- The paper shows that raw-text RAG storage consistently outperforms heavily compressed memory models in continuous lifelog scenarios.
- The study introduces LifeDialBench, featuring EgoMem and LifeMem, to reliably assess memory capabilities with strict temporal causality.
- The research highlights the need for high-fidelity context preservation in AI memory systems to support robust multi-hop and temporal reasoning.
Evaluating Memory Capabilities in Continuous Lifelog Scenarios: An Expert Analysis
With the proliferation of always-on wearable devices (e.g., AI glasses and continuous audio recorders), there is a definitive shift toward recording open-ended, multi-party human life via lifelogs. Existing LLM-based memory systems and their corresponding benchmarks, however, primarily focus on artificial dialogue setups—either single-session human-AI or dyadic interactions—greatly underestimating the distinct challenges of realistic lifelong memory curation and retrieval. The foundational problem here is twofold: (1) The absence of benchmarks and standardized protocols for evaluating LLM memory in true continuous, always-on, causal lifelog scenarios; and (2) The mismatch between over-engineered "agentic" memory modules, which rely heavily on lossy abstraction and compression, and the critical need for high-fidelity, context-preserving representations to support real-world memory tasks.
The authors formalize this gap by contrasting the continuous, multi-speaker, temporally unsegmented lifelog paradigm against episodic, trigger-based human-AI chat (Figure 1).
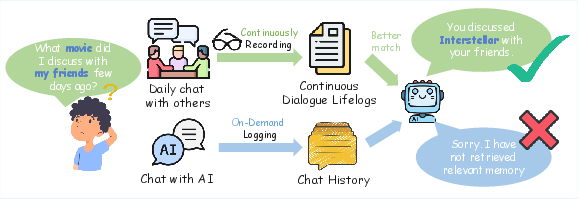
Figure 1: Comparison between continuous always-on lifelog recording and episodic on-demand chat, highlighting structural differences in information capture and retrieval.
The LifeDialBench Benchmark: Construction and Design Principles
To address benchmark limitations, the paper introduces LifeDialBench, with two complementary data subsets:
- EgoMem: Built atop real-world first-person videos from the "EgoLife" dataset, it offers temporally dense, multi-party conversational renderings grounded in physical events, but within a limited (seven-day) time window.
- LifeMem: Synthesized at scale through a human-in-the-loop, hierarchical simulation pipeline that produces a semantically consistent, year-long multi-person dialogue stream, reflecting a realistic distribution of event types, social roles, and locations.
Importantly, LifeDialBench enforces temporal causality by proposing a rigorous Online Evaluation Protocol: all model queries are answered strictly using information available up to each point in time, preventing future context leakage and ensuring a faithful streaming scenario.
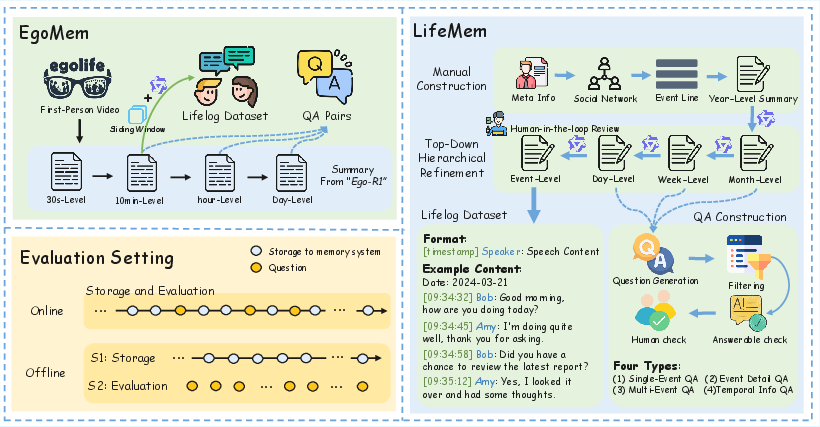
Figure 2: LifeDialBench—EgoMem (real egocentric data) and LifeMem (long-horizon simulation) structure, together with the online incremental evaluation mechanism.
Design principles embodied in LifeDialBench include:
- Temporal Causality: Strict evaluation aligned with real-world information progression.
- Compositional Query Complexity: Coverage of single-event recall, event detail retrieval, multi-hop reasoning, and precise temporal grounding.
- Ecological Validity: Multi-speaker, chronologically continuous data to reflect natural conversational and event flow, not just isolated sessions.
Dataset Analysis
LifeMem achieves realistic long-term coverage, with events and dialogue statistics closely matching real human life regardless of season or subject:
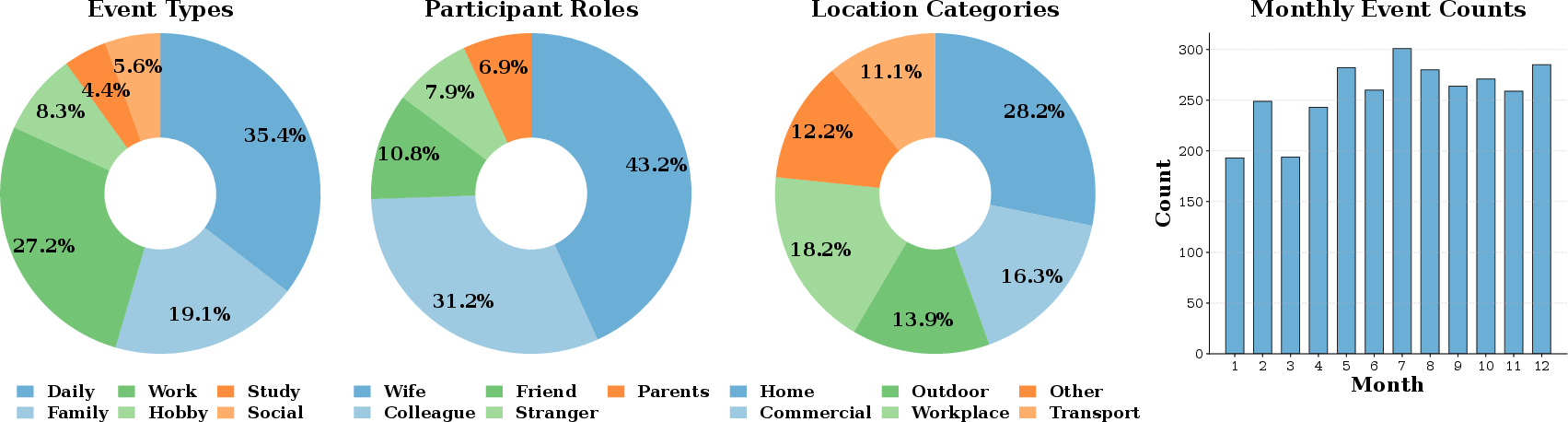
Figure 3: LifeMem dataset distributions—event type, social role, location, and monthly dialogues—demonstrating alignment with ecological lifelog characteristics.
Careful curation ensures all evaluated QA examples are genuinely answerable without timestamp leakage or future knowledge, using a multi-stage LLM-based and human-reviewed pipeline. EgoMem employs a hybrid approach synthesizing text dialogues anchored in real video-derived event summaries, overcoming the ASR limitations and sparsity typical in egocentric audio.
Memory Systems Evaluated
The study benchmarks four paradigms:
- RAG: Direct raw text retrieval-augmented generation.
- A-Mem: RAG-extended with auxiliary metadata (semantic tags, brief summaries).
- MemOS: Context is compressed into lightweight structured records, discarding raw input.
- Mem0: More aggressive fact-level abstraction with highly compressed representations.
Results are presented under both multiple choice and open-ended QA, across both EgoMem and LifeMem, using Qwen and GPT-4o-mini as backbone LLMs.
Empirical Findings
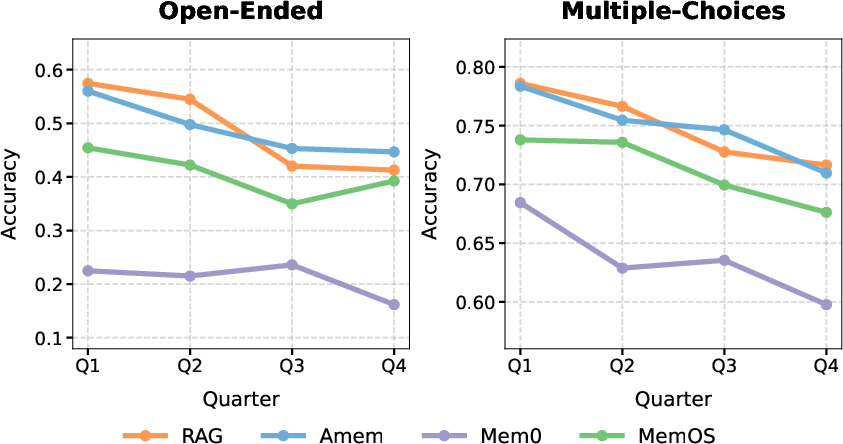
Counter-Intuitive Superiority of Raw-Text RAG Storage
A central, bold finding is that RAG and its minimally-augmented variant (A-Mem) consistently and substantially outperform architecturally sophisticated, compression-based memory systems (MemOS, Mem0) across all conditions and tasks.
This result defies the prevailing trend toward engineered abstraction layers or heavy-duty summarization—in continuous lifelog streams, fidelity in original context encoding is paramount. Auxiliary metadata, as in A-Mem, confers no meaningful improvement over simple RAG. MemOS and especially Mem0, while offering potential storage/inference gains, lose crucial details, causing marked declines in factual and especially temporal/multi-hop reasoning accuracy.
Performance loss is monotonic with compression severity: MemOS (light summarization) consistently outperforms Mem0 (aggressive abstraction), but both lag far behind RAG and A-Mem. This pattern remains robust across backbones, question types, and both benchmark subsets, evidencing that context preservation remains the crux for LLM-memory interactions in real lifelog scenarios.
Question and Setting Effects
Sensitivity and Ablation Insights
- Larger models (e.g., Qwen-Plus) yield uniformly higher performance, confirming that base LLM capacity is a primary bottleneck for long-term memory reasoning in complex settings.
- Increasing top-k retrieval depth enhances recall, suggesting retrieval strategies remain a limiting factor.
Importance of Online, Causal Evaluation Protocols
The authors demonstrate that traditional offline evaluation, by allowing access to the full dataset for all queries, systematically overestimates system performance and induces both future-context contamination and memory-overwrite errors (i.e., systems may “lose” information over time due to lossy update rules). The online protocol ensures answers are derived only from historically available data, yielding more realistic assessments and identifying bottlenecks unobservable under offline settings.
Theoretical and Practical Implications
Practical Implications
- Real-world deployment of conversational memory systems for always-on agents requires prioritizing less lossy, context-rich memory architectures.
- Aggressive abstraction paradigms, popular for chat-session style deployments, break down severely under lifelog conditions.
- Retrieval strategies and model scaling are current functional limits, outpacing the utility of sophisticated structured memory management layers.
Theoretical Implications
- The causally-constrained online setting exposes new evaluation pathologies (e.g., irreversible memory overwrites, dynamic context loss) not captured in batch/offline paradigms, mandating future benchmarks and protocol revisions for continued progress.
- The inability of current systems to solve multi-hop or temporal reasoning (under causal constraints) highlights unresolved issues in LLM long-term reasoning and points to the centrality of context size/recall, rather than mere parametrization or layering.
Dataset and Evaluation Prospects
LifeDialBench establishes a new standard for ecological evaluation of memory-centric LLMs, especially with its focus on continuous, multi-party, causally realistic data streams. The release of the data and code base provides a strong testbed for the community.
Future work will require:
- Extension to multi-modal lifelog inputs (e.g., visual, environmental signals).
- Efficient techniques for context management that maintain high fidelity without unbounded storage or compute cost.
- Refined retrieval and memory lifecycle protocols to handle decay, consolidation, and update in large-scale, always-on settings.
- Integration of strong privacy-by-design and data minimization controls, crucial for real-world adoption given the sensitivity of continuous lifelog data.
Conclusion
The paper "Evaluating Memory Capability in Continuous Lifelog Scenario" (2604.11182) defines and systematically addresses the unique evaluation challenges of always-on, open-world conversational memory for AI agents. By constructing a balanced, realistic benchmark and enforcing temporally causal evaluation protocols, the study demonstrates that high-fidelity, raw-context storage is essential: current abstraction-based memory architectures degrade necessary contextual information, underperforming even basic RAG models by significant margins. This work dictates a reorientation in both memory system design and evaluation philosophy for next-generation agentic AI—away from over-designed abstraction, back toward scalable but information-preserving context preservation.
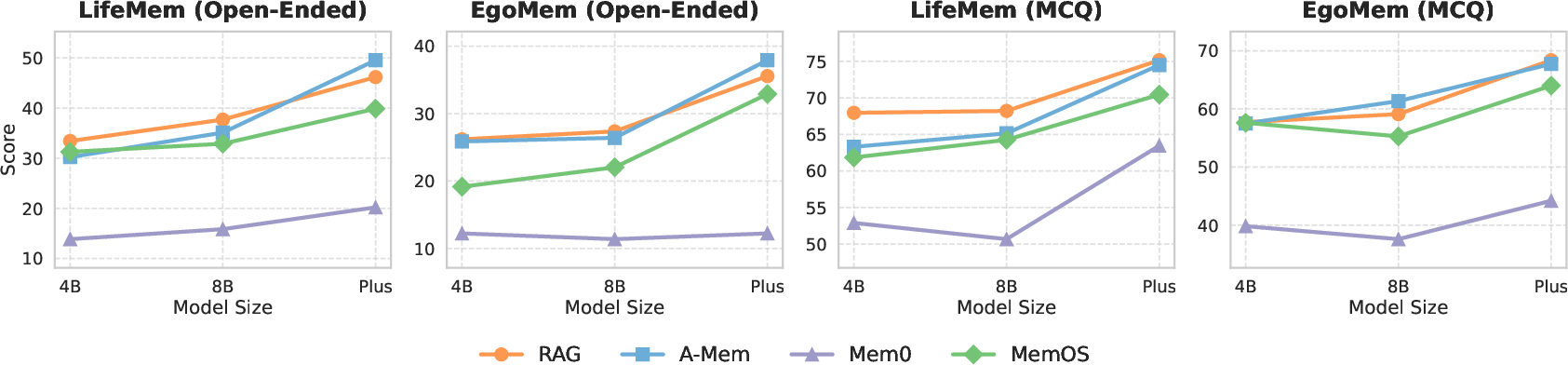
Figure 5: Comparative performance of memory systems using different backbone LLMs, illustrating the positive correlation between backbone capacity and system accuracy.
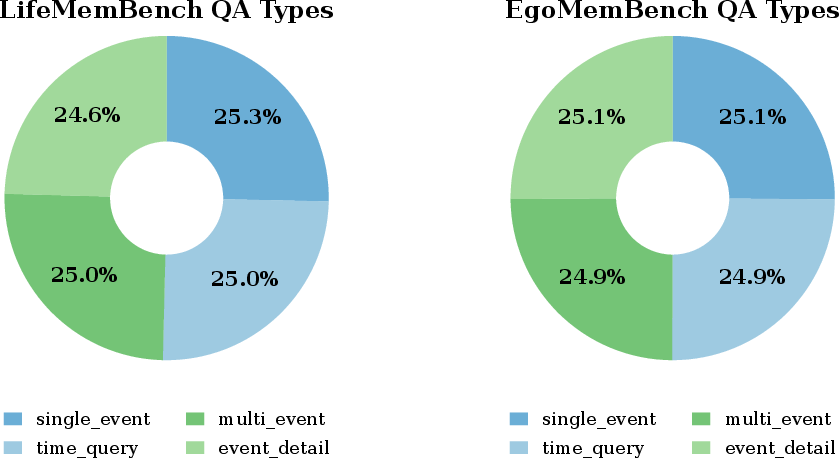
Figure 6: Distribution of LifeDialBench QA types, ensuring balanced coverage of factual, detail, multi-hop, and temporal queries across the evaluation set.
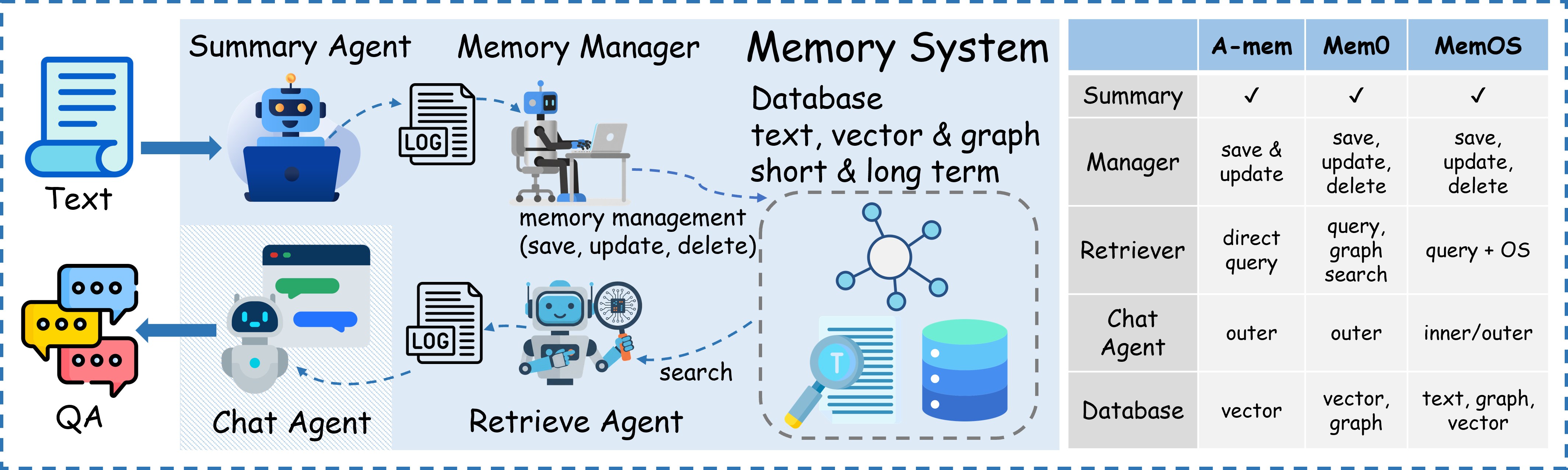
Figure 7: Schematic structure of memory system components and taxonomy of leading architectural approaches.
Summary
This paper provides a rigorous framework, dataset, and experimental paradigm for advancing memory-augmented LLMs in continuous, always-on lifelog scenarios. Its empirical findings challenge accepted wisdom on memory abstraction in agentic architectures, and its protocols establish baseline requirements for robust, contextually faithful, ethically aware, and evaluation-valid memory systems. Future developments in AI lifelog memory must attend to these constraints and insights.