Introspective Diffusion Language Models
Abstract: Diffusion LLMs promise parallel generation, yet still lag behind autoregressive (AR) models in quality. We stem this gap to a failure of introspective consistency: AR models agree with their own generations, while DLMs often do not. We define the introspective acceptance rate, which measures whether a model accepts its previously generated tokens. This reveals why AR training has a structural advantage: causal masking and logit shifting implicitly enforce introspective consistency. Motivated by this observation, we introduce Introspective Diffusion LLM (I-DLM), a paradigm that retains diffusion-style parallel decoding while inheriting the introspective consistency of AR training. I-DLM uses a novel introspective strided decoding (ISD) algorithm, which enables the model to verify previously generated tokens while advancing new ones in the same forward pass. From a systems standpoint, we build I-DLM inference engine on AR-inherited optimizations and further customize it with a stationary-batch scheduler. To the best of our knowledge, I-DLM is the first DLM to match the quality of its same-scale AR counterpart while outperforming prior DLMs in both model quality and practical serving efficiency across 15 benchmarks. It reaches 69.6 on AIME-24 and 45.7 on LiveCodeBench-v6, exceeding LLaDA-2.1-mini (16B) by more than 26 and 15 points, respectively. Beyond quality, I-DLM is designed for the growing demand of large-concurrency serving, delivering about 3x higher throughput than prior state-of-the-art DLMs.
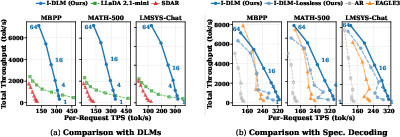
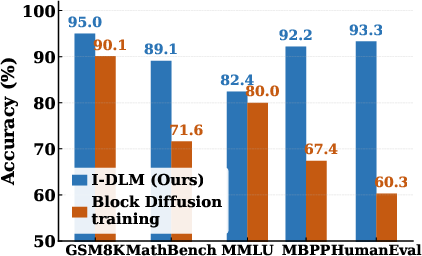
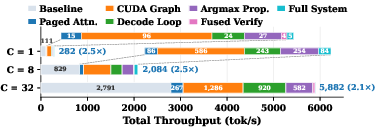
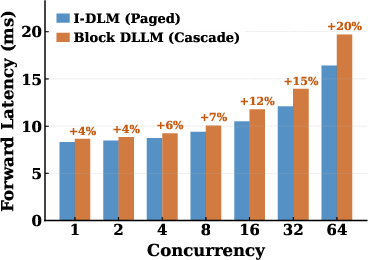
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Introspective Diffusion LLMs (I‑DLM)”
What this paper is about (the big idea)
The paper introduces a new kind of AI LLM called an Introspective Diffusion LLM (I‑DLM). It aims to combine two good things:
- The speed of “diffusion” models that can write several words at once (parallel writing).
- The reliability of “autoregressive” (AR) models that write one word at a time and naturally double‑check their work as they go.
The key insight: previous fast, parallel models weren’t great at “agreeing with themselves” when they re‑examined what they just wrote. This paper teaches a diffusion model to check its own work while it writes—so it stays fast but also becomes as accurate as strong one‑word‑at‑a‑time models.
What questions did the researchers want to answer?
In simple terms, they asked:
- Why do diffusion LLMs, which can write multiple words at once, often sound worse or make more mistakes than traditional models that write one word at a time?
- Can we design a diffusion model that “trusts” and verifies its own writing the same way AR models do?
- Can we make this work not just in theory but also run fast in real systems that handle many users at the same time?
They focused on a concept they call “introspective consistency,” which means: if the model writes some words and then immediately re-checks them using the same rules, does it agree with itself?
How did they approach it (methods in everyday language)
Think of two writing styles:
- Autoregressive (AR): Like writing an essay one word at a time, always looking at everything you’ve already written and making sure the next word fits. This naturally builds in a self-check.
- Diffusion: Like filling in chunks of blank spaces with several words at once, then refining them. It’s fast, but you might not be checking each word in the same way every time.
The authors make a diffusion model that keeps the speed but learns to self-check like AR. They do this in two main steps:
- Training the model to agree with itself
- Causal attention (simple idea): The model only looks at what’s already written to decide the next word—like reading from left to right. This mimics how AR models think.
- Logit shift (plain idea): They train the model so that the hidden state at each word is always predicting the next word, not the current one—again matching the AR way of thinking.
- All‑masked training: During practice, the model sees a fully masked (blanked-out) version alongside the real sentence. Every position is trained to be useful, so no compute is wasted.
- Balanced learning: They automatically balance the training so the “writing” and “self-checking” parts learn equally well.
- Fast, self-checking writing at inference time
- Introspective Strided Decoding (ISD): The model writes several words at a time (a “stride”), and in the very same pass, it verifies the previous words using the same rules it uses to write. If the check agrees with the earlier guess, the word is kept. If not, it’s fixed immediately. You can think of it as “write a few words, check as you go, keep what passes, redo the rest,” all in one smooth step.
- Acceptance test (everyday analogy): For each new word, the model asks, “Does my careful check agree with my earlier guess?” If yes, keep it; if no, revise that word and move on.
- Systems engineering: They built the serving engine to plug right into standard AR systems (like popular LLM servers), so it’s easy to deploy and runs efficiently even with lots of users at once.
What they found (results) and why it matters
- Quality catches up to strong AR models: I‑DLM matches the accuracy of same‑size autoregressive models on many tests (like math and coding), which is a first for diffusion‑style LLMs.
- Big gains over previous diffusion models: On many benchmarks, I‑DLM clearly outperforms earlier diffusion models. For example, on a tough math test (AIME‑24) and a coding test (LiveCodeBench v6), it scores far higher.
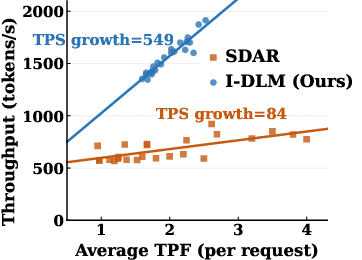
- Faster in real deployments: Because I‑DLM is designed to work well with existing AR servers, it delivers higher throughput (tokens per second) when many requests run at the same time—about 3× higher throughput than prior top diffusion models in their tests.
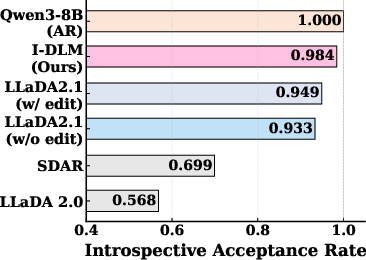
- Strong self‑agreement: The model’s “introspective acceptance rate” (how often it agrees with its own earlier guesses) is much higher than previous diffusion methods, which helps prevent errors from piling up in long answers.
Why this matters: It shows that teaching a model to check itself using the same rules it uses to write makes parallel writing both fast and reliable. That’s a big step forward for getting the best of both worlds.
Why this is important (impact and implications)
- Faster, trustworthy AI writing: I‑DLM can write multiple words at once without losing the carefulness of word‑by‑word models. That means quicker responses without a big drop in quality.
- Better for busy apps: Because it fits naturally into existing serving systems, companies can serve more users at once with high quality.
- A design principle for future models: The idea of “introspective consistency” (self-checking that matches how you write) could guide future models in areas like reasoning, math, and coding.
- Flexible modes: The approach supports both a nearly exact match to the base AR model’s output (lossless mode) and faster, slightly more flexible modes—giving engineers a quality‑speed dial to tune.
In short, the paper’s message is simple: if a fast writer learns to check its own work the same way it writes, it can be both quick and correct. That’s what I‑DLM delivers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces I-DLM with introspective-consistency training and Introspective Strided Decoding (ISD). Below is a focused list of what remains uncertain or unexplored, framed to guide future research:
- Generalization across bases and scales: Does the training recipe (causal + logit shift + all-masked) reliably transfer to other AR backbones (e.g., Llama/Mistral families, MoE architectures, 70B–100B+ scales) and to instruction-tuned vs. base models without retraining instability or quality regressions?
- Multilingual and multimodal coverage: How does I-DLM perform on multilingual datasets (including non-Latin scripts) and in multimodal settings where attention structures and token distributions differ substantially?
- Long-context behavior: How do acceptance rates, throughput, and quality scale with very long context windows (e.g., 128k–1M tokens) where KV cache pressure and context dilution could lower acceptance?
- Distributional robustness: What are acceptance and quality profiles in high-entropy or creative generation (e.g., open-ended writing), low-structure tasks, and out-of-domain inputs not covered by the 15 benchmarks?
- Decoding configuration sensitivity: How do temperature, top-/nucleus sampling, and beam search affect the acceptance criterion, exactness guarantees, and diversity, given the use of argmax proposals during serving?
- Exactness guarantees and assumptions: Provide a formal, end-to-end proof that ISD yields samples from the base AR distribution under practical settings (same-model and , logit shift, argmax proposals, sampling filters), including corner cases (EOS handling, padding, special tokens).
- Lossless R-ISD rigor: Precisely characterize conditions under which “bit-for-bit lossless” outputs are guaranteed (effects of layer norm statistics, mixed-precision arithmetic, quantization, LoRA gating at mask positions, and CUDA graph replays).
- Handling low-acceptance regimes: Quantify compute/latency degradation and output stability when acceptance falls below break-even (e.g., <0.8); design principled fallback strategies (dynamic stride reduction, AR-only phases, or draft-free speculative hybrids) to avoid wasted compute.
- Acceptance–quality relationship: Systematically study whether higher introspective acceptance rates causally correlate with downstream accuracy across tasks and domains, and analyze when high acceptance can mask distributional miscalibration beyond the sampled token.
- Metric adequacy: Evaluate whether “introspective acceptance rate” (avg min(1, p/q)) reliably reflects distributional agreement beyond the sampled outcome; compare against distribution-level divergences (e.g., JS/KL on top-) and calibration metrics.
- Training-cost trade-offs: The all-masked concatenation doubles effective sequence length during training; quantify end-to-end compute/memory cost vs. gains, and evaluate whether this induces catastrophic forgetting or knowledge drift relative to the AR base.
- Hyperparameter sensitivity: Characterize stability and optimal settings for auto-balanced loss scaling, stride during training and inference, continued training to increase , and the relaxed-acceptance knob across tasks.
- Alignment and safety preservation: Assess how conversion affects RLHF behaviors, refusal rates, jailbreak robustness, and toxicity; IFEval alone is insufficient to establish alignment retention.
- Streaming and user experience: Analyze token emission cadence and perceived latency in interactive settings (multi-turn chat, streaming) where verification may delay display of drafted tokens.
- EOS and boundary handling: Detail and test correctness around EOS emission, early stopping, and partial-block acceptance near sequence ends where shifted logits and stride windows interact.
- KV cache dynamics and memory fragmentation: Provide worst-case analyses and measurements of KV trim/commit cycles, fragmentation under continuous batching, and memory overhead from appending masks at large concurrency and long contexts.
- Portability and hardware diversity: Validate speedups on A100s, consumer GPUs, and different kernel stacks (non-paged attention, no CUDA graphs), and with common inference features (INT8/4-bit quantization, MoE routing, tensor/pipeline parallel, multi-node).
- Quantization compatibility: Determine how low-bit quantization interacts with verification (numerical stability of normalize(max(0, p–q)), softmax under FP8/INT8), and whether acceptance rates degrade.
- Integration with other accelerations: Explore composability with external speculative decoding (two-model), multi-token prediction heads, and KV cache recycling; identify regimes where hybrids outperform ISD alone.
- Diversity vs. acceptance trade-off: Measure how argmax proposals (used to boost acceptance) affect sample diversity in tasks where diverse outputs matter; develop diversity-aware proposal strategies that preserve exactness.
- Broader task coverage: Extend evaluation to summarization, translation, retrieval-augmented QA, tool-use/function calling, and long-form factuality to test whether introspective consistency benefits persist.
- Failure case analysis: Provide qualitative and quantitative diagnostics of rejection hotspots (positions, token types, prompt patterns) and common correction paths to guide targeted model or data improvements.
- Data and comparison fairness: Control for data budgets and instruction/thinking-mode settings across baselines to isolate the contribution of introspective-consistency training vs. confounds (e.g., different token counts, hidden prompt-engineering).
- Training recipe reproducibility: Release detailed hyperparameters, data composition, and curriculum for increasing stride to ensure replicability and to help practitioners avoid instability when porting to new bases.
- Extension beyond text: Investigate whether the introspective-consistency principle and ISD apply to other discrete generation domains (e.g., protein sequences, program traces) and to multimodal token decoders where causal anchoring differs.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s methods, metrics, and serving innovations.
- High-throughput LLM serving for chat and copilots
- Sectors: software, customer support, education, finance, healthcare
- Use cases:
- Multi-user chatbots and enterprise copilots (e.g., helpdesk, CRM, EMR note drafting, financial report summaries) with 2–3× higher throughput at similar quality to AR models.
- Coding assistants in IDEs (faster suggestions with near-AR quality for code, tests, and refactors).
- Tools/products/workflows:
- Integrate I-DLM/ISD into SGLang-compatible stacks as a drop-in “AR-compatible DLM serving” backend.
- Configure stride N=3–4, default strict acceptance (τ=0) for guaranteed correctness; increase τ slightly for higher speed where acceptable.
- Use lossless R-ISD (gated LoRA) for safety-critical workloads, yielding bit-for-bit AR outputs with parallel decoding.
- Assumptions/dependencies:
- Access to base AR models of interest and modest finetuning (≈4.5B tokens) to convert to I-DLM.
- Acceptance rates in practice ≥0.85 to achieve net efficiency gains.
- Compatibility with causal-attention serving (e.g., SGLang); GPU inference environment.
- Cost-efficient batch inference for data generation
- Sectors: software, academia, content platforms
- Use cases:
- Synthetic data generation (e.g., instruction tuning corpora, code datasets, math reasoning traces) at substantially higher tokens/sec under concurrency.
- Tools/products/workflows:
- “I-DLM data factory” pipeline with stationary-batch scheduling and CUDA graph capture; argmax proposals for higher acceptance.
- Assumptions/dependencies:
- Memory-bound decode regime to benefit most from TPF↑; proper KV paging and CUDA graph setup.
- Self-speculative decoding without a draft model
- Sectors: software, cloud platforms
- Use cases:
- Accelerate existing AR deployments without training/maintaining a separate small draft model.
- Tools/products/workflows:
- R-ISD mode (gated LoRA residuals only at [MASK] positions) to guarantee exact AR outputs; integrate as a “speculative mode” switch.
- Assumptions/dependencies:
- Train light LoRA adapters; ensure base-model-only introspection path and KV cache persist.
- Latency/QoS control via adaptive stride and acceptance
- Sectors: SaaS, enterprise IT
- Use cases:
- Meeting strict SLAs by dynamically adjusting stride N and acceptance threshold τ per request or tenant.
- Tools/products/workflows:
- A “QoS controller” that modulates N and τ based on queue depth, target latency, and observed acceptance rates.
- Assumptions/dependencies:
- Monitoring of acceptance rates; admission control to avoid GPU saturation.
- Reliability monitoring and guardrails using introspective acceptance rate
- Sectors: healthcare, finance, education, enterprise
- Use cases:
- Online quality signal: low acceptance segments flag potential hallucinations or difficult spans; trigger AR fallback, human review, or tool-call retries.
- Tools/products/workflows:
- “Accept-Rate Monitor” that logs per-span p/q statistics and drives escalation policies.
- Assumptions/dependencies:
- Calibrated acceptance-rate thresholds for each task and risk profile.
- On-prem and multi-tenant deployments with better economics
- Sectors: cloud, MSPs, regulated industries
- Use cases:
- Serve more concurrent users per GPU with consistent progression (at least one verified token per step), improving utilization and cost/token.
- Tools/products/workflows:
- “Stationary-batch scheduler” and paged-only attention kernels integrated in existing inference gateways.
- Assumptions/dependencies:
- Modern GPU stack with paged KV cache and CUDA graph capture; batch sizes that realize concurrency benefits.
- Education and tutoring assistants with faster reasoning
- Sectors: education, consumer apps
- Use cases:
- Math and code tutoring where I-DLM matches AR model quality but responds faster under load.
- Tools/products/workflows:
- ISD decoding with strict acceptance for correctness; optional τ>0 in low-stakes settings.
- Assumptions/dependencies:
- Acceptance monitoring to keep reasoning chains reliable; content moderation unchanged.
- Developer tooling and CI acceleration
- Sectors: software engineering
- Use cases:
- Faster unit-test generation, code review suggestions, and documentation drafts with near-AR accuracy.
- Tools/products/workflows:
- IDE plugins and CI bots backed by I-DLM runtime; use lossless mode for compliance-critical repos.
- Assumptions/dependencies:
- Base model quality on code tasks; acceptance-driven fallback for tricky code paths.
Long-Term Applications
The following require further research, integration, or scaling before wide deployment.
- Generalizing introspective DLMs to multimodal and speech systems
- Sectors: media, accessibility, autonomous systems
- Use cases:
- Parallel, self-verified decoding for audio transcription/translation and vision-language reasoning with AR-level quality.
- Potential tools/products:
- “Introspective Multimodal Decoder” libraries with causal anchors per modality.
- Assumptions/dependencies:
- Extension of strict causal training and logit shift to multimodal encoders/decoders; training data and acceptance metrics per modality.
- Energy- and sustainability-aware serving policies
- Sectors: energy, cloud, policy
- Use cases:
- Data centers selecting stride/τ to minimize energy/token while meeting SLAs; reporting acceptance-based efficiency metrics.
- Potential tools/products:
- “Green Serving Controller” optimizing TPF/compute-overhead vs. energy.
- Assumptions/dependencies:
- Standardized telemetry and energy models tied to acceptance/TPF; policy alignment on efficiency reporting.
- Standardization of introspective acceptance as a quality/uncertainty metric
- Sectors: policy, academia, enterprise governance
- Use cases:
- Benchmarks and compliance regimes using acceptance-rate thresholds as part of model-card disclosures; procurement specs for public-sector AI.
- Potential tools/products:
- Acceptance-aware evaluation suites and dashboards; audit logs keyed to p/q trajectories.
- Assumptions/dependencies:
- Community consensus on metric definitions and task-dependent calibration.
- Training-time acceleration via introspective consistency from scratch
- Sectors: foundation model labs, academia
- Use cases:
- Pretraining objectives that natively co-train generation and verification to reduce compute or improve stability.
- Potential tools/products:
- Pretraining recipes with all-masked causal objectives and logit shift; curriculum for stride scaling.
- Assumptions/dependencies:
- Large-scale experiments validating convergence and data efficiency beyond finetuning.
- Agent systems that exploit adaptive stride and acceptance-aware planning
- Sectors: automation, RPA, robotics
- Use cases:
- Multi-step tool-using agents that speed up “easy” steps (high acceptance) and slow down on hard steps; acceptance dips trigger tool retries or human-in-the-loop.
- Potential tools/products:
- Acceptance-gated planners and chain-of-thought controllers; “stride-aware” task schedulers.
- Assumptions/dependencies:
- Integration with tool libraries and robust acceptance-to-difficulty mapping.
- Privacy-preserving and edge variants
- Sectors: mobile, IoT, healthcare
- Use cases:
- Smaller introspective DLMs for on-device assistants; reduced interaction latency with verified tokens per step.
- Potential tools/products:
- Quantized I-DLMs, memory-optimized ISD kernels; edge-serving SDKs.
- Assumptions/dependencies:
- Research into small-scale models retaining high acceptance; hardware-specific kernel optimizations.
- Hardware–software co-design for parallel self-verified decoding
- Sectors: semiconductor, cloud infrastructure
- Use cases:
- Attention kernels and accelerators tailored for ISD’s small-extend causal passes and fused verification.
- Potential tools/products:
- ISD-aware fused attention/softmax units; KV-commit hardware primitives; scheduling firmware.
- Assumptions/dependencies:
- Stable APIs for ISD; broad adoption justifying silicon investment.
- Risk controls using acceptance as a safety signal
- Sectors: healthcare, finance, legal
- Use cases:
- Compliance pipelines where low-acceptance spans trigger stricter guardrails, red-teaming, or full AR recomputation before release.
- Potential tools/products:
- “Acceptance Gatekeepers” in approval workflows; human-in-the-loop dashboards showing acceptance dips along generated documents.
- Assumptions/dependencies:
- Validated links between acceptance dips and error/hallucination rates for domain-specific tasks.
- Curriculum and pedagogy for ML education
- Sectors: academia, training providers
- Use cases:
- Courses that teach parallel generation with self-verification; labs using open-sourced I-DLM to study decoding–quality trade-offs.
- Potential tools/products:
- Teaching kits: introspective acceptance probes, stride/τ labs, benchmark harnesses.
- Assumptions/dependencies:
- Sustained open-source availability of models and inference code.
- Cross-model orchestration via acceptance-aware routing
- Sectors: platform engineering, MLOps
- Use cases:
- Routers that send easy prompts to high-stride I-DLM and hard ones to AR or larger models based on early acceptance signals.
- Potential tools/products:
- “Acceptance Router” for multi-model fleets; cost–latency–quality tuners.
- Assumptions/dependencies:
- Reliable early acceptance estimates; latency budget for upfront probing.
These applications hinge on the paper’s core ideas—logit-shifted causal training for introspective consistency, introspective strided decoding for single-pass propose-and-verify, and an AR-compatible serving stack—enabling immediate deployment benefits and setting a roadmap for broader, multimodal, and system-level innovations.
Glossary
- All-masked training: A training regime where all input tokens are replaced with a mask to provide dense supervision across positions. "All-masked training with auto-balanced loss."
- Auto-balanced loss: A dynamic loss-weighting scheme that equalizes gradient magnitudes between masked (decode) and clean (introspection) positions. "We address this with an auto-balanced loss:"
- Autoregressive (AR) models: Models that generate text one token at a time, conditioning each prediction on all previous tokens. "Diffusion LLMs promise parallel generation, yet still lag behind autoregressive (AR) models in quality."
- Block-causal attention: An attention pattern that is bidirectional within blocks but causal across blocks. "Unlike SDAR which uses block-causal attention (bidirectional within blocks),"
- Block diffusion: A diffusion decoding approach that operates on token blocks, often requiring multiple denoising steps and commit passes. "This is because block diffusion (SDAR, LLaDA) requires denoising steps plus a mandatory KV-commit forward that produces no new tokens,"
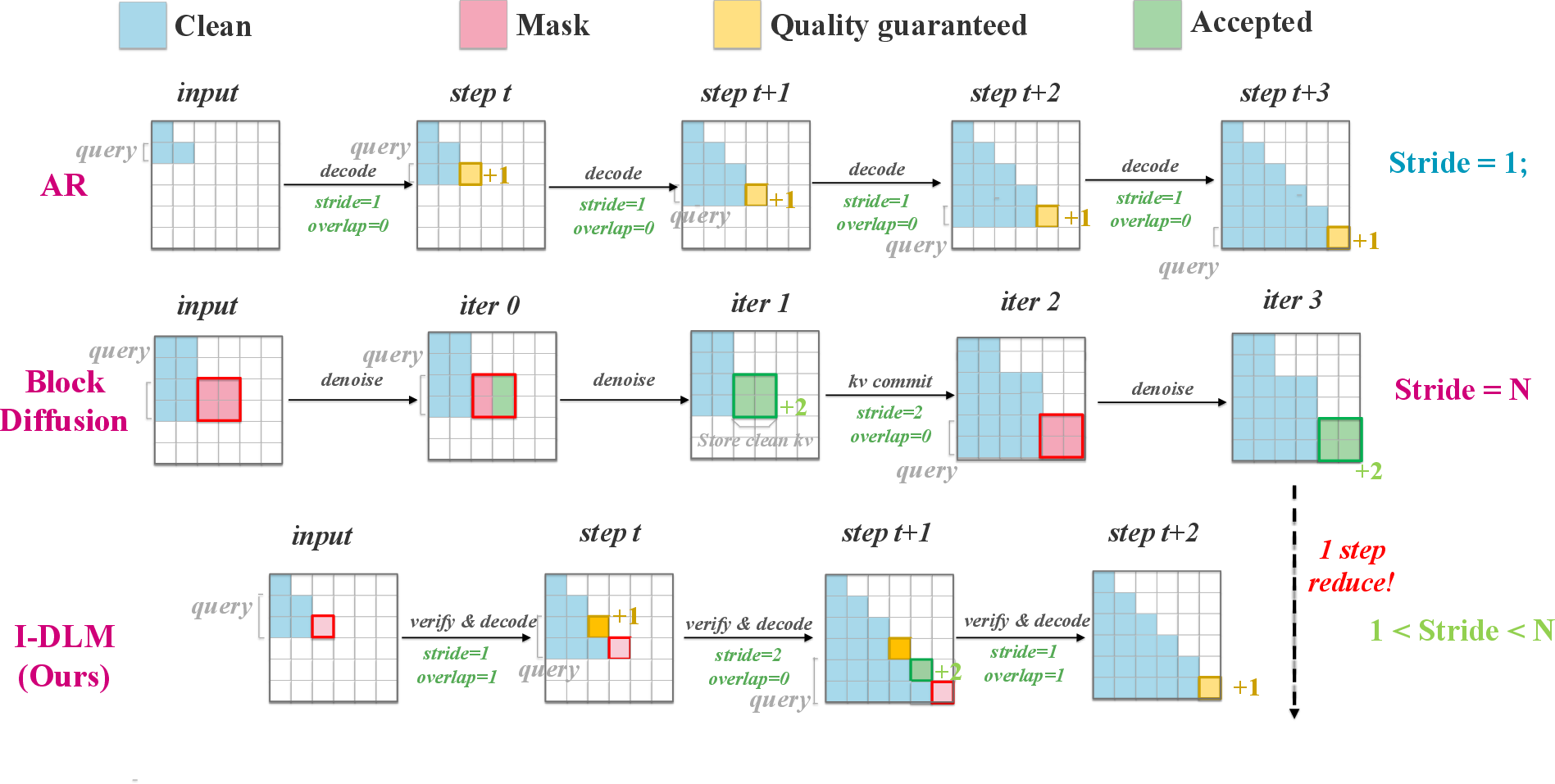
- Causal anchor distribution: The next-token AR distribution used to verify proposed tokens during introspection. "At [MASK] positions, the model proposes new tokens; at introspection positions, it revisits previous tokens against its causal anchor distribution."
- Causal masking: An attention constraint where each position only attends to equal-or-earlier positions, preserving autoregressive ordering. "We apply strict causal masking uniformly across both the masked and clean portions:"
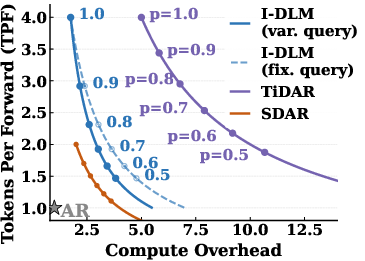
- Compute overhead: Extra floating-point operations incurred relative to standard AR decoding to produce the same number of output tokens. "We define compute overhead as the ratio of total FLOPs to decode a given number of tokens compared to AR decoding."
- Continuous batching: A serving technique that dynamically groups requests so they advance in lockstep for efficient execution. "The modern LLM serving stack (e.g., continuous batching, fused attention kernels, paged KV cache) is highly optimized for AR decoding."
- Cross-entropy loss: The standard negative log-likelihood objective used to train next-token prediction. "We apply a cross-entropy loss with shifted labels separately to the masked and clean regions:"
- CUDA graph: A pre-captured, replayable GPU execution graph that reduces kernel launch overhead. "we capture the entire extend forward into a single CUDA graph, replaying it each step with only input_ids and attention metadata updated in-place."
- Diffusion LLMs (DLMs): Models that iteratively refine token sequences through denoising-style steps to enable parallel generation. "Diffusion LLMs (DLMs)~\citep{austin2021structured,sahoo2024simple,nie2025large,cheng2025sdar} offer an appealing alternative to autoregressive (AR) LLMs:"
- Extend mode: A serving operation that appends multiple new tokens to a sequence in a single step under causal attention. "Each ISD step maps to SGLang's native extend mode, appending tokens with causal attention."
- Fused attention kernels: Optimized GPU kernels that combine multiple attention operations to reduce overhead. "The modern LLM serving stack (e.g., continuous batching, fused attention kernels, paged KV cache) is highly optimized for AR decoding."
- Gated LoRA: A method that applies LoRA adapters selectively (e.g., only at mask positions) via a binary gate to control when adaptations affect outputs. "Inspired by the gated LoRA approach in multi-token prediction~\citep{samragh2025your}, we gate the LoRA residual with a per-token binary mask:"
- Gumbel-max correction: A sampling correction technique leveraging the Gumbel-max trick to adjust proposals to a target distribution. "The verification step is fused into a single Triton kernel with online softmax and Gumbel-max correction;"
- Introspective acceptance rate: A metric measuring how often a model endorses its own previously generated tokens upon re-evaluation. "We define the introspective acceptance rate, which measures whether a model accepts its previously generated tokens."
- Introspective consistency: The property that a model’s generation distribution matches its own verification (causal) distribution. "We stem this gap to a failure of introspective consistency: AR models agree with their own generations, while DLMs often do not."
- Introspective Diffusion LLM (I-DLM): A DLM paradigm that maintains diffusion-style parallelism while enforcing AR-like self-consistency. "we introduce Introspective Diffusion LLM (I-DLM), a paradigm that retains diffusion-style parallel decoding while inheriting the introspective consistency of AR training."
- Introspective Strided Decoding (ISD): A decoding algorithm that generates multiple tokens per pass and simultaneously verifies previous tokens against a causal anchor. "I-DLM uses a novel introspective strided decoding (ISD) algorithm, which enables the model to verify previously generated tokens while advancing new ones in the same forward pass."
- Iterative denoising: Successive refinement steps used in diffusion decoding to progressively improve token predictions. "introspective strided decoding eliminates the compute overhead of iterative denoising (\S\ref{sec:inference});"
- KV-commit: A forward pass that updates the key–value cache to reflect finalized tokens, often incurring extra compute in block methods. "a mandatory KV-commit forward that produces no new tokens,"
- Logit shift: A training adjustment where hidden states at position i predict token i+1, aligning generation and verification signals. "We pair this with a logit shift: the hidden state at position is trained to predict token rather than token ."
- LoRA adapters: Low-rank adaptation modules that fine-tune large models efficiently by injecting small-rank updates. "we develop a gated residual adaptation mechanism where LoRA adapters are applied only at mask positions, while verification relies on the base model weights."
- Paged KV cache: A memory-managed key–value cache for attention that supports efficient, large-concurrency serving via paging. "inheriting paged KV cache, continuous batching, and tensor parallelism without modification."
- Prefill: An initial AR pass over the prompt to build the KV cache before parallel decoding steps. "ISD begins with a standard AR prefill over the prompt, then dynamically selects the effective stride at each decode step via the acceptance criterion."
- p/q acceptance criterion: A probabilistic test that accepts a proposed token with probability min(1, p/q) to guarantee target-distribution correctness. "We introspect on each token by comparing it against its causal anchor using the acceptance criterion~\citep{leviathan2023fast}:"
- Self-speculative decoding: Using the same model to draft and verify tokens, avoiding a separate draft model. "AR-compatible serving stack for deployable DLMs and self-speculative decoding"
- Speculative decoding: A technique that drafts multiple tokens with a fast model and verifies them with a stronger model to accelerate AR decoding. "or speculative decoding which requires a separate draft model, the stride in ISD adapts intrinsically based on the model's own self-consistency:"
- Stationary-batch scheduling: A decode loop that reuses a batch object across steps to reduce CPU–GPU synchronization and scheduler overhead. "and further customize it with a stationary-batch scheduler."
- Tensor parallelism: Distributing model parameters across multiple devices to scale inference/training throughput. "inheriting paged KV cache, continuous batching, and tensor parallelism without modification."
- Tokens per forward (TPF): The expected number of finalized tokens produced per model forward pass, indicating parallel decoding efficiency. "We provide detailed tokens per forward (TPF) pass and compute overhead analysis given different per-token acceptance rates in Appendix~\ref{app:tpf_derivation}."
- Triton kernel: A GPU kernel written in the Triton language to fuse and optimize operations like verification and sampling. "The verification step is fused into a single Triton kernel with online softmax and Gumbel-max correction;"
Collections
Sign up for free to add this paper to one or more collections.