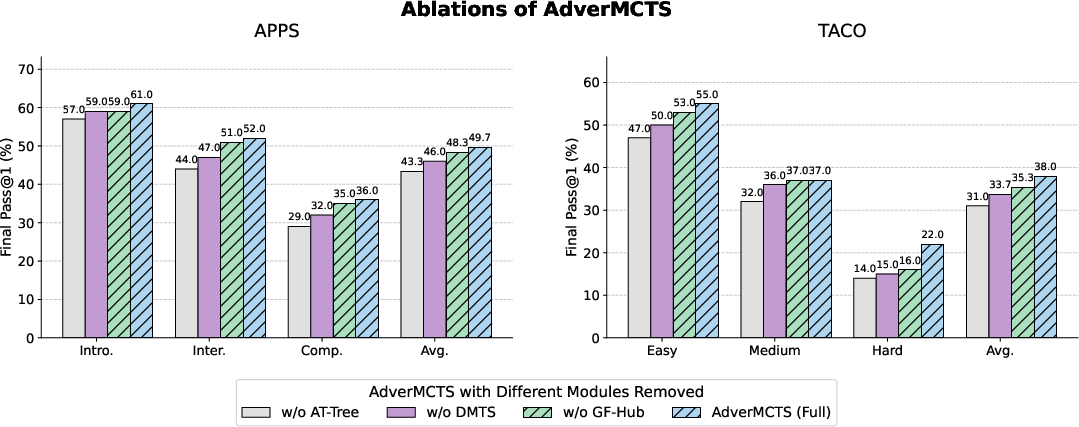
Figure 4: Component-level ablations demonstrate that without the Attacker or global hard constraint filter, pseudo-correctness proliferation severely degrades generalization.
- AdverMCTS offers a superior cost-effectiveness trade-off: for equal or lower token budgets, it achieves higher pass rates versus strategies that merely scale up sample count or tree depth in single-agent baselines.
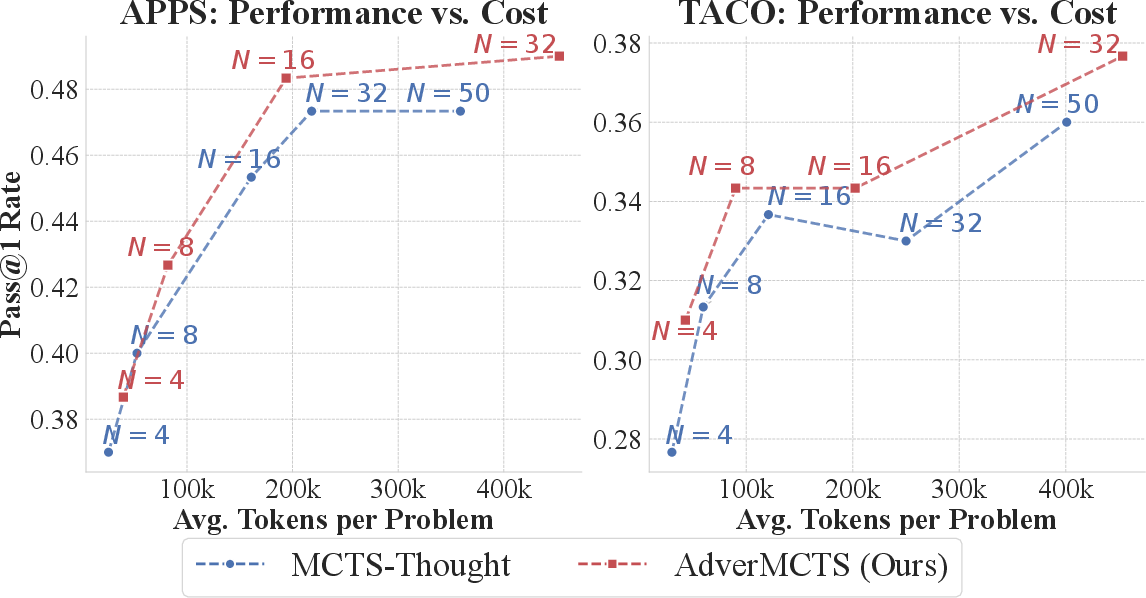
Figure 5: For a fixed inference budget, AdverMCTS consistently traces a better Pareto frontier in terms of final solution accuracy per token expended.
- Analysis of the adversarial co-evolution reveals that, as the Attacker accumulates corner cases, the robustness of the Solver’s surviving codes increases synchronously, with final pass rates closely tracking the cumulative adversarial constraint count.
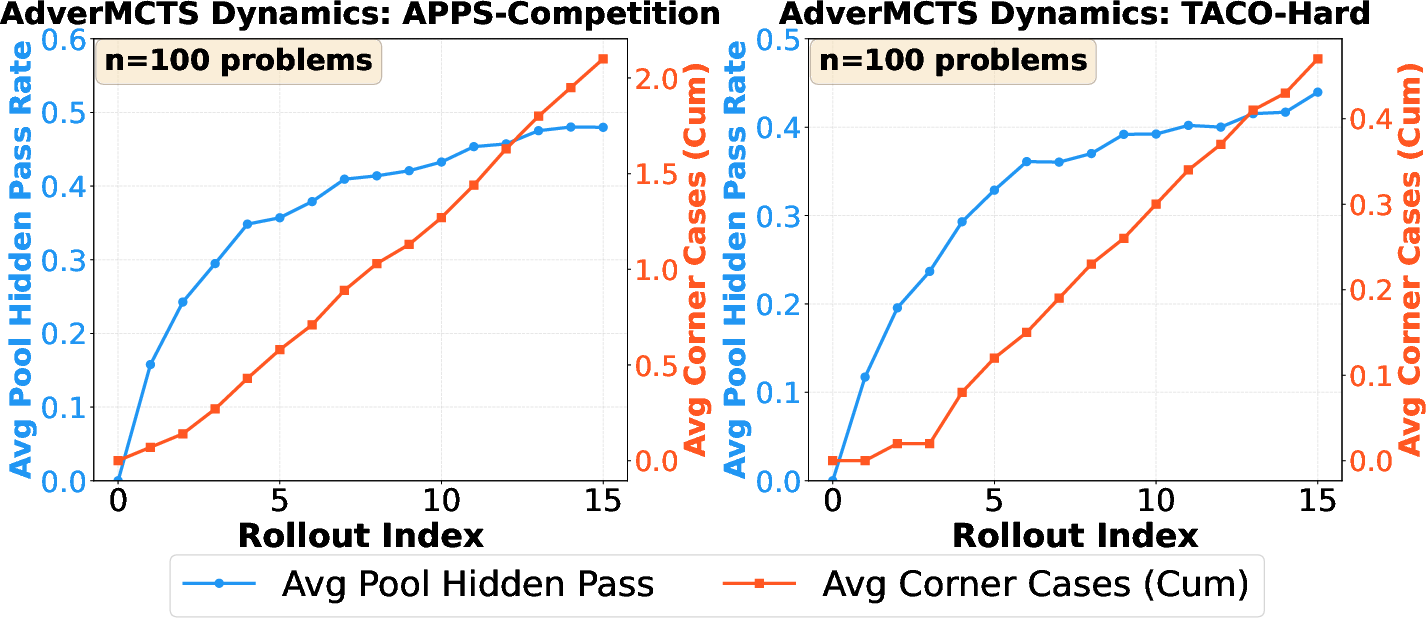
Figure 6: Joint evolution of adversarial test coverage and hidden pass rates indicates that the system moves toward true correctness as the Attacker surfaces and penalizes subtle bugs.
- AdverMCTS’s attacker-generated tests, judged by output divergence, expose over 56% of pseudo-correct codes (Recall), and demonstrate strong Precision (∼79%) with a conservative false positive rate (16%).

Figure 7: The Attacker discriminates pseudo-correct from truly correct code, maintaining low rates of wrongful penalization.
Theoretical and Practical Implications
AdverMCTS demonstrates that the dominant failure mode for code generation search methods is no longer in candidate generation capacity but in verification signal weakness. The adversarial protocol, akin to dynamic environment hardening, is shown to approximate oracle-level hidden test discrimination without requiring privileged access. The LLM-based Arbiter is empirically validated over majority voting, further reducing label leakage and error propagation.
Practically, this framework enables more reliable deployment of LLM-based code generation for competitive and safety-critical applications. By shifting compute toward adversarial test-time verification rather than brute-force sample expansion, AdverMCTS sidesteps the inefficiency of existing approaches and provides an immediately actionable blueprint for further integration into API-level or in-IDE reasoning assistants.
Theoretically, the minimax search-game perspective opens several research avenues:
- Automated curriculum generation and development of higher-fidelity adversarial test-seeking policies
- Adaptive, model-critic learning protocols unifying inference-time and training-time adversarial objectives
- Generalization of the co-evolution paradigm to other structured prediction and program synthesis domains
Future Directions
Numerous questions are provoked by the results:
- What is the optimal allocation of compute between code synthesis and adversarial counter-example search?
- How can attacker strategies be adapted or meta-learned for settings with limited test-time compute?
- What limits emerge in the presence of ambiguous specifications where the Arbiter’s judgment cannot be trusted?
- Can co-trained attacker networks generalize test generation to semantically related but previously unseen program classes?
Conclusion
AdverMCTS reframes the code generation pipeline into a two-agent adversarial game, operationalizing robust MCTS search under dynamic, evolving constraints. By tightly interleaving candidate synthesis, adversarial vulnerability discovery, and LLM-judged constraint aggregation, AdverMCTS demonstrably reduces pseudo-correctness and forces LLMs to produce logically sound, generalizable code. This paradigm substantially advances the methodology for bridging the verification gap in LLM-driven program synthesis, and its core insights—adversarial supervision, dual-tree search, and Arbiter-guided labeling—are directly applicable to broader test-time reasoning and robustness evaluation challenges.