- The paper demonstrates that a fine-tuned PatentSBERTa classifier outperforms legacy LSTM models with 97% precision, 91.3% recall, and a 94.0% F1 score in AI patent identification.
- It utilizes citation connectivity and TF-IDF lexical similarity measures to validate its effectiveness in distinguishing AI patents across US and Chinese datasets.
- The study reveals divergent patterns in spatial diffusion, institutional concentration, and knowledge flows between US and Chinese AI innovation ecosystems.
AI Patents in the United States and China: Measurement, Organization, and Knowledge Flows
Introduction
This paper presents a robust comparative analysis of AI innovation in the United States and China by constructing a high-precision classifier for AI patent identification based on transformer-based NLP architectures. The authors fine-tune PatentSBERTa on manually labeled US Patent and Trademark Office (USPTO) Artificial Intelligence Patent Dataset (AIPD) data, resulting in the FGYZ classifier, which significantly outperforms legacy LSTM approaches in recall, precision, and F1 metrics. The methodology allows for cross-jurisdictional application, yielding a qualitative leap in the identification and classification of AI patents spanning 1976–2023 (USPTO) and 2010–2023 (CNIPA).
Methodological Framework: Fine-tuned LLM Classifiers for AI Patents
The critical methodological innovation is the contrastive fine-tuning of PatentSBERTa, leveraging the domain-specific semantic structure of patent corpora. The FGYZ classifier achieves test precision of 97%, recall of 91.3%, and an F1 score of 94.0% across all major AI subfields, excluding evolutionary computation due to limited labeled samples. The model's output is sharply polarized for true AI and non-AI patents, indicating strong boundary internalization (Figure 1).
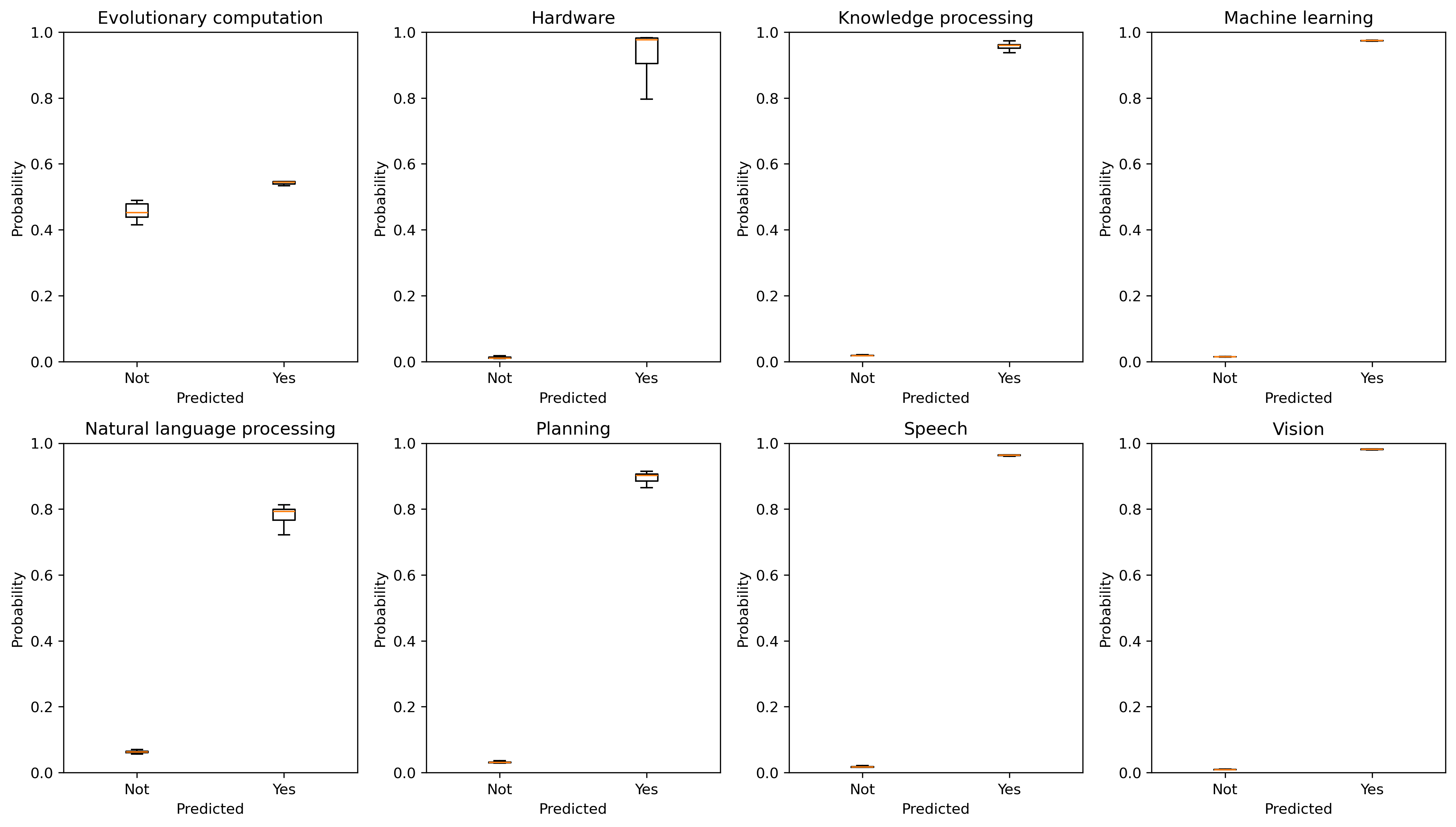
Figure 1: The distribution of classifier probabilities is sharply bimodal except in the evolutionary computation subfield, confirming discriminative capacity across AI subdomains.
This methodology critically corrects the severe attenuation bias and high false discovery rates present in the USPTO’s LSTM benchmark, whose test precision and recall are <41% and <38%, respectively. The FGYZ approach is validated not only on US datasets but also exogenously on the Chinese corpus via cross-country citation/connectivity and TF-IDF lexical homology.
Robustness and Validation: Citation-Based and Lexical Similarity Evaluation
The classifier's validity is systematically tested via (1) citation-based connectivity metrics and (2) TF-IDF–weighted lexical similarity. Patents uniquely identified as AI by the FGYZ model (but not the USPTO AIPD) show significantly higher citation connectivity to the dual-positive set (patents classed as AI by both models) and markedly lower connectivity to dual-negatives (Figure 2). This is evident across all core AI subfields.
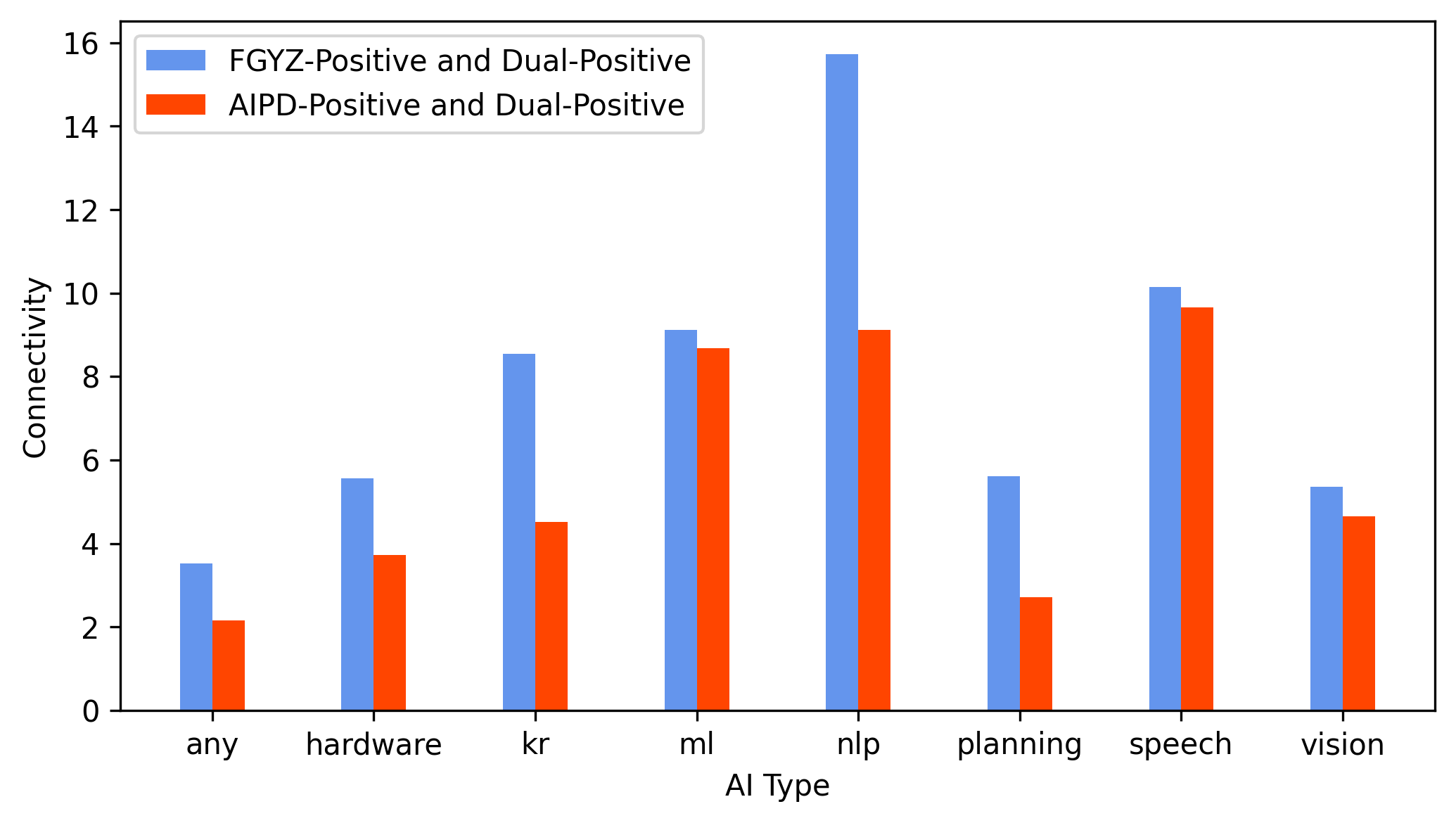
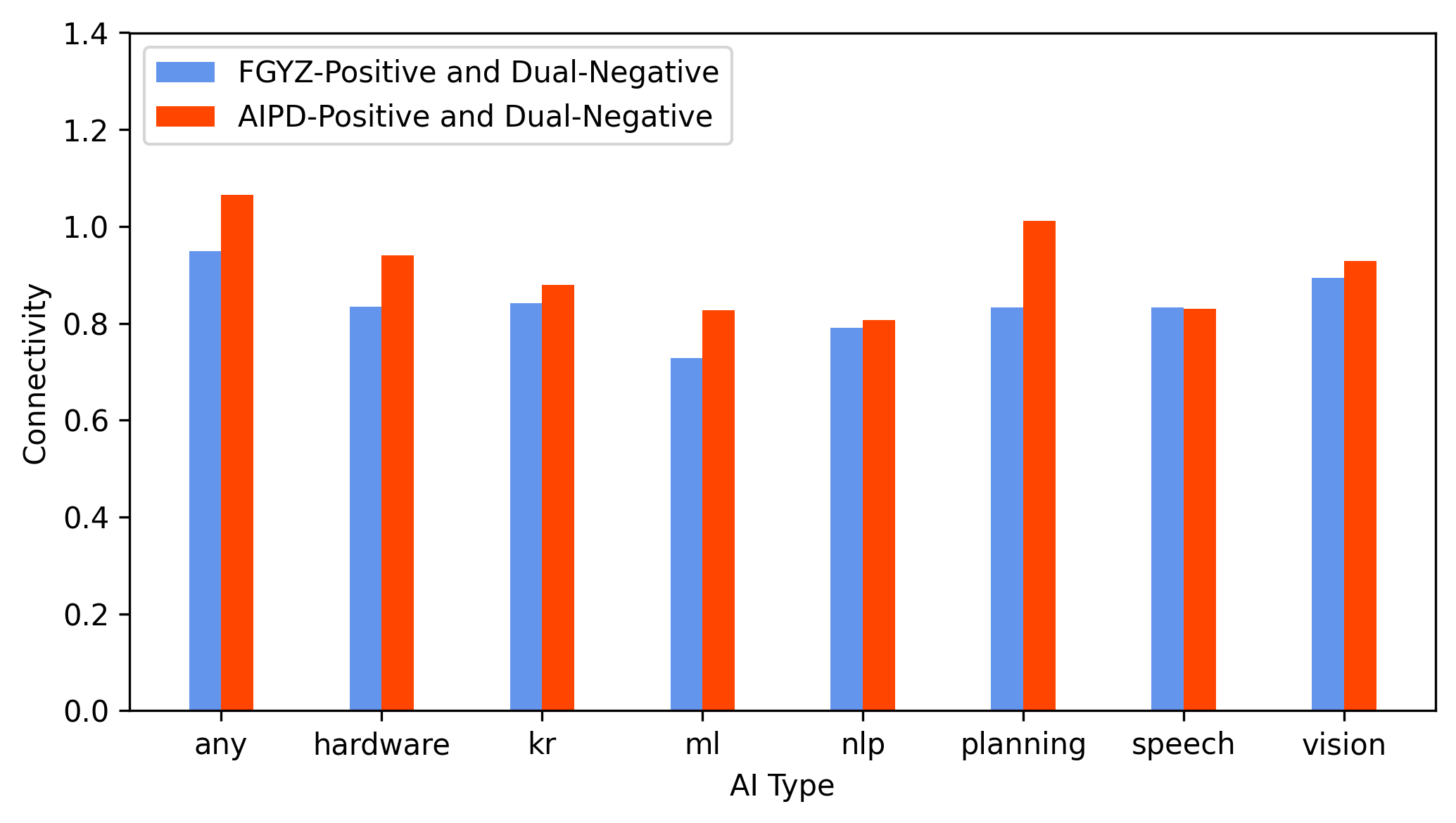
Figure 2: Citation-based connectivity confirms FGYZ-Positive patents are more tightly embedded within the core AI knowledge network than AIPD-Positive patents.
Concordantly, FGYZ-Positive patents exhibit higher TF-IDF–weighted lexical alignment with the gold-standard dual-positive AI patents compared to AIPD-Positive patents (Figure 3). These results are consistent across machine learning, hardware, NLP, and planning subfields.
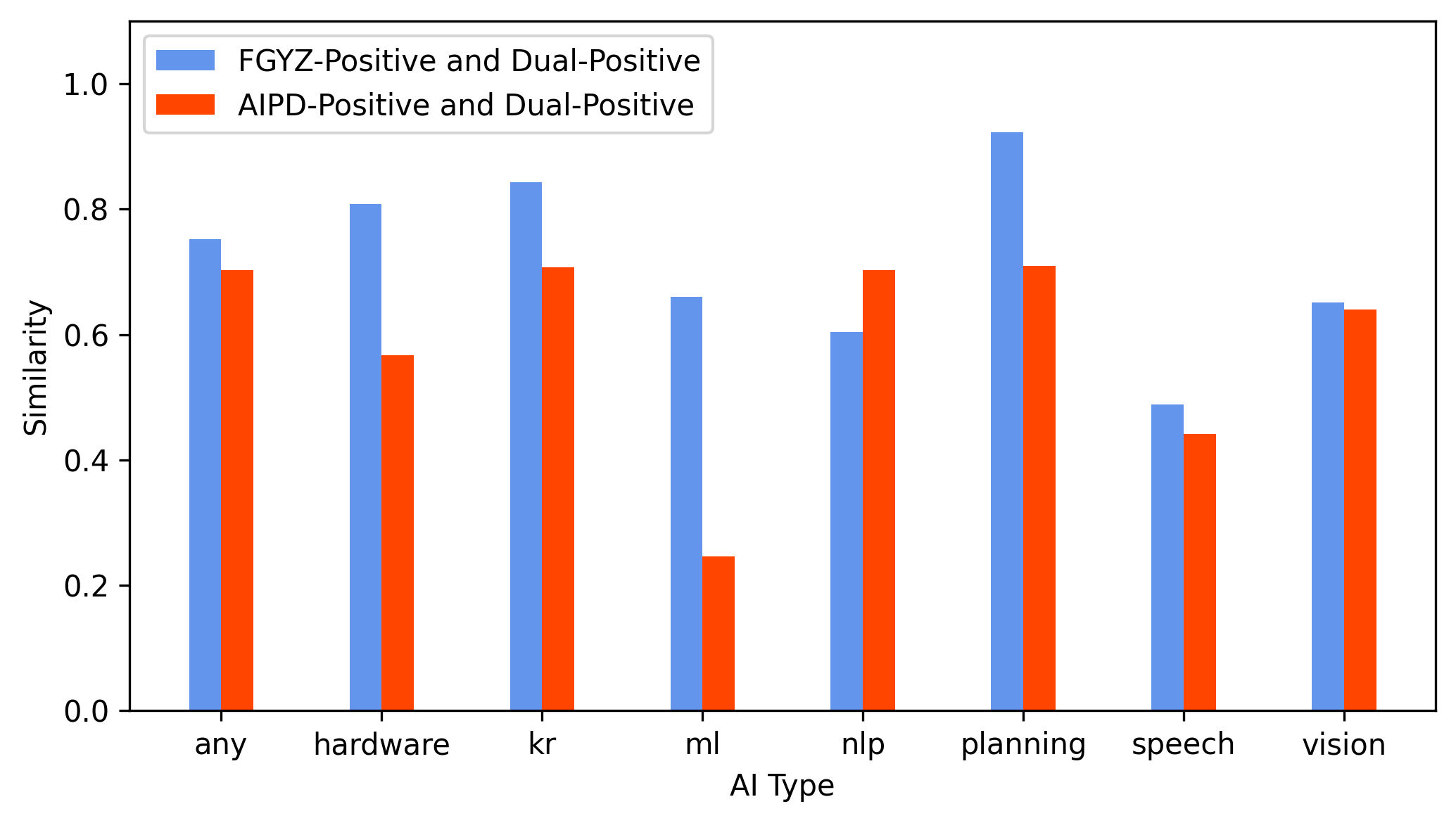
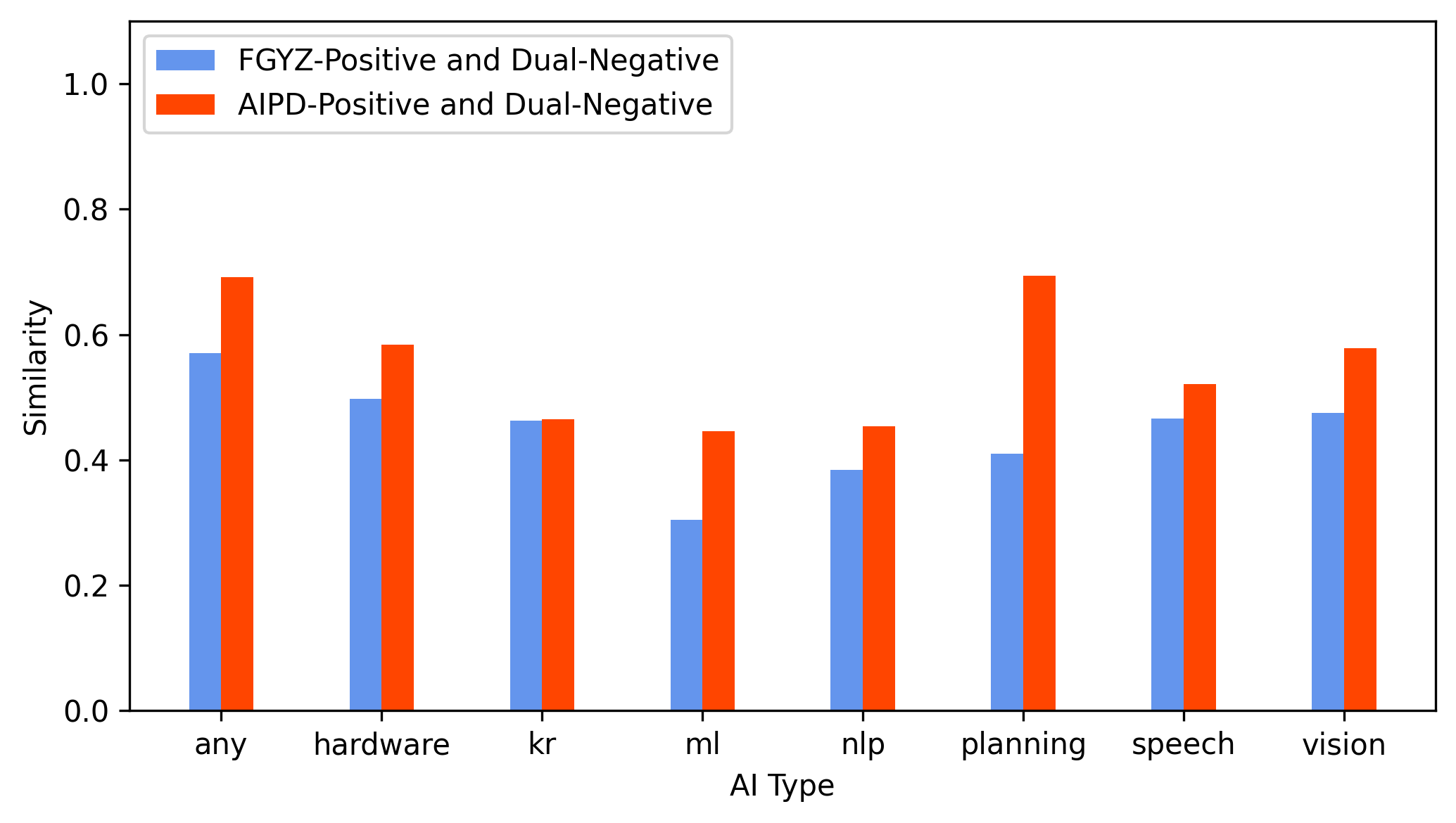
Figure 3: Lexical similarity analysis demonstrates that FGYZ-Positive patents share technical vocabulary distributions with established AI patents, unlike AIPD-Positive patents.
Generalization and Knowledge Transfer: Application to Chinese Patents
The application of the FGYZ classifier to CNIPA patent data robustly distinguishes AI and non-AI patents, evidenced by sharply separated predicted probabilities across all subfields except evolutionary computation (Figure 4). Cross-border citation connectivity and lexical alignment between Chinese and US patents indicate that FGYZ-identified Chinese AI patents are highly connected both citationally and semantically to the US AI frontier (Figures 5, 6).
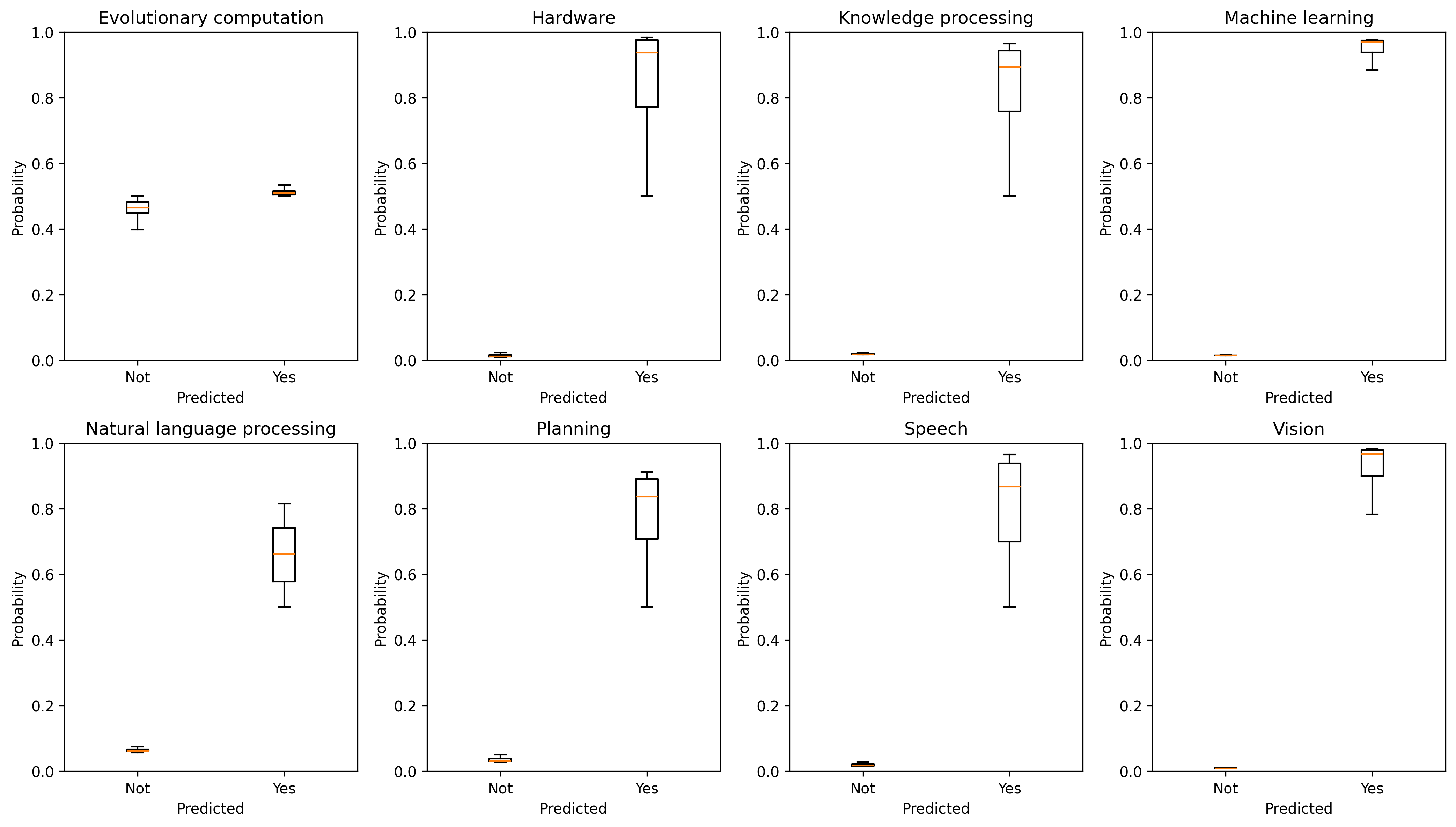
Figure 4: Distributions of classifier predictions demonstrate robust discriminative power for Chinese AI patents, matching US benchmark separability.
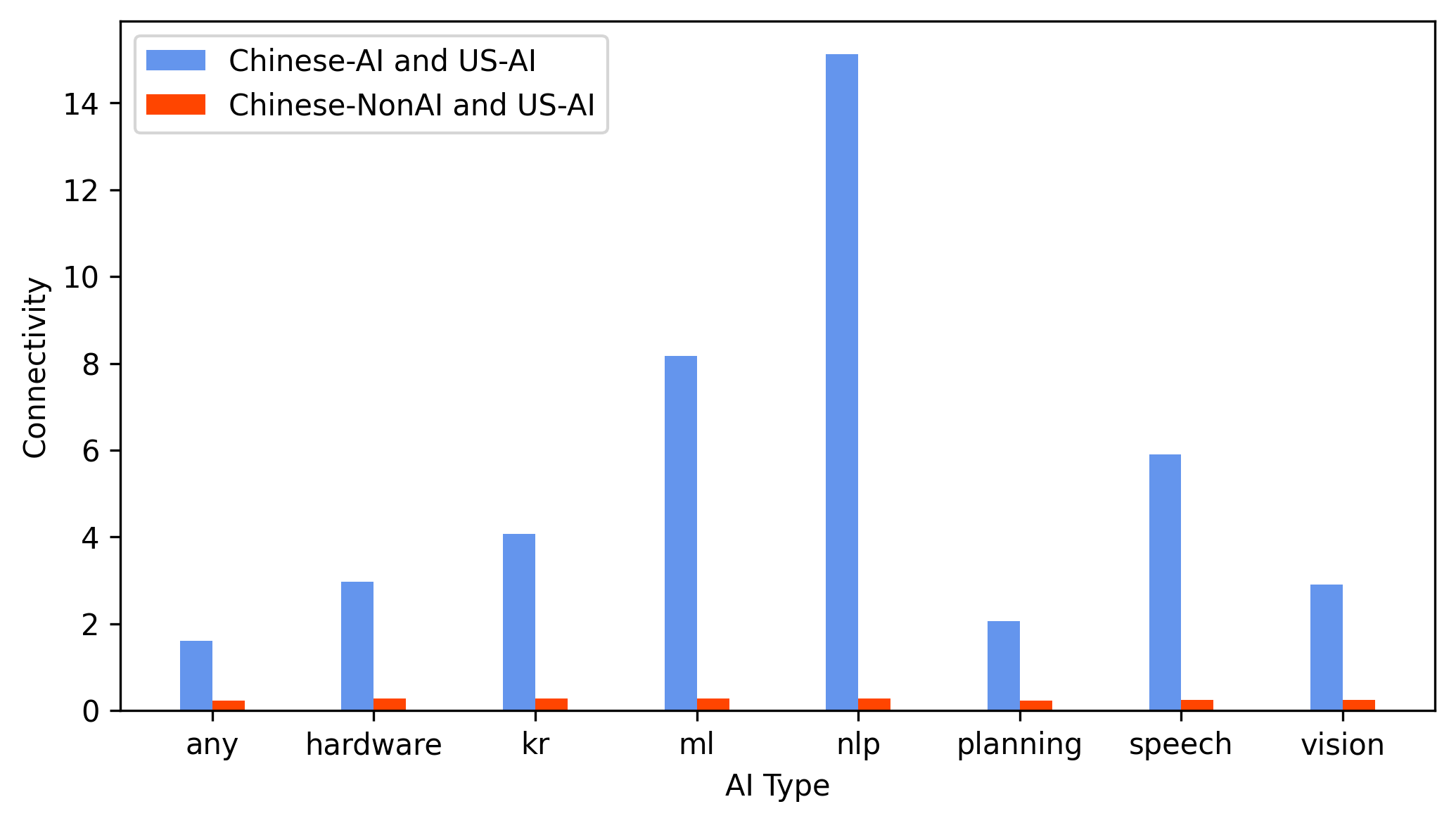
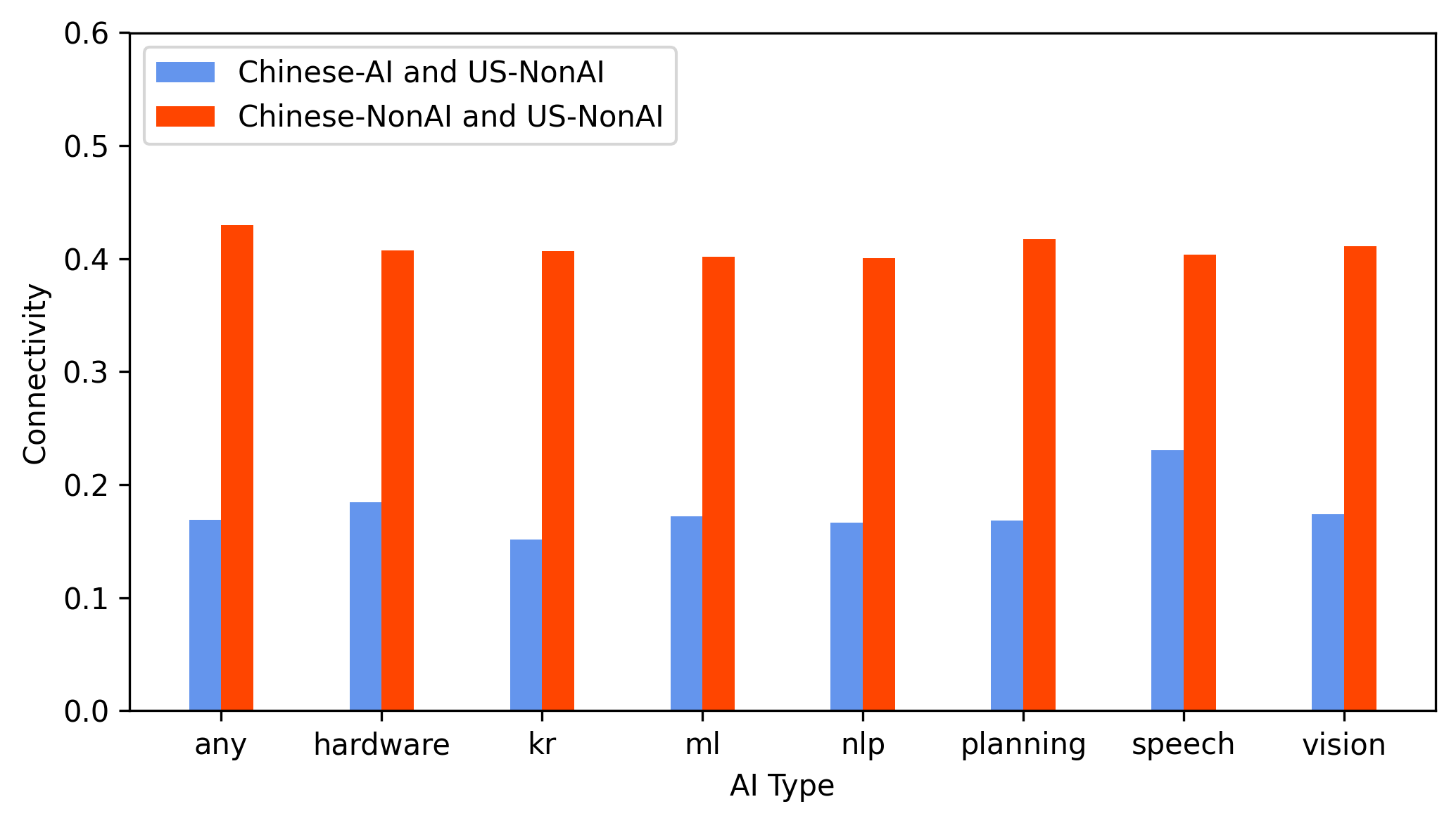
Figure 5: Reciprocal citation connectivity evidences strong technological linkage between FGYZ-identified Chinese AI patents and US AI knowledge.
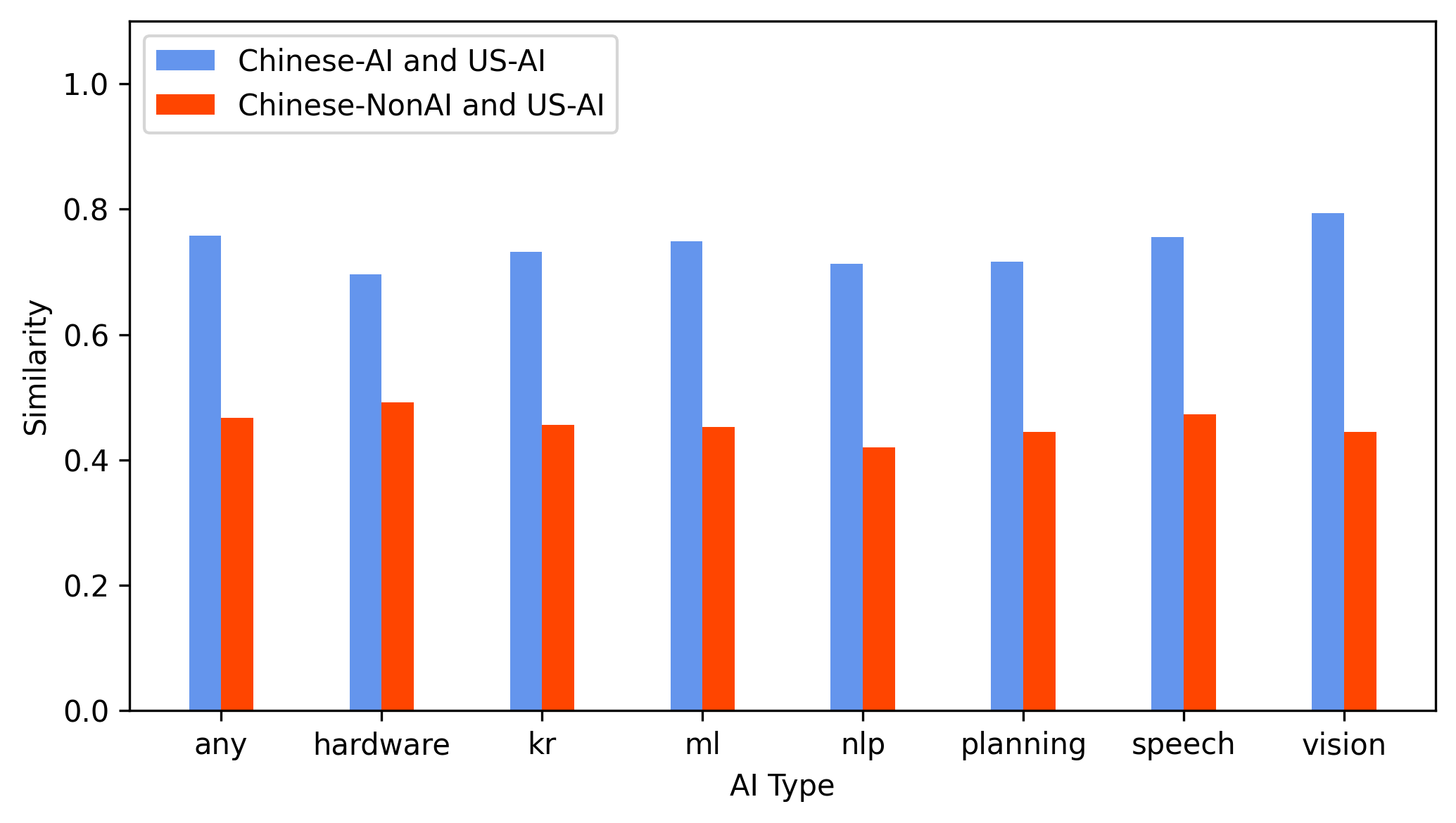
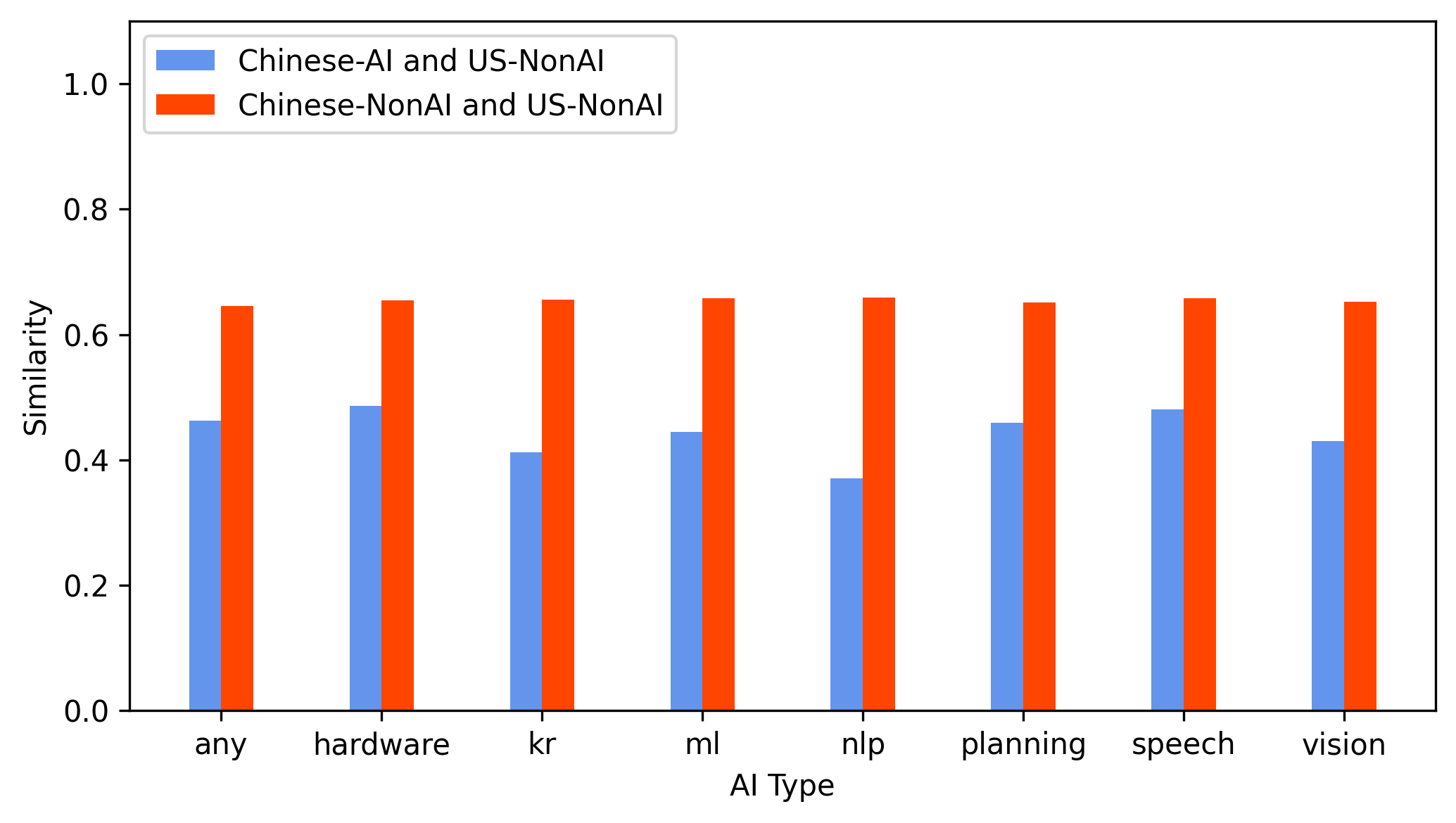
Figure 6: Lexical similarity analysis substantiates the cross-country generalizability of the model by aligning the technical discourse of Chinese and US AI patents.
Dynamics of AI Innovation: Comparative Trends and Subfield Composition
Analysis over time reveals a dramatic convergence in AI patenting activity and subfield intensity between the US and China post-2010. China has overtaken the US in the annual count of AI patent grants since 2020 (Figure 7), though both countries display similar portfolios across planning, vision, knowledge processing, and other subfields (Figures 8, 9).
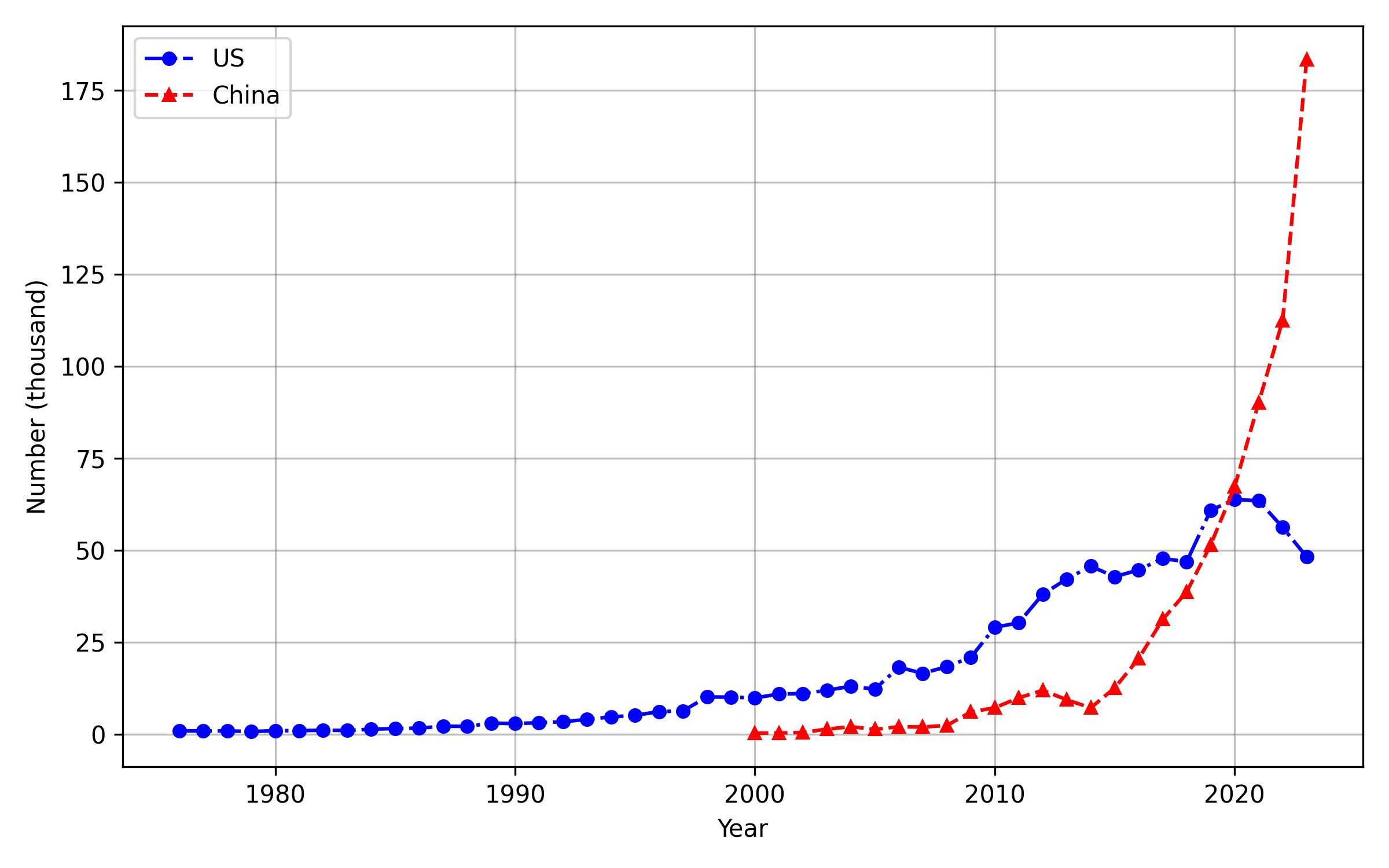
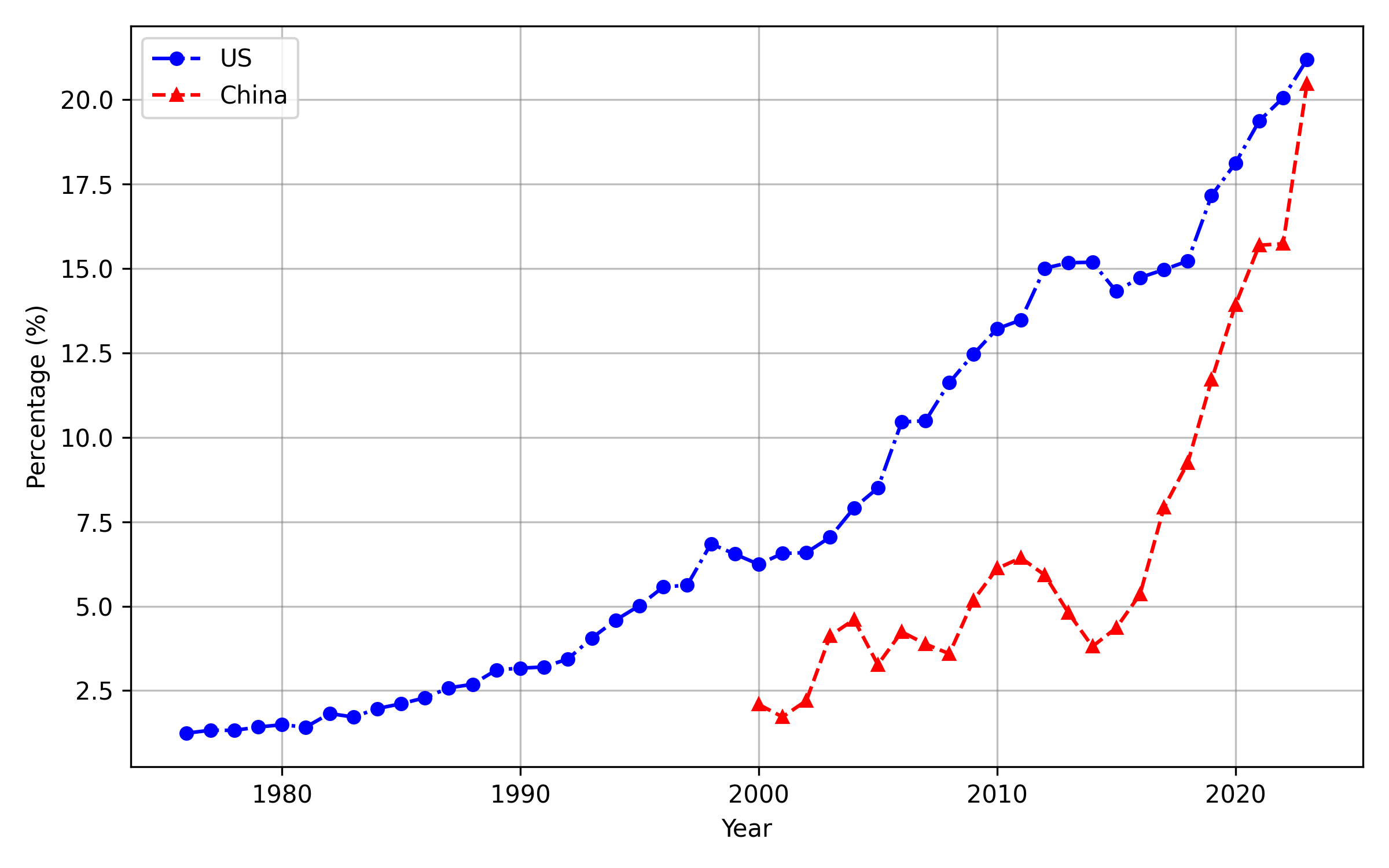
Figure 7: Time series comparison reveals China's rapid overtake of the US in AI patent issuance by volume.
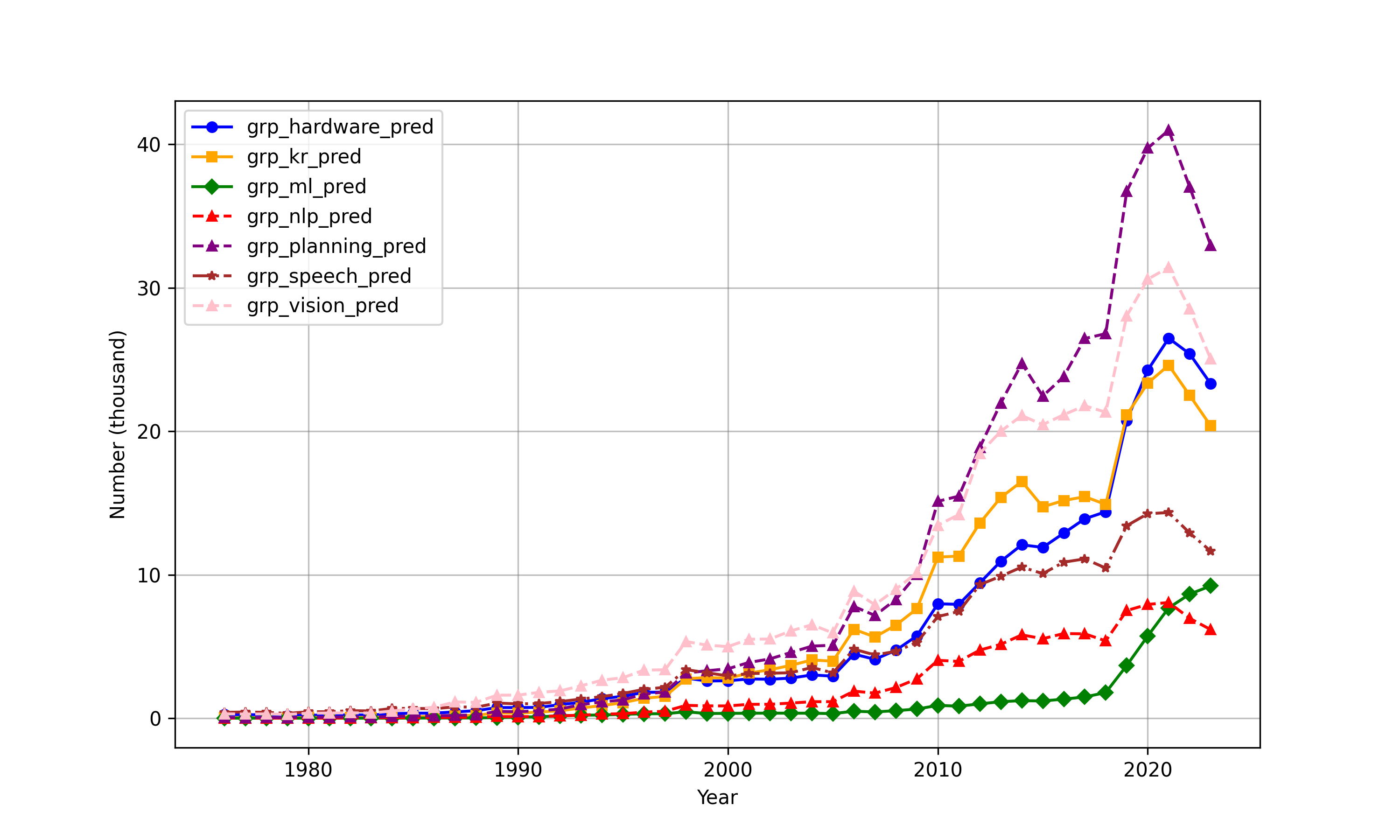
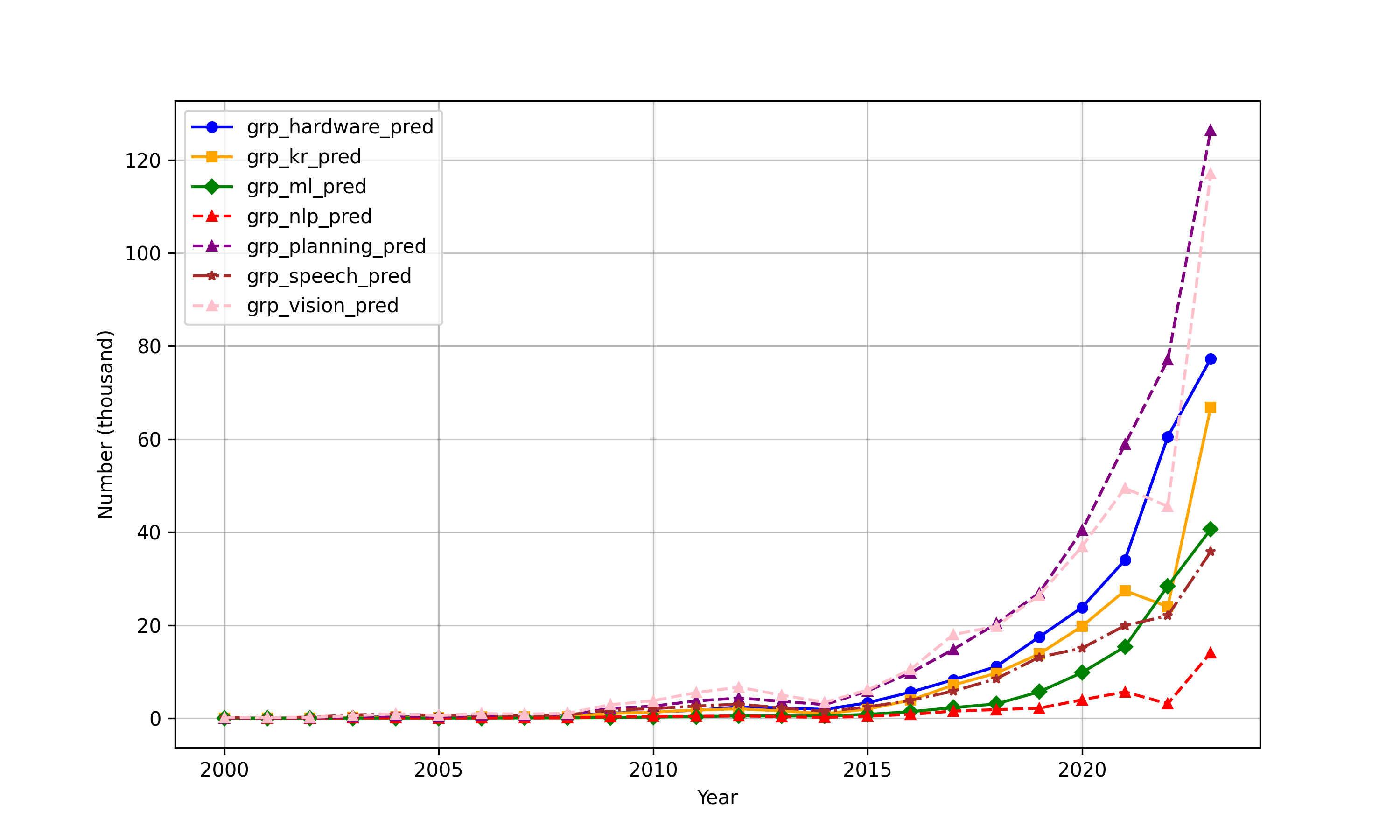
Figure 8: The annual issuance of AI patents by subcategory for each patent office reveals correlated subfield trajectories.
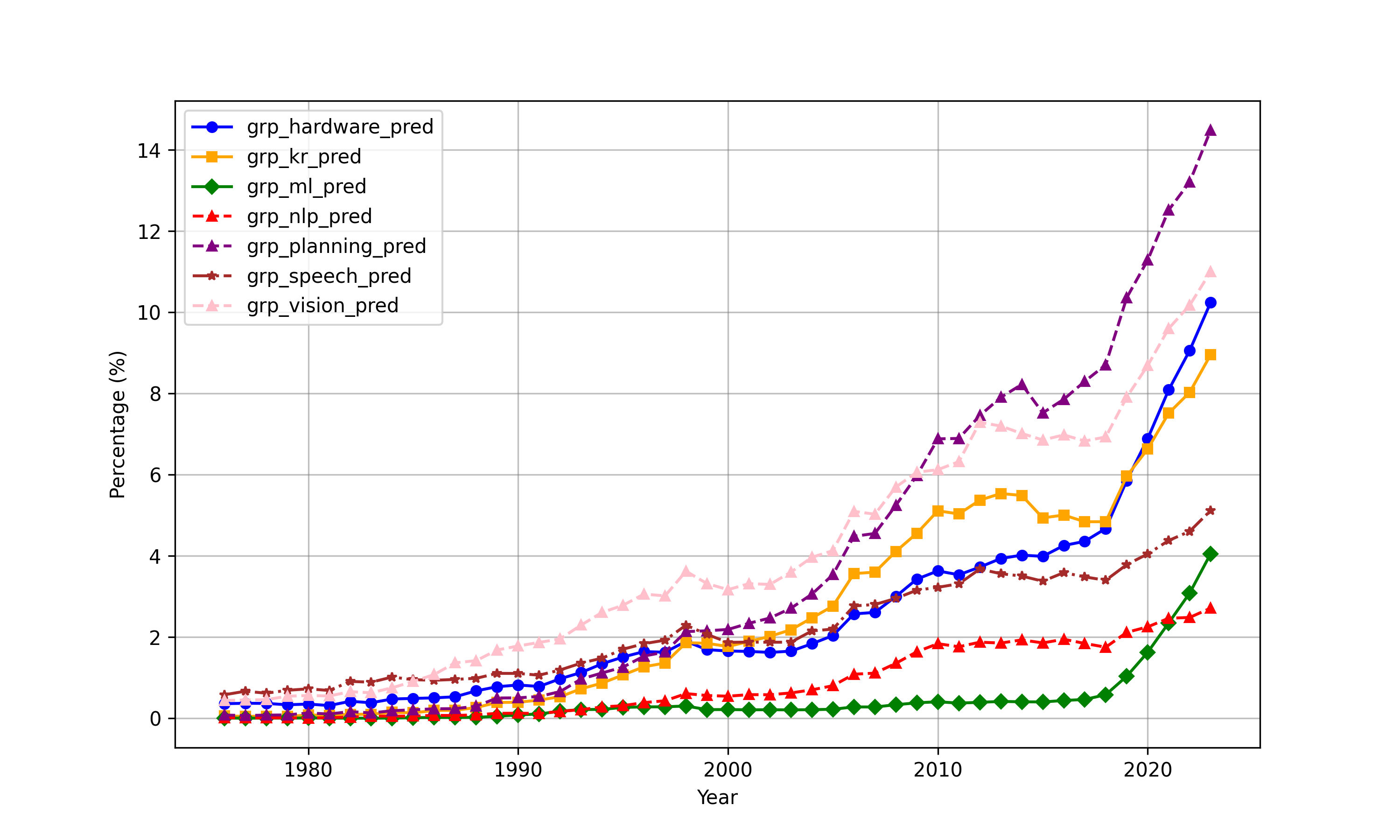
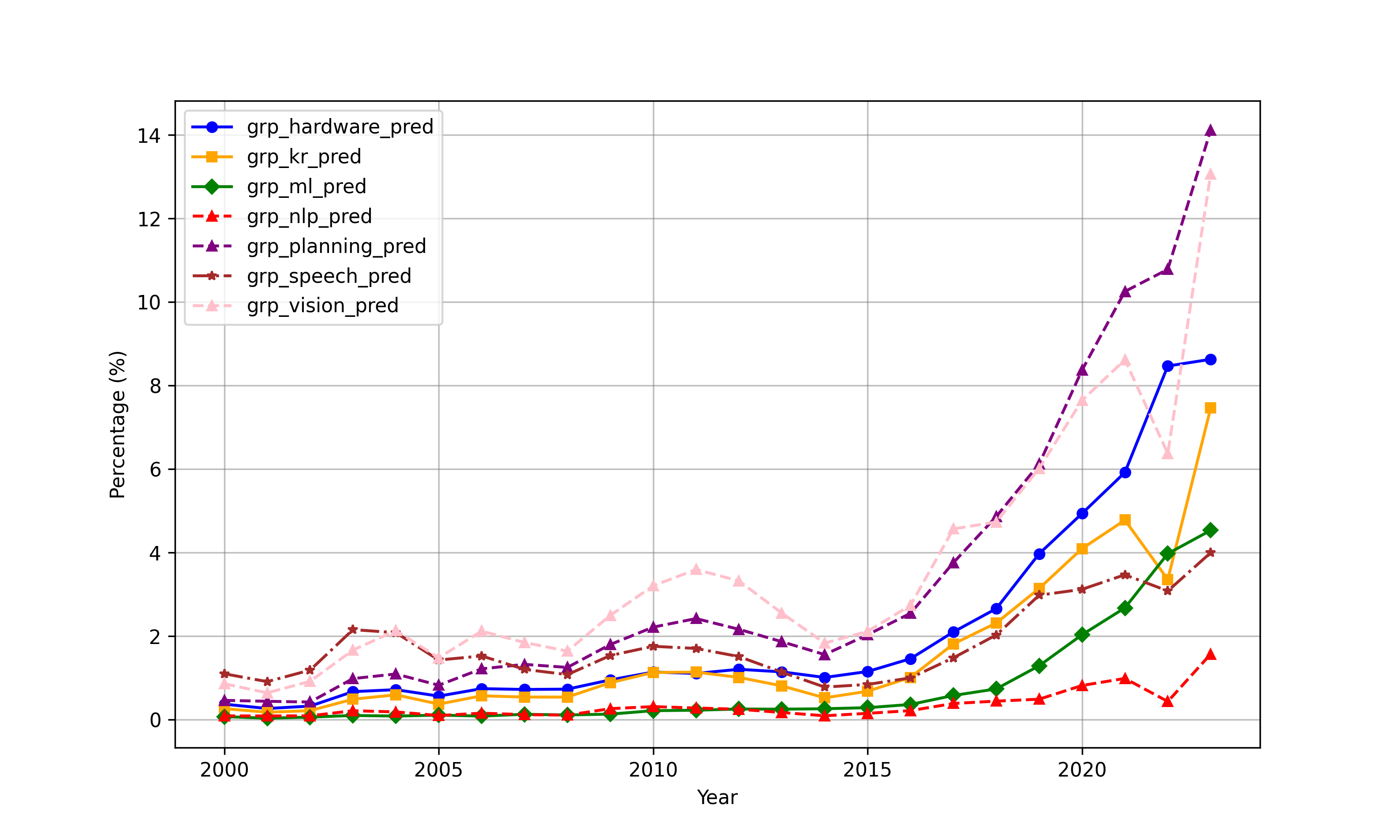
Figure 9: AI subfield shares illustrate compositional convergence and domain-specific divergences (notably in NLP and vision) between the US and China.
Multi-label classification further shows the intrinsically interdisciplinary nature of AI patents, with a nontrivial fraction spanning multiple subdomains; for example, ~49% of recent Chinese AI patents and 46% of US AI patents fall into two or more AI categories (Figure 10).
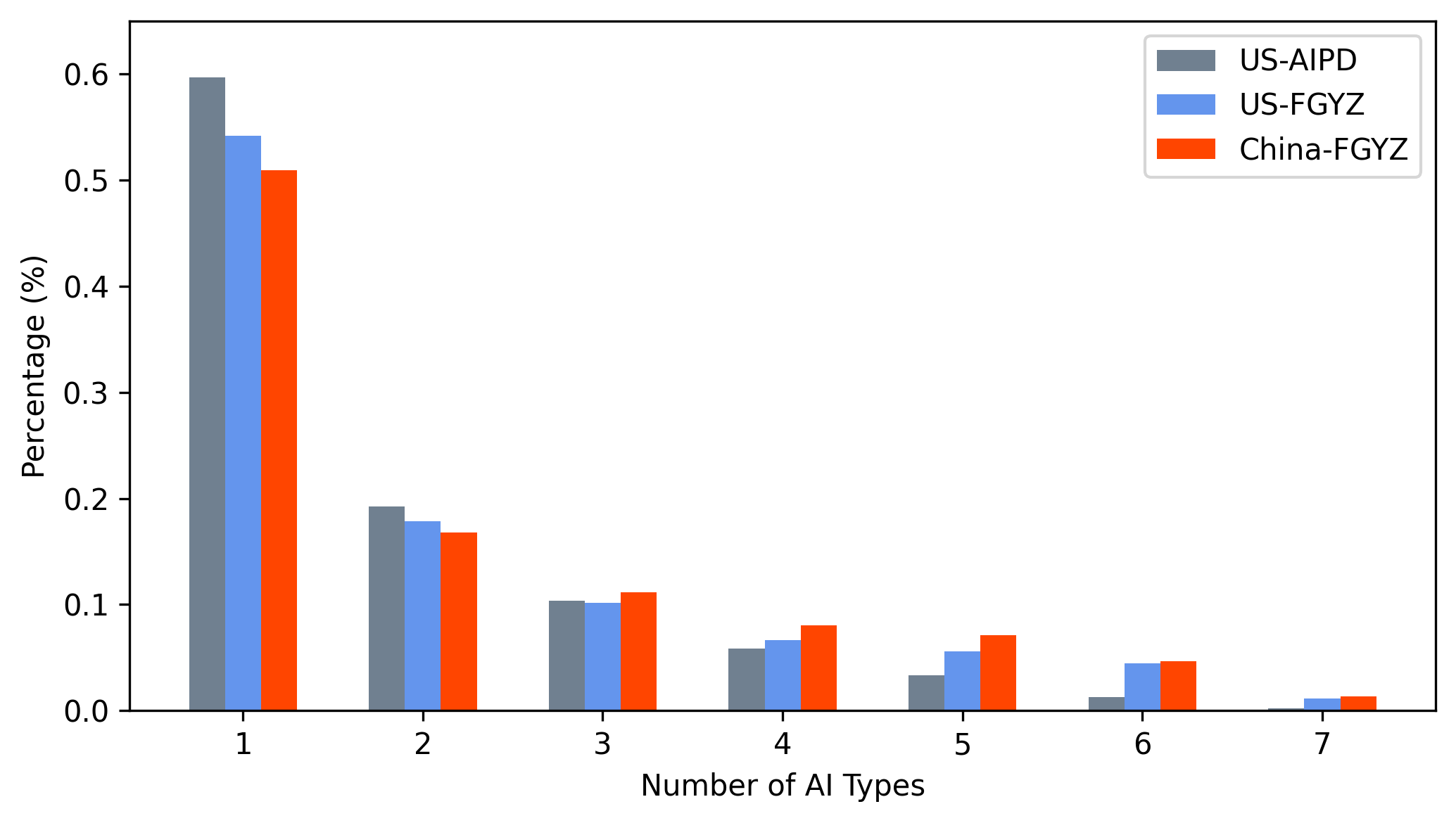
Figure 10: Disaggregation by subfield assignments confirms high AI patent interdisciplinarity in both jurisdictions.
Institutional and Spatial Organization of AI Innovation
The organizational structure of AI patenting diverges sharply. US innovation is highly concentrated among a small set of large private incumbents (IBM, Microsoft, Google, Amazon), whereas Chinese AI patenting is institutionally diverse, with both private tech firms (Tencent, Baidu), SOEs, and universities among top assignees (Table: Top Assignees). This heterogeneity in China is reflected in the geographical diffusion patterns. Spatial analysis shows persistent concentration in US super-clusters (California, Northeast Corridor), with only slow expansion to secondary hubs. In sharp contrast, Chinese AI patenting displays rapid geographic diffusion beyond initial hubs since 2010 (Figures 11–13).
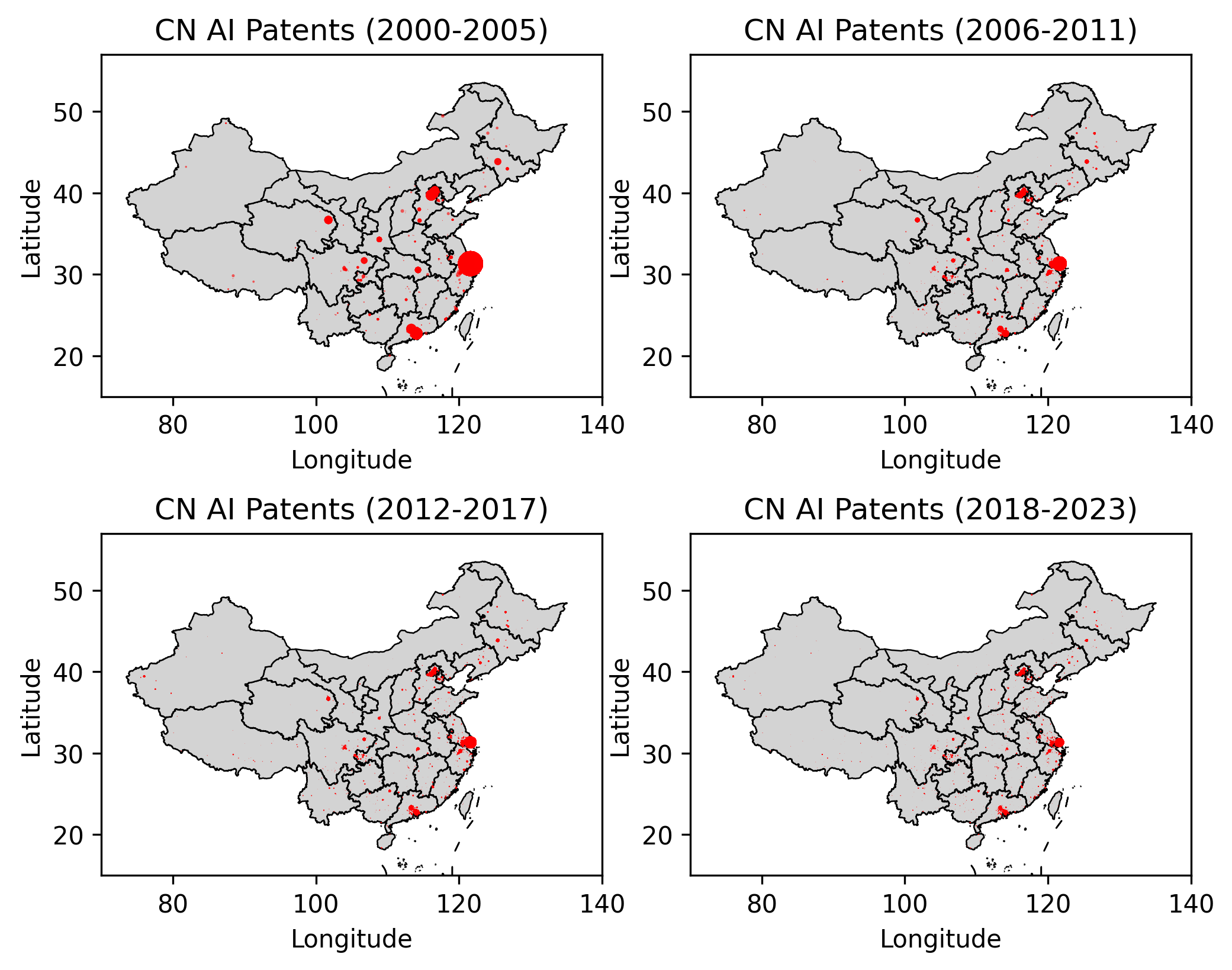
Figure 11: The spatial density of Chinese AI patents expands from coastal mega-regions to inland provincial centers over successive periods.
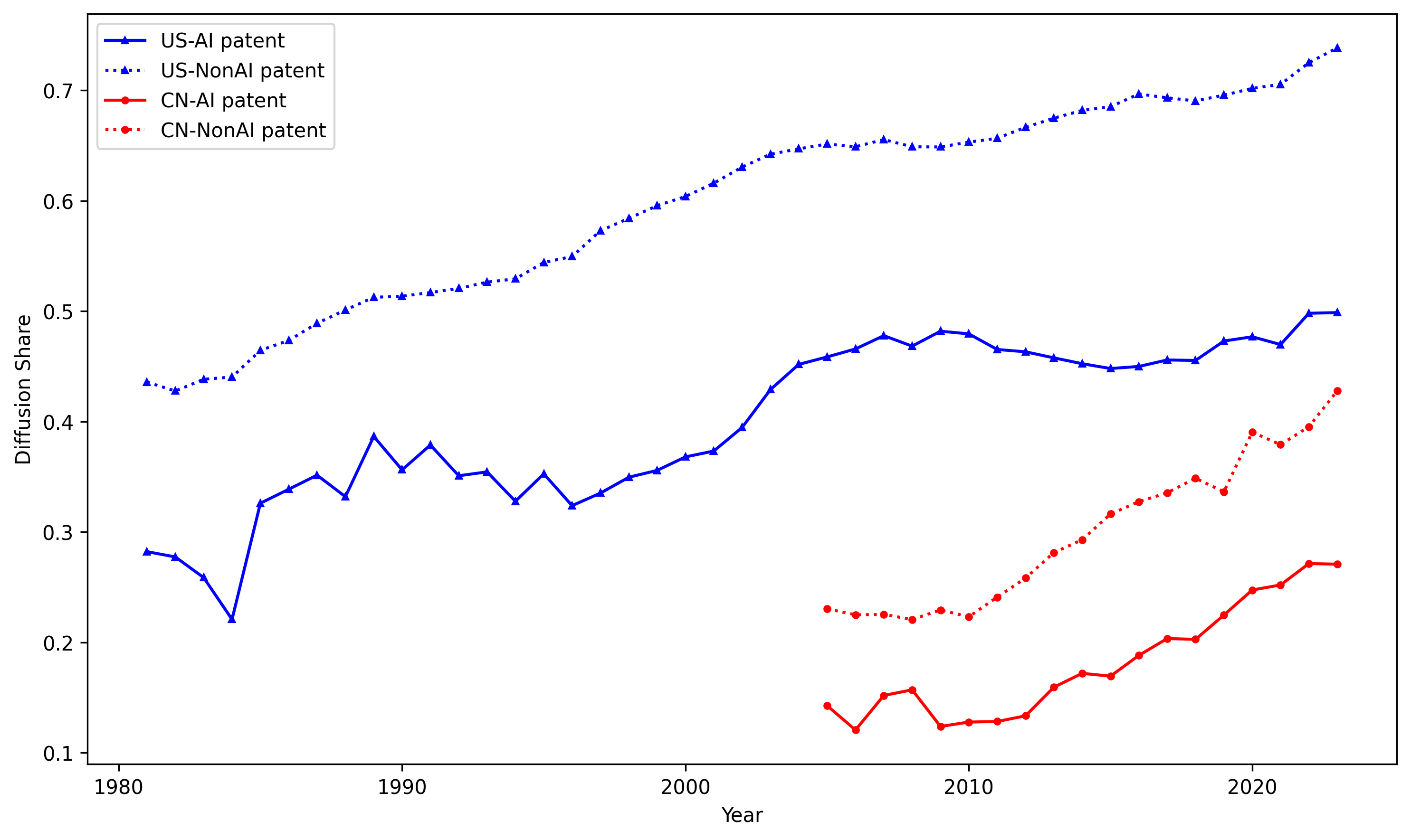
Figure 12: Spatial diffusion index quantifies a widening geographic footprint of AI inventive activity in China versus stasis in the US.
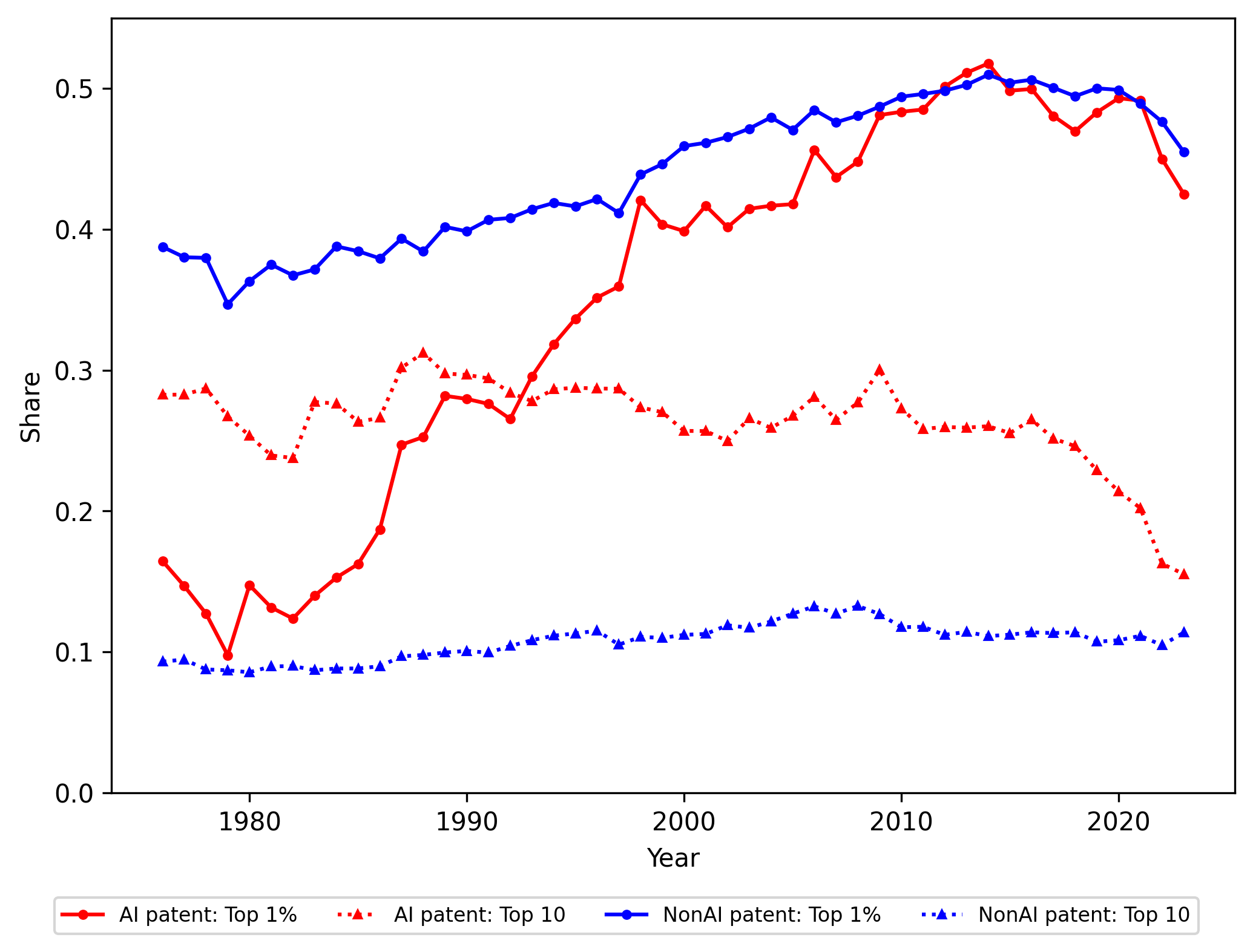
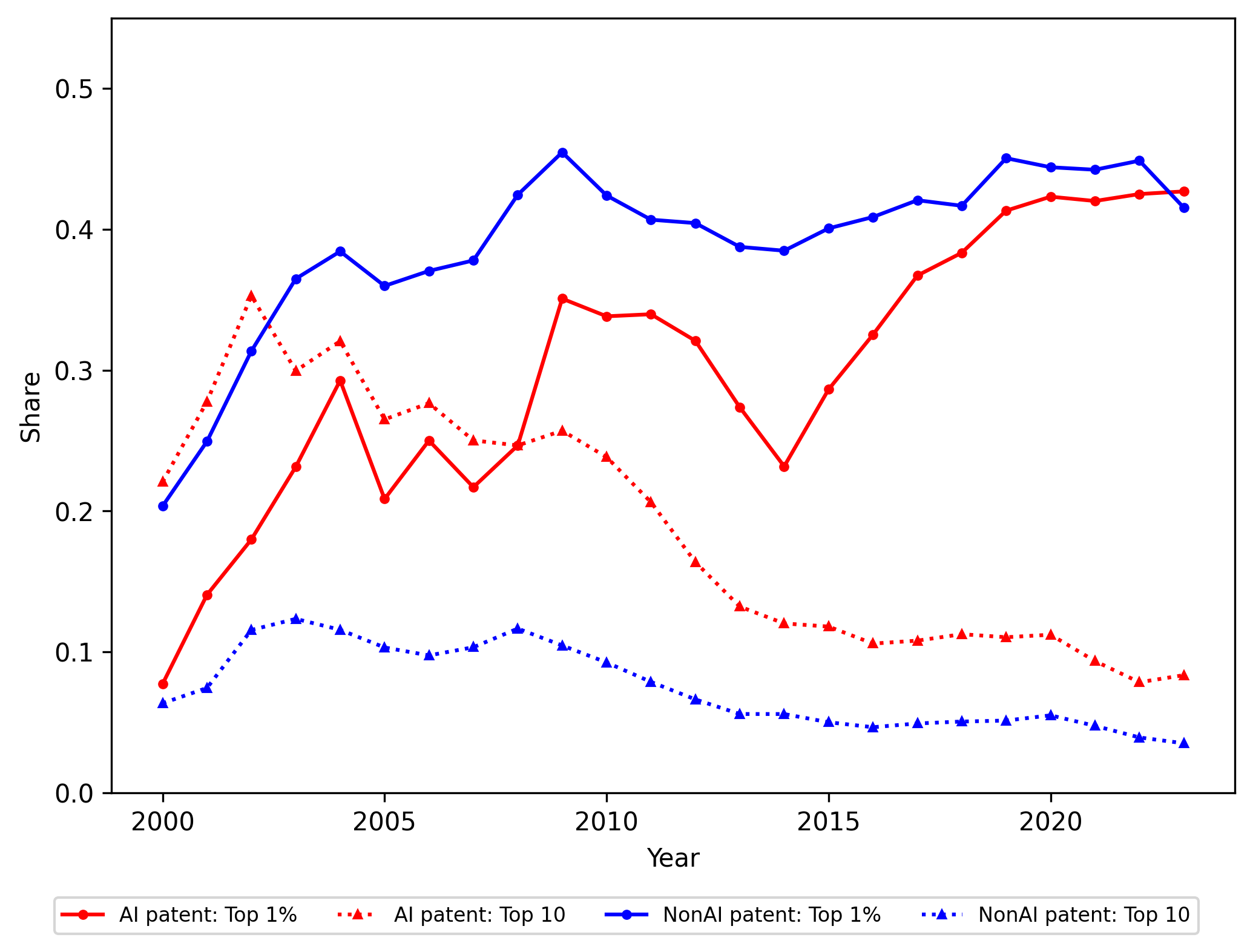
Figure 13: Institutional concentration in AI patenting increases in both countries, but the composition of top assignees is more heterogeneous in China.
Market Valuation: Economic Impact of AI Patents
Abnormal stock market returns around AI patent grant events, following the methodology of Kogan et al. (2017), establish a significant and robust market-value premium for AI over non-AI patents in both economies. This premium is most pronounced in data and software-centric domains (machine learning, NLP). Notably, the value differential for Chinese AI patents persists across institutional forms, challenging the contention that Chinese patent expansion is predominantly subsidy-driven or administratively motivated (Figure 14).
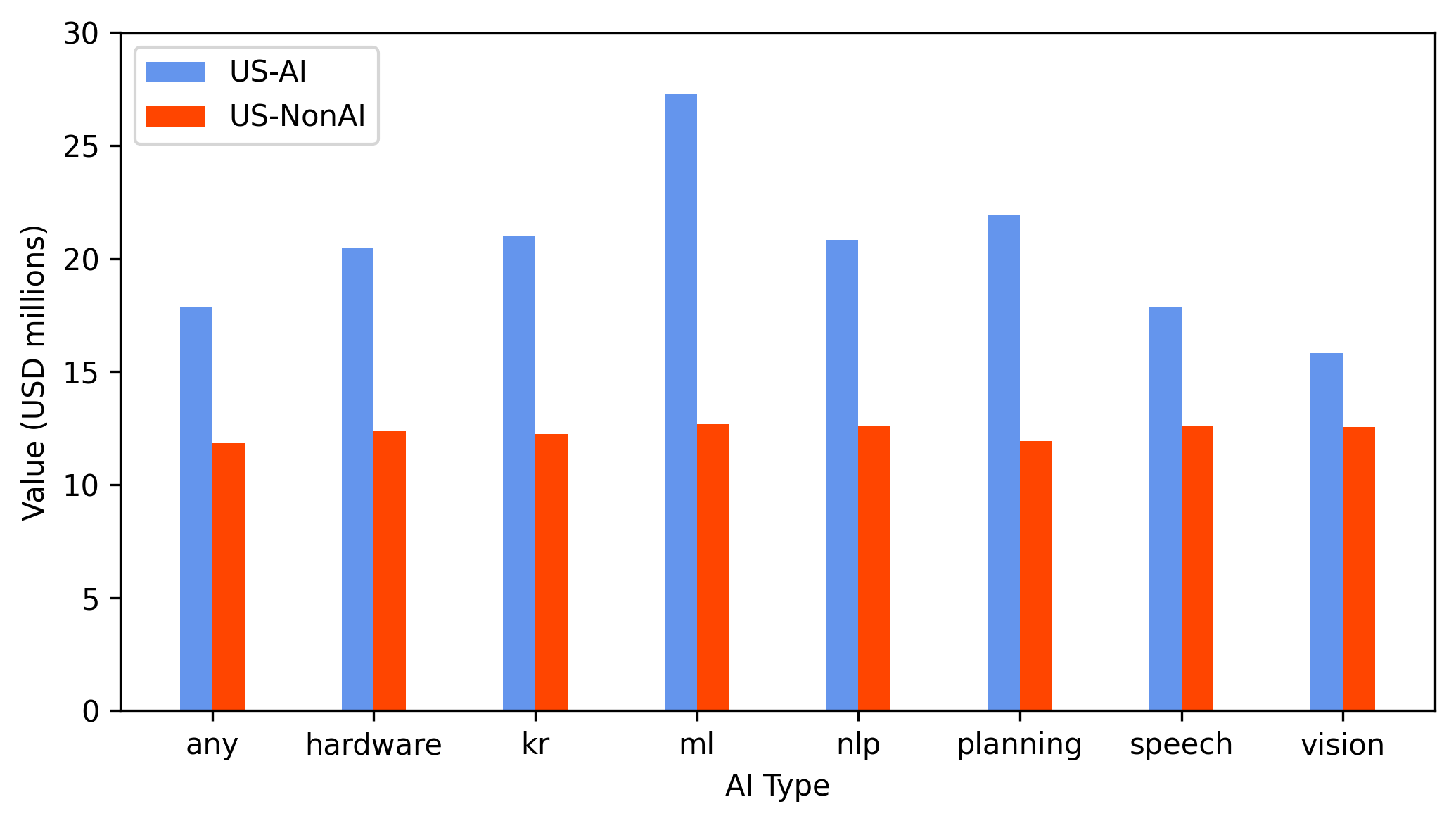
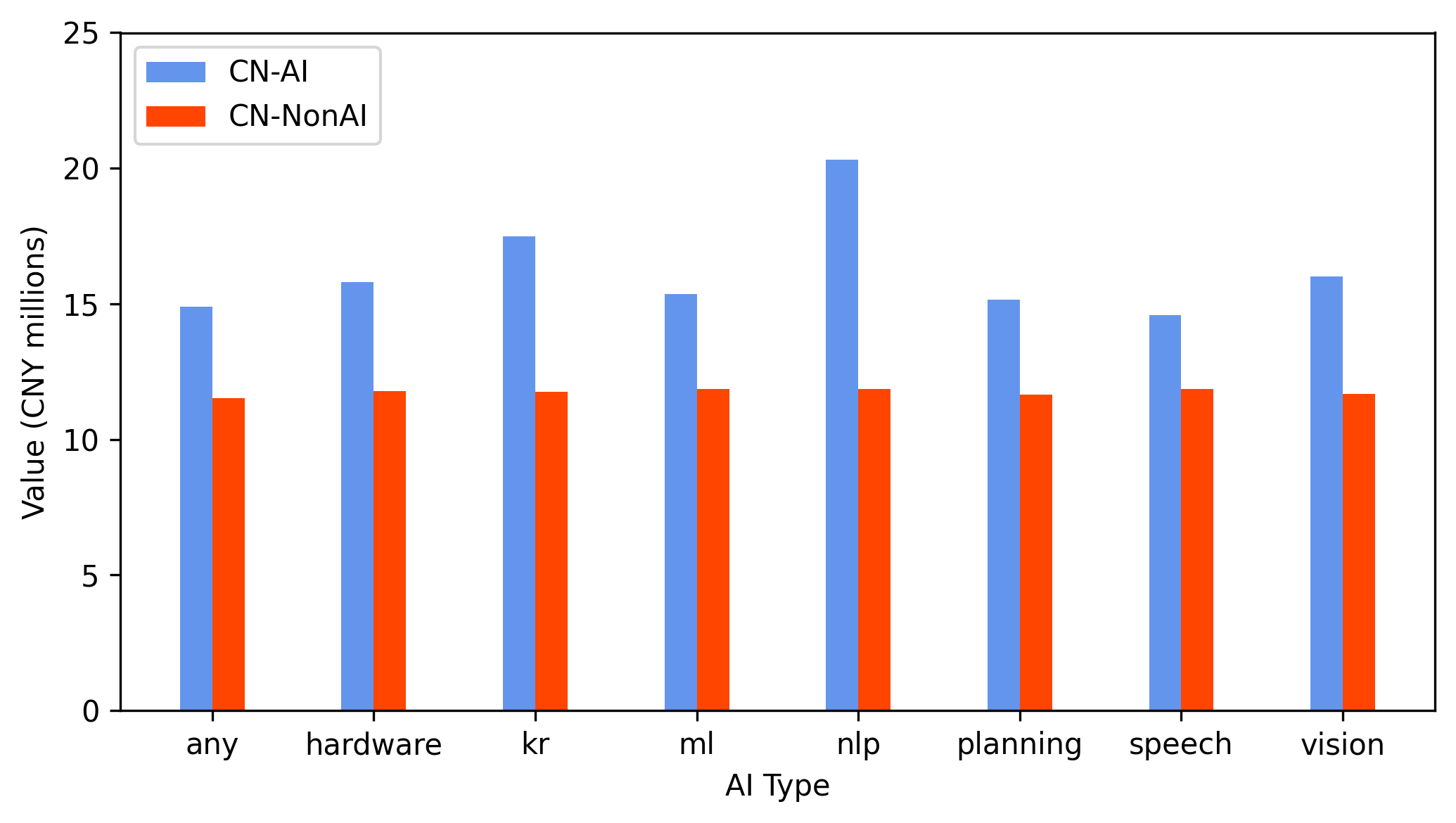
Figure 14: Abnormal stock return-based value measures show a robust AI patent premium in both China and the US, particularly in software-intensive subfields.
Cross-sectoral and Cross-border Knowledge Flows
In the US, academic-to-firm knowledge flows are sparse; university-developed AI patents exhibit high within-sector citation rates, revealing an enclaved knowledge ecosystem. In China, however, POEs and SOEs have intensive reciprocal citation linkages, indicating robust university–industry–state knowledge transfer. This structural distinction underscores the differentiated role of non-market actors in the two systems.
Analysis of cross-border citations between US and Chinese AI patents reveals continued technological interdependence rather than decoupling. Chinese AI inventors exhibit high citation propensity to the US AI frontier, with US-to-China citations concentrated in non-core AI domains (Figures 15, 16).
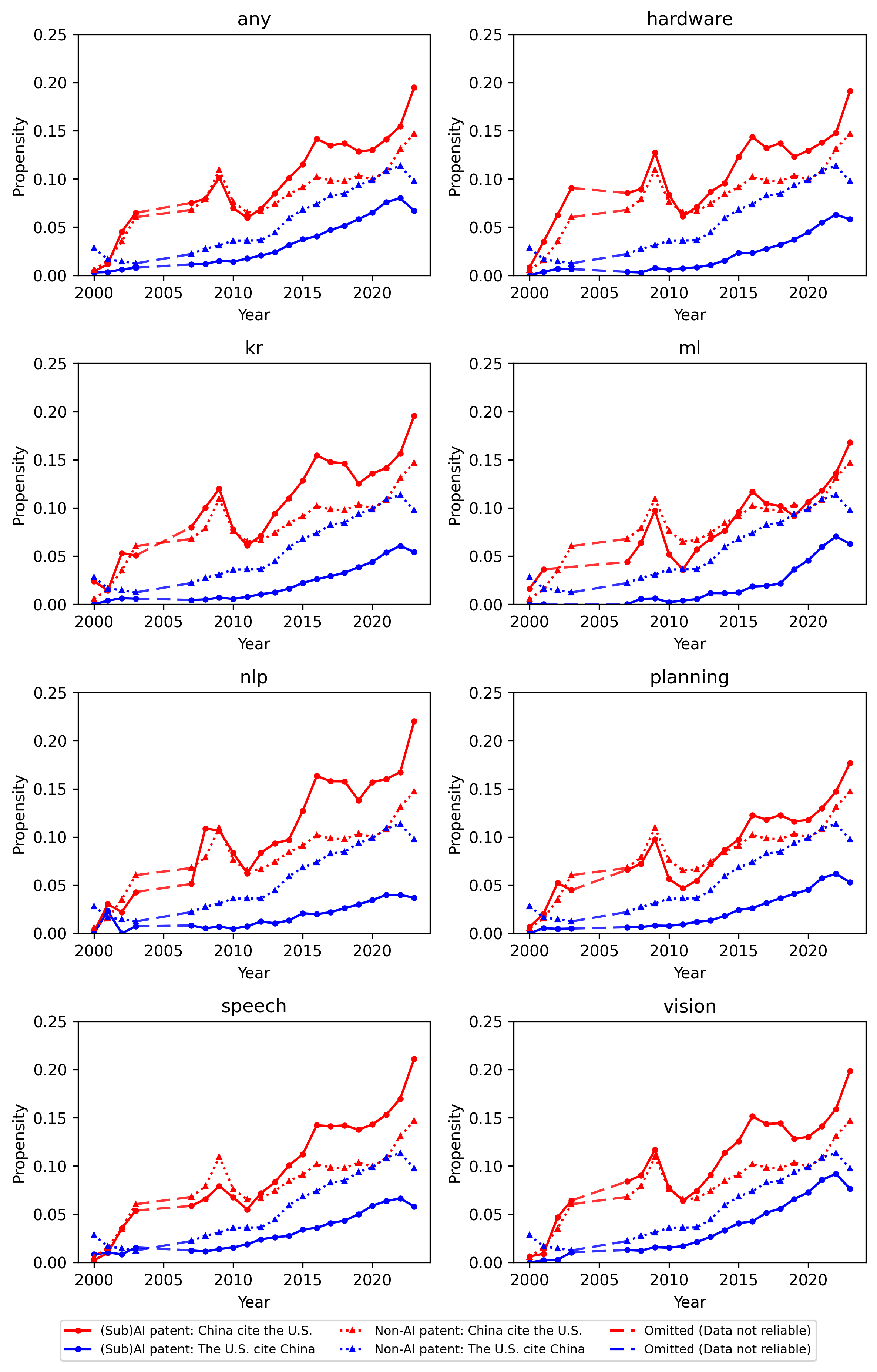
Figure 15: Citation propensity dynamics show strong, asymmetric learning from the US by Chinese AI patentees.
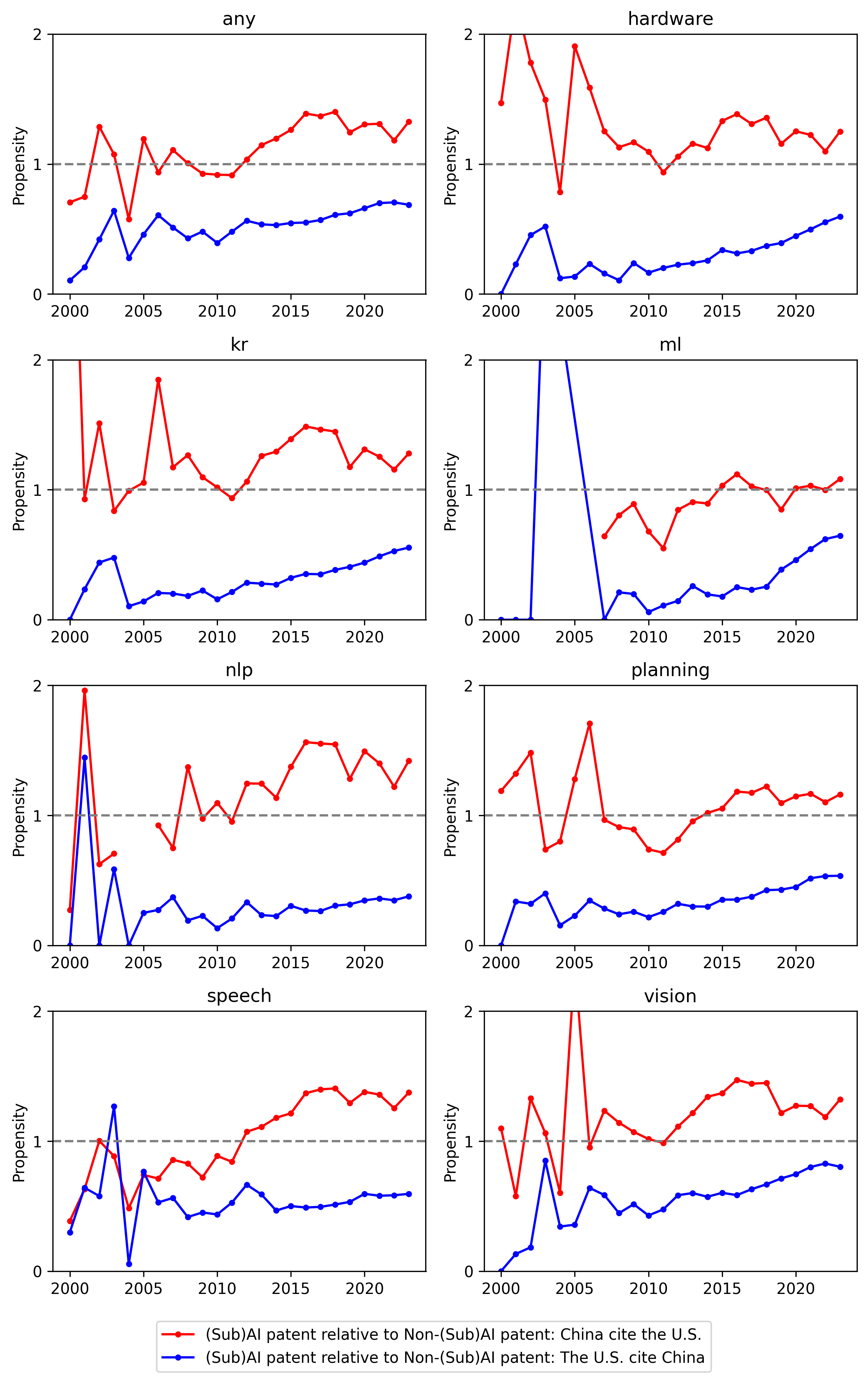
Figure 16: US-to-China cross-domain citation propensity highlights differentiated patterns of knowledge dependence.
Conclusion
The authors establish that the deployment of a fine-tuned LLM-based classifier enables a systematic, high-recall, and high-precision mapping of the AI patent landscape in both the US and China. This provides a robust platform for evaluating convergence in AI domains, divergence in institutional and geographic organization, and the underlying structure of knowledge flow—both domestic and transnational. The findings signal that, while the US and China are converging in AI inventive intensity and subfield composition, fundamental differences persist in spatial diffusion, market versus non-market institutional roles, and the directionality of knowledge flows. The evidence counters narratives of strict technological decoupling: cross-border citation dependence, especially of China on leading US AI inventions, remains strongly positive and in some subfields intensifies.
Future research avenues should focus on the integration of methodological advances in AI patent classification with datasets beyond patents, the analysis of non-patent IP forms, and the dynamic modeling of global knowledge diffusion in the evolving geopolitical context.
Reference: "AI Patents in the United States and China: Measurement, Organization, and Knowledge Flows" (2604.10529)