- The paper introduces a novel human-validated dataset that isolates three key uncertainty sources: model knowledge gaps, output variability, and input ambiguity.
- The paper finds that hybrid methods combining semantic and probabilistic signals often outperform traditional token-probability and consistency-based approaches in targeted scenarios.
- The paper reveals that LLMs tend to produce overconfident outputs under input ambiguity, highlighting a critical need for more nuanced, source-aware UQ strategies.
Introduction
Uncertainty quantification (UQ) in LLMs underpins trust, reliability, and robust deployment, especially across high-stakes domains. Traditional UQ approaches for LLMs collapse diverse uncertainty sources into a unidimensional scalar, typically a confidence score estimating the probability that the generated answer is correct. However, uncertainty in natural language generation can originate from different sources: model knowledge limitations, inherent output variability, or ambiguities in the input. These sources require sharply different downstream actions—ranging from abstention and retrieval to clarification or diversification. The paper "Why Don't You Know? Evaluating the Impact of Uncertainty Sources on Uncertainty Quantification in LLMs" (2604.10495) investigates how existing UQ methods behave under these distinct types of uncertainty, presenting a systematic analysis enabled by a novel human-validated dataset that decouples these sources while ensuring consistency in task structure.
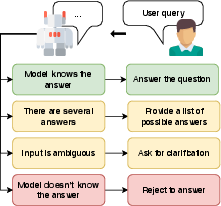
Figure 1: Illustration of model responses and downstream actions under different sources of uncertainty.
Dataset Creation: Controlled Uncertainty Source Decoupling
Recognizing the limitations of prior datasets such as AmbigQA and MAQA, which either conflate uncertainty sources or target only a specific aspect (i.e., temporal ambiguity), the authors construct a new dataset with 539 human-validated question triplets. Each triplet instantiates the same factual context but isolates one of three uncertainty types:
- Model Knowledge Uncertainty: The question presupposes a single correct answer, and uncertainty is expected to reflect gaps in the model’s knowledge.
- Output Variability: Multiple semantically distinct answers are correct; any is valid, but the model’s probability mass is necessarily spread.
- Input Ambiguity: The question is under-specified or ambiguous and cannot be answered without further clarification.
The pipeline ensures each question form is directly comparable in phrasing, format, and domain, providing a robust framework for evaluating and contrasting UQ methods without confounding factors.
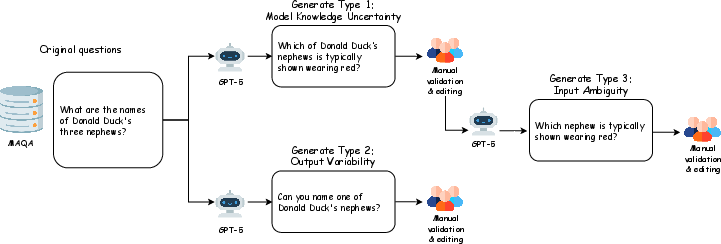
Figure 2: Question generation pipeline used to construct question triplets.
Experimental Setup
Model and Method Selection
Three representative open-weight instruction-tuned LLMs—Llama-3.1-8b-Instruct, Gemma-3-12b-Instruct, Qwen-2.5-14b-Instruct—are selected to span diverse architectures and parameterizations. UQ methods evaluated cover five categories:
- Token-probabilities-based (e.g., Sequence Probability, Perplexity, Mean Token Entropy, MCSE/MCNSE, PMI).
- Consistency-based (e.g., NumSemSets, DegMat, EigValLap, Eccentricity).
- Hybrid (e.g., Semantic Entropy, LUQ, SAR, Semantic Density, CoCoA).
- Verbalized methods (e.g., P(True), 2S-Verbalized Uncertainty).
- Internal state-based methods (for completeness, included in some comparisons but not the main analysis).
Standardized implementations provided by the lm-polygraph library guarantee methodological parity across evaluations.
Metrics
The primary evaluation metric is Prediction Rejection Ratio (PRR), which assesses the quality improvement achieved by selectively rejecting model outputs with the highest UQ scores, normalized against both random and oracle strategies. Additionally, the Spearman correlation between UQ scores and judged output quality is reported.
Main Results
Model Behavior Across Uncertainty Types
All three LLMs obtain comparable accuracy on single- and multi-answer questions, with no spontaneous abstention. However, when faced with input ambiguity, models overwhelmingly commit to an arbitrary interpretation, rarely requesting clarification. This demonstrates that LLMs default to confident outputs, even under conditions where clarification is appropriate—exposing a critical shortcoming in user-facing deployments.
Hybrid methods such as Semantic Density and CoCoA (particularly with MTE as the uncertainty backbone) yield the highest PRR in single-answer settings, leveraging both semantic agreement and probabilistic signals. In contrast, in multi-answer scenarios (output variability), sequence probability-based scores (MTE, MCSE) become more competitive, as consistency-based metrics struggle to distinguish between legitimate answer diversity and uncertainty due to model confusion.
Notably, in ambiguous input conditions, verbalized uncertainty (especially 2S-Verbalized) exhibits strong performance—emphasized by its leading PRR for Qwen-14B and runner-up status for Gemma-12B. Yet, the capability remains limited and highly model-dependent.
Summary visualizations demonstrate the varying dominance of method families based on the underlying uncertainty source.
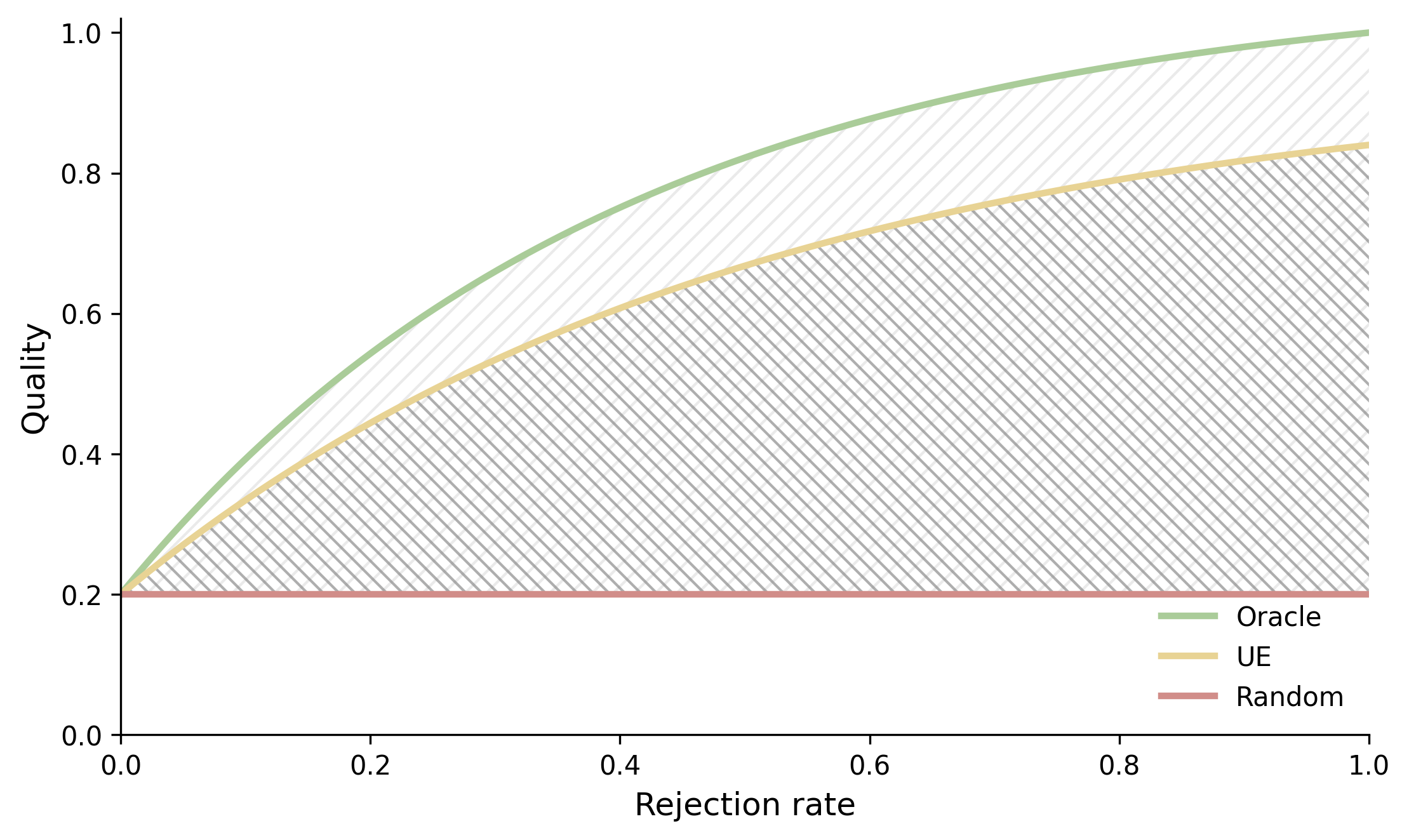
Figure 3: PRR curve illustrating non-rejected prediction quality as a function of rejection rate; Oracle, Random, and UQ classifier comparisons for each method.
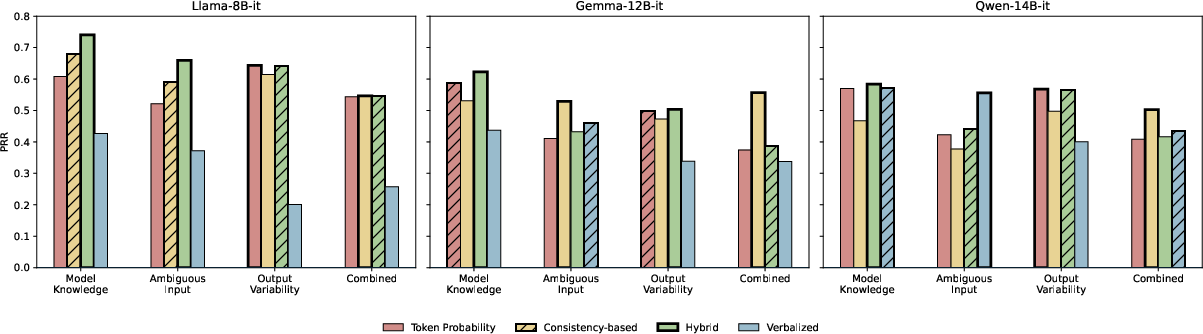
Figure 4: Comparison of uncertainty estimation families by best PRR achieved per model and uncertainty type, with leading families highlighted.
Correlation with Quality and Method Limitations
Spearman correlation analysis reveals maximum alignment between UQ scores and quality in the model knowledge uncertainty (single-answer) regime, with substantially weaker correlation when output variability or input ambiguity is present. This confirms that most methods are implicitly tuned to epistemic uncertainty, not aleatoric (output diversity) or ambiguity-induced uncertainty.
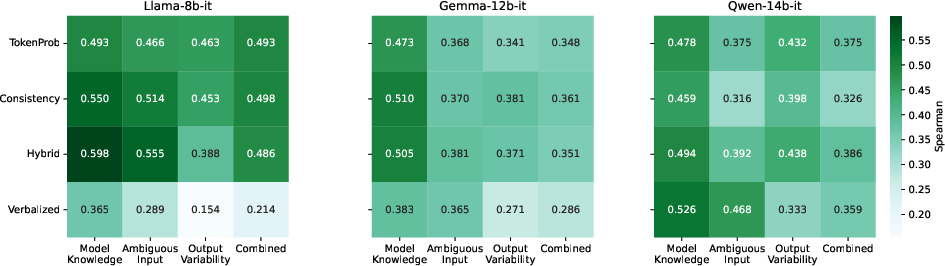
Figure 5: Spearman correlation coefficient for best performing UQ methods in each category, showing source-dependent degradation in correlation.
Qualitative Failure Modes
- Token-probability methods systematically penalize legitimate output diversity (multiple valid answers) by distributing probability mass, resulting in elevated UQ scores that do not correspond to lack of model knowledge.
- Consistency-based methods are confounded by self-consistent but incorrect answers (masking errors) or by legitimate answer variability (overestimating uncertainty).
- Hybrid approaches, while improved, inherit limitations from their components, especially under ambiguity, where models confidently commit to a single plausible but underspecified interpretation.
- Verbalized UQ has limited effect on output variability and is highly sensitive to model size and alignment.
Representative examples of UQ method failure profiles for each uncertainty type reinforce these findings.

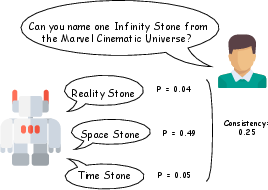
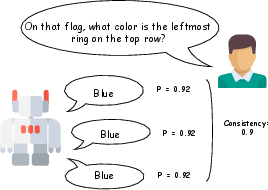
Figure 6: Examples of UQ failure modes: (1) consistent, high-probability errors; (2) output variability interpreted as lack of confidence; (3) ambiguous input with false certainty.
Practical and Theoretical Implications
The results demonstrate that most existing UQ methods lack the granularity or structural awareness to disentangle uncertainty sources. Aggregating distinct uncertainty phenomena into a scalar obscures critical distinctions essential for both safe human-in-the-loop deployment and autonomous decision making. For instance, rejecting model outputs for output variability (desired diversity) would lead to unnecessary abstention or repeated clarification queries. Failing to recognize input ambiguity precludes systems from prompting for clarification, resulting in confident but potentially misleading answers.
Further, the performance of UQ methods is highly model-dependent, with no single class dominating across all scenarios or architectures. Thus, model-metric selection must be adaptive and source-aware.
Outlook and Future Research Directions
Advancing UQ in LLMs requires structured, multi-dimensional representations that explicitly decompose uncertainty into epistemic (knowledge gaps), aleatoric (output variability), and interpretative (input ambiguity) components. Research directions include:
- Designing composite UQ: Combining metrics from diverse families, conditioned on model output analysis or latent input characteristics.
- Building triage policies: Mapping uncertainty source type to optimal action (e.g., output diversification, clarification, or retrieval).
- Integrating ambiguity detection modules: Complementary ambiguity detection (e.g., [shi-etal-2025-ambiguity]) that can signal when clarification is mandated.
- Extending to black-box/tool-augmented systems: Generalizing benchmarks and method evaluation to production-like constraints, including tool use, retrieval-augmented generation, and multilingual contexts.
- Improving model behavior via instruction/fine-tuning: Directly aligning model responses to express uncertainty or refuse confidently when ambiguity or knowledge gaps are present.
Recent work (e.g., [guo2025uncertaintyprofilesllmsuncertainty], [shi-etal-2025-ambiguity]) on uncertainty source decomposition and ambiguity detection provide promising avenues for operationalizing these strategies and achieving more robust, interpretable, and trustworthy AI assistants.
Conclusion
This study presents a comprehensive, controlled framework for dissecting the behavior of UQ methods in LLMs, revealing significant limitations in current approaches when confronted with output variability and input ambiguity. The provided dataset and systematic evaluation expose the critical need for source-aware, structured uncertainty representations and policies. Effective uncertainty quantification in real-world AI systems must move beyond scalar confidence estimation toward adaptive, interpretable models of uncertainty—shaping both system and user belief calibration and guiding appropriate downstream actions.