- The paper introduces a CPMI framework that quantifies belief shifts to efficiently assign step-level rewards in chain-of-thought reasoning.
- It leverages model log-likelihood differences and contrastive negatives to reduce annotation time by 84% compared to Monte Carlo methods.
- The approach achieves superior performance in mathematical reasoning benchmarks, demonstrating its scalability and robust discriminative power.
Introduction
This paper introduces a novel framework, Contrastive Pointwise Mutual Information (CPMI), for process reward modeling (PRM) in the context of LLM reasoning, specifically targeting step-level supervision in chain-of-thought (CoT) mathematical problem solving (2604.10660). Process reward models are critical for evaluating the correctness of intermediate steps in reasoning trajectories, facilitating both fine-grained evaluation and reward optimization. The difficulty in obtaining high-quality, large-scale, human-annotated step-level rewards has limited previous approaches, which typically either rely on costly human annotations or expensive Monte Carlo (MC) estimation via repeated LLM rollouts. The CPMI approach leverages the model’s own log-likelihoods to automate reward assignment, dramatically increasing annotation efficiency and scalability.
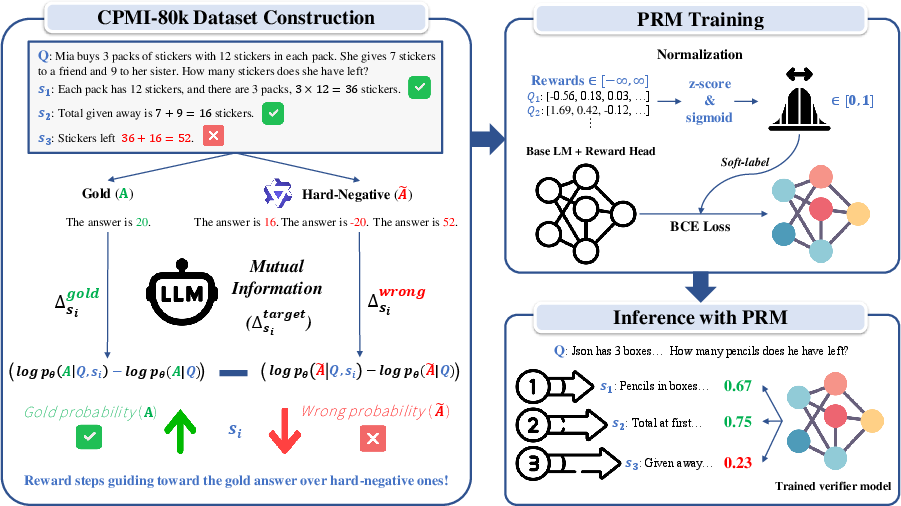
Figure 1: Main framework of reward modeling and PRM training leveraging CPMI-based step-level rewards for efficient, automated supervision.
Methods
CPMI Reward Definition
CPMI quantifies how much a given reasoning step shifts the model’s beliefs toward the correct (gold) answer and away from a set of hard negative (incorrect, plausible) answers. Formally, for each step si and M contrastive negatives, the CPMI reward is given by:
rCPMIi=[logpθ(A∣q,si)−logpθ(A∣q)]−M1m=1∑M[logpθ(A~m∣q,si)−logpθ(A~m∣q)].
This design enables highly efficient, single-forward-pass reward annotation that emphasizes both positive evidence for the ground-truth answer and negative evidence against plausible distractors, providing a dense local reward signal analogous to temporal-difference (TD-0) bootstrapping in RL. Theoretical analysis shows that CPMI approximates the Jeffreys divergence between the pre- and post-step model conditional distributions, yielding strong discriminative signals.
Dataset Construction
The CPMI-80k dataset is constructed by automating step-level reward annotation over reasoning trajectories from the Math-Shepherd corpus, aligned to GSM8K and MATH. Hard negative answers are sampled via the model itself, with additional heuristic perturbations (operator swaps, sign changes) to ensure contrastiveness and informativeness. Four prompt templates are used for reward stabilization via prompt diversification.
PRM Training
PRMs are trained with Qwen3-4B-Base as backbone, attaching a two-layer reward head and optimizing normalized CPMI rewards with a binary cross-entropy (BCE) objective. For robustness, reward values are z-score normalized and mapped to [0,1] via sigmoid. Baselines include MC and process-advantage (PAV) reward models. Hybrid CPMI-Merge variants are also explored, where MC is used for early steps and CPMI for subsequent steps, balancing bias-variance and computational cost.
Experimental Results
Annotation Efficiency
Empirical results highlight the significant efficiency gains of CPMI-based reward annotation. CPMI reduces dataset construction time by 84% and generated tokens by 98% compared to MC estimation, without sacrificing reward quality or downstream performance.
Discriminative Power in Step Quality Assessment
CPMI-labeled PRMs show improved discriminative power over MC and PAV baselines in step-level error detection and process error identification as measured by ROC-AUC, ProcessBench F1, and PRMBench metrics. The explicit contrastive term in CPMI is critical; ablations show that removal of the contrastive negative term leads to marked drops in step-level and downstream performance.
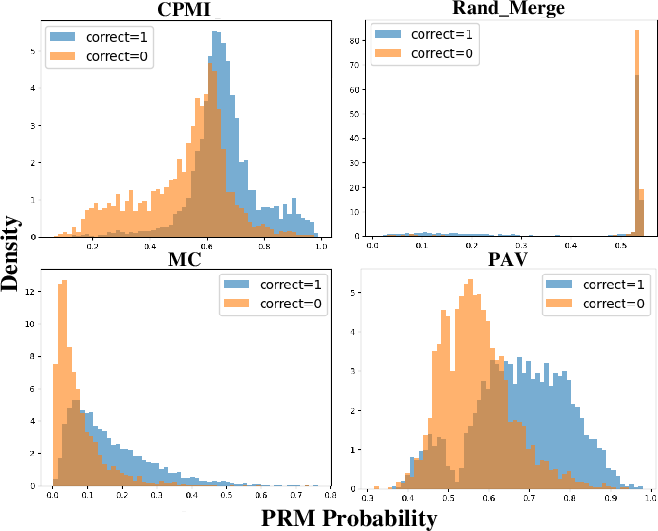
Figure 2: PRM probability distributions on ProcessBench Math split, showing clear separation between correct (blue) and incorrect (orange) steps for CPMI-trained PRMs.
Downstream Impact: Mathematical Reasoning and Sampling
On math reasoning benchmarks (MATH, GSM8K, MMLU, Omni-MATH), CPMI-trained PRMs consistently yield higher best-of-N (BoN) accuracy for larger N, reflecting their stronger trajectory ranking capability. Unlike MC, for which gains saturate or diminish with increasing N, CPMI PRMs continue to scale.
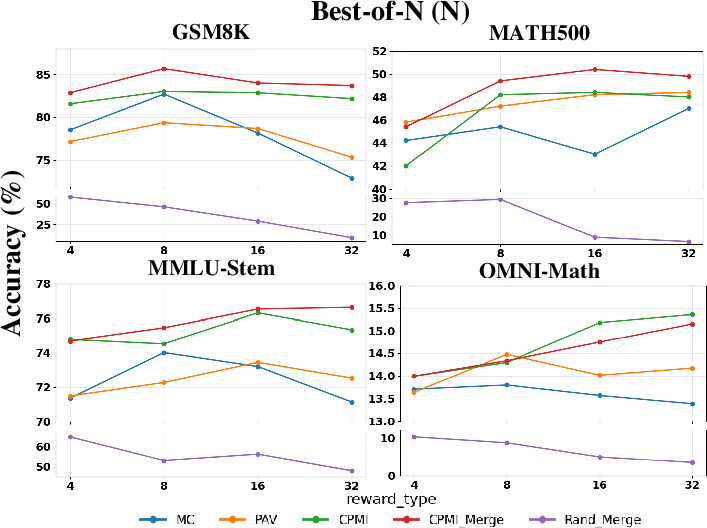
Figure 3: Best-of-N reasoning accuracy on math benchmarks, demonstrating consistent scaling of CPMI and CPMI-Merge PRMs with increased sampling.
Ablation: Influence of Hard-Negative Pool Size
Variation of the number of contrastive negatives M indicates that inclusion of even one hard negative is essential; however, performance is relatively robust for moderate values of M. Overly large M0 dilutes signal strength; defaulting to M1 balances stability and efficiency.
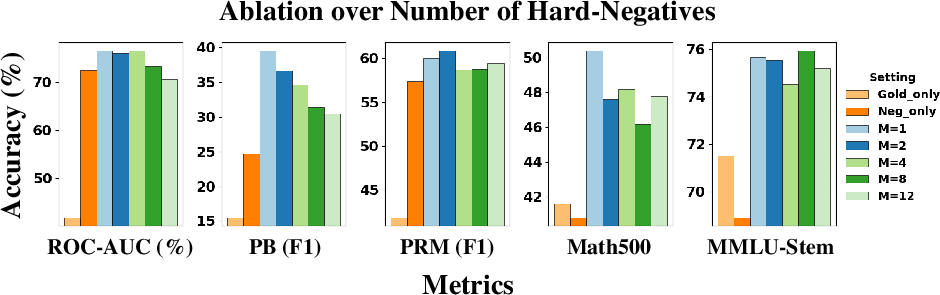
Figure 4: Ablation on number of hard negatives M2 in CPMI objective, highlighting stable process and downstream task performance for moderate M3.
Robustness and Generalization
CPMI-based reward labeling generalizes across backbone model sizes (down to 1B parameter LLMs) and to logical reasoning benchmarks, outperforming MC in all tested regimes at much lower annotation cost. CPMI’s efficacy is independent of downstream training objective, with superiority maintained under both regression (MSE) and pairwise ranking loss.
Implications and Future Directions
The CPMI framework demonstrates that contrastive, model-intrinsic belief shifts can effectively and efficiently supervise process-level reward models for reasoning tasks. This result has direct implications for large-scale, scalable PRM dataset construction, making fine-grained process supervision feasible within both academic and industrial constraints. The framework’s efficiency is particularly salient in resource-constrained environments and for rapid reward dataset development.
Theoretically, CPMI offers an explicitly contrastive, symmetric information-theoretic reward which penalizes reward hacking risks associated with non-contrastive likelihood-based objectives. Its design admits straightforward extension to online reinforcement learning frameworks, model-based RL, or integration with self-improving verifier approaches.
Future work directions include scaling CPMI-annotated process data to larger domains (including multi-hop and non-math tasks), further diversification of hard-negative construction strategies, and systematic benchmarking with larger PRM architectures and online RL settings.
Conclusion
CPMI enables efficient, highly discriminative process reward modeling for LLMs by leveraging the model’s own local evidence shifts over gold and contrastive hypotheses. This yields superior process supervision signals at a fraction of the computational budget required by MC-based approaches. CPMI-trained PRMs not only achieve stronger process-level assessment but also provide more effective control for mathematical reasoning via best-of-M4 selection, with consistently better sample efficiency and generalization. This framework provides a practical, theoretically-grounded tool for the next generation of process supervision in structured LLM reasoning (2604.10660).