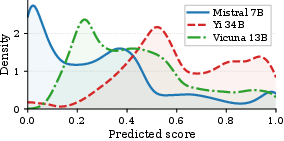
- The paper introduces joint resource allocation and routing optimization that significantly improves output quality under strict latency constraints.
- It employs a dual-price formulation and dynamic latency profiling to adapt GPU partitioning and routing decisions based on real-time model performance.
- Experiments on NVIDIA A100 clusters demonstrate up to 87% performance variance versus static setups, highlighting the benefits of holistic system co-design.
RouterWise: Joint Resource Allocation and Routing for Latency-Aware Multi-Model LLM Serving
Introduction
Modern multi-model LLM serving systems must balance the competing objectives of minimizing latency, optimizing throughput, and preserving output quality, especially under heterogeneous prompt workloads. Traditional LLM routing frameworks largely assume fixed per-model latency and stateless serving, which decouples prompt routing from system resource configuration. "RouterWise: Joint Resource Allocation and Routing for Latency-Aware Multi-Model LLM Serving" (2604.10907) critically re-examines this paradigm and demonstrates the necessity of jointly optimizing resource allocation (GPU placement, compute/memory partitioning) and routing policies. The work provides empirical and theoretical evidence that disregarding dynamic latency interdependencies results in significantly suboptimal system performance.
RouterWise formalizes multi-model LLM serving as a constrained (joint) optimization problem. Given a set of deployed LLMs, a GPU cluster, and a router that estimates prompt-model quality (utility), the goal is to determine:
- System Setup: The concrete assignment of GPUs, tensor parallelism levels (TP), compute caps (e.g., CUDA thread fraction via NVIDIA MPS), and memory partitions to each model.
- Prompt Routing Policy: An assignment function π:X→{1,...,M} that routes each input x to one model.
The overarching objective is to maximize mean output quality subject to a latency SLO (Service Level Objective) τ.

Figure 1: Resource allocation strategies in multi-model LLM serving. Models can run in isolation or be co-located for improved resource utilization and flexible sharing.
Unlike prior work, the paper recognizes that model latency is nontrivially coupled to both resource allocations and the realized traffic induced by the routing policy. Thus, setup and routing must be optimized together rather than in isolation.
Dynamic Latency Profiling and Resource Allocation
RouterWise enables flexible, fine-grained sharing of available GPU resources by supporting MPS-based compute partitioning and VRAM slicing for co-located model shards. Extensive profiling with A100s and vLLM demonstrates that:
- Increasing thread percentage sharply reduces P95 TTFT (time to first token) for a fixed model and load.
- Latency-load curves are both configuration- and model-dependent, exhibiting non-linearities due to resource contention and TP scaling.
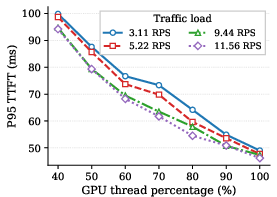
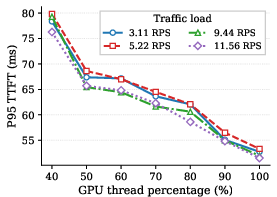
Figure 2: P95 TTFT for Vicuna-13B under varying thread allocations and TP settings. TTFT generally declines with increased threads, but these improvements are load- and configuration-dependent.
RouterWise implements a piecewise-linear, setup-specific latency model for each model/config tuple, interpolated from profiling data. This approach robustly handles the complex heterogeneity of co-located deployments instead of relying on erroneous static cost assumptions.
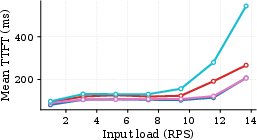
Figure 4: Average TTFT as a function of input load for multiple models and configuration settings; latency-load relationships can invert depending on model, illustrating the risk of static assumptions.
Joint Routing and Setup Optimization
Routing Utility Model
Given per-model quality estimates si(x) for prompt x, the router predicts the expected output score if x is served by i. The assignment of prompts to models is then cast as a combinatorial problem whose objective is maximizing average score under routing fraction constraints, with the additional constraint that the induced per-model load does not violate latency SLOs.
The paper introduces a dual-price formulation for routing: model-specific dual variables αi act as marginal "prices" that penalize over-assignment to model i. At each iteration, the prompt assignment is argmaxi(si(x)−αi), and the duals are adjusted by subgradient steps to enforce target routing fractions. This dual approach ensures tractable and convex optimization over routing distributions in high dimensions.
Latency-constrained Joint Optimization
For a fixed system setup, RouterWise relaxes the latency constraint using a Lagrangian multiplier x0 and seeks the routing distribution x1 that optimizes the penalized objective:
x2
By sweeping x3, the method efficiently explores the Pareto frontier of the score-latency curve and selects the optimal trade-off that satisfies the tight latency constraint.
Discrete Setup Space Search
RouterWise systematically enumerates the system setup space (possible combinations of x4 and x5 for each model), aggressively prunes infeasible setups based on underutilization, overcommitment, or illegal placement, and for each retained setup, solves for optimal routing via the bisection/dual-price method. This procedure is scalable through pruning but guarantees the global optimum within the discretized configuration space.
Experimental Evaluation
Evaluation is performed on clusters of 4 and 8 NVIDIA A100 GPUs, using Mistral-7B, WizardLM-13B, and Yi-34B-Chat as models. The experiments leverage the RouterBench dataset (36k prompts with per-model quality annotations) for utility estimation.
Key findings include:
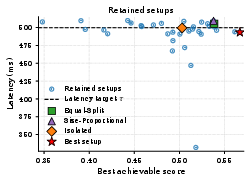
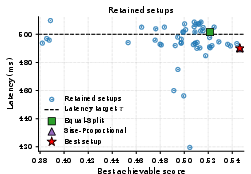
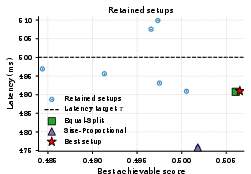
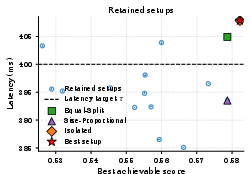
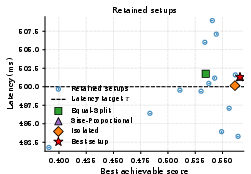
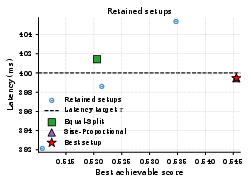
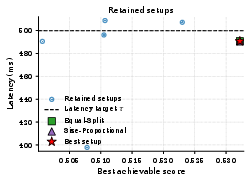
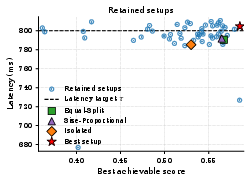
Figure 5: Score-latency scatter of retained setups for x7 and x8. Setup selection yields large differences in maximum achievable output quality at fixed SLO.
RouterWise's setup search space remains tractable: for three models, there are x9700 feasible setups; for four models, τ016,000. Empirical overhead is modest due to aggressive pruning and parallelizable evaluation.
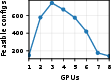
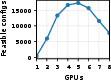
Figure 6: Retained setup space growth is subexponential due to deployability constraints and compute-budget filters, supporting practical scalability to moderate τ1 and τ2.
Implications and Future Directions
RouterWise's joint optimization strategy exposes a critical performance axis ignored in prior work. Practically, latency-aware resource-routing co-design can drive substantial improvements in service quality, enabling more efficient deployment of LLMs in multi-model inference scenarios (e.g., enterprise AI, cloud providers, or modular AI agents). Theoretically, the work motivates a new paradigm in serving systems: treating all hardware-level and software-level parameters as first-class optimizable variables in routing and scheduling policies.
Future research may focus on:
- Scalable exploration/pruning techniques to handle larger numbers of candidate models and cluster sizes.
- Robust online adaptation to drift in prompt input distributions or system conditions.
- Extensions to more complex latency SLOs, batch serving, preemption, or adaptive GPU provisioning.
Conclusion
RouterWise introduces a rigorous framework for jointly optimizing resource allocation and prompt routing in multi-model LLM serving, using dual-price routing and setup-dependent latency profiling. The results definitively establish that ignoring resource allocation leads to significant degradation in achievable output quality under latency constraints. The practical and theoretical insights presented herein are likely to influence the design of future LLM serving stacks, driving a more holistic integration of systems-level and algorithmic control.